
論文まとめ:SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation


- タイトル:SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
- 著者:Meng-Hao Guo, Cheng-Ze Lu, Qibin Hou, Zhengning Liu, Ming-Ming Cheng, Shi-Min Hu
- 所属:清華大学、南開大学、Fitten Tech
- コード:https://github.com/Visual-Attention-Network/SegNeXt
- カンファ:NeurIPS 2022
目次
ざっくりいうと
軽量性と精度を両立したのが売りのセグメンテーションモデル。CNNベースにもかかわらず、Transformerベースのモデルに対して勝利。
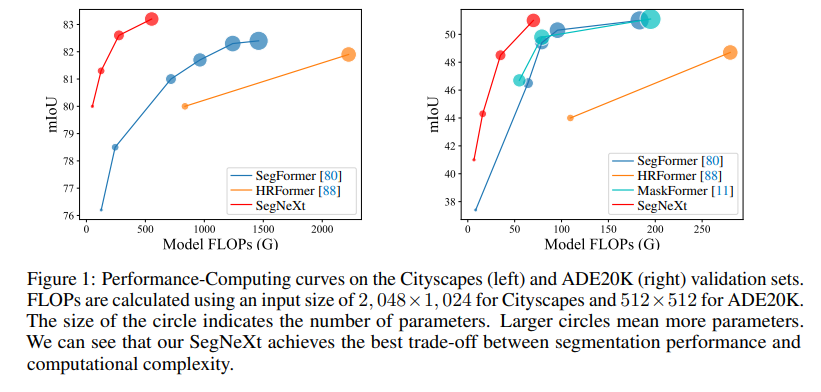
先行研究のDeepLabV3+、SegFormerなどのモデルに見られた工夫を取り入れつつ、計算量オーダーを削減している。
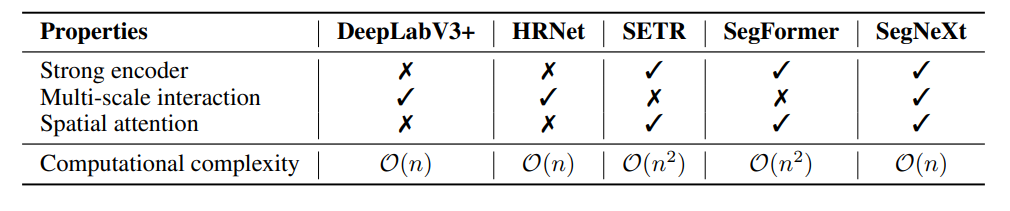
実装を見ると
公式実装より、コードベースでモデルを見てみる。
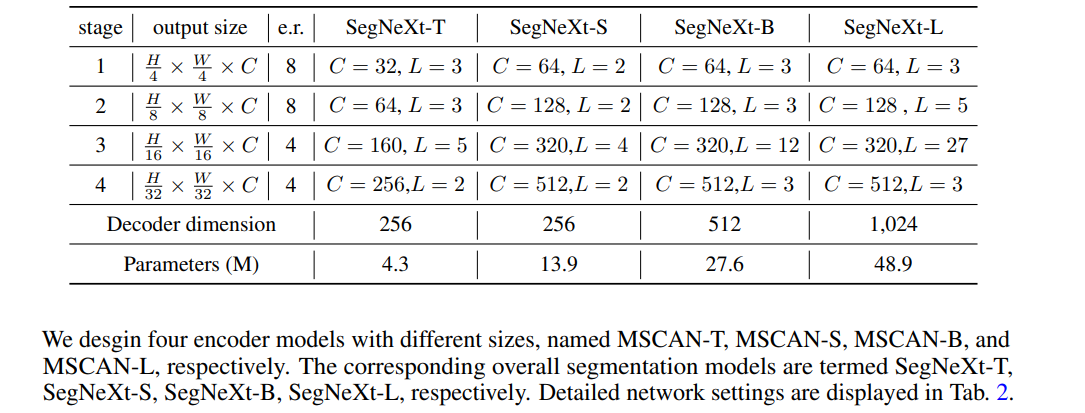
例えば、SegNext-Tinyの場合は、バックボーンに本研究で導入されたMSCANを、Decode Headに先行研究のHamburger Head(LightHamHead)を使っている。
model = dict(
type='EncoderDecoder',
backbone=dict(
init_cfg=dict(type='Pretrained', checkpoint='pretrained/mscan_t.pth')),
decode_head=dict(
type='LightHamHead',
in_channels=[64, 160, 256],
in_index=[1, 2, 3],
channels=256,
ham_channels=256,
ham_kwargs=dict(MD_R=16),
dropout_ratio=0.1,
num_classes=150,
norm_cfg=ham_norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))
MSCANとは
ResNeXtインスパイアなブロック構造。Depthwise Convを多用し、AttentionもCNNベースのもの。
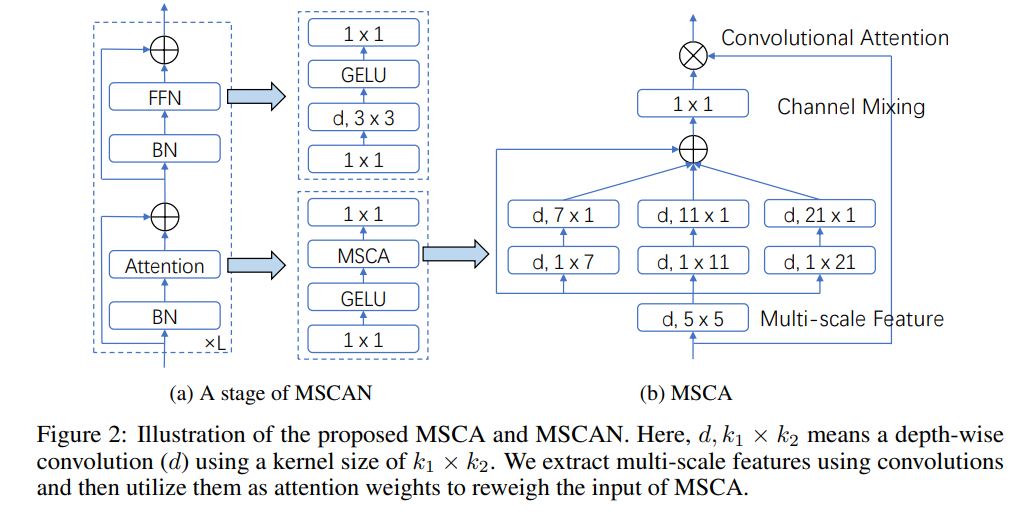
各ステージ構造はかなりResNeXt。チャンネル数とレイヤー数をスケールすることでパラメーター数をコントロールするResNet系でありがちな構造。
HamNetのHead
セグメンテーションのHeadの部分は、先行研究のHamNetを使用。HamNetの論文より
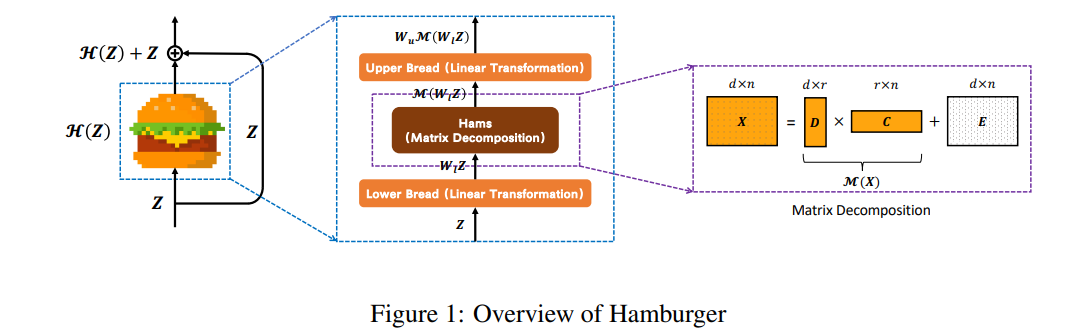
Attentionの代わりに、行列分解(Matrix Decomposition)を使ったHead。行列分解の部分が具で、線形変換の部分がパンだからハンバーガーとのこと。
高解像度で25FPS
Papers with codeを見ればわかるが、計算量度外視してSoTAを狙いにいくモデルではない。あくまでGFLOPsと精度の効率が良い。Transformerベースに対して良好な結果を残している。
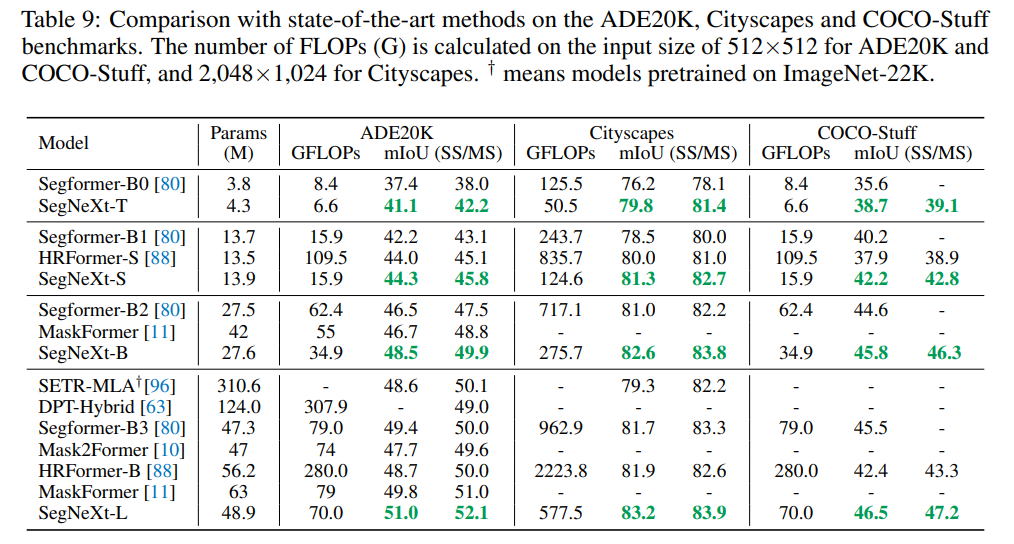
3090GPU1枚+つよつよCPUでTinyが25FPS。入力解像度が768×1536という、やや高めの設定を割り引いて見ると速度出ている。表の他のモデルは全てリアルタイム出るモデル。
どれが効いている?
1×1Convが一番効いている(Channel Mixing)。次に11×11や21×21の大きめのブランチ。

ライセンスについて
コードをApache-2.0ライセンスで公開しているが、商用利用に関しては以下の注意書きがある。
This repo is under the Apache-2.0 license. For commercial use, please contact the authors.
おそらくコードに含まれる比較対象のSegFormerがNVIDIAライセンスだからと思われる(MMSegでもここだけ例外扱いしている)。 MMSegmentaionに準じたコード設計なので、 SegNeXtの部分だけMMSegmentaionに統合されればどうなのだろう?(元となったHamburgerの公式がGPL-3.0なので怪しい雰囲気はなくはないが)
感想
Convだけでわかりやすい。「大きめの畳み込みカーネルを使えば、CNNでもTransformerに引けを取らない精度が出るよ」というどこかでみたような主張だが、これでNeurIPS 2022通っているのが驚き。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー