
論文まとめ:DINOv3


- タイトル:DINO v3
- 著者:Metaの方々
- URL:https://arxiv.org/abs/2508.10104
- GitHub: https://github.com/facebookresearch/dinov3
目次
論文要約 By Gemini
・この論文において解決したい課題は何?
大規模な自己教師あり学習(SSL)において、モデルとデータセットをスケールアップした際に生じる、特にdense feature mapsの品質劣化という課題を解決したい。
・先行研究だとどういう点が課題だった?
DINOv2などの先行研究では、モデルサイズを大きくするとglobalなタスクでは性能が向上するものの、dense predictionタスクでは性能が劣化するという問題があった。また、大規模なデータセットでの学習におけるデータキュレーションや、学習スケジュールの設定も課題だった。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
データキュレーション、モデルアーキテクチャの改良、そして特にGram anchoringという新しい正則化手法を導入した点が独自性。これにより、大規模なモデルでも高品質なdense feature mapsを維持し、様々なタスクでstate-of-the-artの性能を達成した。
・提案手法の手法を初心者でもわかるように詳細に説明して
DINOv3は、教師なしで画像から特徴を学習する自己教師あり学習の手法です。
- データ準備: 大量のWeb画像から、多様性と有用性を考慮してデータを選びます。
- モデル: 画像を小さなパッチに分割し、Transformerというネットワークで処理します。
- 学習:
- DINO: 画像の異なる部分(global crop)がお互いに似た特徴を持つように学習します。
- iBOT: 画像のパッチ(local crop)を隠して、それを予測するように学習します。
- Gram Anchoring: 学習初期のモデル(先生)のパッチ間の類似度(Gram matrix)を、学習が進んだモデル(生徒)に模倣させ、特徴マップの品質を保ちます。
- 高解像度化: 高解像度の画像で追加学習し、様々な解像度に対応できるようにします。
- 蒸留: 大きなモデルの知識を小さなモデルに伝え、効率的に使えるようにします。
・提案手法の有効性をどのように定量・定性評価した?
定量評価:ImageNetでの線形評価、ADE20kでのセマンティックセグメンテーション、NYUv2での深度推定、COCOでの物体検出など、様々なタスクで性能を測定。
定性評価:PCAによる特徴マップの可視化、類似度マップの表示などを行い、特徴の品質を評価。
・この論文における限界は?
DINOv3は多くのタスクで高い性能を発揮するものの、テキスト情報を活用するCLIPなどのモデルと比較すると、一部のタスクでは性能が劣る。また、モデルサイズが大きいため、計算資源の制約がある環境での利用は難しい場合がある。
・次に読むべき論文は?
* DINOv2: Learning Robust Visual Features without Supervision (DINOv3のベースとなっている研究)
* Exploring Plain Vision Transformer Backbones for Object Detection (DINOv3を物体検出に適用した例)
* Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data (DINOv3を深度推定に適用した例)
論文中にコードの提示はありませんでした。
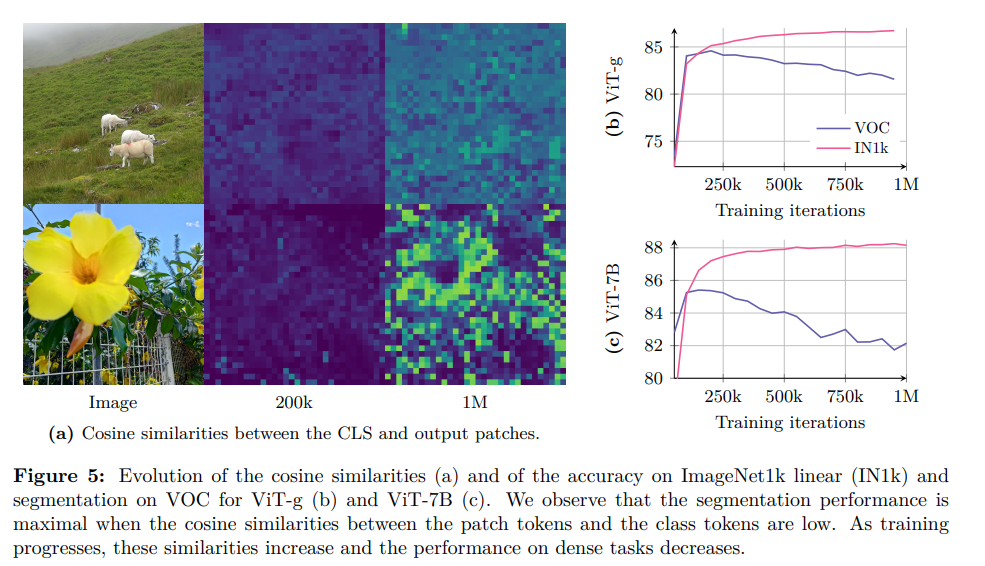
Dense Feature Mapの劣化とは
自己教師あり学習モデル(SSL)を大規模データで長時間学習させると、「密な特徴マップ」の品質が劣化するという問題が起こります。
何が起きるか?
- 画像の部分的な情報(パッチ)の一貫性が失われ、特徴マップにノイズが増えます。
- これにより、セマンティックセグメンテーションのような、画像のピクセル単位での理解を必要とする「密な予測タスク」の性能が低下します。
- これは、分類性能が向上し続けるのとは対照的な現象です。
なぜ起きるか?
- 画像全体を大まかに理解しようとする学習目的(グローバルな表現)と、各部分の詳細を捉えようとする目的(密な表現)が互いに矛盾するためです。
- 特に大規模モデルの長期学習では、全体を理解する学習が優勢になり、部分的な情報の精度が犠牲になります。
対策は?
- この問題に対し、DINOv3というモデルでは「Gram Anchoring」という新しい手法を導入し、品質劣化を効果的に防いでいます。
データセットの戦略
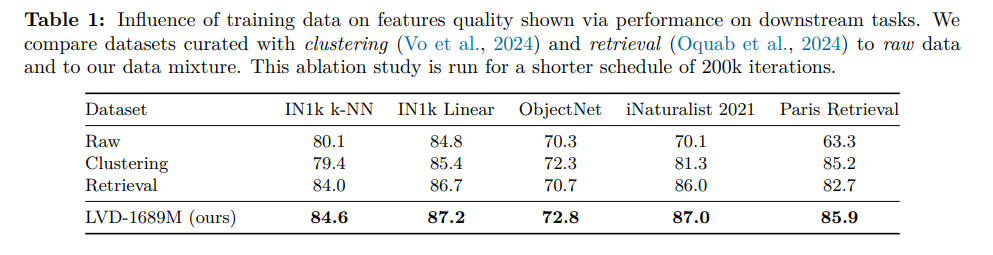
DINOv3は、モデルとデータセットのスケーリング効果を最大化するため、DINOv2を基盤としつつ、データキュレーションとサンプリング戦略を大幅に高度化しました。
データキュレーション戦略
170億枚のウェブ画像データプールから、以下の3つの相補的なアプローチを組み合わせ、大規模かつ高品質な事前学習データセットを構築しています。
- 階層的k-meansクラスタリング: DINOv2の画像埋め込みを活用し、多様な視覚的概念をバランス良く網羅する16.89億枚のデータセット(LVD-1689M)を自動生成。
- 検索ベースのキュレーション: 特定のダウンストリームタスクに関連する画像を検索・収集。
- 公開データセットの活用: ImageNetなど、既存の高品質なデータセットを統合。
データサンプリング戦略
学習の安定性と性能を両立させるため、独自のサンプリング手法を導入しました。具体的には、学習イテレーションごとに、高品質なImageNet1kのみで構成される「均質なバッチ」と、他の全データを混合した「異質なバッチ**」を確率的に切り替えて使用します。
DINOv2からの進化
DINOv2が主に検索ベースの単一的なアプローチだったのに対し、DINOv3は複合的なデータキュレーションと高度なサンプリング戦略を導入しました。これにより、DINOv2のスケーリングを阻害した「ラベルなしデータからの有用な情報収集」という課題を克服し、モデルの長期学習時に見られた密な特徴マップの品質劣化にも対処しています。
学習戦略
DINOv3は、自己教師あり学習(SSL)の性能を最大化するため、DINO、iBOT、そして新技術Gram anchoringという3つの主要な要素を組み合わせています。これにより、モデルとデータセットの大規模化に伴う課題、特に密な特徴マップの品質劣化を解決します。
DINO:画像レベルの目的とDINOv2との違い
DINOは、画像全体の高レベルなセマンティックな理解を学習させる画像レベルの自己教師あり目的関数です。
DINOv3におけるDINO損失の基本的なメカニズムはDINOv2の戦略を踏襲していますが、決定的な違いはその課題解決のアプローチにあります。
- DINOv2での課題: DINO損失によるグローバル表現の学習が優勢になる結果、長期学習において密な特徴マップの品質が劣化する問題がありました。
- DINOv3での進化: この品質劣化という副作用に対し、DINOv3は後述のGram anchoringを新たに組み合わせることで積極的に対処しています。これにより、DINO損失の利点を維持しつつ、DINOv2では未解決だった大規模・長期学習の安定性を確保した点が最大の相違点です。
iBOT:パッチレベルの目的
iBOTは、画像の各パッチにおける局所的な情報を学習させるパッチレベルの潜在再構成目的関数です。密な表現の学習を担いますが、DINO(グローバル目的)との単純な組み合わせでは学習が進むにつれてバランスが崩れ、品質劣化の一因となっていました。
Gram anchoring:品質劣化を防ぐ新戦略
Gram anchoringは、DINOv3で新たに導入された、密な特徴マップの品質劣化を解決するための画期的な損失関数です。
- 目的: 大規模モデルの長期学習時に発生する、パッチレベルの一貫性の喪失を防ぎます。
- メカニズム: 特徴そのものではなく、パッチ特徴間の類似度構造を捉えたGram行列に作用します。学生モデルのGram行列を、品質が良い初期学習段階の教師モデル(Gram teacher)のGram行列に近づけるように制約をかけます。これにより、特徴の表現力を損なうことなく、局所的な一貫性のみを維持・修復します。
このようにDINOv3は、DINOとiBOTのバランス問題を革新的なGram anchoringで解決することで、大規模化しても汎用性と高精度な密な特徴を両立させています。
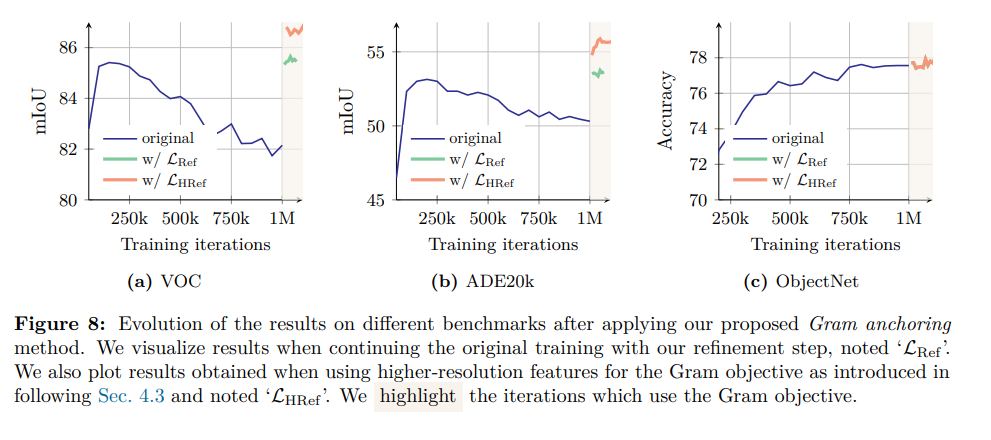
$L_{ref}$が上記3つ全てを考慮した損失関数、$L_{HRef}$が高解像度の工夫あり
高解像度化の工夫
DINOv3は、様々な解像度で高品質な密な特徴マップを生成するために、主に2つの戦略を採用しています。
- 学習中の品質維持(高解像度Gram Anchoring)
学習中に、教師モデル(Gram teacher)に高解像度の画像を入力し、そこから得られる高品質な特徴を学生モデルに蒸留します。これにより、大規模・長期学習で起こりがちな密な特徴の品質劣化を防ぎます。 -
事後学習での柔軟性向上(高解像度適応フェーズ)
基本的な学習の後、様々な高解像度画像を使って短期間の追加学習を行います。これにより、モデルが幅広い入力解像度に柔軟に対応できるようになり、汎用性と性能が向上します。
これらの工夫により、DINOv3は低解像度から4Kを超える高解像度まで、一貫して安定した特徴マップを提供できる強力な基盤モデルとなっています。

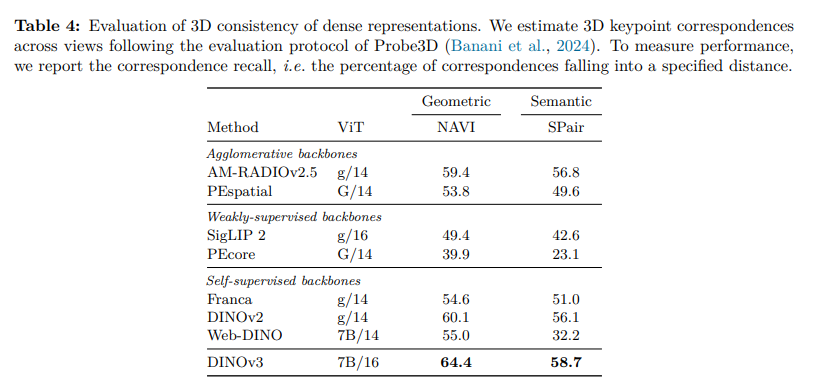
3D関連タスクの能力向上
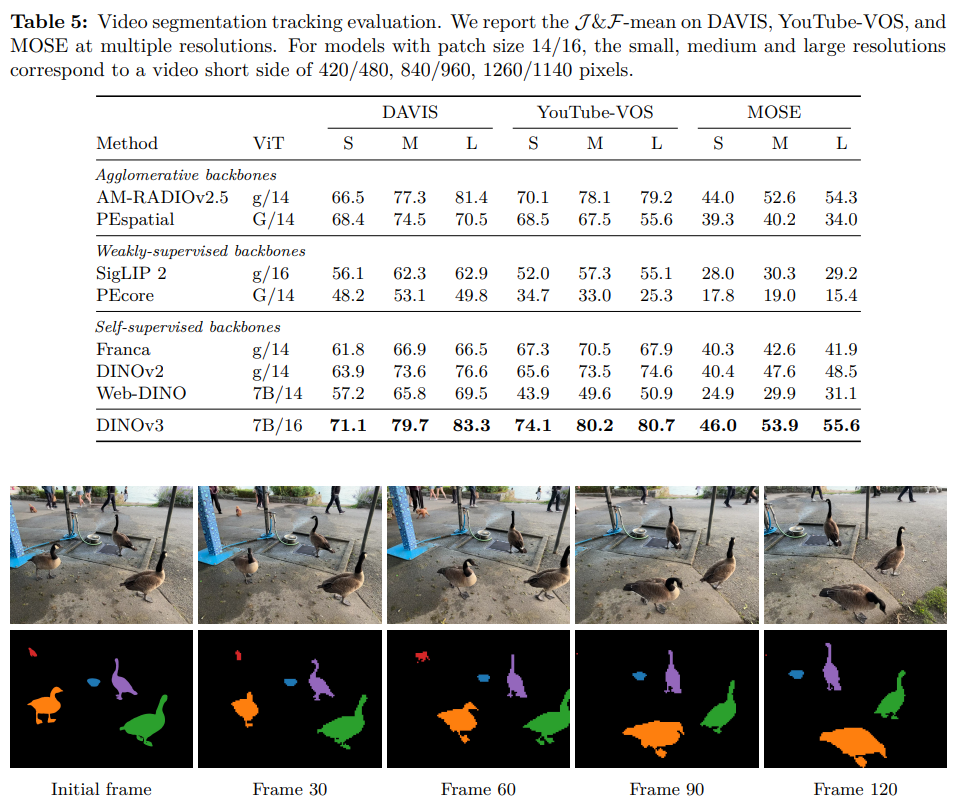
DINOv3は、自己教師あり学習(SSL)を基盤とする画像モデルでありながら、特に3D認識タスクにおいて卓越した性能を示します。これは、物理世界の理解を促す高品質な「密な特徴マップ」を生成するための新しい戦略を導入した成果です。
3Dタスクにおける高い性能
DINOv3は、特に以下の3D関連タスクで最先端の性能を達成しています。
- 3Dキーポイントマッチング: 異なる視点からのオブジェクト対応付けにおいて、従来モデルを大幅に上回る精度を達成し、3D形状に即した特徴(3D-aware features)の生成能力を示しています。
- 単眼深度推定: 追加のファインチューニングなしで(凍結されたバックボーンのまま)、既存のどのモデルよりも高い精度で単一画像からの深度推定が可能です。これは、モデルが本質的に3D認識能力を備えていることを強く示唆します。
- 幾何学的属性の推定: カメラ姿勢や深度マップを推定するシステム(VGGTなど)に組み込むことで、その性能を一貫して向上させます。
3D能力を向上させた技術的要因
画像のみの学習で高い3D能力を獲得した背景には、以下の戦略があります。
- Gram Anchoring戦略: 学習が長期化する際に生じる密な特徴マップの品質劣化を防ぐ新技術です。パッチ間の局所的な類似性構造を正規化することで、ノイズが少なく一貫性のある特徴マップを維持し、3D認識に不可欠な正確な局所表現を可能にします。
- 高解像度適応フェーズ: 様々な解像度の画像ペアで追加学習を行うことで、モデルが多様な入力解像度に対応できるようにします。これにより、4Kを超えるような高解像度画像に対しても安定して高品質な特徴マップを生成でき、詳細な空間情報を要する3Dタスクに直接的に貢献します。
これらの革新的なアプローチにより、DINOv3は2Dの画像データから物理世界の3D構造を深く理解する能力を獲得しています。
PCAについて
DINOv3では、主成分分析(PCA)が主に、モデルが生成する高次元の特徴マップの品質を視覚的に評価・分析するためのツールとして活用されています。
PCAの主な役割:品質の可視化と分析
PCAの最も重要な役割は、人間が直接理解できない高次元の密な特徴マップ(dense feature maps)を、視覚的に評価可能な形式に変換することです。
- RGBへのマッピング: 特徴マップの最初の3つの主成分を抽出し、それらをRGB(赤・緑・青)の各色チャネルに割り当てることで、特徴をカラー画像として可視化します。
- 品質の定性的評価: この可視化された画像により、DINOv3が生成する特徴がどれほど鮮明で、ノイズが少なく、意味的に一貫しているか(例:道路、建物、植生などが明確に分離されているか)を直感的に判断できます。
- 優位性の証明: 他のモデルと比較した際に、DINOv3の特徴マップの品質が優れていることを視覚的に示すための強力な証拠として利用されます。
補助的な役割:特徴量の前処理
また、PCAは補助的な目的として、特徴量の安定性を確保するための前処理手法としても言及されています。モデルの中間層で発生することがある特徴量次元の異常値を正規化し、より安定した特徴量を得るための有効な手段の一つとされています。
要するに、DINOv3におけるPCAは、モデルの性能、特に高品質な密な特徴表現を生成する能力を説得力をもって示すための診断・プレゼンテーションツールであり、同時に特徴量の健全性を保つための実用的な技術としても認識されています。

CLIPとの比較
DINOv3とCLIPは、それぞれ自己教師あり学習(SSL)と弱教師あり学習(WSL)という異なるアプローチを代表するモデルです。この学習方法の違いが、両者の強みと弱みを明確に分けています。
DINOv3の強み:密なタスクとデータ効率
DINOv3の最大の強みは、ピクセルレベルの精密な理解を要する密な予測タスク(dense prediction tasks)における圧倒的な性能です。
- 卓越した密なタスク性能: セマンティックセグメンテーション、単眼深度推定、3Dキーポイントマッチングにおいて、CLIPを含む弱教師ありモデルを大幅に凌駕します。これは、
Gram Anchoring戦略により、ノイズが少なく意味的に一貫した高品質な特徴マップを生成できるためです。 - アノテーション不要: 生の画像データのみから学習するため、高品質なテキストとペアになったデータを必要とするCLIPと異なり、利用可能な学習データ量が事実上無制限であり、スケーラビリティに優れています。
- 汎用性と堅牢性: 特定のタスクに特化しないため、汎用性が高く、物理世界の構造理解に優れた特徴を生成します。
CLIPの強み:テキスト連携とゼロショット能力
CLIPは画像とテキストのペアで学習するため、言語と連携したタスクにネイティブな強みを持ちます。
- 強力なゼロショット能力: テキストを介して、学習データにない物体や概念も認識できる「ゼロショット能力」や「オープンボキャブラリ能力」に非常に優れています。
- OCR関連タスクでの優位性: テキスト情報を含むデータで学習するため、文字認識(OCR)が重要なタスクでは、テキストを学習しないDINOv3に対して明確な優位性を示します。
弱点の比較
両者の弱点は、それぞれの強みの裏返しです。
* DINOv3の弱点: OCR関連タスクの性能が低く、画像分類のようなグローバルなタスクでは、最新の弱教師ありモデルにわずかに劣ることがあります。
* CLIPの弱点: グローバルな特徴に焦点を当てるため、密なタスクの性能が低く、3D的な構造理解に欠けます。また、学習には高品質なアノテーション付きデータが必須です。
結論として、DINOv3はアノテーション不要でスケール可能であり、特に密なタスクや3D理解に卓越した性能を発揮します。一方、CLIPはテキストとの強力な連携を活かしたゼロショット能力やグローバルな画像理解に強みがあります。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー