
PyTorch lightningで訓練時間を指定して自動的に訓練終了+再開(Google Colab向け)


PyTorch lightningでは、Trainerにオプションを追加するだけで、訓練時間を指定できます。これとCheckpointを組み合わせるとGoogle Colabでかなり便利だということがわかったので検証していきたいと思います。
目次
PyTorch lightningでは訓練時間を指定できる
PyTorch lightningのドキュメント読んでたらなかなかいいオプション見つけたので実験。
- max_time
> Set the maximum amount of time for training. Training will get interrupted mid-epoch. For customizable options use the Timer callback.
https://pytorch-lightning.readthedocs.io/en/stable/common/trainer.html#max-time
# Default (disabled)
trainer = Trainer(max_time=None)
# Stop after 12 hours of training or when reaching 10 epochs (string)
trainer = Trainer(max_time="00:12:00:00", max_epochs=10)
# Stop after 1 day and 5 hours (dict)
trainer = Trainer(max_time={"days": 1, "hours": 5})
真ん中のやり方が便利で、「max_epochsに到達するか、max_timeに到達するまで訓練する」という方法。Trainerのオプションに加えればいいだけなのでとても楽。max_timeのフォーマットは「days:hours:minites:seconds」
一定時間経過するとランタイムが落とされるColabとはとても相性が良さそう。
PyTorch lightningのCheckpointと併用
PyTorch lightningには訓練中の係数を保存するためのコールバックが用意されており、これがかなり高機能です。具体的には、
- 保存はもちろん、再開時の読み込みもやってくれる
- 精度が高いエポック3つのみ保存(残りは削除)も勝手にやってくれる
- Colabの場合、保存先をGoogle Driveにすれば再開や保存の処理を別に書く必要がない
具体的には次のようにします、
checkpoint_dir = "drive/MyDrive/cifar/checkpoints"
checkpoint_callback = pl.callbacks.ModelCheckpoint(
monitor="val_acc_epoch",
dirpath=checkpoint_dir,
filename="cifar-{epoch:02d}-{val_acc_epoch:.4f}",
save_top_k=3,
mode="max"
)
# 1st time:None, others:Google drive path
resume_ckpt = find_latest_checkpoints(checkpoint_dir)
trainer = pl.Trainer(
gpus=[0], max_epochs=100,
callbacks=[checkpoint_callback],
max_time="00:00:15:00") # day:hour:minites:seconds
trainer.fit(model, cifar, ckpt_path=resume_ckpt)
とします。checkpoint_dirにはマウントしたGoogle Driveのパスを指定しておきます(ディレクトリの作成は勝手にやってくれます)。
実験
Google Colabで訓練時間を15分に制限してCIFAR-10を訓練してみます。
訓練1回目
最初にGoogle Driveをマウントしておきます。
PyTorch lightningはColabにはインストールされていないので、インストールしておきます。
!pip install pytorch-lightning
以下のコードを実行します。
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
import pytorch_lightning as pl
import torchvision
import torchmetrics
import glob
class TenLayerNetwork(pl.LightningModule):
def __init__(self):
super().__init__()
self.layers = torch.nn.ModuleList()
for i in range(3):
for j in range(3):
out_chs = 64 * 2 ** i
if i == 0 and j == 0:
in_chs = 3
elif j == 0:
in_chs = 64 * 2 ** (i-1)
else:
in_chs = out_chs
self.layers.append(
torch.nn.Conv2d(in_chs, out_chs, 3, padding=1))
self.layers.append(
torch.nn.BatchNorm2d(out_chs))
self.layers.append(
torch.nn.ReLU())
self.layers.append(torch.nn.AdaptiveAvgPool2d((1, 1)))
self.fc = torch.nn.Linear(256, 10)
self.train_acc = torchmetrics.Accuracy()
self.val_acc = torchmetrics.Accuracy()
def forward(self, x):
for layer in self.layers:
x = layer(x)
return self.fc(x.view(-1, 256))
def configure_optimizers(self):
return torch.optim.SGD(self.parameters(), lr=0.1, momentum=0.9)
def training_step(self, train_batch, batch_idx):
x, y_true = train_batch
y_pred = self.forward(x)
loss = F.cross_entropy(y_pred, y_true)
y_pred_label = torch.argmax(y_pred, dim=-1)
acc = self.train_acc(y_pred_label, y_true)
self.log("train_loss", loss, prog_bar=False, logger=True)
self.log("train_acc", acc, prog_bar=True, logger=True)
return loss
def training_epoch_end(self, outputs):
self.train_acc.reset()
def validation_step(self, val_batch, batch_idx):
x, y_true = val_batch
y_pred = self.forward(x)
loss = F.cross_entropy(y_pred, y_true)
y_pred_label = torch.argmax(y_pred, dim=-1)
acc = self.val_acc(y_pred_label, y_true)
self.log("val_loss", loss, prog_bar=False, logger=True)
def validation_epoch_end(self, outputs):
self.log('val_acc_epoch', self.val_acc.compute(), prog_bar=True, logger=True)
self.val_acc.reset()
class CifarDataModule(pl.LightningDataModule):
def __init__(self):
super().__init__()
def prepare_data(self):
self.train_dataset = torchvision.datasets.CIFAR10(
"./data",
train=True,
download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.RandomCrop((32, 32), padding=2),
torchvision.transforms.ToTensor(),
]))
self.val_dataset = torchvision.datasets.CIFAR10(
"./data",
train=False,
download=True,
transform=torchvision.transforms.ToTensor())
def train_dataloader(self):
return DataLoader(self.train_dataset, batch_size=512, num_workers=4, shuffle=True)
def val_dataloader(self):
return DataLoader(self.val_dataset, batch_size=512, num_workers=4, shuffle=False)
def find_latest_checkpoints(checkpoint_dir):
ckpts = sorted(glob.glob(checkpoint_dir+"/*.ckpt"))
if len(ckpts) == 0:
return None
else:
return ckpts[-1]
def main():
model = TenLayerNetwork()
cifar = CifarDataModule()
checkpoint_dir = "drive/MyDrive/cifar/checkpoints"
checkpoint_callback = pl.callbacks.ModelCheckpoint(
monitor="val_acc_epoch",
dirpath=checkpoint_dir,
filename="cifar-{epoch:02d}-{val_acc_epoch:.4f}",
save_top_k=3,
mode="max"
)
tb_logger = pl.loggers.TensorBoardLogger(checkpoint_dir+"/logs")
resume_ckpt = find_latest_checkpoints(checkpoint_dir)
trainer = pl.Trainer(
gpus=[0], max_epochs=100,
logger=tb_logger,
callbacks=[checkpoint_callback],
max_time="00:00:15:00") # day:hour:minites:seconds
trainer.fit(model, cifar, ckpt_path=resume_ckpt)
if __name__ == "__main__":
main()
訓練結果。15分すると止まっているのがわかります。100エポックまでは行きませんでしたね。

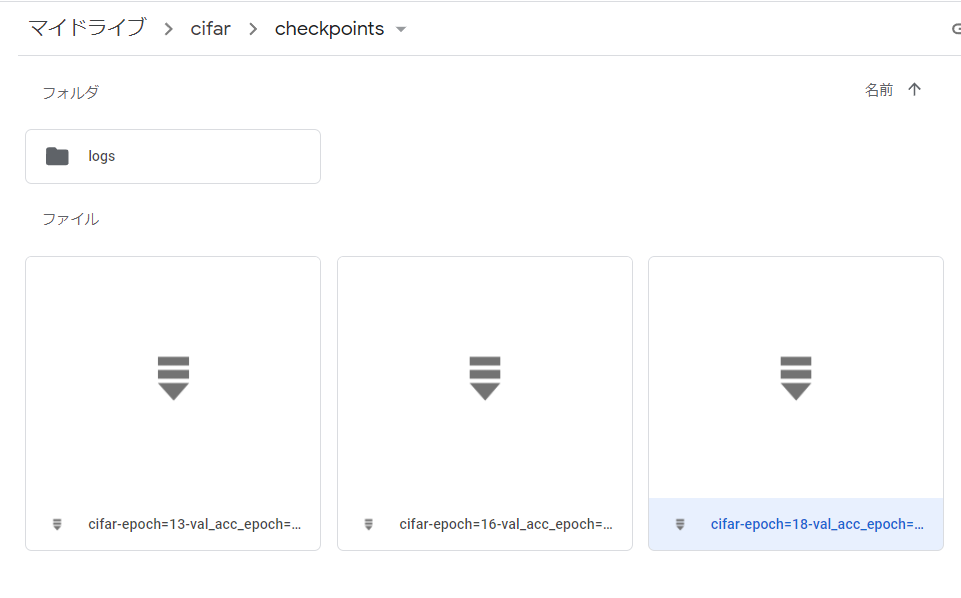
Google Driveを見てみましょう。チェックポイントがちゃんと上位3件のみ保存されています。
訓練2回目
ここでColabのインスタンスが落ちたと仮定します。もう一度PyTorch lightningをインストールし、コードを実行します。チェックポイントの読み込みはPyTorch lightningにおまかせで、手動では定義しません。
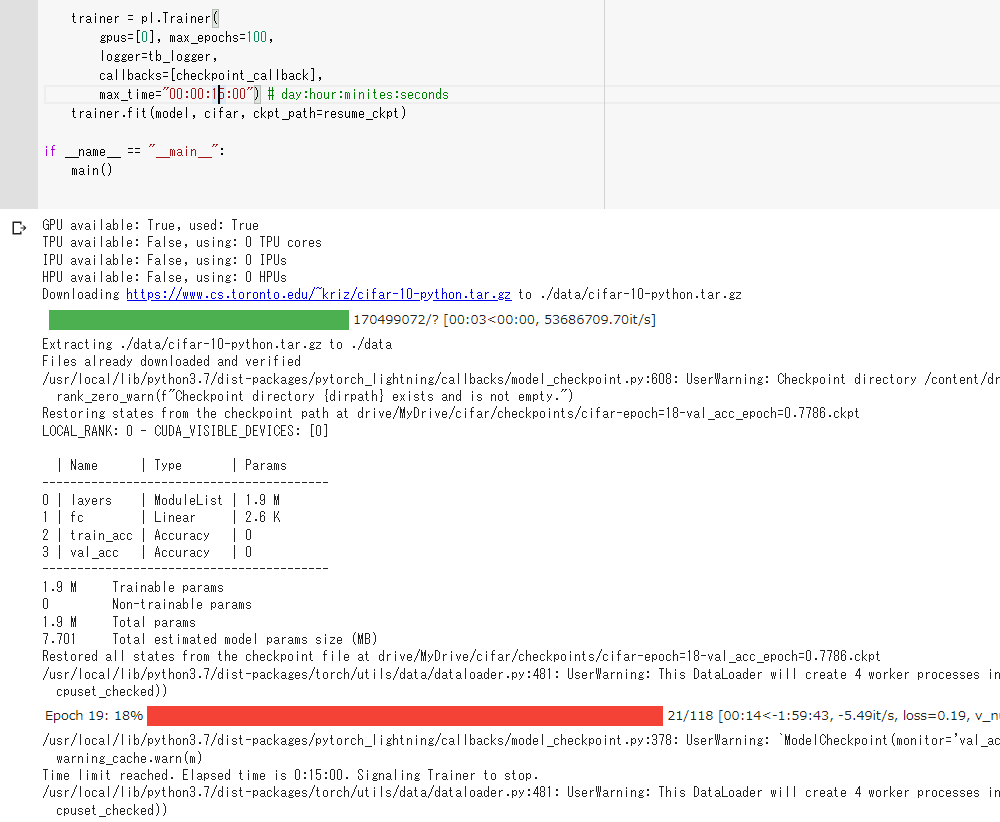
18エポックのチェックポイントがうまく読み込まれていますが、あれ、訓練時間のカウントも引き継がれていますね。
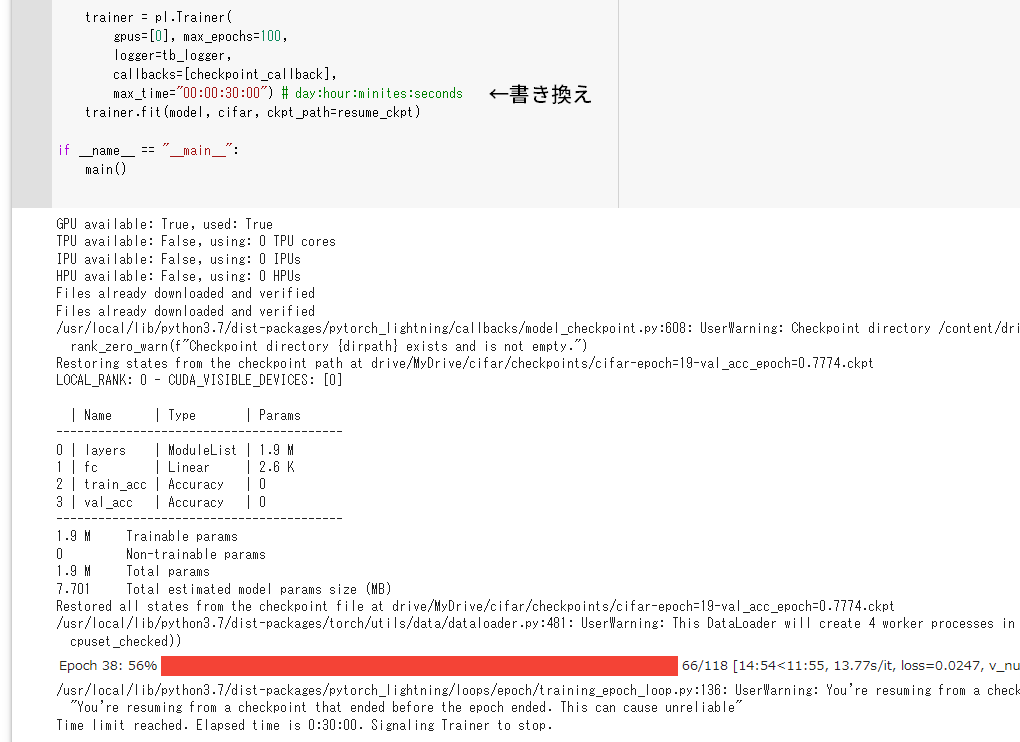
max_timeを30分にして訓練したところ、訓練が進みました。
チェックポイントもいい感じになっています。古いチェックポイントを手動で削除したり、1エポックあたりの訓練時間をいちいち計算しなくていいのが楽ですね。
まとめ
PyTorch lightningのmax_timeとCheckpointをGoogle Drive指定の組み合わせはかなり強力で、Colabで使いやすい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー