
データのお気持ちを考えながらData Augmentationする


Data Augmentationの「なぜ?」に注目しながら、エラー分析をしてCIFAR-10の精度向上を目指します。その結果、オレオレAugmentationながら、Wide ResNetで97.3%という、Auto Augmentとほぼ同じ(-0.1%)精度を出すことができました。
(※すごい長いんで暇なときに読んでね!)
目次
動機
カーネルを見ていると「何でこのAugmentation操作入れるの?」というのがよくあって、それが謎の高い精度を出してたりすることが稀によくあります。結局そういうときってAuto Augmentを使えばいい感じにはなるのだけど、「なぜ?」の部分が結局解決しないままで、モヤモヤ感がすごかったのです。
そこで、訓練と同時にエラー分析を行い、「どのへんがどの程度間違っているの?」ということを明らかにしながら精度向上を行っていきます。データはCIFAR-10を使います。ぶっちゃけCIFAR-10ならAutoAugment用の最適化済みポリシーが既にあってそれを使えば、お手軽に精度を出せるのですが、それだと脳死になっちゃって趣旨に反するので、今回は手動でやります。
ちなみに、Auto AugmentではWide ResNet28-10でエラー率2.6±0.1%という公式記録があります。今回やった手動のAugmentationでは同一のネットワークのほとんど同じ設定で、それに近い精度(エラー率2.7%)というのを達成することができました。
コードは末尾にあります。
導入:Data Augmentationなし
まずは一切Data Augmentationしない設定です。
| 項目 | 設定値 |
|---|---|
| バッチサイズ | 128 |
| エポック数 | 150 |
| 学習率 | Step Decay(開始0.1、75・125epochで各1/10) |
| ネットワーク | 10層CNN |
| Augmentation | なし |
オプティマイザーはMomentumで係数は0.9です。このオプティマイザーの設定はケースを通じて変更しません。ただしその他の設定は途中で変更します。なお、試行回数はすべて1回なので精度に誤差があるかもしれません。
10層CNNは、32×32×64が3層、16×16×128が3層、8×8×256が3層、Global Average PoolingしてSoftmaxが1層という構成です。詳しくは末尾のコードを見てください。
Data Augmentationなしでの精度(テスト精度)は88.95%とりました。テストデータ1万個に対する混同行列は次の通りです。さすがにミス多いですね。

ベースライン:Standard Data Augmentation
ここからData Augmentationを入れます。まず、CIFAR-10のData Augmentationとして定番の左右反転+上下左右4ピクセルのクロップ、いわゆるStandard Data Augmenationを入れます。以下のコードでできます。
def baseline_generator(X, y, batch_size):
gen = ImageDataGenerator(rescale=1.0/255, horizontal_flip=True,
width_shift_range=4.0/32.0, height_shift_range=4.0/32.0)
return gen.flow(X, y, batch_size=batch_size)
さすがに定番だけあって非常によく効いて、88.95%から大幅に改善し、93.18%となりました。混同行列は以下の通りです。

一番多いのが、犬と猫の間違いですね。これはラスボスクラスに強くてどんなにAugmentationしてもなかなか改善されません。実践的にはCats and Dogsのようなデータセットをプラスで入れれば大きく改善されるのでしょうが、それだともうCIFAR-10ではなくなってしまうので。
エラー分析で個々の間違いを見ていきましょう。ベースラインの間違いが多かった上位5件を見てみます。

この表のTrueというのは真のラベルで、Predというのは予測ラベルです。#は該当個数です。rankはそのエラー分析の中での該当個数が多い順のランキングです。この例なら、「本当は犬の画像なんだけど、猫と予測されていて、そのサンプル数が68個あり、エラーの順位としてはワースト1」という意味です。この個数は混同行列の表と対応します。

「本当は猫だけど、犬と予測されている」ケースも多いです。なんかぱっと見ると色が原因のような感じはしますね。例えば、白と黒のしましま模様のは、猫でも犬でもあってそれが紛らわしいような印象は受けます。

3つ目はぐっと件数は減りますが、「本当は猫だけど、鹿と予測されているケース」です。これはわかりやすいですね。草原の背景に黄色い猫は確かに鹿っぽく見える。色が原因ではないかと思われます。

4つ目は「本当は船だけど飛行機と予測されているケース」。これもわかりやすくて、空と湖水・海を勘違いしているケース。やはり色が原因ではないかと思われます。

5つめは「本当は鳥だけど、カエルと予測されているケース」。緑色というのはカエルの重要な特徴ですから、オウムのような緑色の鳥や、草原のような緑色の背景は勘違いさせやすいのでしょう。これもわかりやすいです。
エラー分析を見てみると、「なんか大きな原因に色が関係してそうだよね」というのがわかります。そして同時に「色だけじゃなくてもっと物体の形状を見てほしいよね」というのがわかります。つまり対策としては2つ考えられます。
- 形状を見るためにランダムにズームを入れる(ImageDataGeneratorのRandom Zoom)
- チャンネル単位で色のシフトを入れる(ImageDataGeneratorのColor Shift Range)
この2つのAugmentationが”データのお気持ち”を汲み取った結果ということになります。これらを順にやっていきましょう。
1. Random Zoomを加える
ベースラインから太字にしたところが変更点です。
| 項目 | 設定値 |
|---|---|
| バッチサイズ | 128 |
| エポック数 | 150 |
| 学習率 | Step Decay(開始0.1、75・125epochで各1/10) |
| ネットワーク | 10層CNN |
| Augmentation | RandomZoom(75%-125%) |
このようなジェネレーターになります。
def mode1_generator(X, y, batch_size):
gen = ImageDataGenerator(rescale=1.0/255, horizontal_flip=True,
width_shift_range=4.0/32.0, height_shift_range=4.0/32.0,
zoom_range=[0.75, 1.25])
return gen.flow(X, y, batch_size=batch_size)
ズームレンジは75%~125%にしました。他の試行錯誤の例は後述。この結果、精度は93.36%に改善しました(0.18%の改善)。

効果としては相当地味ですが、犬猫の間違いだけは68件→56件とかなり改善していることがわかります。人間的には犬猫の間違いは注意深くズームすればわかるかなという感じなので、ズームを入れてより形状に注目するようにすれば、若干効果はあるのかもしれません。

しかしこれを見てもやはり色の問題は残っているようで、やはり一度は色のAugmentationを入れたほうがいいことがわかります。
没になったケース
ズーム関係で没になったケースです。まず、犬猫のクラスのみRandom Zoomを入れるケース。
- 犬猫のクラスに100%~150%のズームを入れる→92.34%
- 犬猫のクラスに100%~125%のズームを入れる→92.84%
精度が大きく下がってしまいました。犬猫のクラスのみではなく、全てのクラスにズームを入れると次のような精度になりました。
- すべてのクラスの100~150%のズームを入れる→92.53%
- すべてのクラスに100~125%のズームを入れる→93.12%
いずれの2つのケースでも、犬猫のクラスのみズームするという、局所的なクラスのAugmentationはパフォーマンスを悪化させるというのがわかりました。なので今回のケースでは局所的なAugmentationはそそくさと切り捨ててしまいました。もしこういうのが効果があるという研究があったらぜひ教えてください。
この中で75%~125%のケースのみが93.36%とベースラインからの唯一の改善例となりました。今振り返ると、上記の4例ではズームの平均値が100%ではないので、分布のミスマッチ起こして結果精度が悪くなったのかもしれません。
1+. (没)色調反転
試しに色調反転やったらどうなのか試してみました。白黒の犬や猫に効くのではないかと思ったからです。計算は50%の確率で「1.0-ピクセル値」すればいいだけです。ただし、結果は良くなかったので没にしました。
- 犬猫だけランダムで色調反転 :92.58%
- 全体をランダムで色調反転 : 91.74%
ベースラインが93.18%だったことを踏まえると、大幅に悪化しているのがわかります。色調反転は除外してもよさそうです。
2. Color Shiftを入れる
次に色調のAugmentationを入れます。
| 項目 | 設定値 |
|---|---|
| バッチサイズ | 128 |
| エポック数 | 150 |
| 学習率 | Step Decay(開始0.1、75・125epochで各1/10) |
| ネットワーク | 10層CNN |
| Augmentation | RandomZoom(75%-125%) Color Shift(50) |
ジェネレーター
# カラーシフトを追加
def mode2_generator(X, y, batch_size):
gen = ImageDataGenerator(rescale=1.0/255, horizontal_flip=True,
width_shift_range=4.0/32.0, height_shift_range=4.0/32.0,
zoom_range=[0.75, 1.25], channel_shift_range=50.0)
return gen.flow(X, y, batch_size=batch_size)
精度は93.64%(0.28%改善)となりました。Standard Data Augmentationのように数%の改善というのはなくて、もはや0.数%単位の改善の世界になります。

犬猫のような大きなミスに集中的に効くというよりかは、小さいミスに全般的に効くという感じですね。

「本当は犬で予測は猫」の間違いは73件と増えてしまいましたが、その半面「本当は猫で予測は犬」のケースが46件と少ないので均して見ればイーブン~微減ではないかと思います。ここらへんは乱数の気分で変わるのでどっちでもいいかと思います。あとで混同行列の推移をまとめてみましょう。

ここまでズームと色という2つのAugmentationを加えてみましたが、次に何をしましょう。この例を見てわかるのは、犬か猫かということではなく、ポーズだけを見て犬/猫を割り振っている可能性があるということです。
本当は犬で予測が猫のケースでは、なんとなく猫がやりそうなポーズの犬であるが多いですよね。CNNはぼやっとした全体像に注目することが多いですが、CIFARでは特に解像度が32×32と低いので、人間のように細かな輪郭までなかなか見てくれないと思います。エラー分析を見ると、人間が見たところで、犬か猫かよくわからないケースもあるので。
本当かどうかはわかりませんが、次に「ポーズが原因」と仮説を立てることにしましょう。ポーズに効くのかはなにかというと、回転やシアーといったアフィン変換系です。例えば、寝っ転がっている絵があっても回転させてしまえば全く別のポーズに見えますからね。どちらも試してみましょう。
没になったケース
Color Shiftで没になったケースです。ImageDataGeneratorのColor Shift Rangeの値をいじってみました。
- color_shift_range=100 → 93.17%
- color_shift_range=30 → 93.55%
shift=50が93.62%と最も高かったのでこの値を採用しました。
3.回転を追加
次にランダムの回転を追加します。回転量はごく少数で±10°としました。
| 項目 | 設定値 |
|---|---|
| バッチサイズ | 128 |
| エポック数 | 150 |
| 学習率 | Step Decay(開始0.1、75・125epochで各1/10) |
| ネットワーク | 10層CNN |
| Augmentation | RandomZoom(75%-125%) Color Shift(50) 回転(10°) |
ジェネレーターもこんな感じで足してるだけですね。
def mode3_generator(X, y, batch_size):
gen = ImageDataGenerator(rescale=1.0/255, horizontal_flip=True,
width_shift_range=4.0/32.0, height_shift_range=4.0/32.0,
zoom_range=[0.75, 1.25], channel_shift_range=50.0,
rotation_range=10)
return gen.flow(X, y, batch_size=batch_size)
精度は0.32%改善し、93.94%となりました。

犬猫のミスは相変わらずという感じだけど、その他の細かいミスは減っているような印象を受けます。

ぱっと見てあまり変わってはいなそうだけど、確かに精度は徐々に上がっている状態。本当に効いてるの?という疑問が払拭できないので、ベースラインとモード3(回転まで)の混同行列を比較してみます。

犬猫対策で入れたAugmentationが、実は犬猫にはあまり効いていなくて他のクラスに対して効果が高いというのがわかりました。猫は848→852で0.8%の改善、犬は880→884で0.4%の改善で実は全体の平均よりも低いのです。それより効果が高いのは、鳥が897→917で2%の改善、カエルが945→980で3.5%の改善とトップ2でした。これまでのマニュアルなAugmentationは鳥とカエルの2クラスが押し上げています。ただ、精度は上がっているので結果オーライとしましょう。
没になったケース
回転の角度による派生です。
- 回転±5° → 93.44%
- 回転±10° → 93.94%
- 回転±15° → 93.76%
- 回転±30° → 93.75%
4ケース中で10°が最も良かったのでこれを採用しました。
3+. (没)シアーを追加
回転からシアーを追加したケースです。シアーはImagDataGeneratorのshear_rangeの値をいじりました。3ケース試してみたのですが、全てのケースで精度が下がってしまったので今回は使いませんでした。
- shear_range = 5° → 93.34%
- shear_range = 10° → 93.88%
- shear_range = 30° → 93.65%
試行回数増やせばもうちょっと効果出るかもしれないけど、多分シアーはほとんど効かないのでしょう。ただこれはあくまで「CIFAR-10にシアーの効果は薄いよ」という意味であって、画像データ一般にシアーのAugmentationが意味ないというわけではありません。シアーが効くようなケースもあるので、選択肢の一つとして持っておくといいと思います。
シアーと回転は見た目が似ているので、ズームや平行移動、回転といったアフィン変換によるAugmentationで、もしかしたらシアーに似たような操作も再現できてしまったのかもしれませんね。
では次は何を追加しましょうか。やはり犬猫の誤分類をどうにかしないといけません。そこで仮説なのですが、Random ErasingみたいなAugmentationを使って、画像をランダムに消して注目する部位を平均化してみたらどうだろう?と思うのです。
犬猫だと模様や耳といったわかりやすいパーツがあるので、そこに注目しやすいのではないかと思うのです。わかりやすいパーツが偶然消えてくれれば、他のパーツから判断してくれるようになって、精度が上がってくれたらいいなぁと思うのです。
4. Random Erasingを追加
だいぶAugmentationが豪華になってきましたが、次はRandom Erasingを追加します。
| 項目 | 設定値 |
|---|---|
| バッチサイズ | 128 |
| エポック数 | 150 |
| 学習率 | Step Decay(開始0.1、75・125epochで各1/10) |
| ネットワーク | 10層CNN |
| Augmentation | RandomZoom(75%-125%) Color Shift(50) 回転(10°) Random Erasing(5%-20%) |
Random ErasingはImageDataGeneratorに組み込まれていないので、自分で定義します。また、論文通りだと削除する面積が多すぎて正則化が強すぎるので、消す面積を控えめにします。論文の表記だと「s_l, s_h」といった消す面積比のパラメーターを調整します。Random Erasingのコードは次の通りです。rのパラメーターは割といい加減かも。
def random_erasing(image, prob=0.5, sl=0.05, sh=0.2, r1=0.2, r2=0.8):
# パラメーター
# - image = 入力画像
# - prob = random erasingをする確率
# - sl, sh = random erasingする面積の比率[sl, sh]
# - r1, r2 = random erasingのアスペクト比[r1, r2]
assert image.ndim == 3
assert image.dtype == np.float32
if np.random.rand() >= prob:
return image
else:
H, W, C = image.shape # 縦横チャンネル
S = H * W # 面積
while True:
S_eps = np.random.uniform(sl, sh) * S
r_eps = np.random.uniform(r1, r2)
H_eps, W_eps = np.sqrt(S_eps*r_eps), np.sqrt(S_eps/r_eps)
x_eps, y_eps = np.random.uniform(0, W), np.random.uniform(0, H)
if x_eps + W_eps <= W and y_eps + H_eps <= H:
out_image = image.copy()
out_image[int(y_eps):int(y_eps+H_eps), int(x_eps):int(x_eps+W_eps),
:] = np.random.uniform(0, 1.0)
return out_image
結果は精度が94.14%(0.2%)の改善となりました。

精度上は改善しています。しかし、犬猫がほとんど下がりませんね。
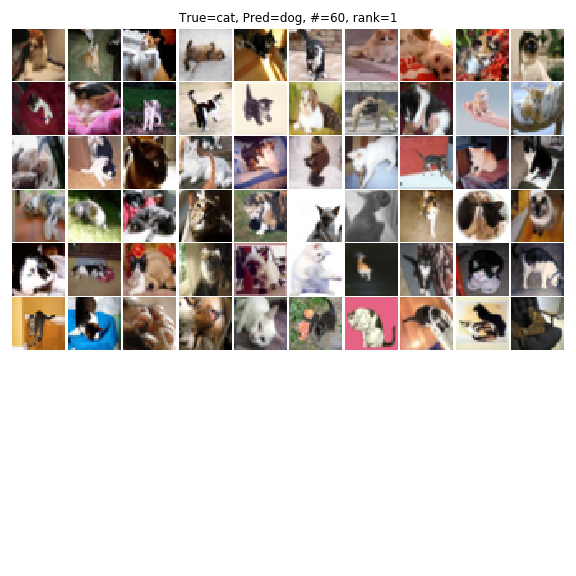
気持ち間違いの件数は減りつつあるものの、ポーズや色といった傾向もなく、正直お手上げ感が強いです。

では、Random Erasing意味ないかというと、そうではなくて、実は犬の精度向上にかなり寄与しているのです。混同行列を直前のケース3(回転まで)と比較しみましょう。

これまで犬のクラスはなかなか精度が上がらなかったのですが、正解の件数が884→896と1.2%も改善しているのです。他にも鳥が917→931と1.4%改善、鹿が945→958と同じく1.4%改善と、Random Erasingは生き物に対してよく効く結果となっています。それはそうで、犬の耳やしっぽといった生き物の特徴的なわかりやすいパーツがRandom Erasingによって消されて、より広範囲を見るようになるからだと思われます。
ただ、その半面飛行機が0.8%悪化、トラックが1.6%悪化と、人工物に対してはRandom Erasingはあまりよくない結果となっています。飛行機やトラックに耳も尻尾もないので、これらのような形が単純なものには向いていないのかもしれません。ここらへんが生物のゲインを人工物が打ち消しているので、0.2%という地味な改善結果となりました。
一応今回がStep Decayを使う最後のパターンなので、テスト精度の推移の学習曲線を書いておきます。
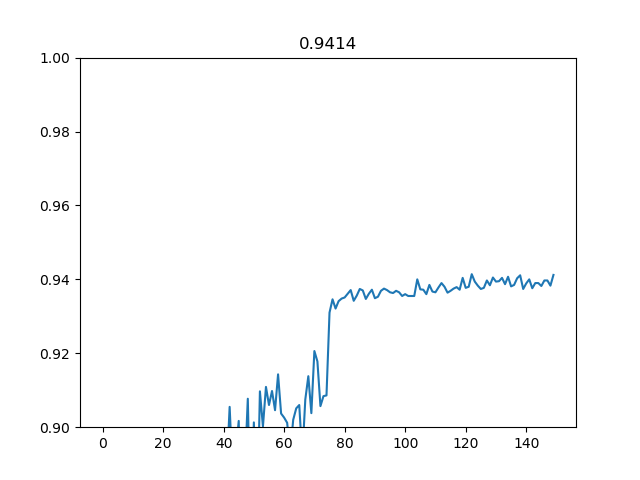
こんな感じで、学習率減衰なしでも92%あたりまで行きますが、一回目の学習率減衰が大きく効いてこれが2%ぐらい精度を押し上げます(70エポック)。二回目の減衰は仕上げで、効きは弱いですが若干押し上げる程度です(125エポック)。これ書いてる途中で気づいたけど、バグで2回目の減衰実は効いていなかった(ifを間違ってelifにした)。まぁ大きな違いないし別にいいよね。
犬猫どうしよ?ということなのですが、特定の理由があるのではなく、犬猫の決定境界が怪しい感じかと思われるので、Mixupみたいなソフトなラベルを使うのが良いのではないか仮説を立てました。そこで次はMixupを使います。
没になったケース
Random Erasingのパラメーター調整です。ケース3の精度が93.94%です。
- sl=0.02, sh=0.15 → 94.11%
- sl=0.05, sh=0.2 → 94.14%
- sl=0.1, sh=0.25 → 93.92%
- sl=0.2, sh=0.5 → 93.66%
sl, shが高すぎると逆に精度が下がってしまうので低めの設定としました。
5. Mixup
Mixupという2つの画像を混ぜるData Augmentationを使います。ただ、これは今までと同じ方式で最適化してもあまりうまくいかなく(最適化があからさまに遅くなる)、訓練時間を長くしないと本来の性能は出ませんでした。具体的な値は没ケースで。
Shake-Shakeみたいに千エポックもやる必要はありませんが(たかがこんなブログ記事で1500エポックも回すのは馬鹿げてるし、CIFAR訓練するだけで1日かかるのはやりたくない)、それに近いような発想は必要になります。そこで、150エポックかつStep Decayから、300エポックのCosine Annealingに変えます。
Cosine DecayのアイディアはSGDRの論文からですね。ただしSGDRの学習率の再スタートは使いません。再スタートなしのCosine AnnealingはShake-Shakeの最適化でも使われているので、Shake-Shakeのお手軽版という位置づけでしょうか。
| 項目 | 設定値 |
|---|---|
| バッチサイズ | 128 |
| エポック数 | 300 |
| 学習率 | Cosine Decay(上限0.1、下限0.001のコサインカーブ) |
| ネットワーク | 10層CNN |
| Augmentation | RandomZoom(75%-125%) Color Shift(50) 回転(10°) Random Erasing(5%-20%) Mixup(beta=0.5) |
今回だけ3項目変更しました。以下のケースでは全て300エポックのCosine Annealing(Decay)を使います。そのため訓練時間が2倍以上になります。ちなみにCosine AnnealingはPyTorchのドキュメントに式が載っており、
$$\eta_t = \eta_{min}+\frac{1}{2}(\eta_{max}-\eta_{min})(1+\cos(\frac{T_{cur}}{T_{max}}\pi)) $$
という関数で表されます。$\eta$は学習率の上限と下限ですね。SGDRの再起動をしない場合は、$T_{max}$は最大エポック数(300)、$T_{cur}$は現在のエポック数を突っ込めば終わりです。これをコードで表せば、
def cosine_decay(epoch):
lr_min = 0.001
lr_max = 0.1
T_max = 300
return lr_min + 1/2*(lr_max-lr_min)*(1+np.cos(epoch/T_max*np.pi))
あとはこの関数をLearningRateSchedulerでラップして、StepDecay同様にCallbackに放り込めばOKですね。
ジェネレーターのほうは次のようになります。
def mixup(X, y, beta=0.5):
shuffle_ind = np.random.permutation(X.shape[0])
rand = np.random.beta(beta, beta)
X_mix = rand * X + (1-rand) * X[shuffle_ind]
y_mix = rand * y + (1-rand) * y[shuffle_ind]
return X_mix, y_mix
# mixup
def mode5_generator(X, y, batch_size):
for X_base, y_base in mode4_generator(X, y, batch_size):
yield mixup(X_base, y_base, 0.5)
結果は94.51%(0.37%の改善)となりました。マニュアルで追加したケースではかなり大きかったのではないでしょうか。

混同行列は足を引っ張っていた犬猫がようやく9割の大台に達しそうです。

エラー分析を見るとあまり進歩しているのがわかりづらいのですが、犬と猫の間違いが合計110~120件ぐらいあったのが、108件まで落ちています。

今回は「本当が犬で予測が猫」のほうに間違いが集中していますが、これならもう間違えても仕方ないやみたいなケースのような感じはします。
直近の混同行列の推移を見ると、犬猫に集中的に効いているのがよくわかって、

猫はMixupの追加で852→882と3%も改善していますね。犬はRandom Erasingの効きのほうが強かったのですが、回転までと比較して1.4%の改善。そしてRandom Erasingでは飛行機やトラックといった人工物の精度が悪くなっていましたが、Mixupを追加するとそこのマイナスが多少打ち消されるようです。
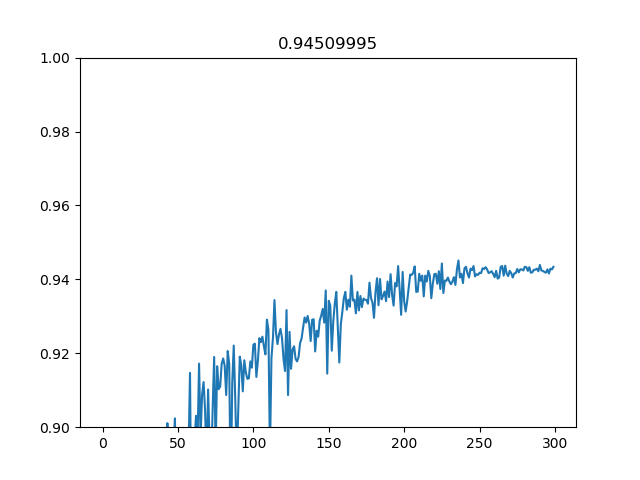
なお、Cosine Annealingでの学習曲線は次のようになります。Cosine Annealingちゃんと使うの初めてでしたが、これは結構良さそうです。実装も面倒ではないし、ステップの調整や指数の調整いらずにコサインカーブで脳死どーんなので、長めの訓練するときは使えるのではないでしょうか。
次のAugmentationですが、なんか万策尽きた感がぱないので、Auto Augmentのアイディアをパクってきました。Auto AugmentはPillowのImage Ops/Enchance機能をData Augmentationに組み込んでいるのが特徴で、よく使われるData Augmentationのようなアフィン変換操作に限定されないの面白いところです。具体的には、Auto Contrastのようなカラーヒストグラムをいじる操作、画像のシャープ化など、フォトレタッチソフトのようなことまで増強に含んでいるんですよね。ここまでData Augmentationを拡張してみましょう。
没になったケース
Mixupでもし今まで通りのStep Decayを使ったら?というケースです
- Mixup beta=0.2, 150epoch, Step Decay → 93.76%
- Mixup beta=0.1, 150epoch, Step Decay → 93.72%
今まで通りのStep Decayでは精度が悪くなってしまうのです。これはMixupの正則化が強すぎるので(既にもう相当正則化強いですが、Mixup入れると訓練精度よりテスト精度のほうが平均的に高いという現象が往々にして起こります)収束に時間がかかってしまうのです。
そのため、本来はもっと高い学習率で長時間訓練させなければいけないのを、Step Decayで学習率が低くなってしまい、単に収束していないからというのが精度の悪化原因です。Step Decayのどこで学習率を落とすかの調整も学習曲線見ながらやらないといけなくて結構大変なので、こうなるとコサインカーブみたいなCosine Annealingに頼りたくなります。
Cosine Annealingでの結果です。全て学習率の上限と下限は一緒(0.1、0.001)です。
- Mixup beta=0.2, 200epoch, Cosine Annealing → 94.17%
- Mixup beta=0.5, 300epoch, Cosine Annealing → 94.51%
- Mixup beta=1.0, 300epoch, Cosine Annealing → 94.47%
訓練エポック数を長くしたので強めのMixupも使えるようになりました。そこで0.5と1.0(1.0の場合は乱数が一様分布です)を試した結果、Mixupのβが0.5が最も良かったのでこれを採用しました。
6. Auto Contrast
Auto ContrastというとData Augmentationで使われるのは稀ですが、カラーヒストグラムのスケール調整です。コントラストが低い画像のカラーヒストグラムを引き伸ばして、コントラストを強調します。試してみたらAuto Contrastが結構効きました。
Mixupからの追加ですが、Auto ContrastはMixupの前に入れます。以降、Mixupは全て最後に入れることにします。
| 項目 | 設定値 |
|---|---|
| バッチサイズ | 128 |
| エポック数 | 300 |
| 学習率 | Cosine Decay(上限0.1、下限0.001のコサインカーブ) |
| ネットワーク | 10層CNN |
| Augmentation | RandomZoom(75%-125%) Color Shift(50) 回転(10°) Random Erasing(5%-20%) Auto Contast(cutoff 1%) Mixup(beta=0.5) |
ジェネレーターはこのようにします。50%の確率でAuto Contrastを入れます。
def auto_contrast(image, cutoff=0):
if np.random.rand() >= 0.5:
array = (image * 255).astype(np.uint8)
with Image.fromarray(array) as img:
autocon = ImageOps.autocontrast(img, cutoff)
return np.asarray(autocon, np.float32) / 255.0
else:
return image
def mode6_generator(X, y, batch_size):
for X_base, y_base in mode4_generator(X, y, batch_size):
X_batch = X_base.copy()
for i in range(X_batch.shape[0]):
X_batch[i] = auto_contrast(X_base[i], 1)
# mixup
yield mixup(X_batch, y_base, 0.5)
精度は95.07%と直近から0.56%も改善しました。ここまで煮詰まっている中で今までで最大のゲインが得られたのは正直びっくりでした。Augmentation次第で10層CNNでもエラー率5%切りできるのを見るとAugmentationって大事なんだなーと思い知らされます(逆に言うとネットワーク構造は論文いっぱい出てるけど、思っているほど重要ではなさそう)。
混同行列を見ると、犬のクラスが9割超えを達成できました。

Mixupの場合と比較するとどうかというと、Auto Contrastは安定的に上がっている(下がったとしてもわずか)というのが確認できます。Auto Contrastで大きく上がったクラスは、そもそもの画像のコントラストが不鮮明だったというケースです。

個別に見ていくと、鳥が924→945で2.1%の改善、鹿が945→963で1.8%の改善で、この2つが主に牽引しているのがわかります。鳥や鹿のような自然に溶け込む画像はコントラストが低かったのでしょう。
コントラストが不鮮明なのを鮮明にすると効くということは、同様にエッジを鮮明にする(画像のシャープ化をする)と精度がよくなるのではないかという仮説も浮かびます。これはAuto Augmentのポリシーでも、「ImageEnhance.Sharpness」というのが採用されているので、確かにやってみる価値はありそうです。他の没ケースについて述べてからシャープ化を試してみます。
没になったケース
Auto Contrastの中での没ケースです。PillowのAuto ContrastにはCutoffという引数があり、デフォルトでは0です。Cutoffの値を0より大きくするとスケール調整だけでなく、ヒストグラムの中から一部(おそらく低い値と高い値?)を捨てるということを行います。これによってより強いコントラスト補正ができるというわけです。
Cutoffの値を調整してみました。
- Cutoffなし : 94.98%
- Cutoff 0.5% : 94.92%
- Cutoff 1% : 95.07%
Cutoffによる有無は誤差挙動感ありますが、この中ではCutoff1%が最も良かったのでそれを使いました。
6+.(没) Equalize
ImageOps.autocontrastの亜種に、ImageOps.equalizeというのがあります。これはカラーチャンネル間のヒストグラムを均一化するという操作を行います。
autocontrastはスケール調整だけなので、RGBのヒストグラムは違うままですが、equalizeはヒストグラムの均一化をするので、個々の分散の情報がおそらく落ちてしまうのではないかと思われます。Auto ContrastしてからEqualizeするというケースを試しました。
これも同様に50%の確率でAuto Contrastしてから、50%の確率でEqualizeするというのを行いました。ちなみにLenaでAuto ContrastとEqualizeの違いを比較してみました。

CutoffなしのAuto Contrastは若干コントラストが強調され、色調はそのまま。Cutoff入れるとAuto Contrastは色調は作られた感じになりますが、コントラストが強調されていい感じになっています(この場合はたまたまうまく行っています)。Equalizeはこの場合は微妙ですね。
そしてEqualizeをData Augmentationを入れてもやっぱりうまくいきませんでした。
- CutoffなしのAuto Contrast→Equalize : 94.37%
- Cutoffが1%のAuto Contrast→Equalize : 94.51%
いずれも0.8%~0.5%の悪化となっています。やはり分散の情報を捨てるのはよくないですね。
7. シャープ化
最後のAugmentationとして画像のシャープ化を行います。シャープ化といっても、アンシャープまでできるのが面白いところで、「ImageEnhance.Sharpness」という関数を使います。
def sharpen(image, magnitude):
array = (image * 255).astype(np.uint8)
with Image.fromarray(array) as img:
factor = np.random.uniform(1.0-magnitude, 1.0+magnitude)
sharp = ImageEnhance.Sharpness(img).enhance(factor)
return np.asarray(sharp, np.float32) / 255.0
enhanceに食わせるfactorの値がポイントとなります。1ならもとの画像と同じ、1より小さくするとぼやけた画像に、1より大きくするとよりシャープな画像になります。

ただし、-10や10といった極端な値を放り込むと逆にノイズが出ます。シャープ化の差はlenaだと分かりづらいかもしれませんね。ジェネレーターはこんな感じに。
def mode7_generator(X, y, batch_size):
for X_base, y_base in mode4_generator(X, y, batch_size):
X_batch = X_base.copy()
for i in range(X_batch.shape[0]):
X_batch[i] = auto_contrast(X_base[i], 1)
X_batch[i] = sharpen(X_batch[i], 1)
# mixup
yield mixup(X_batch, y_base, 0.5)
設定は以下の通り。
| 項目 | 設定値 |
|---|---|
| バッチサイズ | 128 |
| エポック数 | 300 |
| 学習率 | Cosine Decay(上限0.1、下限0.001のコサインカーブ) |
| ネットワーク | 10層CNN |
| Augmentation | RandomZoom(75%-125%) Color Shift(50) 回転(10°) Random Erasing(5%-20%) Auto Contast(cutoff 1%) Random Sharpness(1±1) Mixup(beta=0.5) |
結果は95.30%(0.27%の改善)となりました。magnitude=1で満足してしまったけど、もうちょっと調整すれば上がるかもしれません。しかし、10層のCNNで95.30%なんて出るなんてびっくりですね。

ベースライン(Standard Augmentationだけ)との混同行列の比較です。こうしてみると明らかに良くなっているのがわかりますね。

精度向上に特に寄与したのが押し上げたのは猫(6.1%)、鳥(4.9%)とカエル(3.3%)でした。犬も1.9%の改善となっているので、焦点の犬猫の誤分類を中心としたAugmentationは一応は達成されたということになります。「データのお気持ちを考えながらやる」Augmentation、なんとなくこんな感じというのがわかったでしょうか。
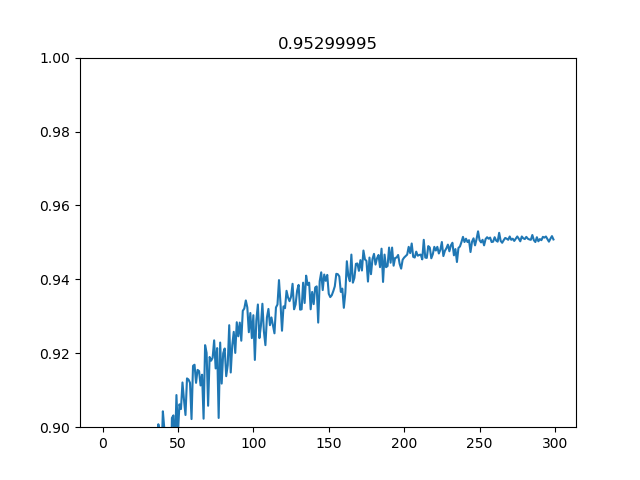
学習曲線はこのようになりました。
Wide ResNet 28-10でAuto Augmentと比較
ではこのオレオレAugmentationがどのぐらいの性能を出すかAuto Augmentと比較してみます。Auto Augmentの論文によると、Wide ResNet 28-10ではエラー率2.6%±0.1%を記録しました。
Auto Augmentの公式のWide ResNetの実装はTensorFlow(非Kerasなのですが)、それを自分がKerasに書き換えました(ちょこっといじっただけ)。それを実行したところ、精度は97.3%とエラー率で2.7%となりました。つまり、このオレオレAugmentationがほぼAuto Augment気持ちマイナス程度の精度は出せたということになります。Auto Augmentは最適なポリシーを見つけるのにGPUで5000時間かかったとのことなので、多分オレオレの人力のほうが速いはずです(一週間程度でここまでいけました)。
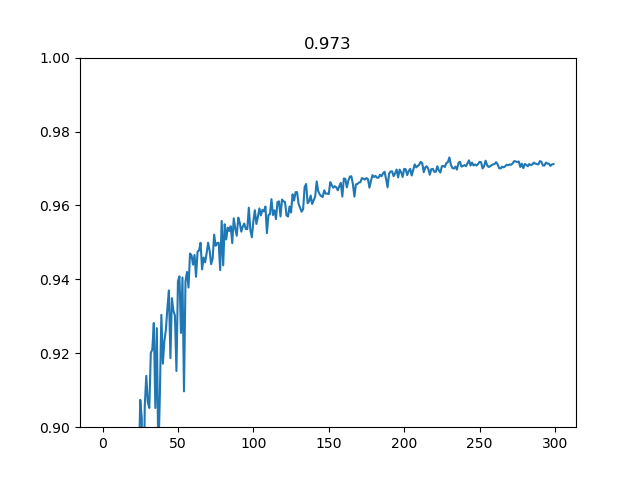
ネットワーク以外は7の設定と同じです。このときの混同行列は次のようになります。

10層CNNが係数2M弱で95.3%、WideResNet 28-10が係数35M程度で97.3%なので、係数に見合った分の精度は出ているということになります。しかしこうして考えるとモデルを大きくして精度を確保するというのは、コスパ的にはあまりよろしくなさそうな感はあります。もちろんSOTAを取りたいのなら別でしょうが。
10層CNNのベースライン、10層CNNの最終段階、WideResNetの最終段階の混同行列の比較は次のようになります。

こうして見ると、間違いやすいクラスというのは、ネットワーク問わずあまり変わらないというのがわかります。ネットワークの深さはあくまで全体の精度を押し上げているだけで、特定のネットワークが特定のクラスを検出しやすかったり、ネットワーク間で得意なクラスに偏りがあるのようなケースは今回は確認できませんでした。
WideResNetの個々のエラー分析を見てみましょう。97.3%なので個数が相当減っています。

「本当は猫で予測が犬」のケースです。33件まで減っています。

こちらは「本当は犬で予測が猫」のケースです。31件まで減っており、犬猫のミスは合計で64件となりました。ベースラインから半分ぐらいになっています。こうしてみると、白黒の犬・猫は依然として間違いやすいというのがわかります。

件数としてはぐっと減りますが、「本当はトラックで予測が自動車」のケースです。14件です。半分ぐらいは人間でも「これ自動車でしょ」みたいなケースがあるので、これは間違っても仕方がないかなと思います。

「本当が飛行機で予測が船」のケースです。これはベースラインでもありましたがぐっと減って10件となりました。もうちょっと細部の構造見てくれるといいかもしれませんね。

「本当が鳥で予測が猫」のケースです。形だけ見ると猫とあんまり変わらないような気がします。言われないと気づかないような。くちばしのような形状に着目してくれるといいんですけどね。
精度推移まとめ
カテゴリー別、全体がどのように精度向上してきたかをまとめます。
クラス別精度
| 正答率 | DAなし | Base | 1(ズーム) | 2(色調) | 3(回転) | 4(RE) | 5(Mixup) | 6(AC) | 7(Sharp) | 7+(WRN) |
|---|---|---|---|---|---|---|---|---|---|---|
| 飛行機 | 90.0 | 94.9 | 94.6 | 93.2 | 94.5 | 93.3 | 94.9 | 94.5 | 95.3 | 97.3 |
| 自動車 | 94.7 | 97.1 | 97.8 | 98.5 | 97.7 | 98.0 | 98.8 | 98.7 | 98.4 | 99.1 |
| 鳥 | 85.1 | 89.7 | 89.3 | 91.3 | 91.7 | 93.1 | 92.4 | 94.5 | 94.6 | 96.3 |
| 猫 | 74.8 | 84.8 | 84.2 | 87.6 | 85.2 | 85.1 | 88.2 | 88.5 | 90.9 | 93.8 |
| 鹿 | 88.1 | 94.8 | 94.2 | 93.8 | 94.5 | 95.8 | 94.5 | 96.3 | 95.2 | 97.3 |
| 犬 | 84.1 | 88.0 | 88.7 | 87.1 | 88.4 | 89.6 | 89.8 | 90.6 | 89.9 | 95.1 |
| カエル | 91.8 | 94.5 | 97.6 | 97.4 | 98.0 | 97.9 | 97.4 | 97.9 | 97.8 | 98.6 |
| 馬 | 92.5 | 96.3 | 95.5 | 94.1 | 96.3 | 96.5 | 96.7 | 96.5 | 97.1 | 98.9 |
| 船 | 94.2 | 95.4 | 95.8 | 96.0 | 96.4 | 97.3 | 96.8 | 97.0 | 97.6 | 98.6 |
| トラック | 92.8 | 96.0 | 96.1 | 96.5 | 96.7 | 95.1 | 96.1 | 95.8 | 96.3 | 97.7 |
| 全体 | 88.95 | 93.18 | 93.36 | 93.64 | 93.94 | 94.14 | 94.51 | 95.07 | 95.30 | 97.30 |
ベースラインとの差分
ベースライン(Standard Data Augmentation)との差分です。クラス別精度をBaseの値から引いたものです。
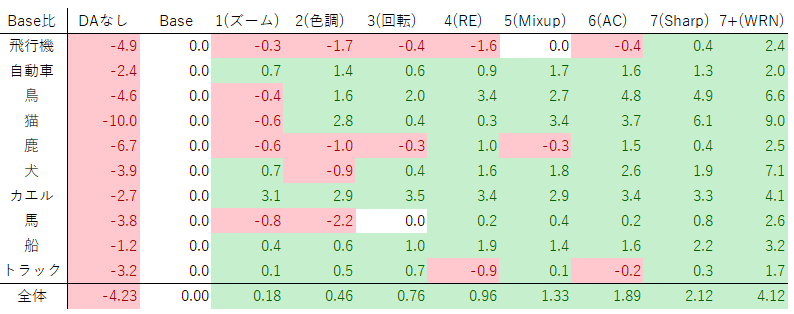
これを見ると、7番目のAugmentationを入れてようやく全クラスがベースラインよりプラスとなる結果になりました。飛行機なんかは1~4までのAugmentationが逆効果になっているのがわかります。
直近との差分
こちらは直近のAugmentationとの差分です。例えば飛行機の7(Sharp)だったら、7(Sharp)の飛行機の正答率の95.3から、6(AC)の飛行機の正答率の94.5を引いて「0.8」となります。
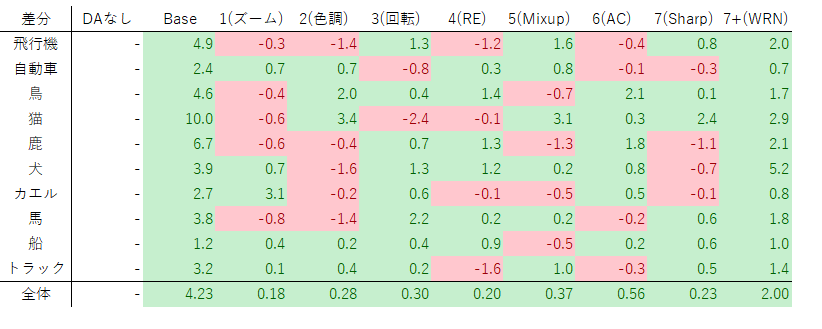
これを見ると、Augmentationにもクラス別に得意不得意があるというのがわかります。均して見ると精度が微増でも、クラス別に見ると、大きく精度が上昇しているケースもあれば、逆に精度が落ちて足を引っ張っているケースもあります。ただし、10層CNN→WRNのようなネットワークレベルでの拡張はどのクラスでも精度が上がっていることが確認できます(それはそう)。
Augmentation効果が高かったもの低かったもの
10層CNNの範囲内でベースライン以降、特に上昇幅の大きかったAugmentation、クラスを列挙すると次のようになります。これらは追加したAugmentationが効きが良かったというケースです。2%以上の上昇のものを列挙しました。
- ズームのカエル 3.1%
- Color Shiftの鳥 2.0%
- Color Shiftの猫 3.4%
- 回転の馬 2.2%
- Mixupの猫 3.1%
- Auto Contrastの鳥 2.1%
- シャープ化の猫 2.4%
効果が高かったものはなんかわかりすい気がします。カエルはそもそも小さい生物なので、ズームをしてあげることでよりカエル本体が中心にきやすくなるのでしょう。色調補正は猫や特に鳥のようにカラーバリエーション豊富な生物で効いています。ただ、犬猫は決定境界が割と曖昧で、色調補正で猫は大きく上昇していても、犬で大きめの下落があるので、そこは割り引いて考える必要があります。回転の馬は何なんでしょうね。馬は姿勢が斜めになるような写真がありそうなので、そこの補正が効くのでしょうか。猫にダイレクトに効いているのはMixupで、犬側の悪化もありません。犬猫のように決定境界が曖昧なケースでは、Mixupのようなソフトラベルはかなり有効ではないかと思われます。Auto Contrastはくすんだ画像で有効でしょう。カットオフを入れなければ副作用はほとんどないはずなので、これは入れてみるといいと思います。Normalizationと似たような効果があるはずです。シャープ化が猫で効いたのは謎ですが、補正の過程で輪郭絡みのAugmentationが入るので、Adversarial Exampleを使ったAugmentationに近いようなことをやっているのかもしれません(素人なのでよくわからん)。
逆に精度が下がってしまったケースも列挙します。これはAugmentationの副作用があったケースです。1%以上の下落のものを列挙しました。
- Color Shiftの飛行機 -1.4%
- Color Shiftの犬 -1.6%
- Color Shiftの馬 -1.4%
- 回転の猫 -2.4%
- Random Erasingの飛行機 -1.2%
- Random Erasingのトラック -1.6%
- Mixupの鹿 -1.3%
- シャープ化の鹿 -1.1%
色調補正は諸刃の剣で、カラーバリエーションが豊富なクラスでは有効ですが、飛行機や馬のように割と色が固定されるようなケースでは精度の悪化が目立ちます。回転の猫は謎ですが、混同行列を見ると鳥、鹿、犬といった生物への誤答が増えているので、猫があんまり取らないような角度に補正すると他の生物へ誤答してしまうのでしょう。Random Erasingの副作用は飛行機やトラックのような機械で目立ちます。この副作用は船やトラックといった近いクラスに誤分類されてしまうことです。Random Erasingは生物の分類のように特徴的な形質以外に注目してほしいときは有効ですが、機械のようにある特定の部分が重要なファクターとなっているケース(例えばトラックだったら荷台、飛行機だったら空や尾翼)では逆効果ということがわかります。Mixupの鹿、シャープ化の鹿も猫、カエル、馬といった周辺の生物への誤答が増えています。Mixupもシャープ化の副作用(特に鹿みたいな輪郭が多いやつで出やすい?)も、ぼやけたり、エッジ周りのノイズが増えたりするので、Auto Contrastのような鮮やかにする系で精度が伸びる鹿のクラスでは逆効果なのでしょうか。
副作用のほうはあんまりわかりやすい結果にはなりませんでしたが、なんとなくそれっぽい理由はありそうです。
コード
Wide ResNetは関数部分だけいい感じにコピーして使ってください。
まとめ
データのお気持ちを考えるの意外と深かった。混同行列の推移見るのや、間違ったやつをプロットしてみるエラー分析意外と使えるかもしれない。ということでした。「なんでこういうAugmnentationするんや?」みたいなもやもやが消えて割とすっきりしました。一度こういうのやってみるといいかもしれませんね。
また、Mixup以降見たように、従来のData Augmentationでは触れられない一般的な画像処理:オートコントラストやシャープ化といった処理も、精度向上に効くことが確認できました。移動や回転といったアフィン変換系ばっかりやっている場合はこっちも考慮に入れてみるといいかもしれませんね。
WRNしか調べていませんでしたが、オレオレAugmentationでAuto Augmentに近い精度が出せたのはびっくりしました。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー