
論文まとめ:Has GPT-5 Achieved Spatial Intelligence? An Empirical Study


- タイトル:Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
- 著者:Zhongang Cai, Yubo Wang, Qingping Sun, Ruisi Wang, Chenyang Gu, Wanqi Yin, Zhiqian Lin, Zhitao Yang, Chen Wei, Xuanke Shi, Kewang Deng, Xiaoyang Han, Zukai Chen, Jiaqi Li, Xiangyu Fan, Hanming Deng, Lewei Lu, Bo Li, Ziwei Liu, Quan Wang, Dahua Lin, Lei Yang
- 論文URL:https://arxiv.org/abs/2508.13142
目次
Gemini 2.5 要約
・この論文において解決したい課題は何?
マルチモーダルモデル(特にGPT-5)の空間認識能力を評価し、人工汎用知能(AGI)達成に向けた課題を特定すること。
・先行研究だとどういう点が課題だった?
既存のベンチマークはタスクの種類や評価方法が統一されておらず、モデル間の公平な比較が困難だった。また、空間認識能力に特化した評価が不足していた。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
空間知能を評価するための包括的なタスク分類を提案し、既存のベンチマークを統合。GPT-5を含む最先端モデルを統一された評価基準で比較し、空間認識における強みと弱みを明らかにした。
・提案手法の手法を初心者でもわかるように詳細に説明して
1. タスク分類: 空間認識に必要な能力を6つ(距離測定、心的再構成、空間関係、視点変換、変形と組み立て、包括的推論)に分類。
2. ベンチマーク選択: 既存の8つの主要な空間認識ベンチマークを選択。
3. 評価プロトコル統一: 評価指標、プロンプト、回答形式を統一し、公平な比較を可能にした。
4. モデル評価: GPT-5などのモデルを選択したベンチマークで評価し、結果を分析。
・提案手法の有効性をどのように定量・定性評価した?
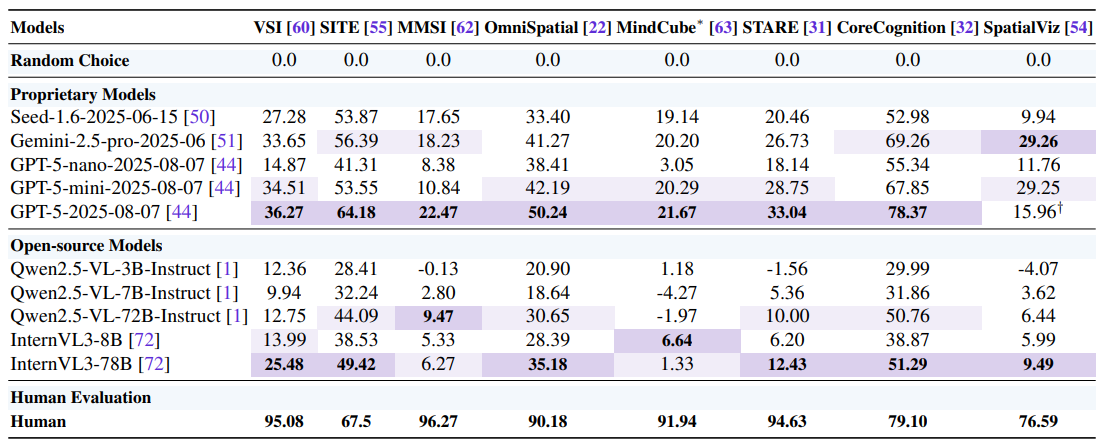
定量評価では、Chance-Adjusted Accuracy (CAA)などの指標を用いて、複数のベンチマークでモデルの性能を比較。定性評価では、具体的な事例を取り上げ、モデルの推論過程を分析し、強みと弱みを詳細に評価した。
・この論文における限界は?
GPT-5の性能は向上しているものの、人間レベルの空間認識能力にはまだ及ばない。特に、心的再構成、視点変換、変形と組み立て、包括的推論のタスクにおいて課題が残る。
・次に読むべき論文は?
論文中で引用されている以下の論文などが参考になるでしょう。特に、空間認識に関するベンチマークや、マルチモーダルモデルの空間認識能力に関する研究がおすすめです。
- VSI-Bench [60]
- SITE [55]
- MMSI [62]
- OmniSpatial [22]
- MindCube [63]
- STARE [31]
- CoreCognition [32]
- SpatialViz [54]
・論文中にコードが提示されていれば、それをリンク付きで示してください
論文中に直接コードは提示されていませんが、以下のツールキットが評価に使用されています。
- VLMEvalKit: https://github.com/EvolvingLMMs-Lab/lmms-eval
- LMMS-Eval: https://github.com/EvolvingLMMs-Lab/lmms-eval
これらのツールキットは、大規模マルチモーダルモデルの評価を支援するためのもので、関連するコードやリソースが含まれている可能性があります。
補足
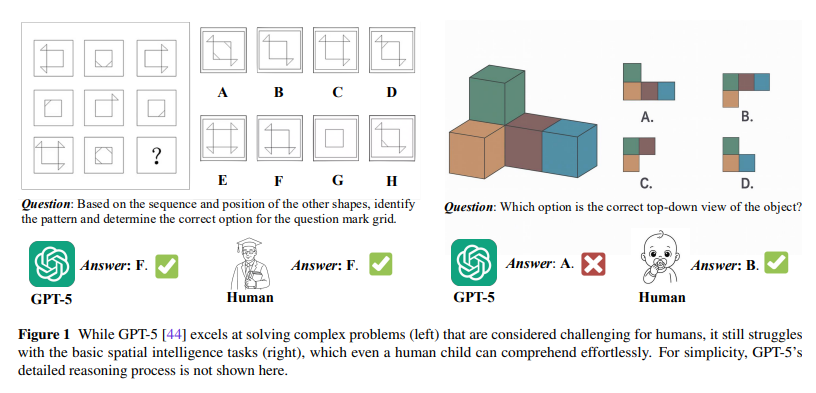
LLMは空間認知弱いぜ
こういう空間認知系のタスクはまだまだLLMは弱い。赤ちゃんレベルの問いも間違う
6つの基本能力
空間認知のタスクについて6つの基本的能力を定義した。
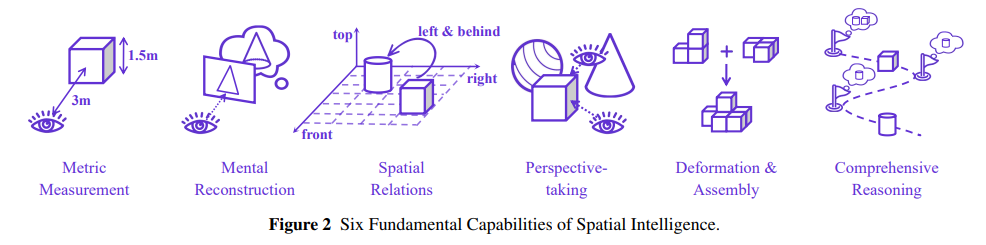
- メートル法測定 (Metric Measurement: MM): 2D観察から3D寸法(奥行きや長さ)を推論する能力。
- 精神的再構築 (Mental Reconstruction: MR): 限られた2D観察から完全な3D構造を推論し、仮想的な操作を行う能力。
- 空間関係 (Spatial Relations: SR): カメラビュー内における複数のオブジェクトの相対的な位置と向きを理解する能力。
- 視点取得 (Perspective-taking: PT): 異なる視点間での推論を行う能力。
- 変形と組み立て (Deformation and Assembly: DA): 変形や構造的変化を理解し、推論する能力(例:2D展開図からの3Dキューブ組み立て)。
- 包括的推論 (Comprehensive Reasoning: CR): 拡張された記憶と多段階の推論と共に、様々な空間能力を連携させて使用する能力。
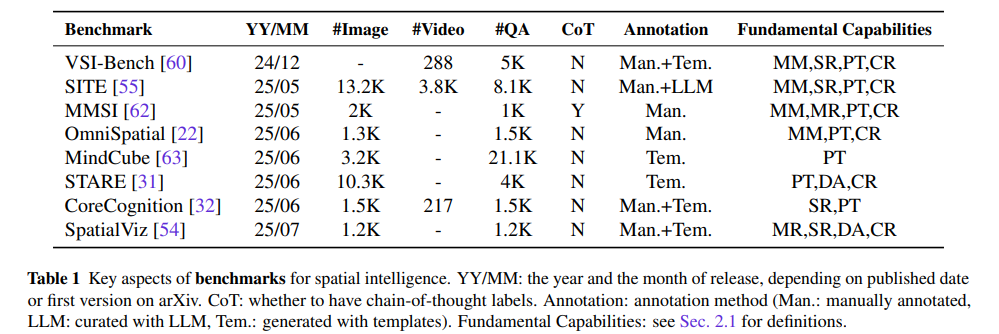
既存の8個のデータセットに対して、「8個のデータセットのうち、このデータセットはこの能力を持っている」というように、各ベンチマーク(またはそのサブカテゴリ)が本来持っている評価対象を、研究者が提示する統一されたフレームワークに沿って人為的に(解釈的に)分類し直したもの(ちょっとここは残念)
教師データは各データセットのものを活用し、以下の3パターンがある。
- 手動アノテーション (Manually annotated: Man.): 人間が直接アノテーションしたデータです。例:MMSI。
- LLMによるキュレーション (Curated with LLM: LLM): 大規模言語モデル(LLM)によってキュレーションされたデータです。例:SITE。
- テンプレート生成 (Generated with Templates: Tem.): 特定のテンプレートに基づいて生成されたデータです。例:MindCube、STARE
評価プロトコルの標準化
- 評価プロトコルの標準化:
- 評価結果がモデル能力以外の要因に大きく左右される可能性があるため、正確性と公平性を確保するために、評価プロトコルを標準化しました。
- 統一されたシステムプロンプトの採用:
- システムプロンプトがモデルのパフォーマンスに大きく影響することが知られているため、各ベンチマークで異なるプロンプトが使用されている問題を解決しました。
- モデルの空間推論能力を最大限に引き出すため、OmniSpatial で採用されているゼロショットChain-of-Thought(CoT)アプローチを使用しました。CoT推論はDirect QAよりも優れていることが観測されています。
- 回答の一貫性と正確な抽出を保証するため、SpatialViz からインスピレーションを得た回答テンプレート(例:回答を
と タグで囲む形式)を組み込みました。 - 回答照合方法の標準化:
- 回答照合方法のばらつきが評価の一貫性を損なうため、VLMEvalKit および LMMS-Eval のベストプラクティスに従い、3段階の照合プロセスを採用しました。
- これには、1) 初期のルールベース照合(
タグ内の回答抽出)、2) 拡張ルールベース照合(追加のパターンによる抽出)、3) LLM支援抽出(ルールベースで失敗した場合のLLMによる抽出)が含まれます。
- 評価指標の標準化:
- 複数選択問題(MCQ)には、ランダムな推測の影響を排除するためにChance-Adjusted Accuracy (CAA) を採用し、数値回答(NA)にはVSI-Bench で使用されているMean Relative Accuracy (MRA) を採用しました。
- また、Accuracy (Acc) や F1 スコア (F1) など、ベンチマーク元の論文に合わせた詳細な指標も報告されています。
- 円環評価戦略(Circular Evaluation)の導入:
- オプションの位置によるバイアスを減らすために、円環評価戦略 を採用しました。
- これにより、複数選択問題は可能な回答オプションを毎回入れ替えて複数回提示され、モデルが真にタスクを理解しているかを厳密に測定します。ただし、計算コストの増大から、主に標準(非円環)方式が採用され、一部の代表的なベンチマークにのみ円環評価が適用されました。

Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー