
AWS LambdaからS3の大容量ファイルを大量並列でダウンロードする検証


LambdaでS3から1GBファイルを同時にダウンロードしても、同時実行数を500まで増やしても通信帯域はほとんどボトルネックにならず、高いスループットを維持できることが確認された。MLモデルなど大きなファイルをLambda外部に置く構成でも十分に高速かつ安定してアクセスできるため、並列時の帯域不足を過度に心配する必要はないとわかった。
目次
はじめに
- Lambdaに収まらないでかいファイルを、S3に(例:MLモデル)おいておいて、実行時にダウンロードするということがよくある
- Lambdaの実行が単一のときのスループットは非常によく調べられているが、10並列、50並列、100並列……とLambdaが大量に並列実行されているときのスループットはあまり調べられていない。AWSもこの帯域は公開していない。
- 大量に実行したときにS3→Lambda間の通信にボトルネックが発生するのではないかと思って調べてみた
関連
Lambdaが1個のときの実験が多い。100並列などは見た限りだとなかった。
- LambdaがS3からGetObjectするのにかかる時間を計測してみた [追記, 修正あり]
- Lambdaでファイルのダウンロード速度をEFSとS3で比較してみた
- [アップデート] Lambda から共有ファイルストレージの EFS が利用可能になりました!
実験
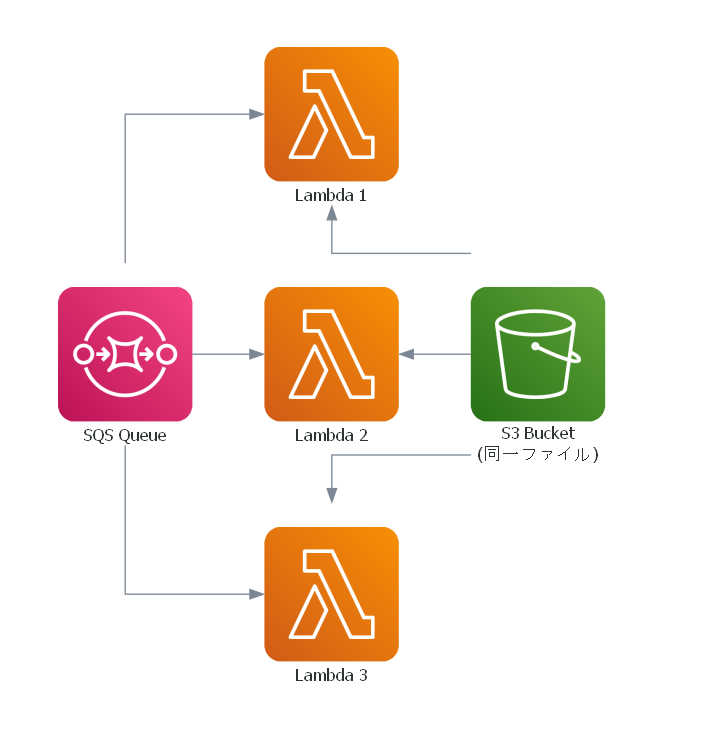
以下のアーキテクチャーで実験する。
- Lambdaの同時実行数をコントロールするため、「予約済み同時実行数」を設定する
- LambdaをSQSから実行するアーキテクチャーにする。つまり、SQSにかなり大量のメッセージを送れば(例:予約済み同時実行数が100のとき、SQSへの送信キュー数は1000)、予約済み同時実行数ぶんの並列同時実行を実現できるというものになる。
- S3には1GBの単一ファイルをおき、全てのLambdaがそのファイルをダウンロードする。本質的には並列アクセスすると速度が落ちやすいシチュエーション。
- 各Lambda内でダウンロード時間を計測し、CloudWatch Logsに吐き出す
- CloudWatch Logs Insightsで集計する
集計時
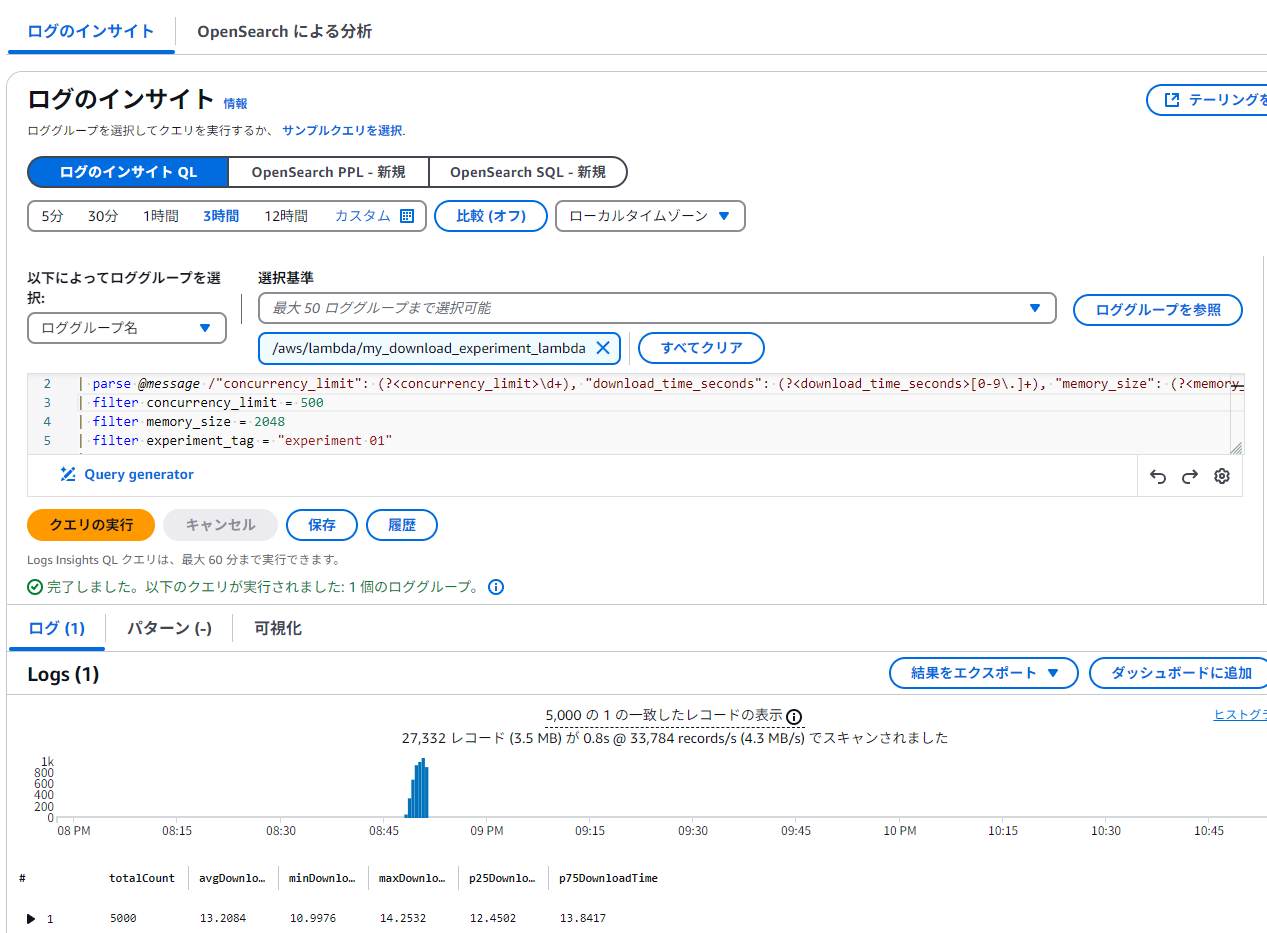
CloudWatch Logsで以下のようなログが出されたとする。
{"concurrency_limit": 1, "download_time_seconds": 12.380369424819946, "memory_size": 1024, "experiment_tag": "experiment 01"}
ここで、
concurrency_limit:予約済み同時実行数。環境変数に登録しておくdownload_time_seconds:S3からのファイルダウンロード所要時間memory_size:Lambdaのメモリサイズ。メモリサイズが少なすぎると速度が出ないこと、1024MB、2048MBぐらいからはサチりやすいということが報告されている。experiment_tag:実験のタグ。最初にデバッグで実行したときを除外する用
このとき、以下のようなCloudWatch Logs Insightsのクエリで集計できる
fields @timestamp, @message
| parse @message /"concurrency_limit": (?<concurrency_limit>\d+), "download_time_seconds": (?<download_time_seconds>[0-9\.]+), "memory_size": (?<memory_size>\d+), "experiment_tag": "(?<experiment_tag>[^"]+)"/
| filter concurrency_limit = 1
| filter memory_size = 1024
| filter experiment_tag = "experiment 01"
| stats
count() as totalCount,
avg(download_time_seconds) as avgDownloadTime,
min(download_time_seconds) as minDownloadTime,
max(download_time_seconds) as maxDownloadTime,
pct(download_time_seconds, 25) as p25DownloadTime,
pct(download_time_seconds, 75) as p75DownloadTime
このように結果が出てくる。CSVでクリップボードにコピペできるので実験向きかと思う。
実験
予約済み同時実行数、Lambdaのメモリを以下のように変化させる。
- 予約済み同時実行数:1, 5, 10, 50, 100, 500
- Lambdaのメモリ:1024MB, 2048MB
- SQSへの送信数は「予約済み同時実行数×10」。つまり、予約済み同時実行数が50ならSQSに500メッセージを一気に送る。
ダウンロードするファイルは、ddコマンドで作ったピッタリ1GBのファイルをaws s3 cpでアップロード。
結果
ダウンロード時間
各条件のダウンロード時間を、最小値、25%値、平均値、75%値、最大値で比較する。
| メモリサイズ | 同時実行数 | minDlTime | p25DlTime | avgDlTime | p75DlTime | maxDlTime |
|---|---|---|---|---|---|---|
| 1024 | 1 | 12.04 | 12.16 | 12.67 | 13.31 | 13.74 |
| 1024 | 5 | 12.07 | 12.18 | 12.86 | 13.53 | 13.86 |
| 1024 | 10 | 11.97 | 12.16 | 12.94 | 13.59 | 13.93 |
| 1024 | 50 | 11.97 | 12.23 | 12.97 | 13.66 | 14.07 |
| 1024 | 100 | 11.78 | 12.35 | 13.10 | 13.70 | 14.17 |
| 1024 | 500 | 11.81 | 12.50 | 13.24 | 13.76 | 14.93 |
| 2048 | 1 | 11.24 | 12.16 | 12.67 | 13.43 | 13.75 |
| 2048 | 5 | 11.10 | 12.08 | 12.72 | 13.47 | 13.92 |
| 2048 | 10 | 11.08 | 12.16 | 12.89 | 13.66 | 14.17 |
| 2048 | 50 | 11.13 | 12.18 | 12.84 | 13.72 | 14.11 |
| 2048 | 100 | 11.08 | 12.13 | 12.67 | 13.66 | 14.09 |
| 2048 | 500 | 11.00 | 12.45 | 13.21 | 13.84 | 14.25 |
驚くことに、500並列まで上げてもそこまでダウンロード速度が落ちていない。若干落ちてはいるものの、CloudWatch Logs側のボトルネックである説もある。全てのLambdaがS3から同時に一個のファイルをダウンロードするという極端な設定なのにこれはすごい。
速度
上の表の値を速度に変換したのがこちら。各列の値を順位逆転させて、速度変換(1024×8÷時間)表示したもの。速度の正確な四分位値や平均値ではないのは注意。単位はMbps
| メモリサイズ | 同時実行数 | minMbps | p25Mbps | avgMbps | p75Mbps | maxMbps |
|---|---|---|---|---|---|---|
| 1024 | 1 | 596.1 | 615.3 | 646.7 | 673.6 | 680.2 |
| 1024 | 5 | 591.2 | 605.4 | 636.9 | 672.8 | 679.0 |
| 1024 | 10 | 588.2 | 602.6 | 632.9 | 674.0 | 684.5 |
| 1024 | 50 | 582.4 | 599.6 | 631.5 | 669.9 | 684.6 |
| 1024 | 100 | 578.3 | 597.8 | 625.4 | 663.3 | 695.3 |
| 1024 | 500 | 548.8 | 595.4 | 618.8 | 655.4 | 693.5 |
| 2048 | 1 | 595.6 | 610.1 | 646.5 | 673.7 | 728.9 |
| 2048 | 5 | 588.5 | 608.1 | 643.9 | 677.9 | 738.3 |
| 2048 | 10 | 578.3 | 599.6 | 635.7 | 674.0 | 739.6 |
| 2048 | 50 | 580.5 | 597.2 | 638.1 | 672.6 | 735.8 |
| 2048 | 100 | 581.5 | 599.6 | 646.6 | 675.3 | 739.4 |
| 2048 | 500 | 574.7 | 591.8 | 620.2 | 658.0 | 744.9 |
500並列させても600Mbps安定して出ているのはすごいな。
結論
- S3とLambdaの可用性はやばい。相当並列させてもほとんど通信面がボトルネックにならない。なので、MLモデルみたいにLambdaに入らない大きなファイルはS3にどんどんオフロードしてOKで、「100連で実行されたら通信帯域やばいんじゃ」みたいな心配はしなくてOK
- この理由の想像であるが、S3はもともと可用性がめちゃくちゃ高い、それにLambdaはどのインスタンスで実行されているかが選べないため、自然と分散されているのではないか。だからこんなに負荷かけても通信が分散されると思う。
- EFSからのダウンロードだともっと極端に落ちると思う。
コード
Terraform
以下のTerraformでデプロイ
variable "s3_bucket_name" {
description = "S3バケットの名前"
type = string
}
variable "s3_file_name" {
description = "Lambda内でダウンロードするS3ファイル名"
type = string
default = "sample_large_file.dat"
}
variable "memory_size" {
description = "Lambdaのメモリサイズ"
type = number
default = 2048
}
variable "experiment_tag" {
description = "実験タグ"
type = string
default = "experiment 01"
}
variable "concurrency_value" {
description = "Lambdaの同時実行数の制限値"
type = number
default = 1
}
# SQS キューの作成
resource "aws_sqs_queue" "my_queue" {
name = "my_experiment_queue"
visibility_timeout_seconds = 120
}
# S3バケットの作成
resource "aws_s3_bucket" "my_bucket" {
bucket = var.s3_bucket_name
force_destroy = true
}
# IAM ロールの作成:Lambdaに必要な権限を付与
resource "aws_iam_role" "lambda_role" {
name = "download_lambda_execution_role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "lambda.amazonaws.com"
}
}]
})
}
# Lambda用のIAMポリシーをアタッチ
resource "aws_iam_role_policy" "lambda_policy" {
name = "lambda_policy"
role = aws_iam_role.lambda_role.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
]
Effect = "Allow"
Resource = "arn:aws:logs:*:*:*"
},
{
Action = [
"s3:GetObject"
]
Effect = "Allow"
Resource = "${aws_s3_bucket.my_bucket.arn}/*"
},
{
Action = [
"sqs:ReceiveMessage",
"sqs:DeleteMessage",
"sqs:GetQueueAttributes"
]
Effect = "Allow"
Resource = aws_sqs_queue.my_queue.arn
}
]
})
}
data "archive_file" "lambda_zip" {
type = "zip"
source_file = "lambda_function.py"
output_path = ".cache/lambda_function.zip"
}
# Lambda 関数の作成
resource "aws_lambda_function" "my_lambda" {
function_name = "my_download_experiment_lambda"
role = aws_iam_role.lambda_role.arn
handler = "lambda_function.lambda_handler"
runtime = "python3.12"
# Lambdaソースコードの指定。ここではzipファイルからデプロイする例。
filename = data.archive_file.lambda_zip.output_path
source_code_hash = filebase64sha256(data.archive_file.lambda_zip.output_path)
memory_size = var.memory_size
timeout = 60
ephemeral_storage {
size = 1200
}
# 環境変数の設定
environment {
variables = {
CONCURRENCY_LIMIT = tostring(var.concurrency_value)
BUCKET_NAME = var.s3_bucket_name
FILE_NAME = var.s3_file_name
EXPERIMENT_TAG = var.experiment_tag
MEMORY_SIZE = tostring(var.memory_size)
}
}
# Lambdaの同時実行数の制御
reserved_concurrent_executions = var.concurrency_value
}
# Lambda 関数の名前を変数として定義している場合、
# それを使ってロググループ名を指定します。
resource "aws_cloudwatch_log_group" "lambda_log_group" {
name = "/aws/lambda/${aws_lambda_function.my_lambda.function_name}"
retention_in_days = 7
depends_on = [
aws_lambda_function.my_lambda
]
}
# SQSからのイベントソースマッピングでLambdaをトリガー
resource "aws_lambda_event_source_mapping" "sqs_trigger" {
event_source_arn = aws_sqs_queue.my_queue.arn
function_name = aws_lambda_function.my_lambda.arn
batch_size = 1
enabled = true
}
Lambda関数のコード(lambda_function.py)
import os
import json
import time
import boto3
from botocore.exceptions import ClientError
# S3クライアントの作成
s3 = boto3.client('s3')
def lambda_handler(event, context):
# 環境変数の取得
memory_size = os.environ.get('MEMORY_SIZE', '128')
concurrency_limit = os.environ.get('CONCURRENCY_LIMIT', '1')
bucket_name = os.environ.get('BUCKET_NAME')
file_name = os.environ.get('FILE_NAME')
experiment_tag = os.environ.get('EXPERIMENT_TAG', 'default-tag')
download_start = time.time()
try:
# S3からファイルをダウンロード
# Lambdaの/tmpディレクトリに一時保存
local_file_path = f"/tmp/{file_name}"
s3.download_file(bucket_name, file_name, local_file_path)
except ClientError as e:
# エラーハンドリング
print(f"Error downloading file from S3: {e}")
return {
'statusCode': 500,
'body': json.dumps({'error': str(e)})
}
download_end = time.time()
# ダウンロードにかかった時間を計算
download_time = download_end - download_start
# ダウンロードしたファイルを削除
os.remove(local_file_path)
# 結果の準備
result = {
'concurrency_limit': int(concurrency_limit),
'download_time_seconds': download_time,
'memory_size': int(memory_size),
'experiment_tag': experiment_tag
}
# 結果をJSON形式で出力(CloudWatch Logsに出力など)
print(json.dumps(result))
# 必要に応じて結果を返す
return {
'statusCode': 200,
'body': json.dumps(result)
}
ローカルからのキューの送信
import boto3
import uuid
from botocore.exceptions import ClientError
# SQSクライアントの作成
boto_session = boto3.Session(profile_name='hogehoge')
sqs_client = boto_session.client('sqs')
def get_queue_url(queue_name):
try:
response = sqs_client.get_queue_url(QueueName=queue_name)
return response['QueueUrl']
except ClientError as e:
print(f"Error retrieving queue URL: {e}")
return None
def send_messages_in_batches(queue_url, total_messages, batch_size=10):
"""
指定されたバッチサイズで total_messages 件のメッセージを送信します。
"""
messages_sent = 0
while messages_sent < total_messages:
entries = []
# 各バッチの作成: バッチサイズ分のメッセージを用意
for i in range(batch_size):
# 総送信件数を超えたらループ終了
if messages_sent >= total_messages:
break
# 一意なIDを生成(send_message_batch では一意な ID が必要)
entry_id = str(uuid.uuid4())
message_body = f"Message {messages_sent + 1}"
entries.append({
'Id': entry_id,
'MessageBody': message_body
})
messages_sent += 1
try:
response = sqs_client.send_message_batch(
QueueUrl=queue_url,
Entries=entries
)
# 成功したメッセージと失敗したメッセージの処理
if 'Successful' in response:
for success in response['Successful']:
print(f"Sent message ID: {success.get('MessageId')}")
if 'Failed' in response and response['Failed']:
print(f"Failed to send some messages: {response['Failed']}")
except ClientError as e:
print(f"Error sending message batch: {e}")
print(f"Total messages attempted to send: {total_messages}")
def main(concurrency_size):
queue_name = 'my_experiment_queue'
total_messages_to_send = concurrency_size * 10
queue_url = get_queue_url(queue_name)
if queue_url:
send_messages_in_batches(queue_url, total_messages_to_send)
else:
print("Unable to retrieve queue URL.")
if __name__ == "__main__":
main(500)
ChatGPTのコメント(o1)
この現象についてChatGPTの解説
一見「単一ファイルへの大量並列アクセス=読み込み競合で速度低下」というイメージがありますが、S3 も Lambda も内部的に大規模な分散アーキテクチャを採用しており、単一ファイルであっても背後では多くのサーバやネットワーク経路が動的に利用されるため、高いスループットを維持できると考えられます。具体的には次のようなポイントがあります。
- S3 はデータを分散して保存している
S3 は単一オブジェクト(ファイル)であっても、内部で複数の物理サーバやストレージにデータを分散配置し、高い可用性とスループットを実現しています。したがって「1 つのサーバがひとつのファイルを丸ごと抱えている」という構造ではなく、リクエストがさまざまなサーバやルートに振り分けられ、並列アクセスに強い設計になっています。 -
グローバルスケールなバックエンド構成
AWS 全体が大規模なネットワーク帯域と多層構造のロードバランシングを持っているため、リクエストが集中しても自動的・動的に負荷分散が行われます。いわゆる「AWS の中で巨大なパイプを使っている」イメージに近く、それぞれの Lambda が同時に S3 にアクセスしても、ひとつの物理的な経路に集中しにくい仕組みがあります。 -
Lambda 自体も分散実行される
Lambda は呼び出しのたびに複数の物理インフラに「サーバレスコンテナ」が起動され、分散的に実行されます。単一のホストや単一のネットワークカードに負荷が集中するのではなく、AWS 内部でスケールアウトしながら動作しているため、アクセスも潜在的に複数経路から行われます。 -
S3 の高リクエスト処理性能
S3 は大量の GET リクエストを捌くためのチューニングや仕組みが標準で備わっています。ドキュメントにもあるとおり、S3 は「プレフィックス」単位のスケーラビリティを備えており、オブジェクト名=ファイル名がどのように分散管理されるかも大規模アクセス時のスループットに影響します。とはいえ現在はオブジェクト名のプレフィックスを意識しなくても高いパフォーマンスが得られるよう進化しています。 -
ネットワークキャッシュやコンテンツ配信の最適化
AWS 内でデータがよく参照される場合、ネットワーク的にキャッシュされやすかったり、CDN(CloudFront)を併用することもあります。S3 単体でも読み込みキャッシュのような仕組みはありませんが、結果として各データセンター間のトラフィック制御などが高速化しており、ユーザが「並列アクセスが集中している」と感じるほどの帯域競合が起きにくいです。
要するに「S3 は単一のサーバーに置かれたファイルを一斉に読みにいくわけではない」「Lambda も単一のインスタンスで動いているわけではない」ため、表面的には“1 つのファイルをみんなで取り合う”ように見えても、実際には大規模な分散構造でうまくさばくことができる、というのが帯域があまり落ちない理由です。クラウドのインフラレイヤーをフル活用できるのが、S3 + Lambda の強みといえます。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー