
論文まとめ:OmniGen: Unified Image Generation


- タイトル:OmniGen: Unified Image Generation
- 著者:Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Shuting Wang, Tiejun Huang, Zheng Liu (BAAI)
- 論文URL:https://arxiv.org/abs/2409.11340
- GitHub:https://github.com/VectorSpaceLab/OmniGen(MIT)
- デモ:https://huggingface.co/spaces/Shitao/OmniGen
目次
ざっくりいうと
- テキストと画像の両方を条件として受け入れ、多様な画像生成タスク(テキスト画像生成、画像編集、制御可能な生成など)を単一のモデルで実現する統一的な画像生成モデルOmniGen
- VAEとTransformerを主要コンポーネントとし、追加のエンコーダーを不要にしてシンプルかつユーザーフレンドリーな構造を実現*。さらに、多様なタスクを学習するために大規模で多様な画像生成データセット「X2I」構築。
- GenEvalベンチマークでSD3に匹敵する性能を示し、EMU-EditデータセットではInstructPix2Pixを大きく上回る性能を達成し、多様なタスクにおいて高品質な画像生成能力を示した。
論文要約By Gemini 1.5 Pro
課題: 複数の画像生成タスクを単一のフレームワークで処理できる統一モデルの開発。
先行研究の課題: 既存の画像生成モデルはタスク特化型であり、テキスト画像生成、画像編集、制御可能な生成などを単一モデルで処理できなかった。
提案手法の独自性:
* OmniGen は、テキストと画像の両方を条件として受け入れ、多様な画像生成タスクを単一モデルで実行できる拡散モデル。
* 追加のエンコーダを必要とせず、テキストと画像を単一モデルで処理することで、既存モデルよりもシンプルかつユーザーフレンドリー。
手法:
1. VAEを用いて画像から特徴量を抽出。
2. Transformerモデルを用いて、テキストと画像の条件に基づいて画像を生成。
3. 統一された画像生成データセット X2I を構築し、多様なタスクを学習。
評価:
* 定量評価: GenEvalベンチマークでSD3に匹敵する性能。EMU-EditデータセットでInstructPix2Pixを大きく上回る性能。
* 定性評価: テキスト画像生成、画像編集、主題に基づく生成など、多様なタスクにおいて高品質な画像生成能力を示した。
限界: 長いテキストのレンダリング、複雑な画像の細部の生成、未知の画像タイプの処理に課題が残る。
次に読むべき論文:
* Stable Diffusion https://arxiv.org/abs/2112.10752
* DALL-E 2 https://arxiv.org/abs/2204.06125
* ControlNet https://arxiv.org/abs/2302.05543
コード: https://github.com/VectorSpaceLab/OmniGen

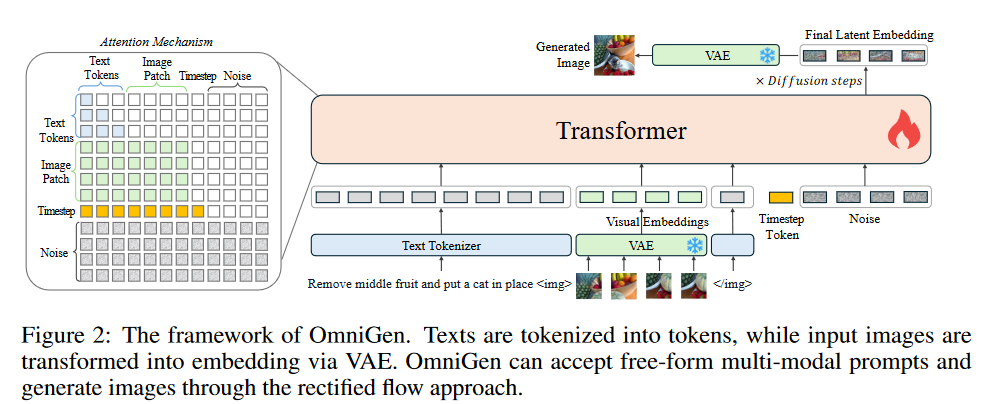
概要
- これまでのよくある画像生成モデル:テキストエンコーダー+U-Net+VAE→タスクスペシフィック
- OmniGenはLLM(VLM)ベースのアーキテクチャで、プロンプトでタスクを定義
- VisuialEncoderがなく、VAEとTransformerが主要コンポーネント
- VAEはSDXL、VLMはPhi-3を用いる
- Phi-3はテキスト処理能力を活用
X2I Dataset
- ロバストなマルチ処理能力を実現するために、X2I Datasetを構築。大規模で多様なデータセットがまだ出現していない。1億枚(0.1B)の画像からなる。
テキスト→画像
- SAM-LLaVA、ShareGPT4V、LAION-Aestheticなど容易に入手可能なデータセットを活用
- 多くの研究で、合成された詳細なキャプションによりモデルを大幅に改善できることがわかっている
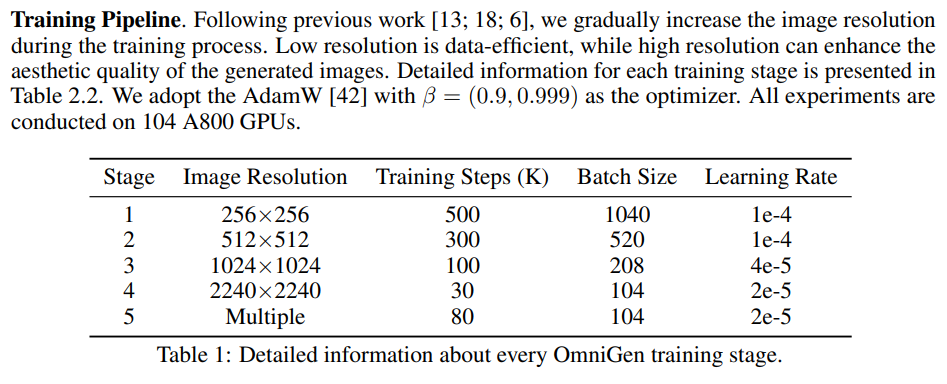
- 学習の初期はPublicデータの全画像、Stage3以降は高画質な内部データのみ使用し、美的品質を向上
- InterVL2を活用し、内部データとLAION-Aestheicの合成アノテーションを作成。他のデータは詳細なアノテーションがあり、合成は不要
混合モーダルプロンプト
一般的な混合モーダルプロンプト

画像編集(SEED-Data-Edit [19]、MagicBrush [72]、InstructPix2Pix [4])、人間の動き(Something-Something [23])、仮想試着(HR-VITON [31]、FashionTryon [75])、スタイル転送(stylebooth [24])
など、これはペアで使用
またControlNetでよく使っている視覚条件を利用する問題のために、Canny、HED、Depth、Skeleton、Bounding Boxの視覚条件を学習(MultiGenデータセット)
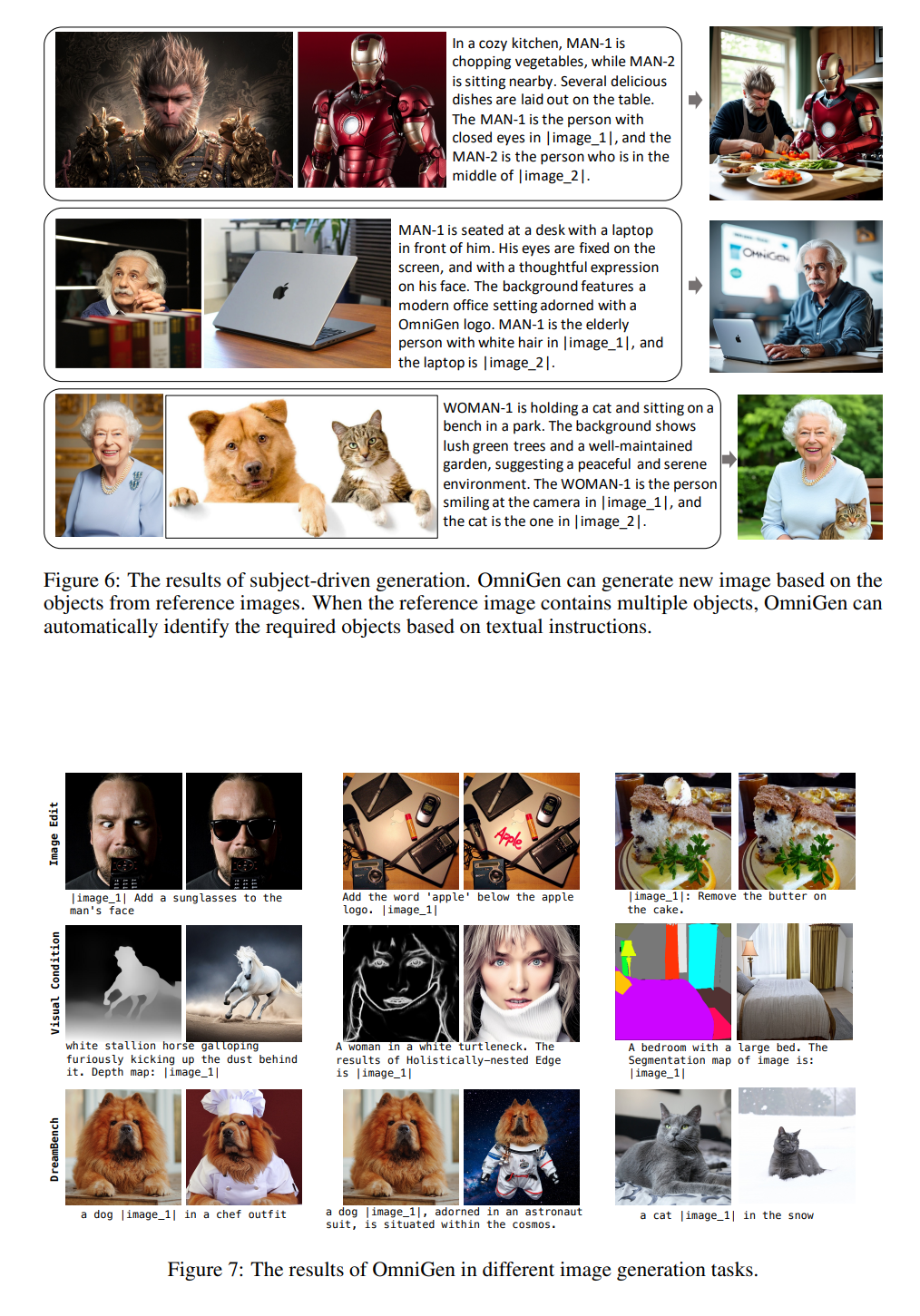
被写体駆動型画像生成
GRIT-EntityデータセットとWeb Imagesデータセットの両方を構築。SAMやGrounding DINO(セグメンテーション)、MS Diffusionによる合成を活用し、データセットを構築。

結果
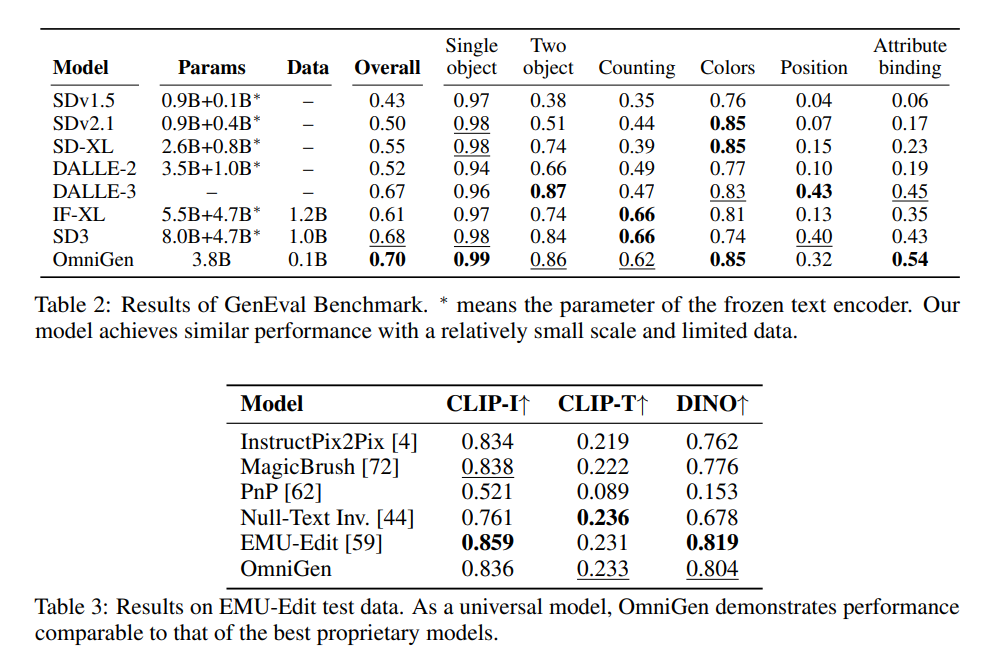
上が画像生成、下が画像編集の定量結果。定量評価はGenEvalベンチマーク
画像編集は、CLIP-Iがソース画像vs出力画像、CLIP-Tが出力画像vsキャプションの類似度。DINO:DINOのEmbeddingを使った画像間類似度
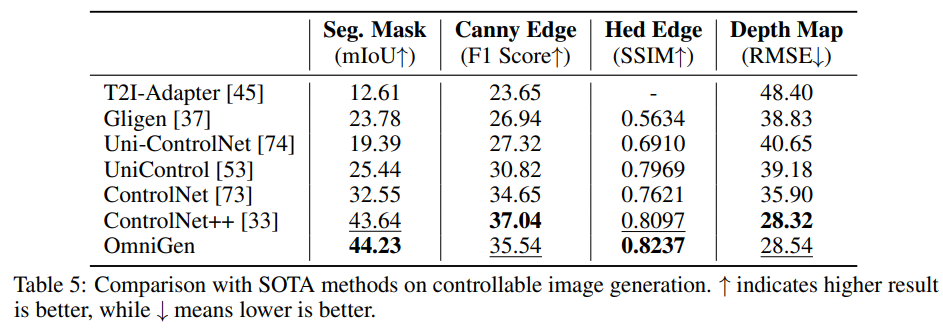
視覚条件つきのコントロールでは、ControlNetよりも性能が良い

上がOmnigenの推論能力
下はアニメデータ画像データセットを用意し、PAINTS-UNDOモデルを使って、各段階をシミュレート。8フレームを選択肢、ステップバイステップの画像生成を行うためのファインチューニングをした。
→できてはいるものの、最終的に生成された画像の品質のクォリティが元のモデルより低い課題がある。
しかし、ブラックボックスの拡散モデルの生成を待つのではなく、積極的に介入するアプローチは今後の有望な方向性であると主張。

所感
- すごい!
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー