
S3バッチオペレーションで大量ファイルを一括変換する


AWS S3バッチオペレーションを使い、Lambdaで数万の画像を一気にリサイズする実装手順を紹介。料金やIAMロールの設定、Terraformによるデプロイ手順など、実運用に役立つポイントを具体的に解説してみた。
目次
はじめに
- 大量のオブジェクトを操作するときによく問題に出てくるS3バッチオペレーションを試してみた
- 今回は、バケットに大量の画像を入れて、それをリサイズするLambdaをバッチオペレーションで起動することを行う
S3バッチオペレーションとは
文字通り、S3にあるファイルに対してバッチ処理を行うもの。マニフェストというJSONやCSV(この例ではCSVで紹介)を通じてジョブを定義し、大量のファイルをバッチ処理できる。オペレーションは以下の通りで、Lambdaの実行以外にもかなりある。
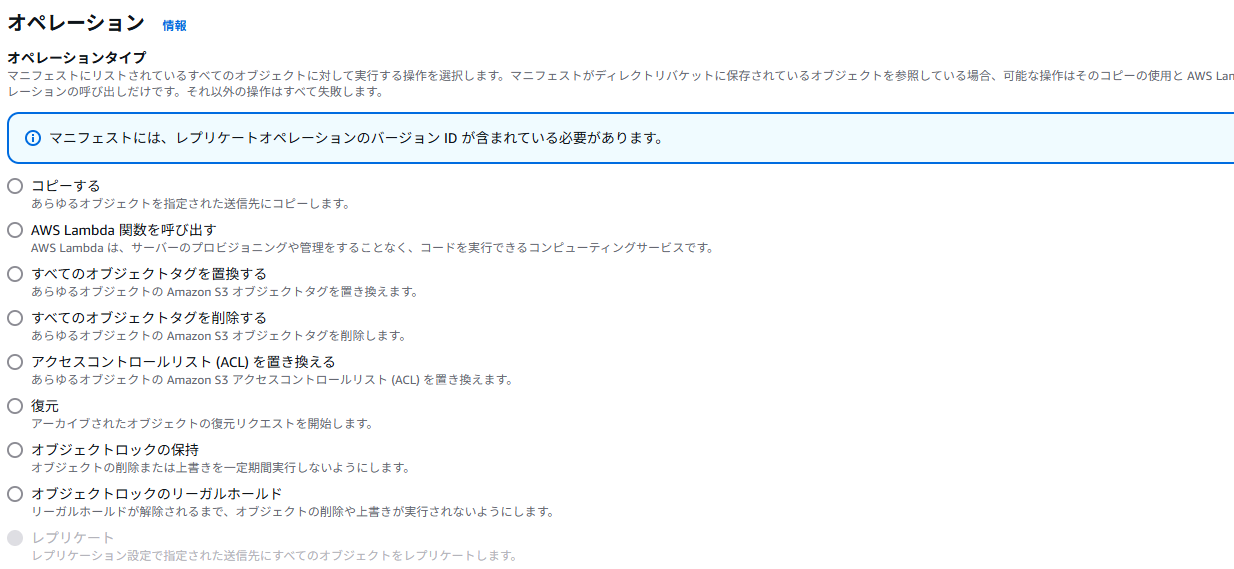
便利そうなのは、「タグの置き換え」「Lambdaの呼び出し」「復元(Glacierからの復元)」あたりだと思う。オブジェクトロックはコンプライアンス向け。
以前、Glacierからの取り出しをAWS CLIで行ったことあるのだが、ファイルが万単位であると復元APIを叩くだけで半日ぐらいかかってしまうので、そこからGlacier Flexible Retrievalの時間がかかるので体感的には相当長くなる。これは結構クリティカルに効くと思われる。
料金や使い所
バッチオペレーション単独の料金は以下の通り(公式より)
- バッチ操作 – ジョブ:ジョブあたり USD 0.25
- バッチ操作 – オブジェクト:処理された 100 万オブジェクトあたり USD 1.00
- バッチ操作 – マニフェスト (オプション):ソースバケットの 100 万オブジェクトあたり USD 0.015
ジョブの費用がちょっと高いので、データ数が万超えてこないとあんまりペイしないと思う。ただ、AI・ML系だと割とよくあるので、AIの人間だと割と使い所はあると思う。大量のCSVの整形やログデータの整形の簡易版としても使えるし、与えられたデータに対してOpenAIをAPIをどーっと流すみたいな使い方もOKだ。
ちょっとおもしろい使い方は、画像や動画のような大きめのデータをエンコードしてバックアップするもの(イベント通知でもいい説はあるが)。S3へのアップロードは料金かからないが、ダウンロードは転送量がかかるので、ダウンロード前にデータをスリム化できればバックアップのDLが必要になったときの転送量を圧縮できる。
やること
バッチオペレーションは基本ブラウザから行うので、事前準備としてTerraformで作る必要があるのは以下の通り
- 処理用のLambda関数のデプロイ
- Lambdaとバッチオペレーション用のIAMロールの作成
- 元ファイルのアップロード
- マニフェストファイルの作成
Lambda関数の定義
デプロイ用のTerraformは末尾に示す。バッチオペレーションで呼ばれたときのLambdaの入力は、イベント通知やSQSと同様に専用のフォーマットになっている。公式ドキュメントは以下を参照。
紛らわしいのが呼び出しスキーマのバージョンがバージョン2.0と1.0があるという点だ。この例では、バージョン2.0で説明する。
基本こういうコードを書く。短いコードなのでLambdaの全体コードを示す。このコードでは、S3からファイルをダウンロードし、短辺を256サイズにして、同一バケットのresized/以下のキーに置くことをしている。
import json
import boto3
from io import BytesIO
from PIL import Image
s3_client = boto3.client('s3')
def lambda_handler(event, context):
print("Received event: " + json.dumps(event))
# invocationSchemaVersionとinvocationIdはイベントに含まれる(例では2.0)
invocation_schema_version = event.get("invocationSchemaVersion", "1.0")
invocation_id = event.get("invocationId", "")
results = []
# S3 Batch Operationsのイベントは tasks 配列に各オブジェクトの情報が含まれる
for task in event.get('tasks', []):
task_id = task.get('taskId')
# s3BucketArnが存在しない場合はs3Bucketを利用する
bucket_info = task.get('s3BucketArn') or task.get('s3Bucket')
key = task.get('s3Key')
version = task.get('s3VersionId') # 存在しない場合もある
# バケット名がARN形式の場合、サンプルでは":"でsplitして最後を利用している
if bucket_info and bucket_info.startswith("arn:aws:s3:::"):
bucket = bucket_info.split(":")[-1]
else:
bucket = bucket_info
try:
# 画像オブジェクトの取得
get_obj_kwargs = {"Bucket": bucket, "Key": key}
if version:
get_obj_kwargs["VersionId"] = version
response = s3_client.get_object(**get_obj_kwargs)
image_data = response['Body'].read()
# Pillowで画像を読み込む
with Image.open(BytesIO(image_data)) as img:
original_width, original_height = img.size
# 短辺が256になるようにリサイズ(アスペクト比を保持)
if original_width <= original_height:
new_width = 256
new_height = int((original_height / original_width) * 256)
else:
new_height = 256
new_width = int((original_width / original_height) * 256)
resized_img = img.resize((new_width, new_height), Image.LANCZOS)
# 出力用バッファに保存
out_buffer = BytesIO()
# 画像フォーマットは元画像の形式(なければJPEG)
img_format = img.format if img.format else 'JPEG'
resized_img.save(out_buffer, format=img_format)
out_buffer.seek(0)
# 出力先パス(同じバケット内の "resized/" プレフィックス付き)
output_key = f"resized/{key}"
# リサイズ済み画像をアップロード
s3_client.put_object(
Bucket=bucket,
Key=output_key,
Body=out_buffer,
ContentType=response.get('ContentType', 'image/jpeg')
)
results.append({
"taskId": task_id,
"resultCode": "Succeeded",
"resultString": f"Resized image saved as {output_key}"
})
except Exception as e:
print(f"Error processing task {task_id}: {str(e)}")
results.append({
"taskId": task_id,
"resultCode": "PermanentFailure",
"resultString": str(e)
})
return {
"invocationSchemaVersion": invocation_schema_version,
"invocationId": invocation_id,
"treatMissingKeysAs": "PermanentFailure",
"results": results
}
バッチオペレーションからLambdaに渡される入力は以下のようになっている。これはバージョン2.0における、Lambdaのeventをダンプしたもの。
{
"invocationId": "AAA...w=",
"job": {
"id": "daf62001-a78f-49e7-870a-de3bba8b1997",
"userArguments": null
},
"tasks": [
{
"taskId": "AAAA...w=",
"s3Bucket": "my-batch-bucket-456231685024",
"s3Key": "ILSVRC2012_val_00000008.JPEG",
"s3VersionId": null
}
],
"invocationSchemaVersion": "2.0"
}
tasks以下にS3バケット名とキーが与えられるので、Lambda内でダウンロードしてよしなに処理してねというもの。成功・失敗はresultCodeがSucceededかPermanentFailureで決める。
Lambdaとバッチオペレーション用のIAMロールの作成
IAMロールと必要なポリシーは以下の通り
- Lambda用のロール
- 普通にLambdaを作るときと同じ。
lambda.amazonaws.comとの信頼関係を入れれば良い。 - S3の読み書き権限が実質必要
- 普通にLambdaを作るときと同じ。
- S3バッチオペレーション用のロール
batchoperations.s3.amazonaws.comとの信頼関係- S3への読み書き権限
- Lambdaの実行権限
バッチオペレーション用のロールは行う処理によって変わるので柔軟にいれること。公式ドキュメントではいくつかポリシー例がある。この例では、以下のポリシーやロール設定でOKだった。
# S3 Batch Operations 用の実行ロール作成
resource "aws_iam_role" "s3_batch_operations_role" {
name = "s3_batch_operations_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Principal = {
Service = "batchoperations.s3.amazonaws.com"
},
Action = "sts:AssumeRole"
}
]
})
}
# S3 Batch Operations 用のロールに、Lambda 関数呼び出し権限およびマニフェスト(S3オブジェクト)読み取り権限を付与
resource "aws_iam_role_policy" "s3_batch_operations_policy" {
name = "s3_batch_operations_policy"
role = aws_iam_role.s3_batch_operations_role.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Action = [
"lambda:InvokeFunction"
],
Resource = aws_lambda_function.image_processing_lambda.arn
},
{
Effect = "Allow",
Action = [
"s3:GetObject",
"s3:PutObject"
],
Resource = "${aws_s3_bucket.batch_bucket.arn}/*"
}
]
})
}
元ファイルのアップロード
aws s3 syncでローカルからアップロードする。ここではImageNetのValidationデータの5万枚を採用した。
マニフェストファイルの作成
「バケット名, キー」の形で以下のようなCSVを作れば良い。
my-batch-bucket-456231685024,ILSVRC2012_val_00000001.JPEG
my-batch-bucket-456231685024,ILSVRC2012_val_00000002.JPEG
my-batch-bucket-456231685024,ILSVRC2012_val_00000003.JPEG
マニフェストの生成は以下のコードでできる(ローカルで動かす)。
import os
import csv
# ローカルのディレクトリパス(バックスラッシュをエスケープするか、raw文字列を使います)
local_dir = r"対象のディレクトリのパス。ここではImageNetの検証データ"
# アップロード先のS3バケット名(例: my-s3-bucket)
bucket_name = "your_bucket_name"
# マニフェストファイルの出力先(例: manifest.csv)
manifest_file = "manifest.csv"
# マニフェストファイル作成(CSV形式)
# ※S3 Batch Operations のCSVマニフェストは、各行に
# bucket_name, object_key [, versionId] の形式になります
with open(manifest_file, "w", newline="") as csvfile:
writer = csv.writer(csvfile)
# ヘッダー行は不要なので、データ行のみ出力します
for root, dirs, files in os.walk(local_dir):
for file in files:
# JPEGファイルのみ対象(大文字小文字の区別をしない)
if file.lower().endswith((".jpg", ".jpeg")):
# アップロード先はS3バケットのルートに配置する想定なので、ファイル名のみをキーとする
object_key = file
writer.writerow([bucket_name, object_key])
print(f"Manifest file '{manifest_file}' has been created.")
バッチオペレーションを開始する
ブラウザからの操作になるのでスクショで説明。
バッチオペレーションの作成
S3バケットの左側の「バッチオペレーション」から実行する
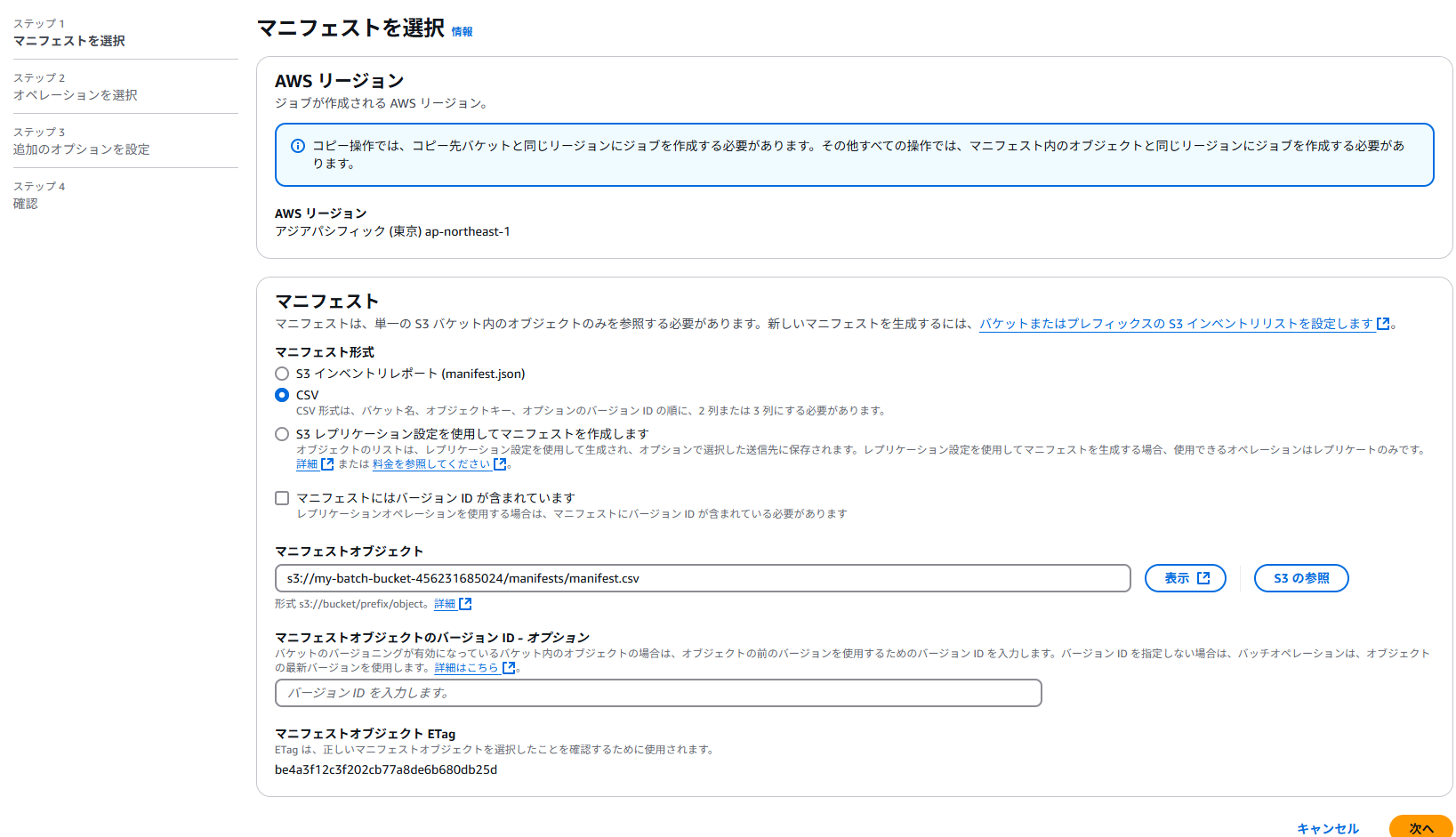
マニフェストファイルを選択する。ここではCSV形式。マニフェストファイルもS3にアップロードしておく必要があり、ここでは/manifests以下にアップロードした
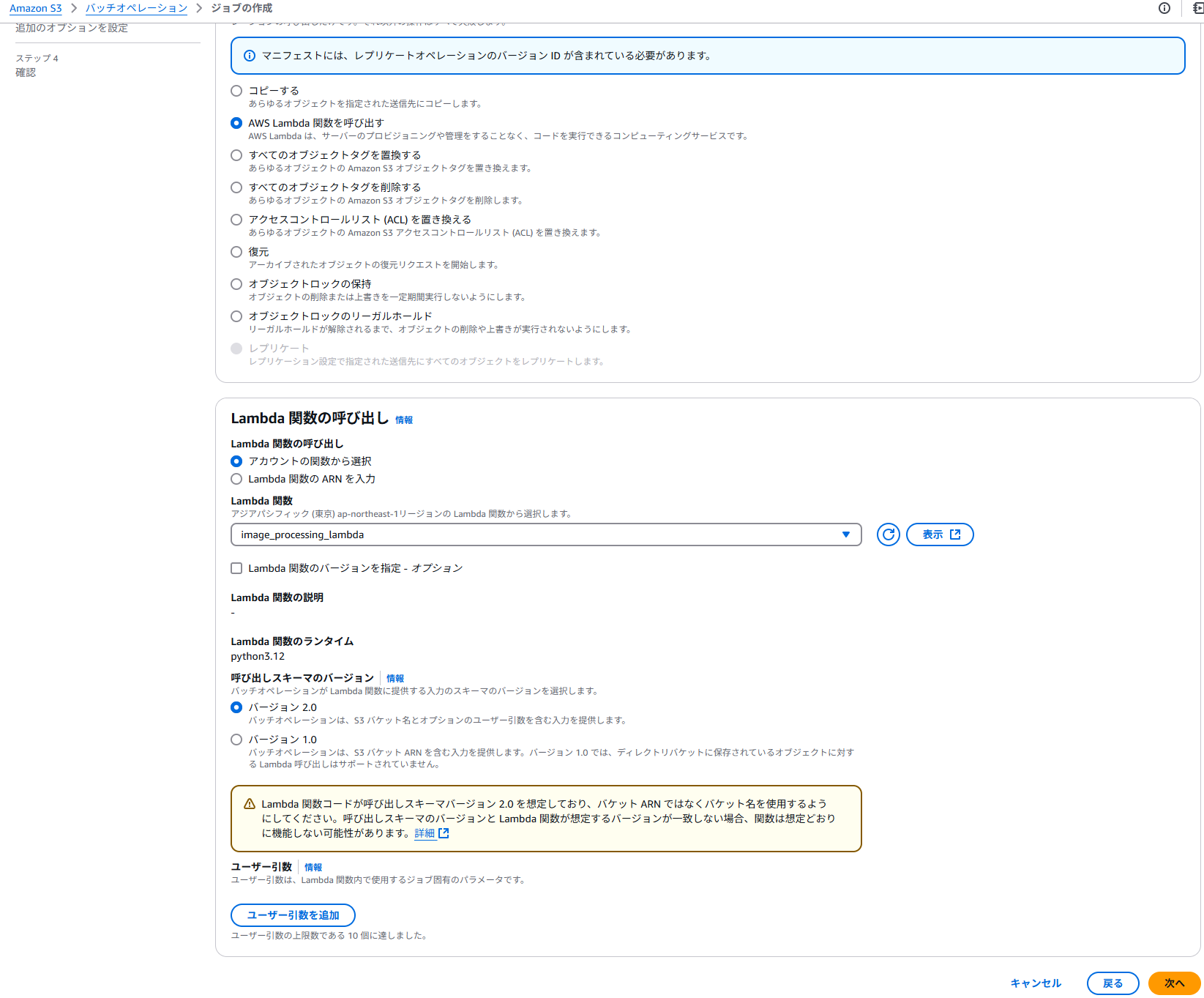
「AWS Lambda関数を呼び出す」を選択し、TerraformでデプロイしたLambdaを線t買う。呼び出しスキーマのバージョンは「バージョン2.0」で。ユーザー引数も設定できるようだ。
完了レポートを適当な場所に生成する/batch_reportsにおいてみる。Terraformで作成したバッチオペレーション用のロールを選択する。
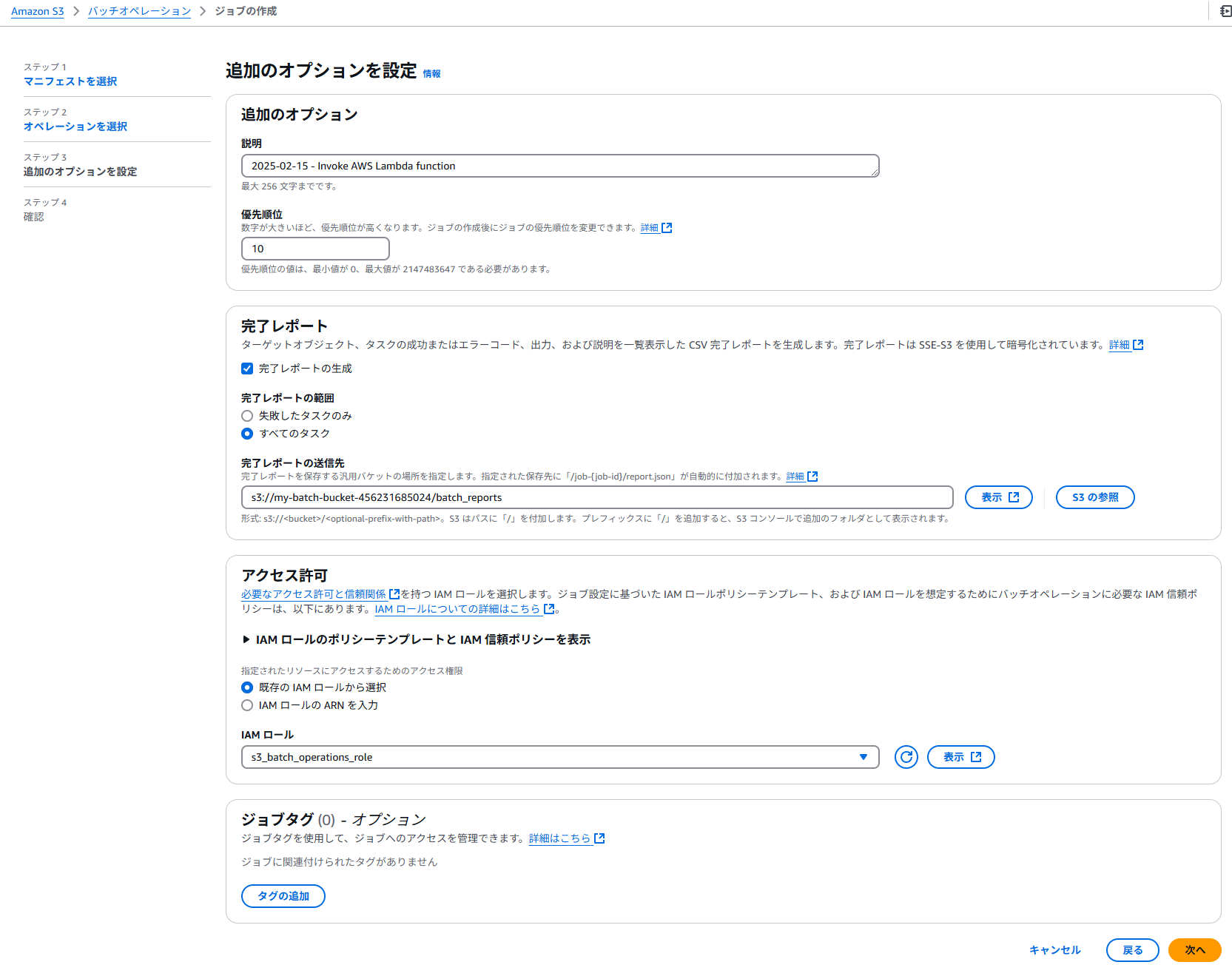
確認画面でジョブの作成。デバッグ用には最初は10ファイルぐらいのマニフェストでやってみるのが良いだろう。
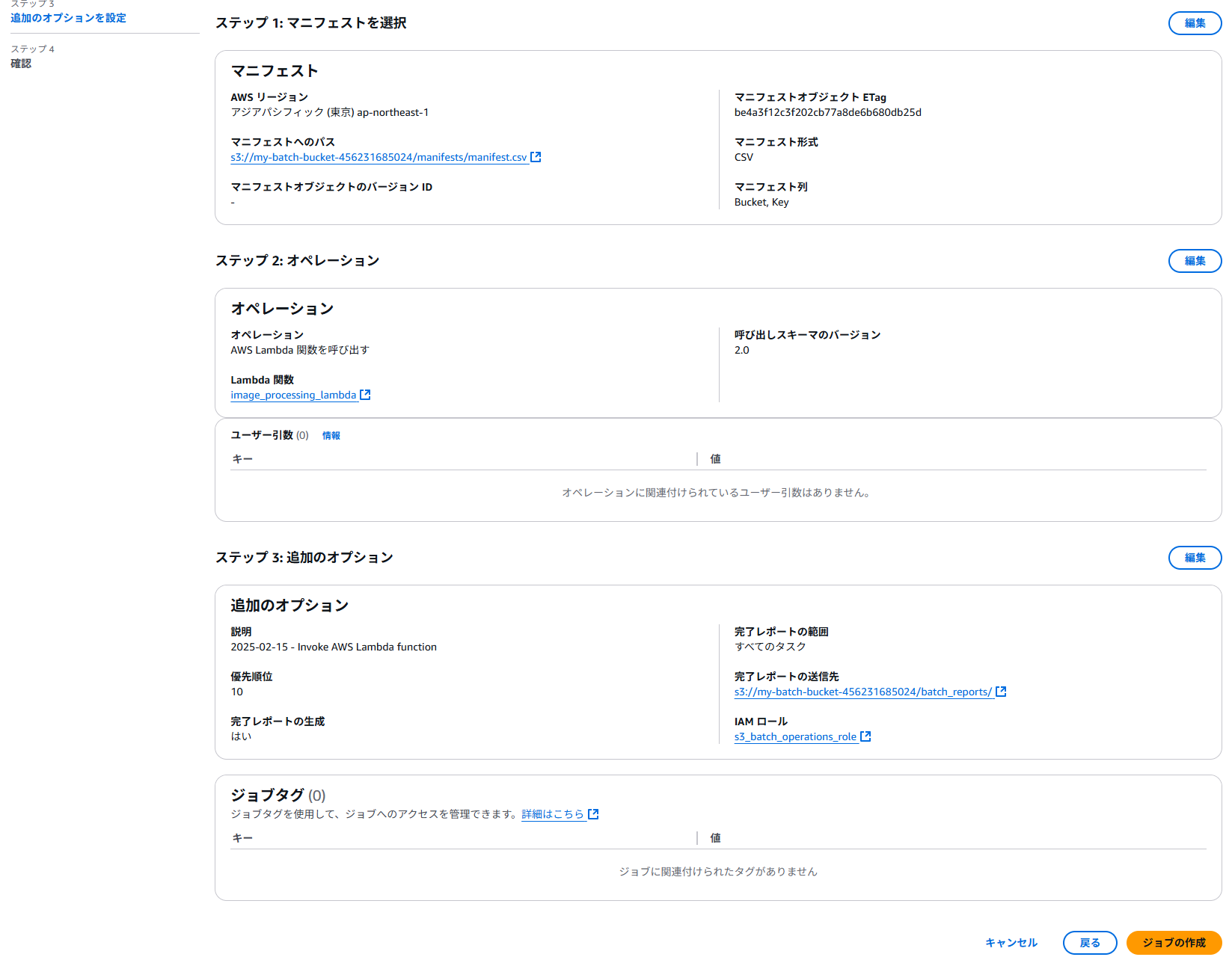
バッチオペレーションの開始
ちょっとここがややこしいのだが、オペレーションを作成してもすぐには実行されない。図ジョブの画面に行って、「ジョブを実行」をクリックする。おそらくこれもAPIでできるとは思う。
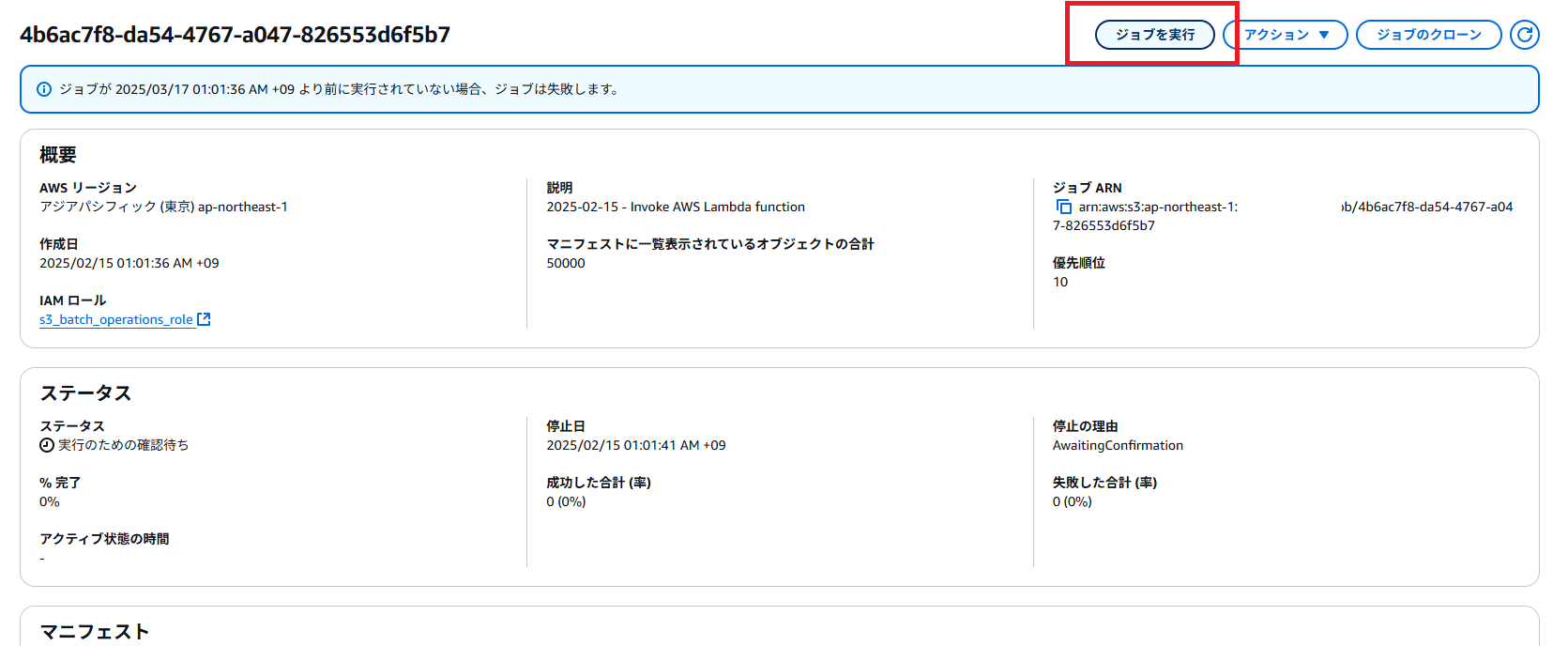
「ジョブを実行」をクリック
Lambdaのログストリームを見ると、大量のロググループが作成されている。相当分散処理されているはずだ。
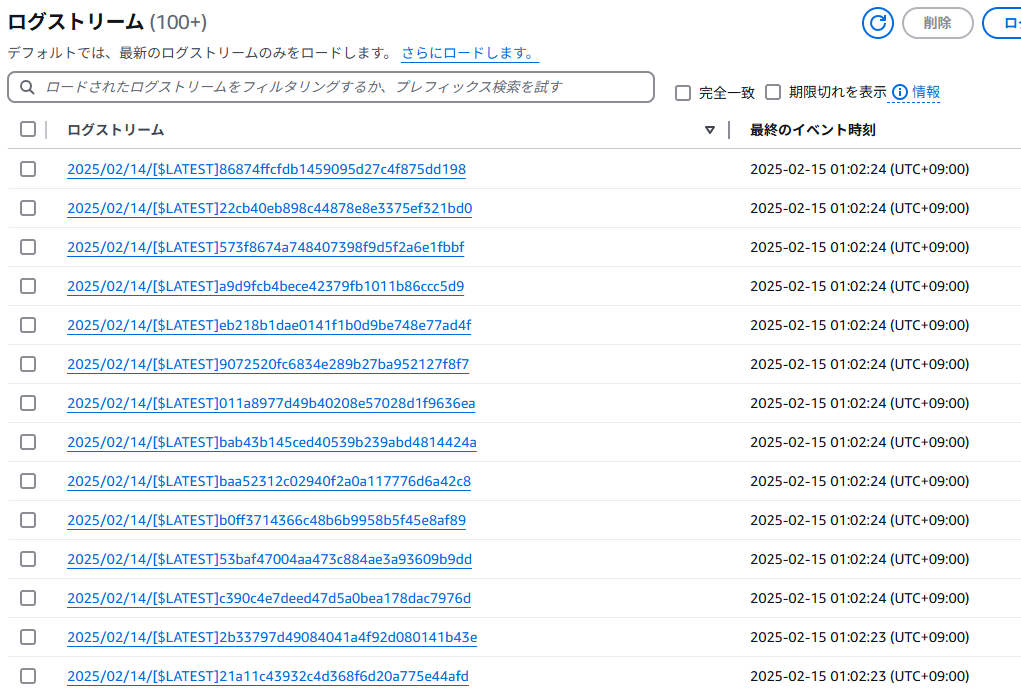
ジョブ完了後
5万ファイルのリサイズがたった23秒で完了してしまった。512MBのメモリのLambdaで、1個のファイルにつき0.1~0.3秒程度かかっている。Lambdaはデフォルトで1000並列まで行けるので、なかなかの分散処理能力である。Sparkよりは全然手軽だし、これで足りることも結構あるはずだ。

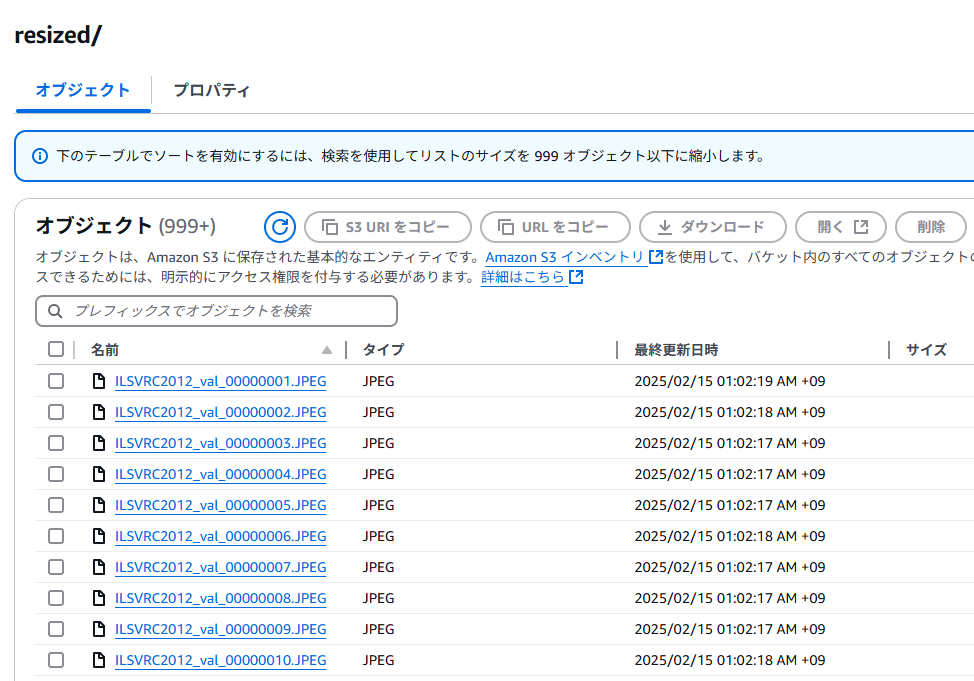
resized/以下に大量のリサイズファイルが作成されている。
スロットリングしたいときは
これはLambdaの内部でPillowを動かしているだけなので、フルスロットルで分散させて構わないが、OpenAIへのAPIコールのようにリミットにかかってしまうケースは、おそらくLambdaの予約済み同時実行数で分散数をコントロールできると思われる。試してはいないが、SQSのときはこれでコントロールできたので、おそらく機能するかと。
Terraformのコード
Terraformの全体コードは以下の通り。Lambdaとロール2個とS3バケットなのでそこまで複雑ではない。Pillowのレイヤーは別途定義必要(lambda_layers/pillow.zip)。
########################################
# Lambda 関数と関連リソース定義
########################################
# Lambda 関数用のソースコードのZIP化
data "archive_file" "lambda_zip" {
type = "zip"
source_file = "${path.module}/lambda_function.py"
output_path = ".cache/lambda_function.zip"
}
# Pillow の Lambda Layer 定義
resource "aws_lambda_layer_version" "pillow_layer" {
layer_name = "pillow_layer"
description = "Pillow library layer"
compatible_runtimes = ["python3.12"]
filename = "${path.module}/lambda_layers/pillow.zip"
source_code_hash = filebase64sha256("${path.module}/lambda_layers/pillow.zip")
}
# Lambda 関数定義
resource "aws_lambda_function" "image_processing_lambda" {
function_name = "image_processing_lambda"
runtime = "python3.12"
handler = "lambda_function.lambda_handler"
role = aws_iam_role.lambda_exec.arn
filename = data.archive_file.lambda_zip.output_path
source_code_hash = filebase64sha256(data.archive_file.lambda_zip.output_path)
timeout = 10
memory_size = 512
# 定義したレイヤーを紐付け
layers = [
aws_lambda_layer_version.pillow_layer.arn
]
}
# Lambda 実行ロール (最小例)
resource "aws_iam_role" "lambda_exec" {
name = "lambda_exec_role"
assume_role_policy = data.aws_iam_policy_document.lambda_assume_role_policy.json
}
# Lambda の IAM ロールに S3 バケットへの読み書き権限を付与するインラインポリシー
resource "aws_iam_role_policy" "lambda_bucket_access" {
name = "lambda_bucket_access"
role = aws_iam_role.lambda_exec.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Action = [
"s3:ListBucket"
],
Resource = aws_s3_bucket.batch_bucket.arn
},
{
Effect = "Allow",
Action = [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
Resource = "${aws_s3_bucket.batch_bucket.arn}/*"
}
]
})
}
data "aws_iam_policy_document" "lambda_assume_role_policy" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
}
}
# Lambda 用の基本実行ポリシーをアタッチ
resource "aws_iam_role_policy_attachment" "lambda_exec_attach" {
role = aws_iam_role.lambda_exec.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
# CloudWatch Logs の Log Group 定義(ログ保持日数を指定)
resource "aws_cloudwatch_log_group" "lambda_log_group" {
name = "/aws/lambda/${aws_lambda_function.image_processing_lambda.function_name}"
retention_in_days = 7 # 必要に応じて保持日数を変更してください
}
########################################
# S3 Batch Operations 用のリソース定義
########################################
# S3 Batch Operations 用にマニフェスト等を保管するバケットの定義
resource "aws_s3_bucket" "batch_bucket" {
bucket = var.s3_bucket_name # ※グローバルで一意の名前に変更してください
force_destroy = true
}
# S3 Batch Operations 用の実行ロール作成
resource "aws_iam_role" "s3_batch_operations_role" {
name = "s3_batch_operations_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Principal = {
Service = "batchoperations.s3.amazonaws.com"
},
Action = "sts:AssumeRole"
}
]
})
}
# S3 Batch Operations 用のロールに、Lambda 関数呼び出し権限およびマニフェスト(S3オブジェクト)読み取り権限を付与
resource "aws_iam_role_policy" "s3_batch_operations_policy" {
name = "s3_batch_operations_policy"
role = aws_iam_role.s3_batch_operations_role.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Action = [
"lambda:InvokeFunction"
],
Resource = aws_lambda_function.image_processing_lambda.arn
},
{
Effect = "Allow",
Action = [
"s3:GetObject",
"s3:PutObject"
],
Resource = "${aws_s3_bucket.batch_bucket.arn}/*"
}
]
})
}
所感
- もともとはGlacierからの復元やレプリケーション、タグ付けに使うことを想定された機能だけど、割とMLとも相性良さそう。
- ネックはジョブあたり0.25ドルという連発するとそこそこかかる費用なので、データを万や数十万単位で溜め込んで一気に叩くみたいなケースで有効だと思う。
- 本格的にやるならAWS BatchだけどDocker定義するの面倒ってときは結構いい。少なくともデフォルトで1000の分散処理は強力
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー