
API GatewayにKinesis Data StreamsをつけてLambdaのスロットリングを回避する
Posted On 2025-01-25


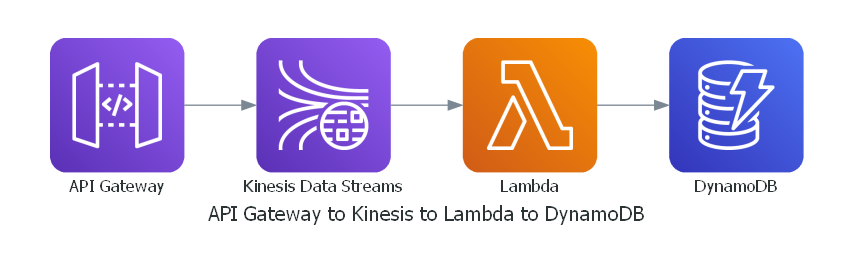
API GatewayからKinesis Data Streamsへ直接データを流し込み、LambdaがポーリングしてDynamoDBへ書き込むことで大量リクエストでもスロットリングを回避しやすくなります。Terraformを使ったリソース構築例と実行結果を示し、Kinesisによるデータバッファリング効果を確認します。
目次
はじめに
- SAP勉強して出てきた例。API GatewayからLambdaを経由してDynamo DBに書き込む例だが、スパイクでものすごいリクエスト量が出てきて、「Lambdaのスロットリングかかってしまうときにどうしたらいいか?」というサンプル
- Kinesis Data StreamsをAPI Gatewayに直付けして、LambdaがそこからポーリングしてDynamo DBに書き込むというもの
- Kinesis Data Streamsがバッファリングの役割をになって、Lambdaがスロットリングしにくくなるというもの
Terraformでの実装
ポイントが2つある。主にAPI GatewayからKinesis Data Streamsの連携がメイン
- Kinesis Data Streamsへのデータ送信はbase64でエンコードする必要がある。これがJSONのままだとAPIのレスポンスでは500エラー、APIのエラーログでは400エラーが出ているはず(下のコード参照)
- Kinesis Data Streamsとの連携はAWS統合となる。Lambdaの場合はプロキシ統合だったので、200レスポンスや400レスポンスを定義しなくてよかったが、AWS統合の場合は別途統合が必要。
失敗時のエラー
status_code=500 (Internal Server Error)
API Gateway側でのエラーログ
(...) Sending request to https://kinesis.ap-northeast-1.amazonaws.com/?Action=PutRecord
(...) Received response. Status: 400, Integration latency: 1 ms
(...) Execution failed due to configuration error: No match for output mapping and no default output mapping configured. Endpoint Response Status Code: 400
全体のコード(Terraform)
# データソース: リージョンとアカウント情報
data "aws_region" "current" {}
data "aws_caller_identity" "current" {}
########################################
# 1) API Gateway の設定
########################################
resource "aws_api_gateway_rest_api" "example_api" {
name = "kinesis-sample-api"
description = "API connected to Kinesis Data Streams"
}
# ここでは POST メソッドでボディを受け取り、そのまま Kinesis に流す例
resource "aws_api_gateway_method" "root_method" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
resource_id = aws_api_gateway_rest_api.example_api.root_resource_id
http_method = "POST"
authorization = "NONE"
}
########################################
# 2) Kinesis Data Streams への接続用 IAM ロール
########################################
# API Gateway が assume するロール
data "aws_iam_policy_document" "apigw_assume_role_policy" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["apigateway.amazonaws.com"]
}
}
}
resource "aws_iam_role" "apigw_kinesis_role" {
name = "apigw_kinesis_role"
assume_role_policy = data.aws_iam_policy_document.apigw_assume_role_policy.json
}
# Kinesis Stream に PutRecord するためのポリシー
data "aws_iam_policy_document" "apigw_kinesis_policy_doc" {
statement {
actions = ["kinesis:PutRecord"]
resources = [aws_kinesis_stream.example.arn]
}
}
resource "aws_iam_role_policy" "apigw_kinesis_role_policy" {
name = "apigw_kinesis_role_policy"
role = aws_iam_role.apigw_kinesis_role.id
policy = data.aws_iam_policy_document.apigw_kinesis_policy_doc.json
}
########################################
# 3) Kinesis Data Streams リソース
########################################
resource "aws_kinesis_stream" "example" {
name = "example-stream"
shard_count = 1
}
########################################
# 4) API Gateway → Kinesis の Integration
########################################
resource "aws_api_gateway_integration" "root_integration" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
resource_id = aws_api_gateway_rest_api.example_api.root_resource_id
http_method = aws_api_gateway_method.root_method.http_method
integration_http_method = "POST"
type = "AWS"
# PutRecord アクションを呼び出すためのエンドポイント
uri = "arn:aws:apigateway:${data.aws_region.current.name}:kinesis:action/PutRecord"
credentials = aws_iam_role.apigw_kinesis_role.arn
# シンプルに Body 全体を Data として送ってしまう例
request_templates = {
"application/json" = <<EOF
{
"StreamName": "${aws_kinesis_stream.example.name}",
"PartitionKey": "$context.requestId",
"Data": "$util.base64Encode($input.body)"
}
EOF
}
}
# 1) 成功時 (200)
resource "aws_api_gateway_method_response" "root_method_200" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
resource_id = aws_api_gateway_rest_api.example_api.root_resource_id
http_method = aws_api_gateway_method.root_method.http_method
status_code = "200"
# 必要に応じてレスポンスモデルを指定
response_models = {
"application/json" = "Empty"
}
}
resource "aws_api_gateway_integration_response" "root_integration_200" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
resource_id = aws_api_gateway_rest_api.example_api.root_resource_id
http_method = aws_api_gateway_method.root_method.http_method
status_code = "200"
selection_pattern = "" # = 空文字列 => 正常系(200など)にマッチ
response_templates = {
"application/json" = "" # 必要であれば JSON マッピングテンプレートを指定
}
depends_on = [
aws_api_gateway_integration.root_integration
]
}
# 2) クライアントエラー (400)
resource "aws_api_gateway_method_response" "root_method_400" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
resource_id = aws_api_gateway_rest_api.example_api.root_resource_id
http_method = aws_api_gateway_method.root_method.http_method
status_code = "400"
response_models = {
"application/json" = "Empty"
}
}
resource "aws_api_gateway_integration_response" "root_integration_400" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
resource_id = aws_api_gateway_rest_api.example_api.root_resource_id
http_method = aws_api_gateway_method.root_method.http_method
status_code = "400"
# 4XX 系のレスポンスをまとめて 400 として返したい場合
# 例: "4\d{2}" => 400,401,402,...499 を一括で 400 として扱う
selection_pattern = "4\\d{2}"
response_templates = {
"application/json" = ""
}
depends_on = [
aws_api_gateway_integration.root_integration
]
}
########################################
# 5) デプロイメントとステージ
########################################
resource "aws_api_gateway_deployment" "example_deployment" {
depends_on = [aws_api_gateway_integration.root_integration]
rest_api_id = aws_api_gateway_rest_api.example_api.id
triggers = {
redeployment_integration = sha1(jsonencode(aws_api_gateway_integration.root_integration))
}
lifecycle {
create_before_destroy = true
}
}
resource "aws_api_gateway_stage" "example" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
deployment_id = aws_api_gateway_deployment.example_deployment.id
stage_name = "dev"
}
########################################
# 6) DynamoDB (ID + Message のみ)
########################################
resource "aws_dynamodb_table" "example_table" {
name = "example-table"
billing_mode = "PAY_PER_REQUEST"
hash_key = "ID"
attribute {
name = "ID"
type = "S"
}
}
########################################
# 7) Lambda: Kinesis → DynamoDB (サンプル)
########################################
# Lambda 用 IAM ロール
data "aws_iam_policy_document" "lambda_assume_role_policy" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
}
}
data "aws_iam_policy_document" "lambda_kinesis_to_dynamo_policy_doc" {
# DynamoDB への書き込み権限
statement {
actions = ["dynamodb:PutItem"]
resources = [aws_dynamodb_table.example_table.arn]
}
# Kinesis Stream からの読み取り権限
statement {
actions = [
"kinesis:GetRecords",
"kinesis:GetShardIterator",
"kinesis:DescribeStream",
"kinesis:ListShards"
]
resources = [aws_kinesis_stream.example.arn]
}
# CloudWatch Logs への出力権限 (ログ用)
statement {
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = ["arn:aws:logs:*:*:*"]
}
}
resource "aws_iam_role" "lambda_role" {
name = "lambda_kinesis_to_dynamo_role"
assume_role_policy = data.aws_iam_policy_document.lambda_assume_role_policy.json
}
resource "aws_iam_role_policy" "lambda_policy" {
name = "lambda_kinesis_to_dynamo_policy"
role = aws_iam_role.lambda_role.id
policy = data.aws_iam_policy_document.lambda_kinesis_to_dynamo_policy_doc.json
}
data "archive_file" "lambda_zip" {
type = "zip"
source_file = "${path.module}/lambda_function.py"
output_path = ".cache/lambda_function.zip"
}
# 実際の Lambda 関数 (handler は例。Python や Node.js など任意)
resource "aws_lambda_function" "kinesis_to_dynamo" {
function_name = "kinesis_to_dynamo"
role = aws_iam_role.lambda_role.arn
runtime = "python3.12"
handler = "lambda_function.lambda_handler"
filename = data.archive_file.lambda_zip.output_path
source_code_hash = filebase64sha256(data.archive_file.lambda_zip.output_path)
memory_size = 256
timeout = 60
}
# Kinesis Stream をトリガーにする
resource "aws_lambda_event_source_mapping" "kinesis_trigger" {
event_source_arn = aws_kinesis_stream.example.arn
function_name = aws_lambda_function.kinesis_to_dynamo.arn
batch_size = 100
starting_position = "LATEST"
}
########################################
# 8) 出力
########################################
output "api_endpoint" {
value = aws_api_gateway_stage.example.invoke_url
}
# 必要に応じて Lambda の ARN やテーブル名などを出力してもOK
output "kinesis_stream_arn" {
value = aws_kinesis_stream.example.arn
}
output "dynamodb_table_name" {
value = aws_dynamodb_table.example_table.name
}
########################################
# API Gatewayのデバッグ用のログ(必要に応じて設定)
########################################
# # 1) API Gateway 用に CloudWatch Logs を有効化するためのロール設定
# data "aws_iam_policy_document" "apigw_cloudwatch_assume_policy" {
# statement {
# actions = ["sts:AssumeRole"]
# principals {
# type = "Service"
# identifiers = ["apigateway.amazonaws.com"]
# }
# }
# }
# resource "aws_iam_role" "apigw_cloudwatch_role" {
# name = "apigw-cloudwatch-logs-role"
# assume_role_policy = data.aws_iam_policy_document.apigw_cloudwatch_assume_policy.json
# }
# data "aws_iam_policy_document" "apigw_cloudwatch_policy_doc" {
# statement {
# effect = "Allow"
# actions = [
# "logs:CreateLogGroup",
# "logs:CreateLogStream",
# "logs:DescribeLogGroups",
# "logs:DescribeLogStreams",
# "logs:PutLogEvents"
# ]
# resources = ["arn:aws:logs:*:*:*"] # 必要に応じて絞り込んでもOK
# }
# }
# resource "aws_iam_role_policy" "apigw_cloudwatch_role_policy" {
# name = "apigw-cloudwatch-logs-policy"
# role = aws_iam_role.apigw_cloudwatch_role.id
# policy = data.aws_iam_policy_document.apigw_cloudwatch_policy_doc.json
# }
# # 2) API Gateway アカウントに対して CloudWatch Logs 出力用ロールを関連付け
# resource "aws_api_gateway_account" "this" {
# cloudwatch_role_arn = aws_iam_role.apigw_cloudwatch_role.arn
# # ポリシーが作成されてから関連付けしないとエラーになる場合があるため depends_on を設定
# depends_on = [aws_iam_role_policy.apigw_cloudwatch_role_policy]
# }
# # 3) 対象 API & ステージでログレベルを有効化 (Method Settings)
# resource "aws_api_gateway_method_settings" "example_method_settings" {
# rest_api_id = aws_api_gateway_rest_api.example_api.id
# stage_name = aws_api_gateway_stage.example.stage_name
# method_path = "*/*" # 全メソッド対象
# # ロール設定が完了してからステージを更新するように
# depends_on = [
# aws_api_gateway_account.this,
# aws_api_gateway_stage.example
# ]
# settings {
# metrics_enabled = true
# logging_level = "INFO" # "ERROR" などでもOK
# data_trace_enabled = true
# }
# }
Kinesis Data Streams→Dynamo DBのLambdaコード(lambda_function.py)
import json
import boto3
import base64
import uuid
# DynamoDB リソースを初期化
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('example-table') # テーブル名を合わせる
def lambda_handler(event, context):
"""
Kinesis Data Streams からのイベントを取得し、
base64 でエンコードされたレコードをデコードして
DynamoDB の example-table に書き込みます。
"""
for record in event['Records']:
# Kinesis の payload は base64 でエンコードされている
payload = base64.b64decode(record['kinesis']['data'])
# payload を文字列にデコード
payload_str = payload.decode('utf-8')
# payload が JSON 形式を仮定するか、あるいはそのまま文字列として扱うかは要件次第
# ここでは JSON と仮定してパースします
try:
data = json.loads(payload_str)
except json.JSONDecodeError:
# JSON でなければそのまま文字列として取り扱う
data = {"message": payload_str}
# ID を UUID で生成 (ランダム)
item_id = str(uuid.uuid4())
# DynamoDB に書き込み。テーブルスキーマ: ID (PK) + Message
table.put_item(
Item={
"ID": item_id,
"Message": data.get("message", "NoMessage")
}
)
return {
"statusCode": 200,
"body": json.dumps({"result": "ok"})
}
ローカルから大量にリクエストを送るコード(send_api.py)
import json
import requests
import concurrent.futures
# 例: Terraform で構築した API Gateway のエンドポイント
# "dev" はステージ名に合わせて調整ください
API_ENDPOINT = "https://<your-api-id>.execute-api.<region>.amazonaws.com/dev"
# スレッドプールの最大同時実行数
MAX_WORKERS = 1
# 一度に送るリクエストの総数
NUM_REQUESTS = 10
def send_request(payload):
"""
与えられた payload を JSON として POST リクエストし、レスポンスを返します
"""
headers = {
"Content-Type": "application/json"
}
try:
response = requests.post(API_ENDPOINT, data=json.dumps(payload), headers=headers, timeout=5)
return {
"status_code": response.status_code,
"text": response.text
}
except Exception as e:
return {
"status_code": None,
"text": f"Error: {e}"
}
def main():
# 実際に送信したいデータを定義する例。用途に合わせて変更してください。
messages = [f"Test message {i}" for i in range(NUM_REQUESTS)]
with concurrent.futures.ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
# 非同期でリクエストを投げる
futures = []
for idx, msg in enumerate(messages):
payload = {
"index": idx,
"message": msg
}
futures.append(executor.submit(send_request, payload))
# 完了したリクエストから順に結果を取得する
for future in concurrent.futures.as_completed(futures):
result = future.result()
print(f"status_code={result['status_code']}, response={result['text']}")
if __name__ == "__main__":
main()
結果
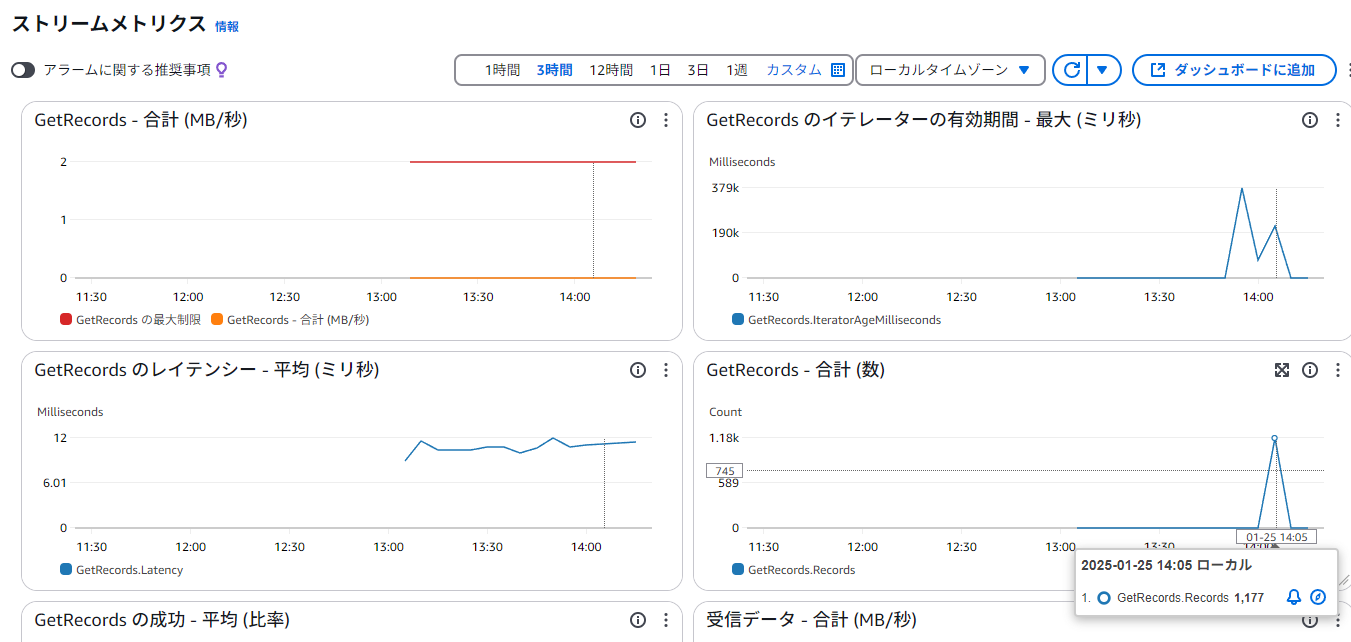
1000個ぐらいデータをローカルから送ってみる(すごい勢いで送るとたまにエラーが出ることがある)。
Kinesis Data Streamsのモニタリングを見ると、GerRecordsに1k近いスパイクが発生している。Kinesisで大量の通信スパイクをキャッチできており、うまくいっている例
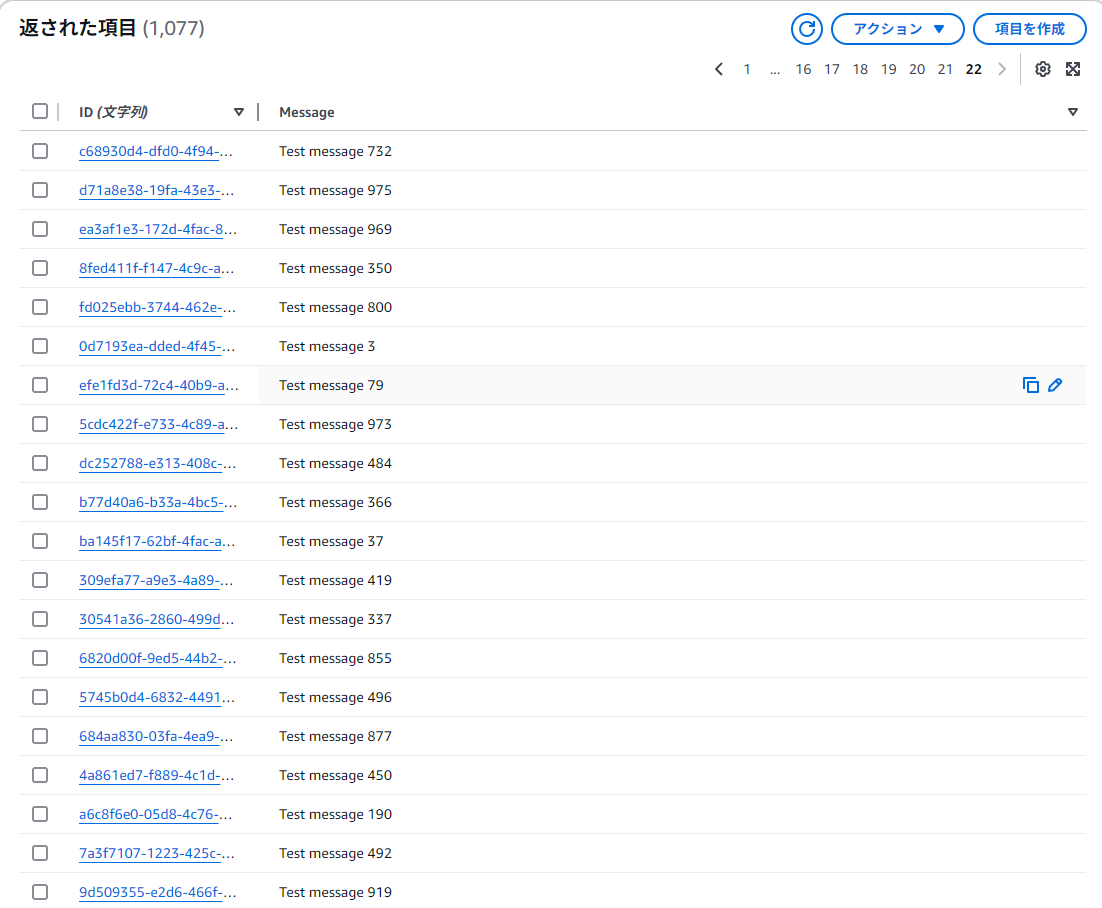
Dynamo DBではデータが受信できている。
所感
- Kinesis Data Streamsすごい! 割と実践的な使い方な気がする
- Kinesisでデータをバッファリングするというのはなるほどという感。ただこんだけの通信を前段でさばけるAPI Gatewayすごい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー