
SA-GANの実装から見る画像のSelf attention


自然言語処理でよく使われるSelf-attentionは画像処理においてもたびたび使われることがあります。自然言語処理のは出てきても、画像のはあまり情報が出てこなかったので、SAGANの実装から画像におけるSelf attentionを見ていきます。
目次
SA-GAN
Self attention GANの略語。論文はこちら。GANの生成画像のクォリティーを上げる手法の一つにSelf attention機構を使っています(ただし、Self attentionだけがこの論文のポイントではない)。
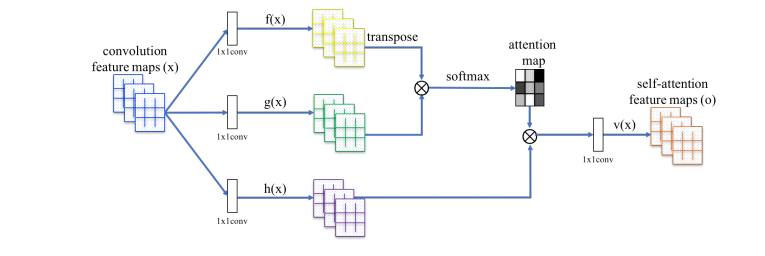
たびたび引用される図ですが、わかりやすいです。ちなみに公式実装では以下のコードにあたります。
https://github.com/brain-research/self-attention-gan/blob/master/non_local.py#L48
ここの「sn_non_local_block_sim」という関数がSelf attention機構になります。ただし、SNGANの場合はSpectral Normという別の手法も合わさっっているので注意してください。TensorFlowのコードです。抜粋すると以下のとおりです。
def sn_non_local_block_sim(x, update_collection, name, init=tf.contrib.layers.xavier_initializer()):
with tf.variable_scope(name):
batch_size, h, w, num_channels = x.get_shape().as_list()
location_num = h * w
downsampled_num = location_num // 4
# theta path
theta = sn_conv1x1(x, num_channels // 8, update_collection, init, 'sn_conv_theta')
theta = tf.reshape(
theta, [batch_size, location_num, num_channels // 8])
# phi path
phi = sn_conv1x1(x, num_channels // 8, update_collection, init, 'sn_conv_phi')
phi = tf.layers.max_pooling2d(inputs=phi, pool_size=[2, 2], strides=2)
phi = tf.reshape(
phi, [batch_size, downsampled_num, num_channels // 8])
attn = tf.matmul(theta, phi, transpose_b=True)
attn = tf.nn.softmax(attn)
print(tf.reduce_sum(attn, axis=-1))
# g path
g = sn_conv1x1(x, num_channels // 2, update_collection, init, 'sn_conv_g')
g = tf.layers.max_pooling2d(inputs=g, pool_size=[2, 2], strides=2)
g = tf.reshape(
g, [batch_size, downsampled_num, num_channels // 2])
attn_g = tf.matmul(attn, g)
attn_g = tf.reshape(attn_g, [batch_size, h, w, num_channels // 2])
sigma = tf.get_variable(
'sigma_ratio', [], initializer=tf.constant_initializer(0.0))
attn_g = sn_conv1x1(attn_g, num_channels, update_collection, init, 'sn_conv_attn')
return x + sigma * attn_g
よく見るとやっていることは上の図の通りですが、TensorFlowのコードはやはりわかりづらいですね。PyTorchのコードに書き換えましょう。
PyTorchのコードに書き換える
SNGANのSelf attentionからSpectral Normを抜いて、PyTorchのコードに書き換えました。ただし、TensorFlowでは画像のテンソルがchannels_last(4次元目)なのに対して、PyTorchではchannels_first(2次元目)なのに注意します。Spectral Normを抜いたので純粋なSelf attentionの機構が取り出せます。
import torch
from torch import nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
"""Self-attention GANにおけるSelf-attention
ただしSAGANのSpectral Normを抜いているので注意
Arguments:
dims {int} -- 4Dテンソルの入力チャンネル
"""
def __init__(self, dims):
super().__init__()
self.conv_theta = nn.Conv2d(dims, dims // 8, kernel_size=1)
self.conv_phi = nn.Conv2d(dims, dims // 8, kernel_size=1)
self.conv_g = nn.Conv2d(dims, dims // 2, kernel_size=1)
self.conv_attn = nn.Conv2d(dims // 2, dims, kernel_size=1)
self.sigma_ratio = nn.Parameter(torch.zeros(1), requires_grad=True)
def forward(self, inputs):
batch, ch, height, width = inputs.size()
# theta path
theta = self.conv_theta(inputs)
theta = theta.view(batch, ch // 8, height * width).permute([0, 2, 1]) # (B, HW, C/8)
# phi path
phi = self.conv_phi(inputs)
phi = F.max_pool2d(phi, kernel_size=2) # (B, C/8, H/2, W/2)
phi = phi.view(batch, ch // 8, height * width // 4) # (B, C/8, HW/4)
# attention
attn = torch.bmm(theta, phi) # (B, HW, HW/4)
attn = F.softmax(attn, dim=-1)
# g path
g = self.conv_g(inputs)
g = F.max_pool2d(g, kernel_size=2) # (B, C/2, H/2, W/2)
g = g.view(batch, ch // 2, height * width // 4).permute([0, 2, 1]) # (B, HW/4, C/2)
attn_g = torch.bmm(attn, g) # (B, HW, C/2)
attn_g = attn_g.permute([0, 2, 1]).view(batch, ch // 2, height, width) # (B, C/2, H, W)
attn_g = self.conv_attn(attn_g)
return inputs + self.sigma_ratio * attn_g
sigma_ratioというパラメーターはどの程度Attentionマップを”味付け”するかという係数で、SAGANでは学習を通じて動かすようにしています。
このSelf-Attentionレイヤーの入力と出力のshapeは同じになります。途中でMaxPoolや1x1Convでチャンネル数が増えたり減ったりしているので、計算量を減らすためのテクニックが入っているからです。
試しにバッチサイズ8、チャンネル数16、32×32の解像度の入力に対してSelf-Attentionの出力がどのようなサイズになるか確認してみます。
if __name__ == "__main__":
model = SelfAttention(16)
x = torch.randn(8, 16, 32, 32)
y = model(x)
print(y.size())
torch.Size([8, 16, 32, 32])
入力と出力のサイズが同じになるのが確認できました。
Self Attentionから係数を抜く
実践的には上のコードで十分ですが、本来のSelf Attentionの役割を見るために、計算量を減らすためのテクニックを外します。これにより1x1Convをすべて消すことができるので、レイヤーの持っている係数は0にすることができます。sigma_scaleのパラメーターは1と仮定して、Attentionマップによる味付け部分だけ返すようにしてみましょう。
class SelfAttentionNoWeights(nn.Module):
"""係数なしのSelf-attention
"""
def __init__(self):
super().__init__()
def forward(self, inputs):
batch, ch, height, width = inputs.size()
# theta path
theta = inputs.view(batch, ch, height * width).permute([0, 2, 1]) # (B, HW, C)
# phi path
phi = inputs.view(batch, ch, height * width) # (B, C, HW)
# attention
attn = torch.bmm(theta, phi) # (B, HW, HW)
attn = F.softmax(attn, dim=-1)
# g path
g = inputs.view(batch, ch, height * width).permute([0, 2, 1]) # (B, HW, C)
attn_g = torch.bmm(attn, g) # (B, HW, C)
attn_g = attn_g.permute([0, 2, 1]).view(batch, ch, height, width) # (B, C, H, W)
return attn_g
コードが単純になりました。ただし、このコードは愚直なやり方なのでめちゃくちゃメモリを食うのに注意してください。320×213の解像度の画像のAttentionマップをとっただけでメモリが30GB以上必要になります。
Attentionマップの可視化
本来Attentionマップは、クラス別のAttentionマップを取って「どのへんが判断根拠になっているか」みたいな可視化が多いのですが、ここは簡略的に画像のカラーチャンネル単位のAttentionを取ってみます。(コードは後述)
そして、(少なくともSNGANでは)Self Attentionはネットワークの中間で使うので、Self Attentionによって味付けされた出力には非線形関数が適用されます。その非線形関数をエミュレートする処理として、「元の画像ピクセルの値 × カラーチャンネルのAttention^定数乗」という計算をしてみます。AttentionマップにはSoftmax関数が適用されているので、値域は0~1になります。つまり、Attentionの定数乗は「0~1のべき乗」になるため、乗数定数によって異なる味によって味付けされた出力となります。
言葉でいってもよくわからないと思われるので実例を示しましょう。このインコの画像を「rainbow.jpg」とします。

チャンネル単位のピクセル値
まず、チャンネル単位のピクセル値を見ると以下のとおりです。

上から順にR,G,Bのピクセル値ですね。この場合はRGBという画像の構成要素そのものなので、Attentionマップなんか取らなくてもピクセル値だけ見ればRGBによる根拠付けはどれくらいかを見ることはできます。しかし、中間層や出力層になると、データの”空間”が変わってくるため、Attentionマップによる可視化が、RGBチャンネルのような画像から目に見える値とは変わってきます。
具体的には、クラス単位でのAttentionは(ほぼ)出力層でとったものです。これはデータの空間が入力層(RGB)とは大きく異なります。そのため、あたかもそのAttentionが、クラス単位の判断根拠という別の意味の持つように見えるという理屈(だと思われます)。
チャンネル単位のAttention
次にRGBのチャンネル単位でのAttentionをとってみます。
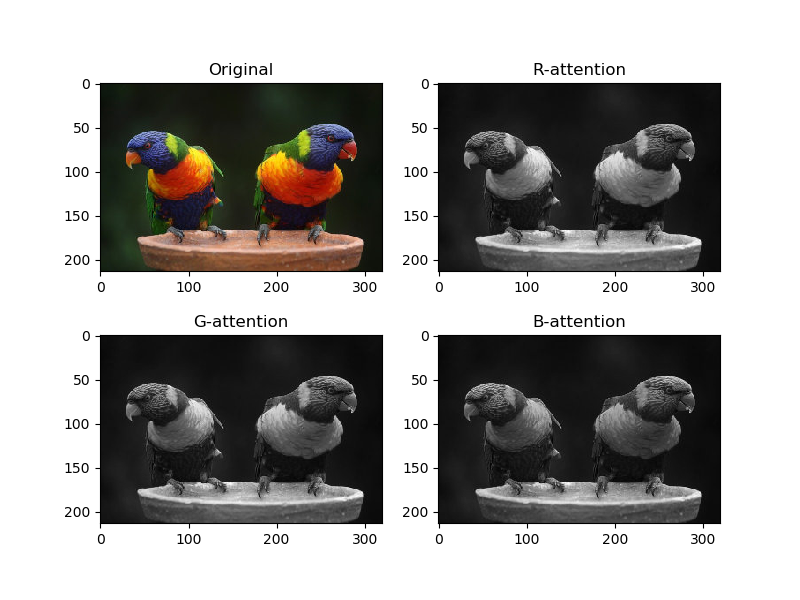
ピクセル値だけよりかはかなりマイルドな特徴量になりましたね。これはSelf Attentionの計算中にグラム行列をとっているためで、Attentionの1ピクセルと、入力画像の1ピクセルが1対1対応ではなくなったからです(広域に見ている)。
このAttentionはRGBでほぼ差がないように見えますが、それでもRのAttentionは鳥の胸やくちばしが強かったり、BのAttentionは頭の部分が強かったりと、オリジナルのカラー配色と対応しているのが確認できます。
Attentionマップによる重み付け(乗数項1)
ここからが本領です。SNGANにおけるSelf attentionは、Attentionで重み付けしたあとにSelf attentionの入力に足す(そのあと非線形関数がくる)という操作をやっているので、広い意味では重み付けと捉えることができます。
そこで非線形関数をエミュレートするために「入力×Attention^定数項」という計算をします。本来のSelf attentionによる重み付けしたあとの値域に制限はありませんが、今は可視化のために出力が0~1である(画像として意味ある出力にする)ために、このような変な計算をします。ここでは定数項は1とします。
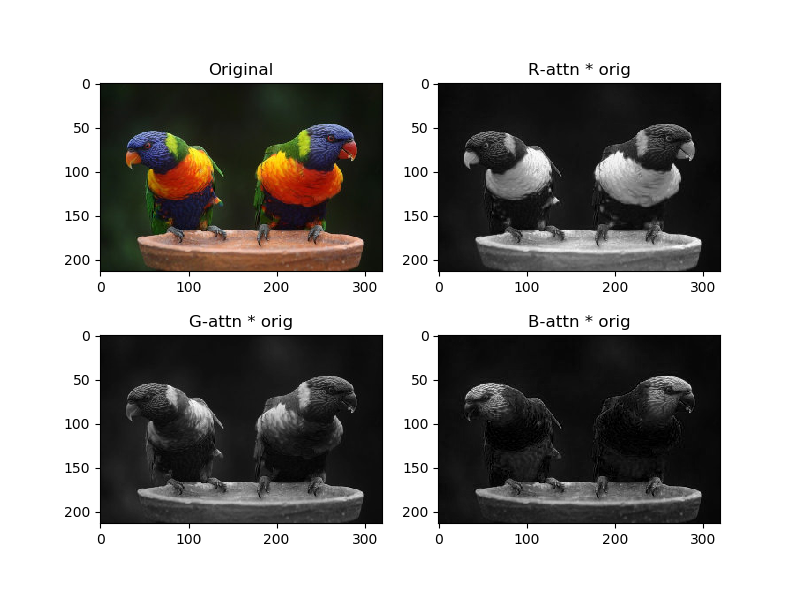
このようになりました。だいぶいわゆるAttentionっぽくなりましたね。純粋にチャンネル単位で強い部分が残る(白になる)ようになっています。
Attentionマップによる重み付け(乗数項5)
さらにAttentionの寄与を強くして、「入力×Attention^5」という計算をします。
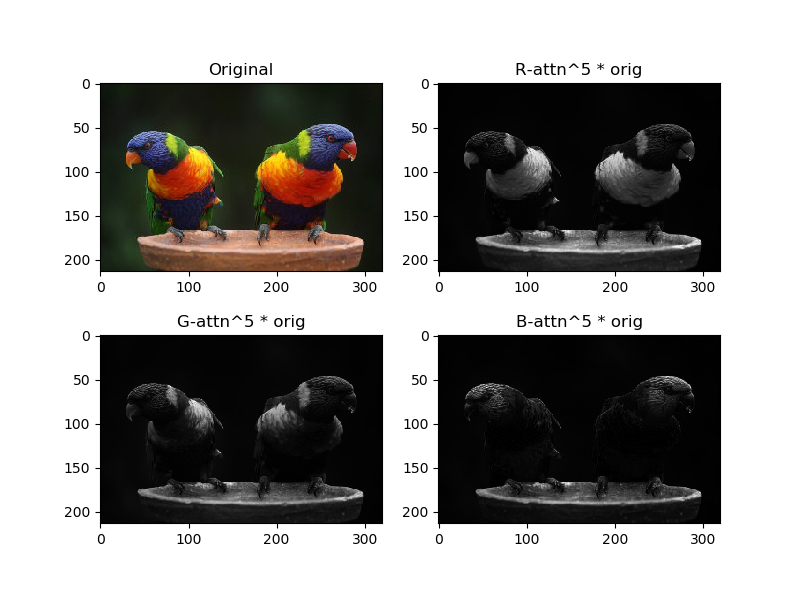
白く光っている部分がより局所的になってきました。これはRGBの強いところを特に強調するという操作になっています。
より一般的にいえば、Attentionの空間(この場合はRGB)に対してその寄与が強いところを集中して重み付けするというのがSelf Attentionのやっていること、とも考えられます。確かにこれなら、生成モデルの出力がよりきれいになったり、分類モデルの精度が上がったりしても「確かにそれはそうだな」と納得できるでしょう。
コード
この部分のコードは次のとおりです。
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
def visualize_self_attention():
with Image.open("rainbow.jpg") as img:
array = np.asarray(img, np.float32) / 255.0
array = np.transpose(array, [2, 0, 1])
array = np.expand_dims(array, axis=0)
with torch.no_grad():
model = SelfAttentionNoWeights()
x = torch.as_tensor(array)
attn = model(x).numpy()
plt.figure(figsize=(8,6))
# channel-wise plot
sub = plt.subplot(2, 2, 1)
sub.imshow(np.transpose(array[0], [1, 2, 0]))
sub.set_title("Original")
for i, t in zip(range(3), ["R", "G", "B"]):
sub = plt.subplot(2, 2, 2 + i)
sub.imshow(array[0, i,:,:], cmap="gray")
sub.set_title(t)
plt.show()
plt.figure(figsize=(8,6))
# attention-plot
sub = plt.subplot(2, 2, 1)
sub.imshow(np.transpose(array[0], [1, 2, 0]))
sub.set_title("Original")
for i, t in zip(range(3), ["R", "G", "B"]):
sub = plt.subplot(2, 2, 2 + i)
sub.imshow(attn[0, i,:,:], cmap="gray")
sub.set_title(t+"-attention")
plt.show()
plt.figure(figsize=(8,6))
# original * attention
sub = plt.subplot(2, 2, 1)
sub.imshow(np.transpose(array[0], [1, 2, 0]))
sub.set_title("Original")
for i, t in zip(range(3), ["R", "G", "B"]):
sub = plt.subplot(2, 2, 2 + i)
sub.imshow(attn[0, i,:,:] * array[0, i,:,:], cmap="gray")
sub.set_title(t+"-attn * orig")
plt.show()
plt.figure(figsize=(8,6))
# original * attention^5 (ちょっとナンセンスかもしれない)
sub = plt.subplot(2, 2, 1)
sub.imshow(np.transpose(array[0], [1, 2, 0]))
sub.set_title("Original")
for i, t in zip(range(3), ["R", "G", "B"]):
sub = plt.subplot(2, 2, 2 + i)
sub.imshow(attn[0, i,:,:]** 5 * array[0, i,:,:], cmap="gray")
sub.set_title(t+"-attn^5 * orig")
plt.show()
まとめ
SNGANにおけるSelf attentionを、PyTorchを使って大まかなイメージを捉えることができました。SNGANの実装時にはSpectral Normなど別の要素が必要になるので、これをベースに実装していけばいいです。他のSelf attentionを使った画像モデルにも応用できるはずです。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー