
Fargate/ECSのスポットインスタンスのドレインを試す
Posted On 2025-02-04


ECSにおけるFargate/ECS on EC2のスポットインスタンス運用を試してみる。Fargateスポットは簡単な設定で大幅なコスト削減を可能にしつつ、稼働停止もほとんど発生しなかった。一方、ECS on EC2のスポット運用はAmazon Linux 2023の不具合や二重プロビジョニングなどの問題があり、管理が複雑になりがちである。
目次
はじめに
- ECSにスポットインスタンスのドレインという、スポットインスタンスを継続的に利用する方法があったので試してみた
- スポット価格はECS(EC2)だけでなく、Fargateでも利用できる
- Webアプリの利用想定で、具体的にはStreamlitのアプリをホストすることを想定
- 両者のTerraformでの書き方、中断率を比較してみた
ECSのスポット
- 基本はEC2のスポットインスタンスと同じで、安い代わりにいつ切断されるかわからない
- ただ切断された場合に自動的に新しいインスタンスを取ってくる仕組みは用意されている。
- Fargate:デフォルトで用意されているので特に気にする必要はない
- ECS:Auto Scaling Groupを定義し、Spot Instance Drainingを有効化する。これによりスポットインスタンスの終了通知がきたと同時に新たなインスタンスへのスイッチオーバーがされる
Fargateの場合
コストは以下の通り。1ヶ月の費用は、デフォルトのタスク定義の1vCPU・メモリ3GBを想定。東京リージョンでx86_64の場合
| 料金 | オンデマンド | スポット |
|---|---|---|
| 1 時間あたりの vCPU 単位 | USD 0.05056 | USD 0.01614841 |
| 1 時間あたりの GB 単位 | USD 0.00553 | USD 0.00176623 |
| 1ヶ月費用(1vCPU・3GB) | USD 48.35 | USD 15.44 |
Streamlitでここまでスペックを張る必要はないが、かなりコストは下がる。
ECS on EC2の場合
スポットインスタンスに準じるので、AWSのページ見てください
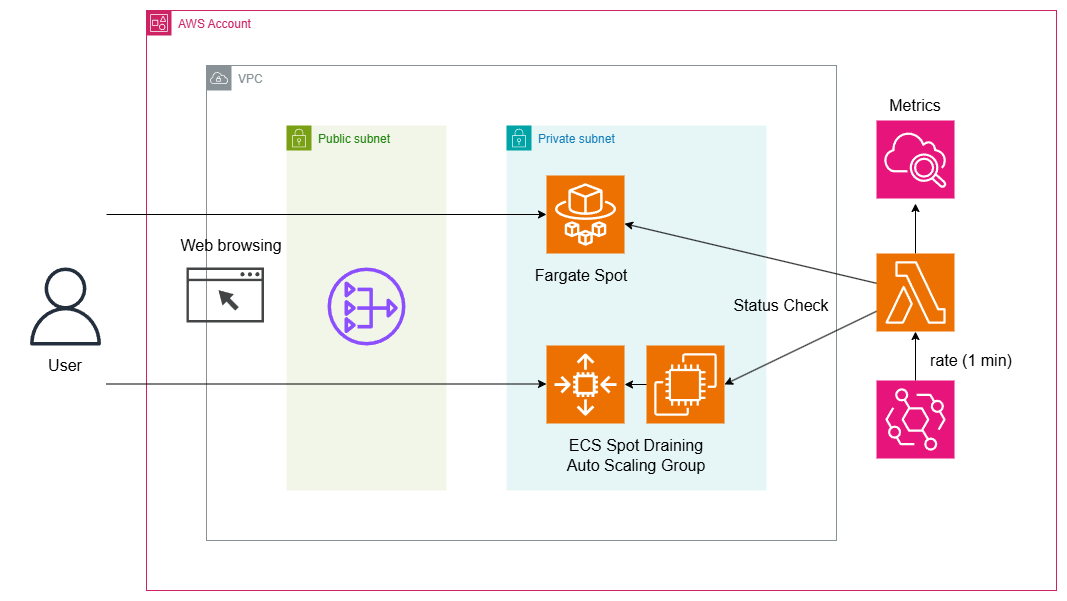
アーキテクチャー図
- ECS on EC2とFargateの両方で試す
- ステータスチェック用に定期実行されるLambdaを追加し、CloudWatch Metricsに公開する
実験
- StreamlitをホストするFargate/ECS on EC2をそれぞれ立てる。EC2はt3.smallを使用
- ステータスチェックのLambdaを回し続け、200が出たかをひたすら記録し続ける。スポットインスタンスのダウンのときはこれが200にならないため
- どの程度ダウンが発生するのかを検討する
実験期間
2025/1/31(金)の15時~2/4(火)の5時
スポットインスタンスのダウンは営業日・営業時間にかなり左右される。例えば、休日はほぼダウンが発生しないが、平日の営業日になるとダウンが発生することが多い。
結果
ほとんどダウンが発生していない

日次の平均値は以下の通り。
| Fargate | ECS EC2 | |
|---|---|---|
| 2025/1/31(金) | 1.0000 | 0.9991 |
| 2025/2/1(土) | 1.0000 | 1.0000 |
| 2025/2/2(日) | 1.0000 | 0.9993 |
| 2025/2/3(月) | 0.9992 | 0.9968 |
ハマりポイント
やってわかったハマりポイントが結構ある
ECS on EC2は現在Amazon Linux 2023で動かないことがある
- 2025/2現状、安定して動くのはAmazon Linux2。2023だとECSのタスクが「プロビジョニング」のままずっと止まっている
- これはECS AgentがOSの仕様によりKillされて初期化失敗したためかと思われる
- 実際に
systemctl status ecsで見るとinactive (dead) と表示されている - この現象はGitHubのIssueで報告されている。Dockerイメージを展開する際に大きくメモリを確保しに行こうとするが、Amazon Linux 2023はメモリキラーが積極的になって、これとの相性が悪いとのこと。
- 現状有効な解決法がAmazon Linux2に戻すで、Amazon Linux 2023でハマりまくったところでAmazon Linux2のAMIに戻したら解決した
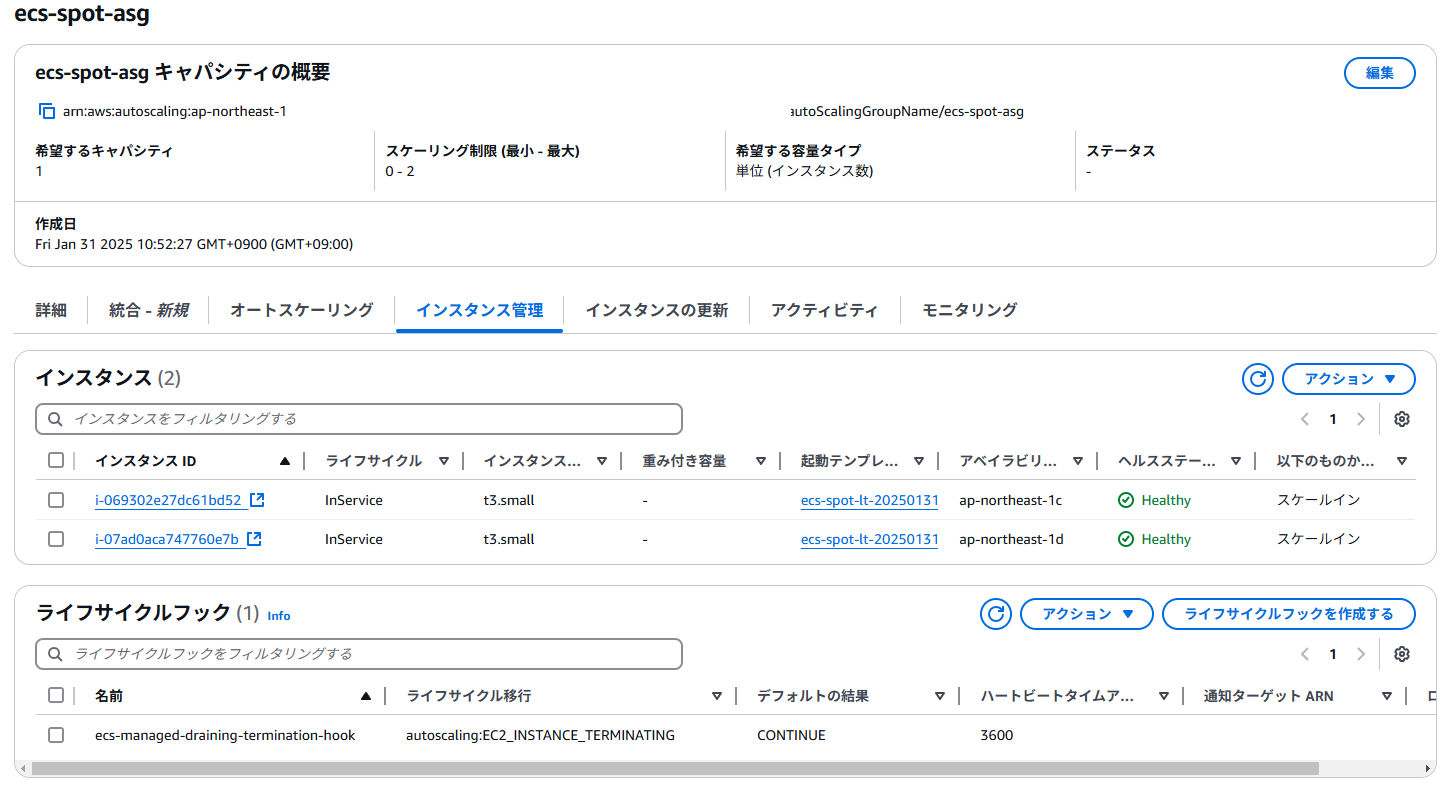
ECS on EC2はインスタンスが二重にプロビジョニングされることが多い
- ECS on EC2はAuto Scaling Groupの設定が良くないのかもしれないが、インスタンスが落ちたあとにインスタンスが2個立ち上がることがある。
- デフォルトのクールダウン:300秒、デフォルトのインスタンスのウォームアップ:300秒で設定しているがそれでも二重に立ち上がる
- Drainingを使うには実質的にスケールイン保護を併用しないとTerrafromがエラーを出す
- Spot Instance Drainingを使う場合は、
ecs-managed-draining-termination-hookという3600秒のライフサイクルフックが自動的に付与され、これをカスタマイズするのが厳しそう - 3600秒のハートビートタイムが結構厄介で、Auto Scaling Groupからインスタンスを消してほしいときに残り続けるという問題がある
- 2個インスタンスが立ち上がってしまうと、二重に課金されるため、せっかくスポットインスタンスで値段を下げても帳消しされてしまう
- スケーリングの最大を0-2ではなく、0-1にすれば解決するかもしれないが、ダウンの頻度を上げることになるので、そこは一定課題ありそう
Fargateは簡単
- 上記はECS on EC2だけの話で、Fargateはキャパシティプロバイダーを追加すればいいだけなので簡単。Terrafromでは以下のように書く。
resource "aws_ecs_cluster" "this" {
name = "example-spot-cluster"
}
resource "aws_ecs_cluster_capacity_providers" "this" {
cluster_name = aws_ecs_cluster.this.name
capacity_providers = ["FARGATE", "FARGATE_SPOT"]
default_capacity_provider_strategy {
capacity_provider = "FARGATE_SPOT"
base = 0
weight = 1
}
}
全体コード
長いのでGitHubに
https://github.com/koshian2/ecs-fargate-ecs-spot
所感
- Fargate spotが良さそう
- ECS on EC2のスポットインスタンスドレインは、タスクで動かすならいいけど、常駐アプリは動かすのが思ったより大変そう。Amazon Linux 2023動かない問題はどうするんだろう?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー