
TensorFlow2.0でDistributed Trainingをいい感じにやるためのデコレーターを作った


TensorFlow2.0+TPUで訓練していて、いちいちマルチデバイスための訓練・Validationのコード書くの面倒くさいなと思ったので、それをいい感じにラップしてくれるデコレーターを作ってみました。ただ単に「@distributed」とつけるだけで使えます。
目次
作ったもの
from enum import Enum
# Distribute trainingを楽にするためのデコレーター
class Reduction(Enum):
NONE = 0
SUM = 1
MEAN = 2
CONCAT = 3
def distrtibuted(*reduction_flags):
def _decorator(fun):
def per_replica_reduction(z, flag):
if flag == Reduction.NONE:
return z
elif flag == Reduction.SUM:
return strategy.reduce(tf.distribute.ReduceOp.SUM, z, axis=None)
elif flag == Reduction.MEAN:
return strategy.reduce(tf.distribute.ReduceOp.MEAN, z, axis=None)
elif flag == Reduction.CONCAT:
z_list = strategy.experimental_local_results(z)
return tf.concat(z_list, axis=0)
else:
raise NotImplementedError()
@tf.function
def _decorated_fun(*args, **kwargs):
fun_result = strategy.experimental_run_v2(fun, args=args, kwargs=kwargs)
if len(reduction_flags) == 0:
assert fun_result is None
return
elif len(reduction_flags) == 1:
assert type(fun_result) is not tuple and fun_result is not None
return per_replica_reduction(fun_result, *reduction_flags)
else:
assert type(fun_result) is tuple
return tuple((per_replica_reduction(fr, rf) for fr, rf in zip(fun_result, reduction_flags)))
return _decorated_fun
return _decorator
使い方・特徴
train_on_batchやvalidation_on_batchのような訓練ループの中でバッチ単位で訓練・Validationする関数にデコレートします。対象の関数に「@distributed(引数)」とつけるだけで、分散訓練に対応できます。
デコレーターの中身で@tf.functionは入れているので、@distributedを入れればtf.functionはいりません。
また、TF2.0では対応していない、各デバイスのtrain_on_batchでの返り値をconcatして返すという処理も実装してみました。
どのような形になるかというと、
@distributed(Reduce.SUM, Reduce.CONCAT)
def train_on_batch(X, y):
loss = some_calculation(X, y) # 何らかの処理
out = tf.random.normal(shape=(5, 3)) # 何らかの渡したいもの
return loss, out
とすると、lossはデバイス間で和を取り、outはデバイス間でConcat:つまり、デバイス数が8なら(5, 3)を8個積み重ね、(40, 3)という出力になります。損失関数内で計算した値を使いたいときに便利だと思います。
デコレーターを使わない場合
公式ドキュメントに載っているようなやり方です。
import tensorflow as tf
import os
# tpu用
# 詳細 https://www.tensorflow.org/guide/distributed_training#tpustrategy
tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) # TF2.0の場合、ここを追加
tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) # TF2.0の場合、今後experimentialが取れる可能性がある
strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) # ここも同様
from tensorflow.keras import layers
def conv_bn_relu(inputs, ch, reps):
x = inputs
for i in range(reps):
x = layers.Conv2D(ch, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
return x
def create_model():
inputs = layers.Input((32, 32, 3))
x = conv_bn_relu(inputs, 64, 3)
x = layers.AveragePooling2D(2)(x)
x = conv_bn_relu(x, 128, 3)
x = layers.AveragePooling2D(2)(x)
x = conv_bn_relu(x, 256, 3)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(10, activation="softmax")(x)
return tf.keras.models.Model(inputs, x)
def data_augmentation(image):
x = tf.cast(image, tf.float32) / 255.0 # uint8 -> float32
x = tf.image.random_flip_left_right(x) # horizontal flip
x = tf.pad(x, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") # pad 2 (outsize:36x36)
# 黒い領域を作らないようにReflect padとしている(KerasのImageDataGeneratorと同じ)
x = tf.image.random_crop(x, size=[32, 32, 3]) # random crop (outsize:32xx32)
return x
def load_dataset(batch_size):
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.map(
lambda image, label: (data_augmentation(image), tf.cast(label, tf.float32))
).shuffle(buffer_size=50000).batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.map(
lambda image, label: (tf.cast(image, tf.float32) / 255.0, tf.cast(label, tf.float32))
).batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return trainset, testset
def main():
batch_size = 128
trainset, valset = load_dataset(batch_size)
with strategy.scope():
model = create_model()
optim = tf.keras.optimizers.SGD(0.1, momentum=0.9)
loss_func = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
acc = tf.keras.metrics.SparseCategoricalAccuracy()
trainset = strategy.experimental_distribute_dataset(trainset)
valset = strategy.experimental_distribute_dataset(valset)
def train_on_batch(X, y_true):
with tf.GradientTape() as tape:
y_pred = model(X, training=True)
loss = tf.reduce_sum(loss_func(y_true, y_pred), keepdims=True) * (1.0 / batch_size)
gradient = tape.gradient(loss, model.trainable_weights)
optim.apply_gradients(zip(gradient, model.trainable_weights))
acc.update_state(y_true, y_pred)
return loss
@tf.function
def distributed_train_on_batch(X, y):
per_replica_losses = strategy.experimental_run_v2(train_on_batch, args=(X, y))
return strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses, axis=None)
def validation_on_batch(X, y_true):
y_pred = model(X, training=False)
acc.update_state(y_true, y_pred)
@tf.function
def distributed_validation_on_batch(X, y):
return strategy.experimental_run_v2(validation_on_batch, args=(X, y))
for i in range(5):
acc.reset_states()
print("Epoch = ", i)
for X, y in trainset:
distributed_train_on_batch(X, y)
train_acc = acc.result().numpy()
acc.reset_states()
for X, y in valset:
distributed_validation_on_batch(X, y)
print(f"Train acc = {train_acc}, Validation acc = {acc.result().numpy()}")
if __name__ == "__main__":
main()
これはまぁ悪くはないですが、やはりdistribued用の関数を定義するのが冗長な気がします。
Epoch = 0
Train acc = 0.24135999381542206, Validation acc = 0.12530000507831573
Epoch = 1
Train acc = 0.3626999855041504, Validation acc = 0.287200003862381
Epoch = 2
Train acc = 0.4607999920845032, Validation acc = 0.32600000500679016
Epoch = 3
Train acc = 0.5678600072860718, Validation acc = 0.5971999764442444
Epoch = 4
Train acc = 0.6450600028038025, Validation acc = 0.5734999775886536
デコレーターを使う場合
このデコレーターを使う場合はこちら。大きいプロジェクトになった場合は、デコレーターとEnumは別ファイルにおいておきimportすればいいですね。デコレーター自体は処理に依存しないのでコピペすればいいので。
import tensorflow as tf
import os
# tpu用
# 詳細 https://www.tensorflow.org/guide/distributed_training#tpustrategy
tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) # TF2.0の場合、ここを追加
tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) # TF2.0の場合、今後experimentialが取れる可能性がある
strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) # ここも同様
from tensorflow.keras import layers
from enum import Enum
import matplotlib.pyplot as plt
import numpy as np
def conv_bn_relu(inputs, ch, reps):
x = inputs
for i in range(reps):
x = layers.Conv2D(ch, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
return x
def create_model():
inputs = layers.Input((32, 32, 3))
x = conv_bn_relu(inputs, 64, 3)
x = layers.AveragePooling2D(2)(x)
x = conv_bn_relu(x, 128, 3)
x = layers.AveragePooling2D(2)(x)
x = conv_bn_relu(x, 256, 3)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(10, activation="softmax")(x)
return tf.keras.models.Model(inputs, x)
def data_augmentation(image):
x = tf.cast(image, tf.float32) / 255.0 # uint8 -> float32
x = tf.image.random_flip_left_right(x) # horizontal flip
x = tf.pad(x, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") # pad 2 (outsize:36x36)
# 黒い領域を作らないようにReflect padとしている(KerasのImageDataGeneratorと同じ)
x = tf.image.random_crop(x, size=[32, 32, 3]) # random crop (outsize:32xx32)
return x
def load_dataset(batch_size):
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.map(
lambda image, label: (data_augmentation(image), tf.cast(label, tf.float32))
).shuffle(buffer_size=50000).batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.map(
lambda image, label: (tf.cast(image, tf.float32) / 255.0, tf.cast(label, tf.float32))
).batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return trainset, testset
# Distribute trainingを楽にするためのデコレーター
class Reduction(Enum):
NONE = 0
SUM = 1
MEAN = 2
CONCAT = 3
def distrtibuted(*reduction_flags):
def _decorator(fun):
def per_replica_reduction(z, flag):
if flag == Reduction.NONE:
return z
elif flag == Reduction.SUM:
return strategy.reduce(tf.distribute.ReduceOp.SUM, z, axis=None)
elif flag == Reduction.MEAN:
return strategy.reduce(tf.distribute.ReduceOp.MEAN, z, axis=None)
elif flag == Reduction.CONCAT:
z_list = strategy.experimental_local_results(z)
return tf.concat(z_list, axis=0)
else:
raise NotImplementedError()
@tf.function
def _decorated_fun(*args, **kwargs):
fun_result = strategy.experimental_run_v2(fun, args=args, kwargs=kwargs)
if len(reduction_flags) == 0:
assert fun_result is None
return
elif len(reduction_flags) == 1:
assert type(fun_result) is not tuple and fun_result is not None
return per_replica_reduction(fun_result, *reduction_flags)
else:
assert type(fun_result) is tuple
return tuple((per_replica_reduction(fr, rf) for fr, rf in zip(fun_result, reduction_flags)))
return _decorated_fun
return _decorator
def main():
batch_size = 128
trainset, valset = load_dataset(batch_size)
with strategy.scope():
model = create_model()
optim = tf.keras.optimizers.SGD(0.1, momentum=0.9)
loss_func = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
acc = tf.keras.metrics.SparseCategoricalAccuracy()
# distributedのデコレーターをつければいい感じにできるようになる(引数はどのようにReduceするか)
@distrtibuted()
def train_on_batch(X, y_true):
with tf.GradientTape() as tape:
y_pred = model(X, training=True)
loss = tf.reduce_sum(loss_func(y_true, y_pred), keepdims=True) * (1.0 / batch_size)
gradient = tape.gradient(loss, model.trainable_weights)
optim.apply_gradients(zip(gradient, model.trainable_weights))
acc.update_state(y_true, y_pred)
@distrtibuted(Reduction.CONCAT, Reduction.CONCAT)
def validation_on_batch(X, y_true):
y_pred = model(X, training=False)
acc.update_state(y_true, y_pred)
return X, y_pred
for i in range(5):
acc.reset_states()
print("Epoch = ", i)
for X, y in trainset:
train_on_batch(X, y)
train_acc = acc.result().numpy()
acc.reset_states()
for X, y in valset:
img, y_pred = validation_on_batch(X, y)
print(f"Train acc = {train_acc}, Validation acc = {acc.result().numpy()}")
print(img.shape) # (batch_size, 32, 32, 3)
print(y_pred.shape) # (batch_size, 10)
# plot image + prediction
classname = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "trunk"]
fig = plt.figure(figsize=(16, 16))
for i in range(6):
# image
ax = fig.add_subplot(6, 4, 4 * i + 1)
ax.imshow(img[i])
ax.axis("off")
# prediction
ax = plt.subplot2grid((6, 4), (i, 1), colspan=3, fig=fig)
ax.bar(np.arange(len(classname)), y_pred[i,], tick_label=classname)
fig.savefig("prediction.png")
fig.show()
if __name__ == "__main__":
main()
この例では少しコードが長くなってしまいましたが、大きめのプロジェクトになったときに便利だと思います。最初の例ではできなかったこんなプロットもできます。
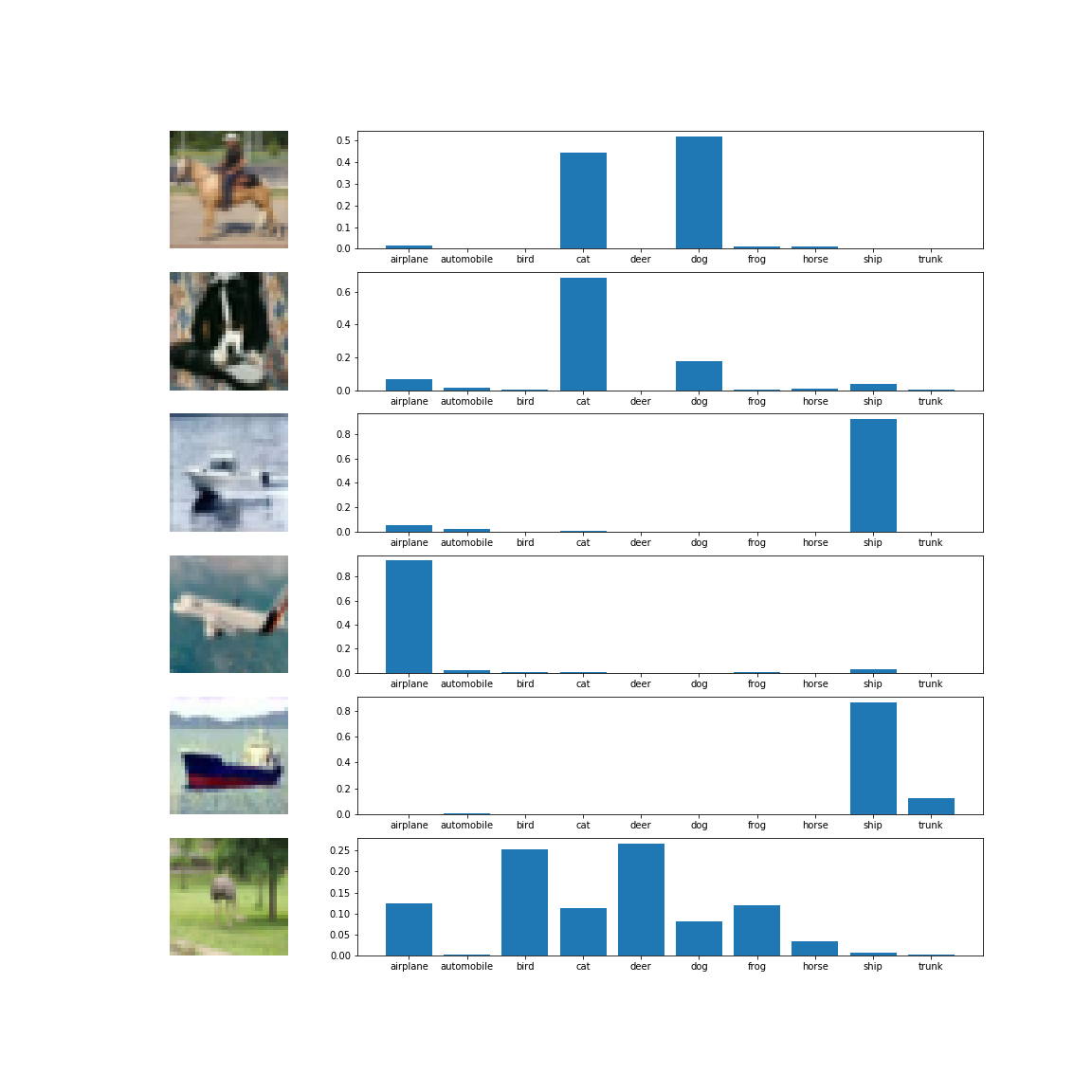
各画像とクラス別の予測確率のプロットです。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー