
論文まとめ:Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling


- タイトル:Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
- 著者:DeepSeek-AIの方々
- 論文URL:https://arxiv.org/abs/2501.17811
- GitHub:https://github.com/deepseek-ai/Janus
目次
関連記事
論文要約By Gemini 1.5 Pro
・この論文において解決したい課題は何?
マルチモーダル理解と生成の両方を高いレベルで実行できる単一モデルの性能向上、特に短いプロンプトでの画像生成の安定性と生成品質の向上。
・先行研究だとどういう点が課題だった?
先行研究であるJanusは、マルチモーダル理解と生成の両方に同じビジュアルエンコーダーを使用していたため、両方のタスクに最適な表現を得ることが難しく、特に短いプロンプトでの画像生成性能と安定性に課題があった。また、学習データの量とモデルサイズも限定的だった。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
提案手法Janus-Proは、Janusの学習戦略、データ、モデルサイズを改善することで、マルチモーダル理解と生成の性能を大幅に向上させた。具体的には、3段階の学習における各段階のデータと学習ステップ数を調整し、学習データ量を増加させ、モデルサイズを大きくすることで、短いプロンプトでの画像生成の安定性と品質、そしてマルチモーダル理解能力を向上させた。
・提案手法の手法を初心者でもわかるように詳細に説明して
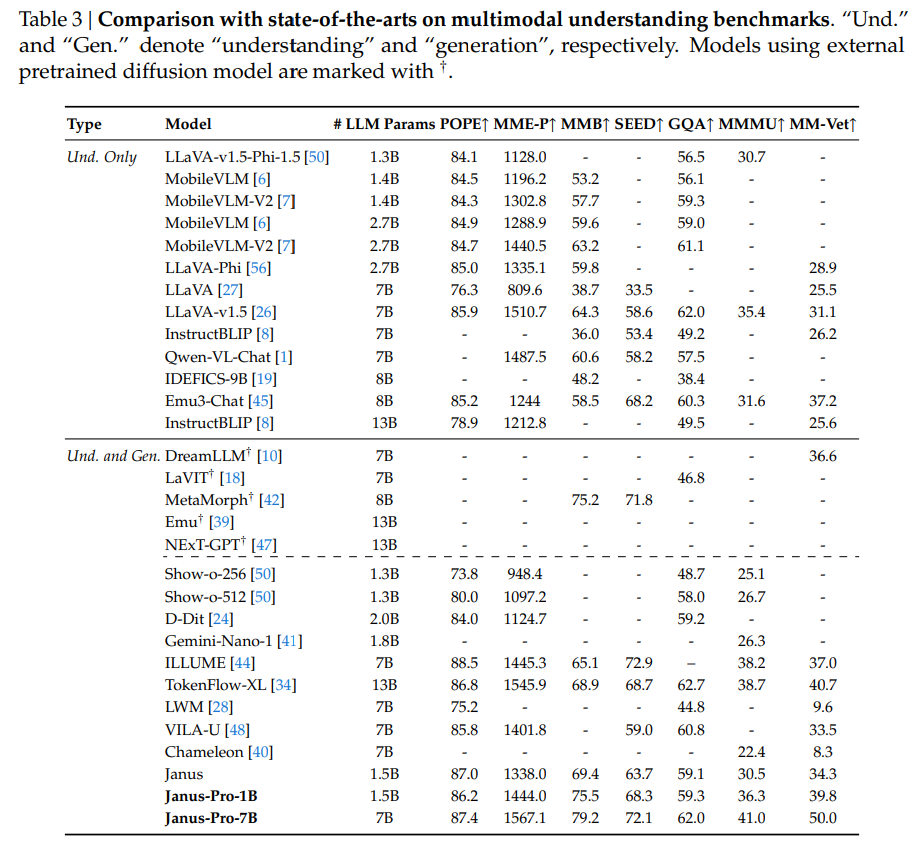
Janus-Proは、理解タスクと生成タスクで別々のビジュアルエンコーダーを使うことで、両方のタスクを高性能でこなせるように設計されています。
理解タスク:画像の意味を理解するためにSigLIPエンコーダーを使います。これは画像の特徴を抽出し、言語モデルが入力として理解できる形に変換します。
生成タスク:VQトークナイザーを使って画像を個別のIDに変換します。これらのIDに対応する埋め込み表現は、言語モデルの入力空間へ変換されます。
言語モデル:前処理された画像情報とテキスト情報は、単一の言語モデル(DeepSeek-LLM)に入力されます。この言語モデルは、理解タスクでは画像に関する質問に答え、生成タスクではテキストに基づいて画像を生成します。
画像デコーダー:生成タスクでは、言語モデルの出力が画像デコーダーに送られ、最終的な画像が生成されます。
学習は3段階で行われます。
ステージ1:アダプターと画像生成ヘッドを学習します。
ステージ2:統一事前学習を行い、理解エンコーダーと生成エンコーダーを除く全てのコンポーネントのパラメータを更新します。
ステージ3:ステージ2に基づいて教師ありファインチューニングを行い、理解エンコーダーのパラメータも更新します。
・提案手法の有効性をどのように定量・定性評価した?
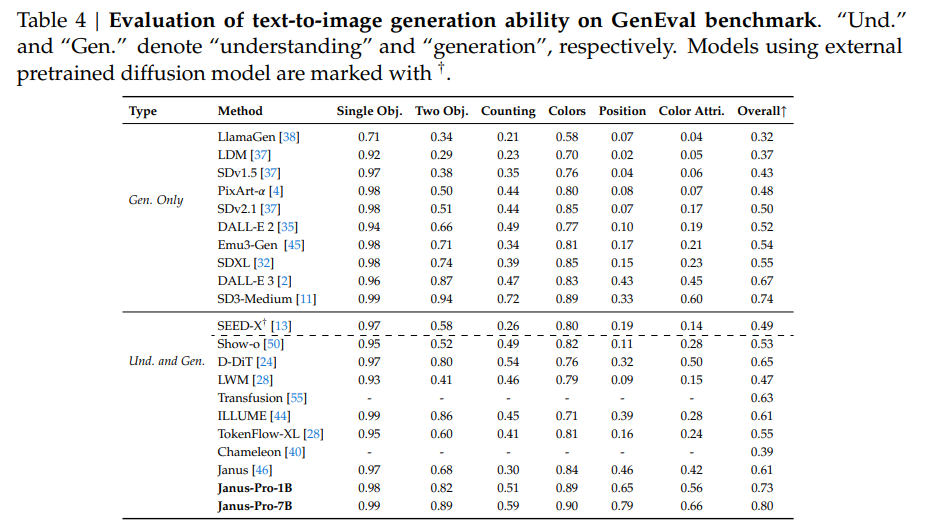
マルチモーダル理解タスクでは、GQA、POPE、MME、SEED、MMB、MM-Vet、MMMUといったベンチマークで評価し、先行研究や他のモデルと比較しました。
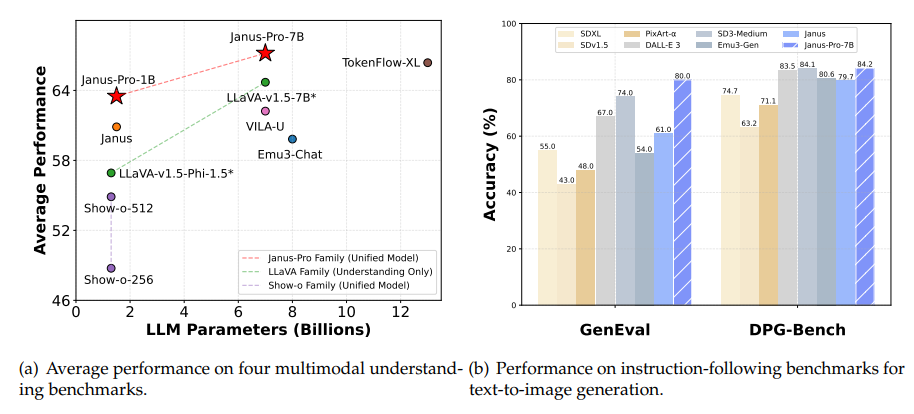
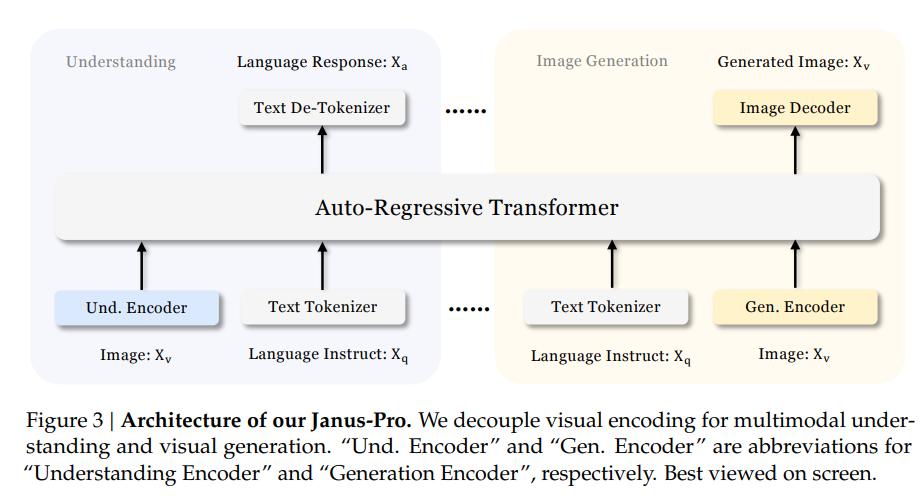
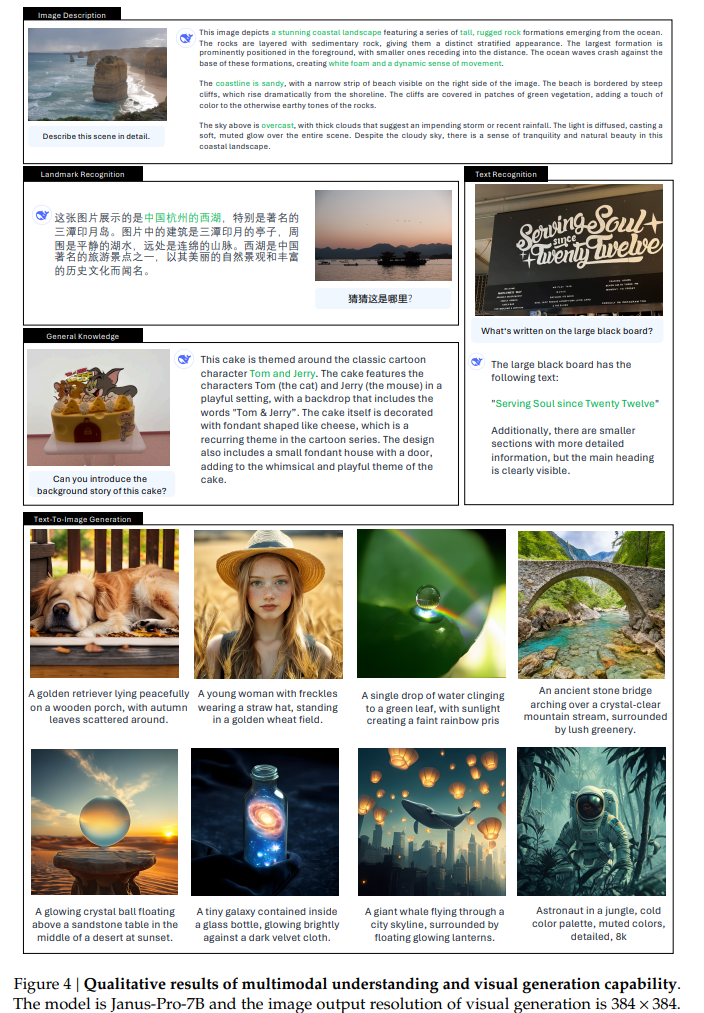
画像生成タスクでは、GenEvalとDPG-Benchを用いて評価し、生成された画像の品質とプロンプトへの適合性を検証しました。また、図4に示すように、定性的な結果も示し、生成された画像の品質を視覚的に確認しました。
・この論文における限界は?
入力画像の解像度が384×384に制限されているため、OCRなどの細かいタスク性能が影響を受ける。また、生成される画像の解像度も低く、細かいディテールが欠けている。
・次に読むべき論文は?
論文中で比較対象として挙げられている、Janus [46]、TokenFlow [34]、MetaMorph [42]、Emu3 [45]、LLaVA [27] など。特に、Janus[46] (https://arxiv.org/abs/2410.13848) は、Janus-Proのベースとなっている論文なので、まず読むべきでしょう。コードはhttps://github.com/deepseek-ai/Janus にあります。
補足
学習戦略
- ステージ1:ImageNetのデータで他で十分。ただ長く学習する
- ステージ2:Text2Imageで学習。密なキャプションで学習
- 学習データセットの比率を変更し、マルチモーダルの理解能力の向上を達成しつつ、強力な画像生成能力を維持することが可能
- 以前 Image to Text:Text to Text:Text 2 Image = 7 : 3 : 10
- 提案 Image to Text:Text to Text:Text 2 Image = 5 : 1 : 4
データのスケーリング
- マルチモーダル理解(Image to Text)
- ステージ2の事前学習データは、DeepSeekVL2を参照して9000万サンプルを追加。YFCCのようなキャプションデータ、表、グラフ、文章理解のデータを含む
- ステージ3のSFTデータでは、ミーム理解、中国語会話データ、対話体験の向上を目的としたデータセット
- 視覚生成(Text to image)
- Janusの古いバージョンは実世界のデータだった。これは品質に欠け、大きなノイズを含んでいる。不安定性につながる
- Janus-Proでは7200万サンプルの合成美学データを組み込む。安定性と品質の向上
- このプロンプトはMidjourney prompt dataset
- 訳注:どこからサンプルしたかは書いていない
訓練時間
- 1.5B/7Bモデル、各モデルは8台のNvidia A100(40GB)GPUを搭載し、16/32ノードのクラスタで約9/14日間の学習を行った
所感
- 自己回帰でInputもOutputもマルチモーダルにしちゃえば性能出るよというのはわかる。2個Vision Encoder入れたというのは、理解と生成で必要な情報粒度が違うのでなんとなく理解できるが、ここはもともとのEncoderからSkip Connectionを入れてしまうのでもいいのではないか
- 画像生成のデータセットについて合成した(プロンプトでサンプリングした)というが、ここで使われたモデルが何なのかこれに尽きると思う。なぜここを明示しなかったのか、開示すると都合が悪いことでもあったのか
- LLMできたからとりあえずやってみた程度という印象な論文
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー