
論文まとめ:RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation


- タイトル:RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
- 著者:Dongyu Ru, Lin Qiu, Xiangkun Hu, Tianhang Zhang, Peng Shi, Shuaichen Chang, Cheng Jiayang, Cunxiang Wang, Shichao Sun, Huanyu Li, Zizhao Zhang, Binjie Wang, Jiarong Jiang, Tong He, Zhiguo Wang, Pengfei Liu, Yue Zhang, Zheng Zhang(AWSなど)
- URL:https://arxiv.org/abs/2408.08067
- GitHub:https://github.com/amazon-science/RAGChecker/ (Apache 2.0)
目次
ざっくりいうと
- Retrieval-Augmented Generation (RAG) システムの評価を目的とした新しい詳細なフレームワークRAGChecker
- 取得されたコンテキストと生成された応答をクレームレベルで評価し、検索モジュールと生成モジュールの両方を診断
- GitHubで公開されており、評価データセットに基づいて人間の判断と高い相関を示すことが実証
論文要約 Gemini 1.5 Pro
60秒で読める論文要約
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
60秒で読める論文要約
・この論文において解決したい課題は何?
Retrieval-Augmented Generation (RAG) システムの包括的な評価が、RAGのモジュール性、長文応答の評価、測定の信頼性のために難しいという課題を解決したい。
・先行研究だとどういう点が課題だった?
先行研究では、評価指標がルールベースだったり粗粒度だったりして、正確で解釈可能な結果を提供できなかった。また、検索モジュールと生成モジュールの相互作用を評価する指標が不足していた。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
提案手法であるRAG CHECKERは、検索と生成の両方のモジュールに対して、詳細な診断指標を組み込んだ、新しい詳細な評価フレームワークである。これは、応答レベルの評価ではなく、詳細なクレームレベルのチェックに基づいているため、エラーの原因に関する実用的な洞察を提供する。
・提案手法の手法を初心者でもわかるように詳細に説明して
RAG CHECKERは、ユーザーのクエリ、取得されたコンテキスト、応答、および正解を用いて、以下の指標を生成する。
- 全体指標: 生成された応答の全体的な品質を評価し、システムのパフォーマンスの全体像を提供する。
- 診断検索指標: ナレッジベースから関連情報を見つける際の検索モジュールの有効性を評価し、その長所と短所を特定する。
- 診断生成指標: 生成モジュールが取得されたコンテキストをどのように利用し、ノイズの多い情報をどのように処理し、正確で忠実な応答をどのように生成するかを診断し、そのパフォーマンスを評価する。
これらの指標は、応答と正解からクレームを抽出し、他のテキストに対してそれらをチェックするというクレームレベルの含意チェックに基づいている。
・提案手法の有効性をどのように定量・定性評価した?
提案された指標と人間の判断との相関関係を評価するために、人間の判断データセットに注釈を付け、メタ評価を実施した。このメタ評価により、人間の視点からRAGシステムの品質と信頼性を捉えるR AG CHECKERの有効性が検証された。また、10のドメインにわたる公開データセットから再利用したベンチマーク上で、8つの最先端のRAGシステムを評価する包括的な実験を通じて、RAG CHECKERの有効性を実証した。
・この論文における限界は?
検索モジュールの診断指標は、生成モジュールの指標ほど洞察力に富んでいない。また、提案された指標は、生成された応答を評価する際に、RefCheckerからの「中立」と「矛盾」のチェック結果を区別していない。さらに、評価ベンチマークは既存のテキストのみのデータセットに基づいており、英語のクエリとコーパスに限定されている。
・次に読むべき論文は?
論文中で参照されている、TruLens [6], RAGAS [5], ARES [35], CRUD-RAG [25] などのRAG評価フレームワークに関する論文を読むと良いでしょう。
・論文中にコードが提示されていれば、それをリンク付きで示してください
この論文のコードは、https://github.com/amazon-science/RAGChecker にて公開されています。
先行研究
- 伝統的指標
- 検索部分:Recall@kやMRR:知識ベースの完全な意味的範囲にかける
- 生成部分:n-gram(BLEUやROUGE)、Embedding:簡潔な回答ではうまくいくが、長い回答での検知ができない
- 先行研究:RAGAS、TruLens、ARES
- きめ細かな評価指標を提供をしている
- 本研究:すべてきめ細かいクレームレベルのチェックに基づいており、エラーの原因に対する実用的な洞察を提供するように設計
- 私の注釈:特にRAGASはFew-shotで使っている例をそのままテンプレートとして使っていいのか?
- Contribution
- RAG C HECKER は、レトリーバとジェネレータの両方のコンポーネントに対してきめ細かい評価を提供する新しい RAG評価フレームワークであり、エラーの原因に対する実用的な洞察を提供する新しい診断メトリクスを導入している。
- メタ評価を行い、R AG C HECKERが他の評価指標よりも人間の判断との相関が有意に優れていることを検証した。
- 我々は、10のドメインにわたって、我々のキュレーションされたベンチマーク上で8つのRAGシステムを評価する広範な実験を行い、検索改善とノイズ導入のトレードオフ、忠実なオープンソースモデルがコンテキスト上の信頼を盲目にする傾向などの貴重な洞察を明らかにする。
設計原理
- 2つの主要ペルソナを想定し、両者に対応するため「Overall」「Retriver」「Generator」を区分
- 最初のペルソナ:RAGの全体を気にするユーザー:最高の性能を持つシステムを選択
- ランク付けするための単一の値のメトリックを好む
- 2つ目のペルソナ:RAGシステムの改善を充填をおき、エラーの原因や改善の余地の特定。2つの原因からなる
- 検索エラー:Retriverが関連するコンテクストを返さない場合
- 生成エラー:コンテクストから関連する情報を特定し、活用するのが課題
- 最初のペルソナ:RAGの全体を気にするユーザー:最高の性能を持つシステムを選択
RAG Checkerの指標
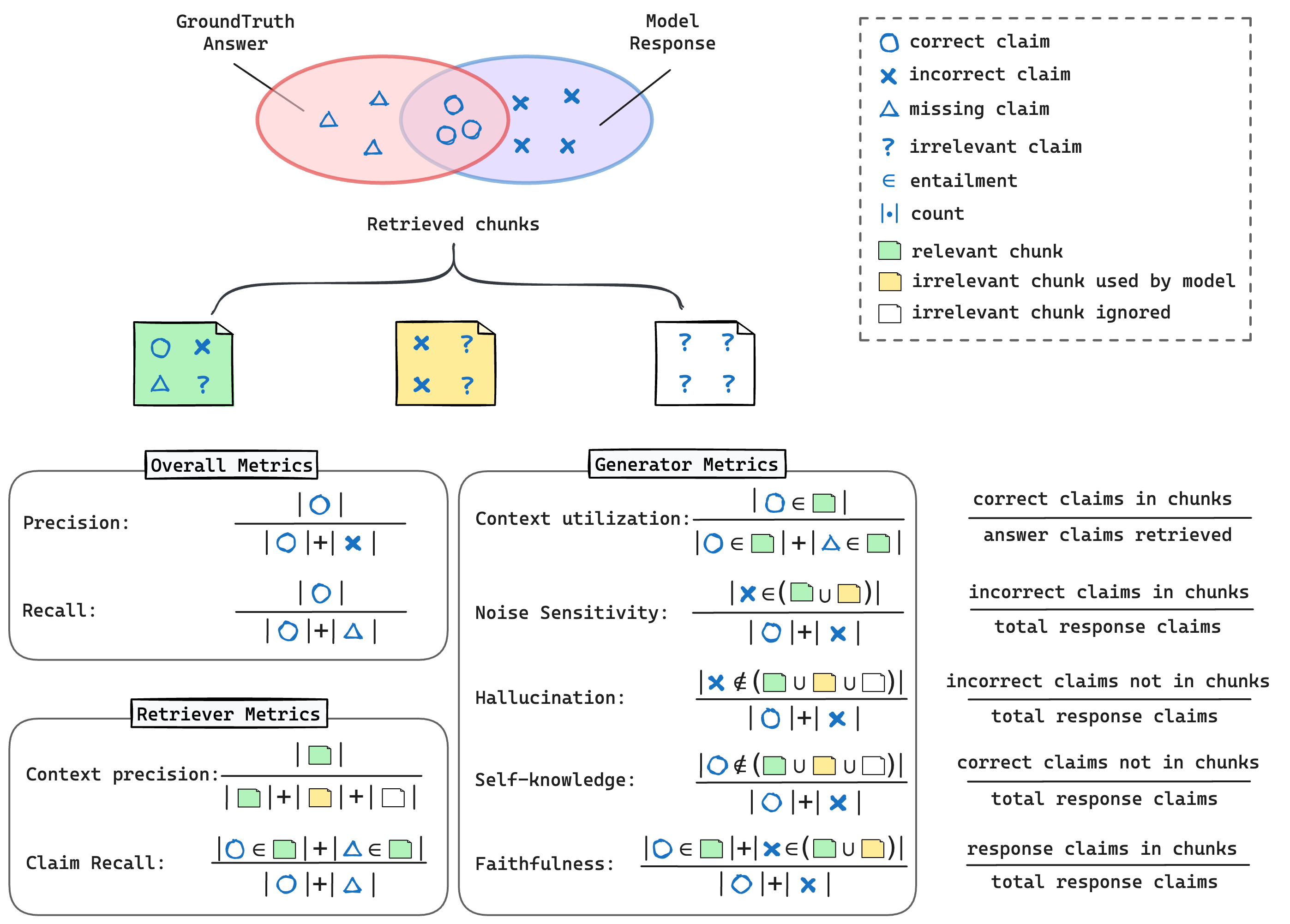
クレームレベルとは
- RAGの回答には、正しいクレーム(主張)(◯)と正しくない主張(☓)が含まれ、クレーム単位に分解して考えることが重要
- 以下の2つを作る
- クレーム抽出器
- クレームが参照テキストRefに含まれるかどうかの内包チェッカー
検索部分の指標
- 完全なレトリーバーは、真実の答えを生成するために必要なすべての主張を正確に返す
- チャンクレベルの精度は、クレームレベルの精度よりも優れた解釈可能性を提供するが、チャンクとは無関係な情報や誤解を招く情報を含んでいる可能性がある
- チャンク単位のPrecision
- クレーム単位のRecall
生成部分の評価
- 生成器の結果は検索されたチャンクに依存するため、その性能の異なる側面を特徴付ける合計6つのメトリクスを提供する。
評価
- 評価システムの結果を、アノテーターを使って人間が評価
- 有意に良い、やや良い、同点、やや悪い、有意に悪い
- 検索:BM25とE5-Mistral
- ジェネレーター:GPT-4、Mixtral8x7B、Llama3-8B、Llama3-70B
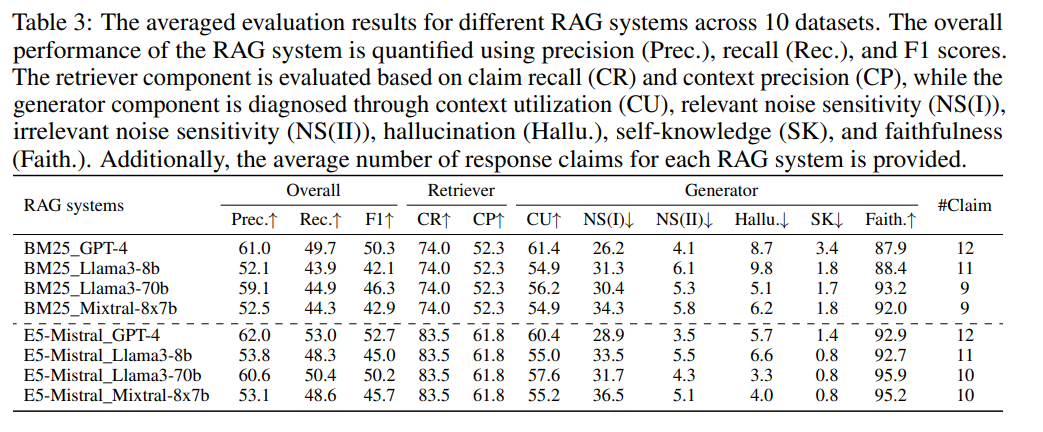
評価システム間の比較
評価指標×(生成モデル/検索方法)による比較
OSS的な詳細
- Ground Truthのデータが必要
- checking_inputs.jsonによるテンプレートがあるのはRAGASと同様だが、変更ができる
所感
- 評価ツールの利用者のペルソナまで考慮して設計しているのが◎
- OSS的に使いやすそう
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー