
論文まとめ:When Do We Not Need Larger Vision Models?


モデルサイズを拡大する従来のアプローチに対し、入力画像の解像度を複数スケールで処理する「S2」手法を提案します。既存の小さなビジョンモデルでもパラメータ数を増やすことなく、多くのタスクで大規模モデルを凌駕する性能を達成できることを示した。
- タイトル:When Do We Not Need Larger Vision Models?
- 著者:Baifeng Shi, Ziyang Wu, Maolin Mao, Xin Wang, Trevor Darrell(UC Berkeley+Microsoft)
- URL:https://arxiv.org/abs/2403.13043
- カンファ:ECCV 2024
- GitHub:https://github.com/bfshi/scaling_on_scales
目次
論文要約 By Gemini 2.5 Pro
・この論文において解決したい課題は何?
より高性能なAIのためにモデルサイズを大きくし続けるのが一般的ですが、本当に常に大きなモデルが必要なのか?という疑問に答え、代替案を示すことです。
・先行研究だとどういう点が課題だった?
主にモデルサイズを大きくすることで性能向上を目指していましたが、計算コストやメモリ消費が増大する点が課題でした。また、マルチスケール処理は特定モデル向けだったり、汎用的な解決策ではありませんでした。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
独自性は、既存の小さなモデルを凍結したまま、入力画像の解像度を複数スケールに変えて処理する「S2 (Scaling on Scales)」という手法を提案した点です。これにより、パラメータ数を増やさずに、大きなモデルと同等以上の性能を多様なタスクで達成できることを示し、特にMLLMの詳細理解ではGPT-4Vを超える成果も報告しています。
・提案手法の手法を初心者でもわかるように詳細に説明して
S2とは、1枚の画像を様々なサイズ(例:小さいまま、2倍、3倍)に拡大・縮小します。大きな画像は、元のAIモデルが学習したサイズに分割して入力し、それぞれの結果を賢く統合します。これにより、AIは同じ物体を色々な大きさで見ることになり、細部から全体像までより深く理解できるようになります。モデル自体を大きくするのではなく、見せ方を変える工夫です。
・提案手法の有効性をどのように定量・定性評価した?
画像分類、セグメンテーション、深度推定、マルチモーダルLLM、ロボット操作といった幅広いタスクで、S2を用いた小さなモデルと、より大きなモデルの性能を比較しました。計算量(GFLOPS)が同程度の場合、S2を用いた方がパラメータ数が少なく、性能も同等かそれ以上であることを示しました。特にMLLMでは、S2によって細かい部分の理解度が向上し、GPT-4Vを超える例も定性的に示しています。
・この論文における限界は?
非常に稀なケースや曖昧な画像の認識では、依然として大きなモデルの方が得意な場合がある点です。また、S2をどのサイズのモデルに適用するのが最適かは、モデルやタスクによって変わる可能性があります。
・次に読むべき論文は?
本論文の考察で触れられている「スケール選択的処理」や「単一画像の並列処理」に関する研究、例えば人間の視覚的注意メカニズムに関する論文 (Itti & Koch, 2001など) や、本研究で比較対象となったDINOv2やLLaVAのような高性能モデルの原論文が良いでしょう。
・論文中にコードが提示されていれば、それをリンク付きで示してください
はい、提示されています。
https://github.com/bfshi/scaling_on_scales
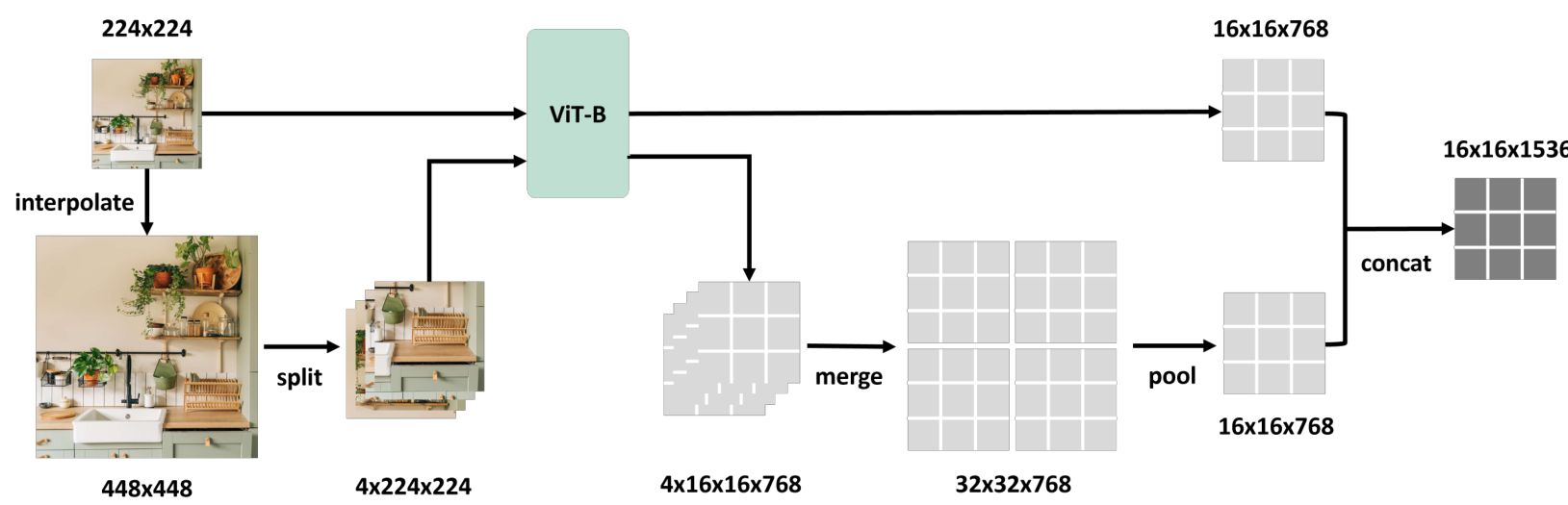
補足
- 事前に訓練され凍結された小さなビジョンモデル(例えば、ViT-BやViT-L)は、分類、セグメンテーション、深度推定、マルチモーダルLLM(MLLM)ベンチマーク、ロボット操作において、より大きなモデル(例えば、ViT-HやViT-G)を凌駕することができる
- より大きなモデルは、難しい例に対してより良い汎化を行うという利点があるが、我々は、より大きなビジョンモデルの特徴は、マルチスケールの小さなモデルの特徴でうまく近似できることを示す。
画像スケールでのスケーリングはモデルサイズでのスケーリングに勝る
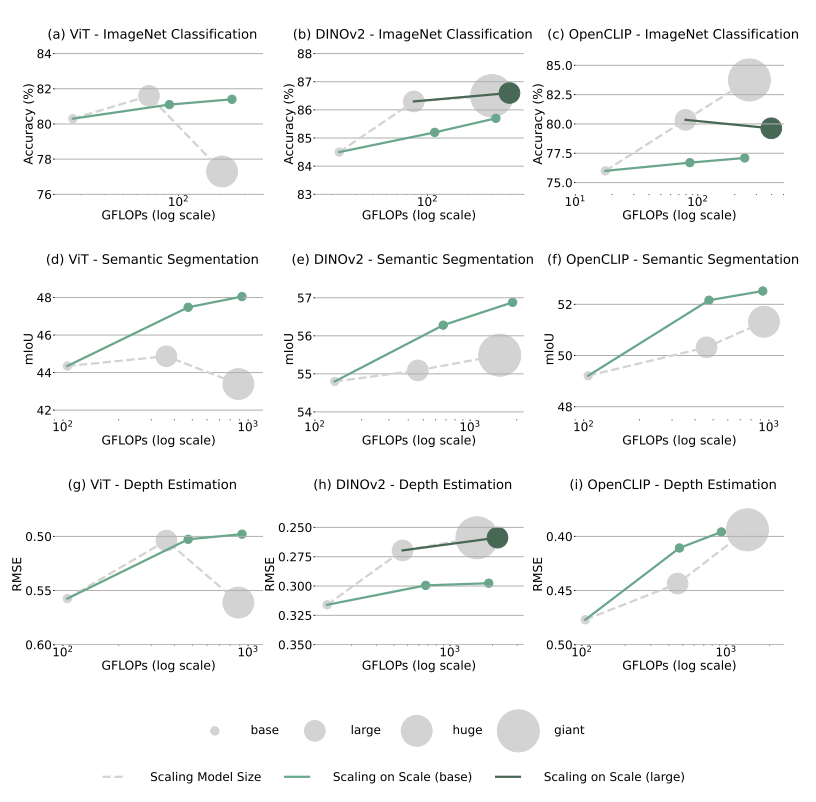
上が画像分類、中がSemantic Segmentation、下がDepth Estimation
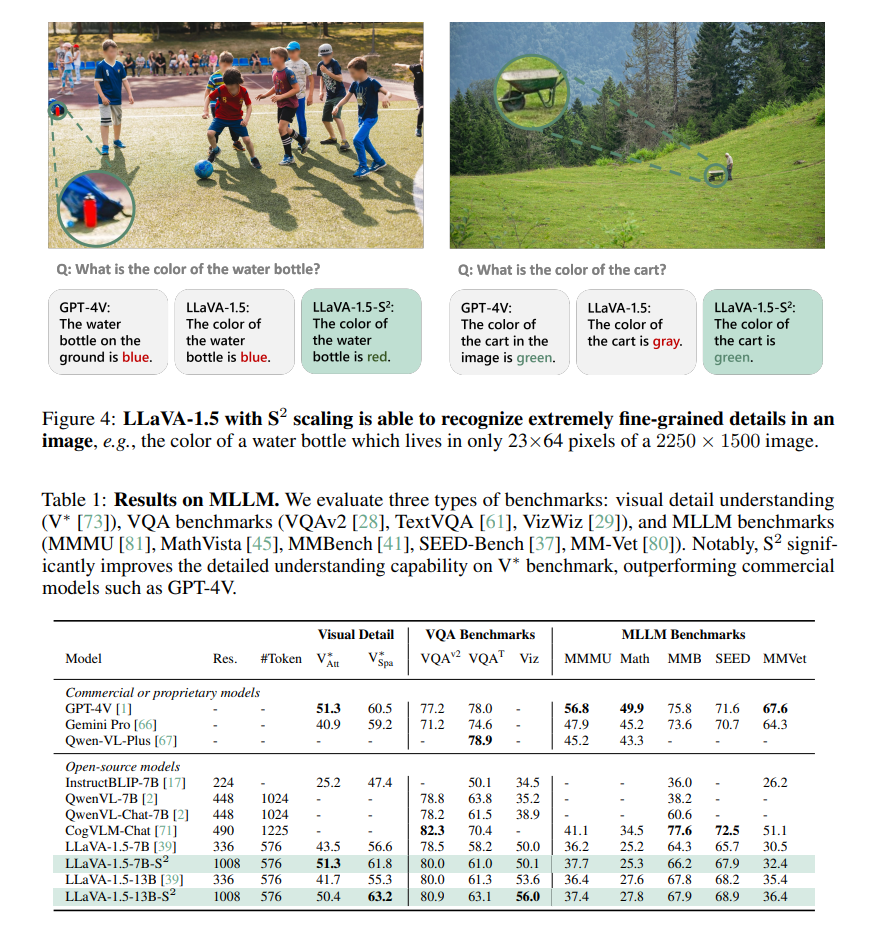
VQAでも同じ結果になった。小さいオブジェクトで正確に当てられている
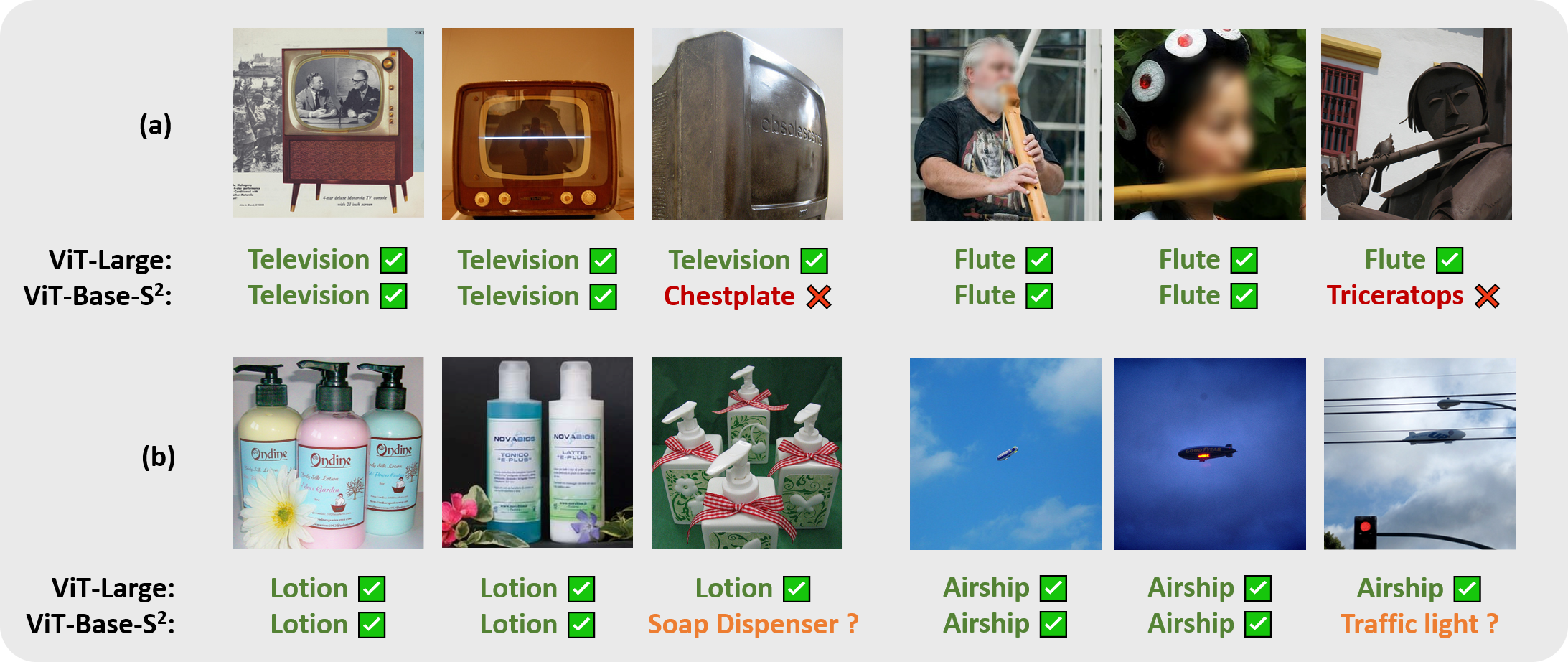
大きいモデルのほうが強いケース
より大きなモデルは難しい例でより良く一般化する
上が稀なケース、下が曖昧なケース。これらはS2よりも大きなモデルのほうが強い
小さなモデルは大きなモデルが何を学習するか?
- 大きなモデルの特徴量と、小さなモデルの特徴量、小さなモデル+S2による特徴量の相互情報量を比較(Table 2を比較)
- 大きなモデルを超えることはないが、S2を使うことでより多くの情報が最構成できる
S2による事前学習は小さなモデルをより良くする
- 事前学習時にS2を使ったところ、ViTの精度が良かった
testing-time augmentationと何が違う?
- Testing-time Augmentation(TTA)は昔から使わっており、マルチ解像度は検出やセグメンテーションのデフォルトの方法
- おそらく基盤モデルや事前学習として使うの文脈まで切り込んだのが新規性?
- ViTのマルチ解像度(モデルのアーキテクチャー)で使うのもある。しかし、これは一般的な事前学習済みモデルには適用できない
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー