
論文まとめ:Generalized Decoding for Pixel, Image, and Language
Posted On 2023-02-09


- タイトル:Generalized Decoding for Pixel, Image, and Language
- 著者:Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee, Jianfeng Gao(ウィスコンシン大学、UCLA、Microsoft)
- コード:https://github.com/microsoft/X-Decoder
- HuggingFace:https://huggingface.co/spaces/xdecoder/Demo
- 論文:https://arxiv.org/abs/2212.11270
目次
ざっくりいうと
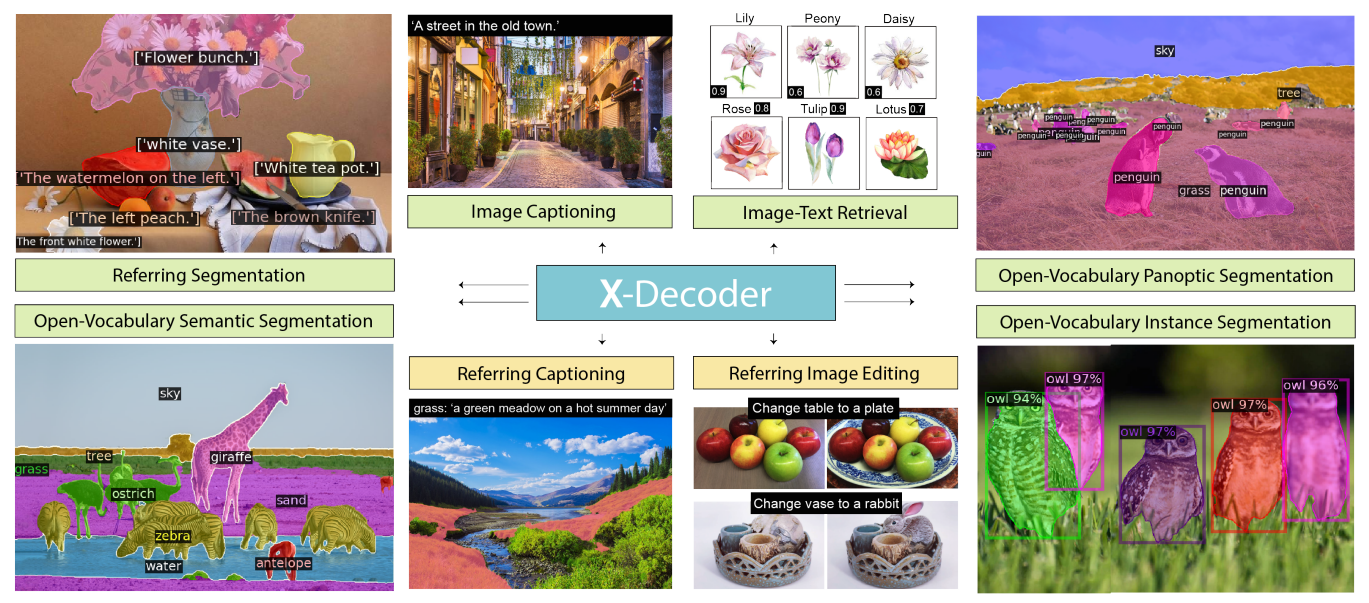
- オープンワールドのセグメンテーションタスクを統合した汎用モデル
- デコーダーの構造を工夫し、潜在・テキストクエリの2種類を入力、意味的・ピクセルレベルの2種類を出力とし、組み合わせでタスクを類型化
- 強いゼロショット転移性があり、下流タスクでSoTA
- 画像編集や、主観変更したキャプション生成も可能
導入
- オープンワールドのセグメンテーション問題って需要あるけどなかなか進んでないよね
- アノテーションコスト高い
- 全ピクセルをグループ化して、オープンボキャブラリーで認識することはあまり研究されていない
- 分類・検索・検出・VQA・セグメンテーションのような粒度の異なるタスクから、相互利益を得て学習することは自明ではない
- CLIPのような基盤モデルから、セグメンテーションタスクに取り組むのはある(MaskCLIP、DenseCLIP)
- しかし、特定のセグメンテーションタスクのみで、異なる粒度へのタスクへの一般化は行っていない
- スペシャリストモデルからジェネラリストモデルにしたい
- X-Decoder(本研究)のやりたいこと:画素レベルの画像分割、画像レベルの検索、視覚言語タスクなど、すべてのタスクの汎用的な複合手順の定式化
- EncoderはMask2Formerの枠組み
- Mask2Formerは、セグメンテーションタスクの統合はしたが、設定がオープンボキャブラリーではない
- Decoderの設計が新規性
- 2種類のクエリを使う
- 普遍的なセグメンテーションのための、セグメンテーションマスクのデコードを目的とした一般的な非意味的クエリ(Mask2Formerと同じ)
- 言語関連の多様なビジョンタスクのための、デコーダで言語認識させるためのテキストクエリ(新規性)
- ピクセルレベルのマスク、トークンレベルのセマンティックの2種類の出力を予測
- これらの組み合わせで、全てのタスクをシームレスにサポート
- EncoderはMask2Formerの枠組み
- 7つのデータセットの10個の設定でSoTAで、ゼロショット転移性つよつよ
手法
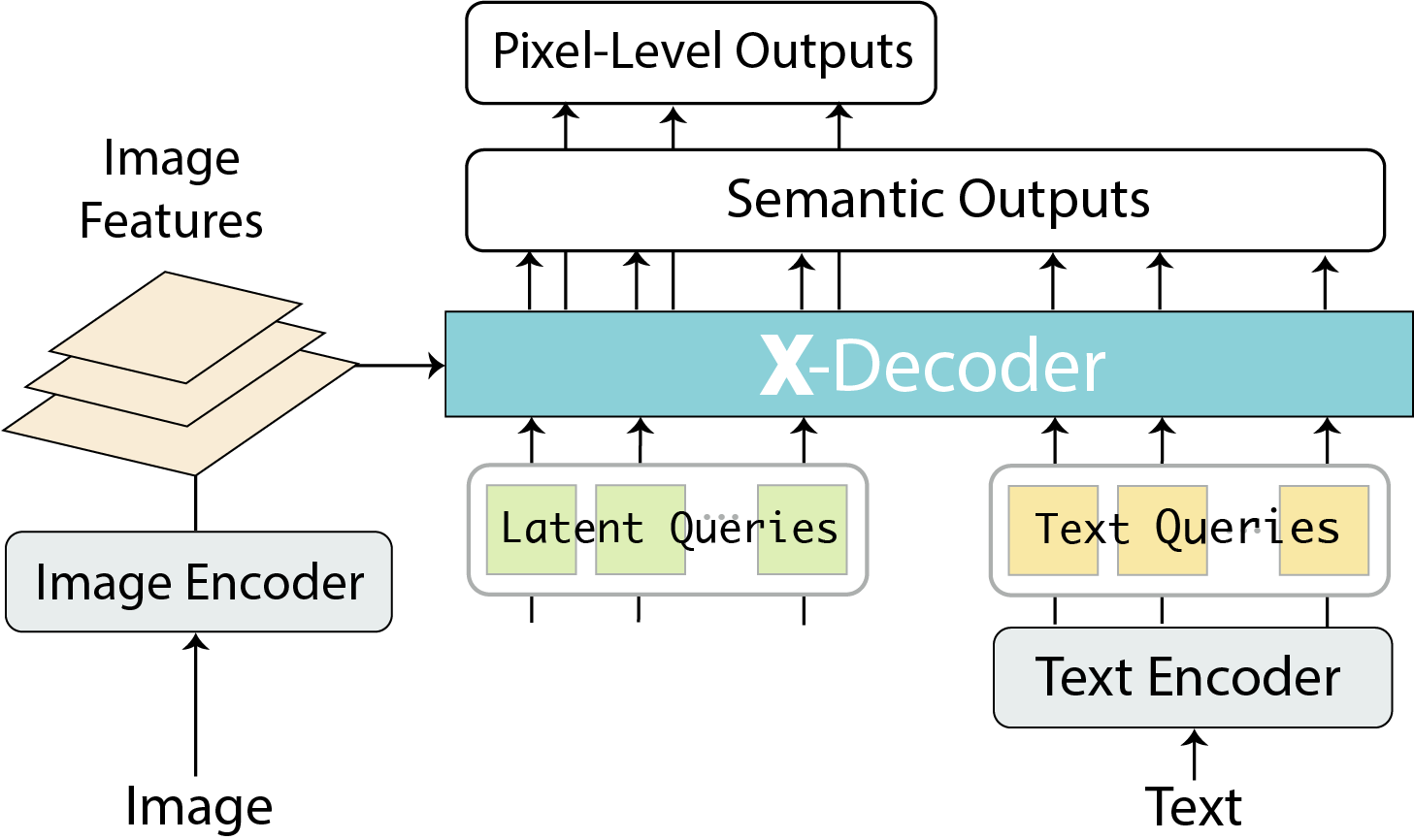
2つのクエリ×2つの出力

- X-DecoderのInputは2種類のクエリ
- Latent Queries(Image EncoderからのFPN状の特徴量)
- Text Queries(Text Encoderの特徴量)
- X-DecoderのOutputは2種類
- Semantic Outputs
- Pixel-Level Outputs
これらの組み合わせですべてのタスクを表現
エンコーダーでの画像とテキストを完全に分離
X-Decoderの工夫点:画像とテキストのエンコーダを完全に分離
* これまでの研究(MDETRやUnitab)はエンコーダーで画像とテキストをFusionするのが大半だった
* Contrastive Learinngや生成的な事前学習も困難
* X-Decoderのように完全に分離すると、出力をすべてクエリとして用いることが可能
* より強いピクセルレベル表現の学習と異なる粒度のタスクのサポートに不可欠
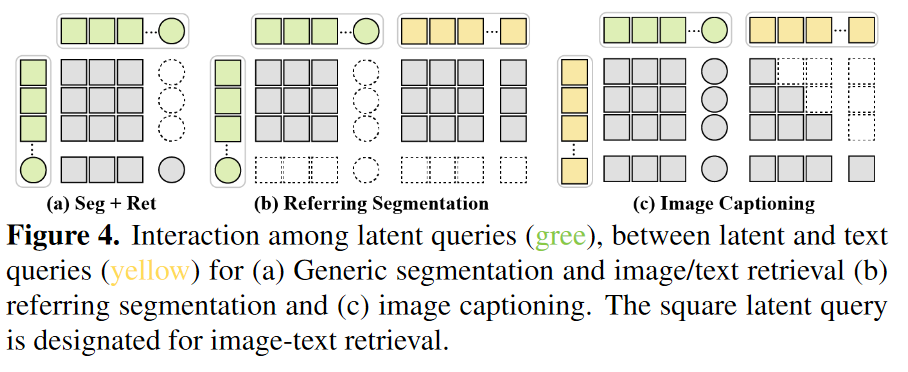
タスクごとに異なるマスク戦略
- X-Decoderでは、Latent QueryとText QueryについてSelf AttentionとCross Attentionをとっている
- Cross Attentionについては、タスクごとに取り方が違う
損失関数
- Senamtic OutputとText Queryとのアフィンをとり、Ground Truthとのクロスエントロピーを計算
- Sematic OutputとPixel-Level outputから、ハンガリアンマッチングを行い、セグメンテーションのロスを計算(Binary Cross EntropyやDice Loss)
訓練詳細
- 今までTask Specificだったデータセットを、タスクごとに一杯集めてきて事前訓練
- GPU数32で50エポック
- 10.4万枚でSegmentationの事前訓練をする
- クローズドなセットと比較するために、Task specificなFine-tuningをした
- VQAでヘッドを追加する以外はモデル構造はそのまま
結果
Task-specificなFinetuneをした場合、SoTA
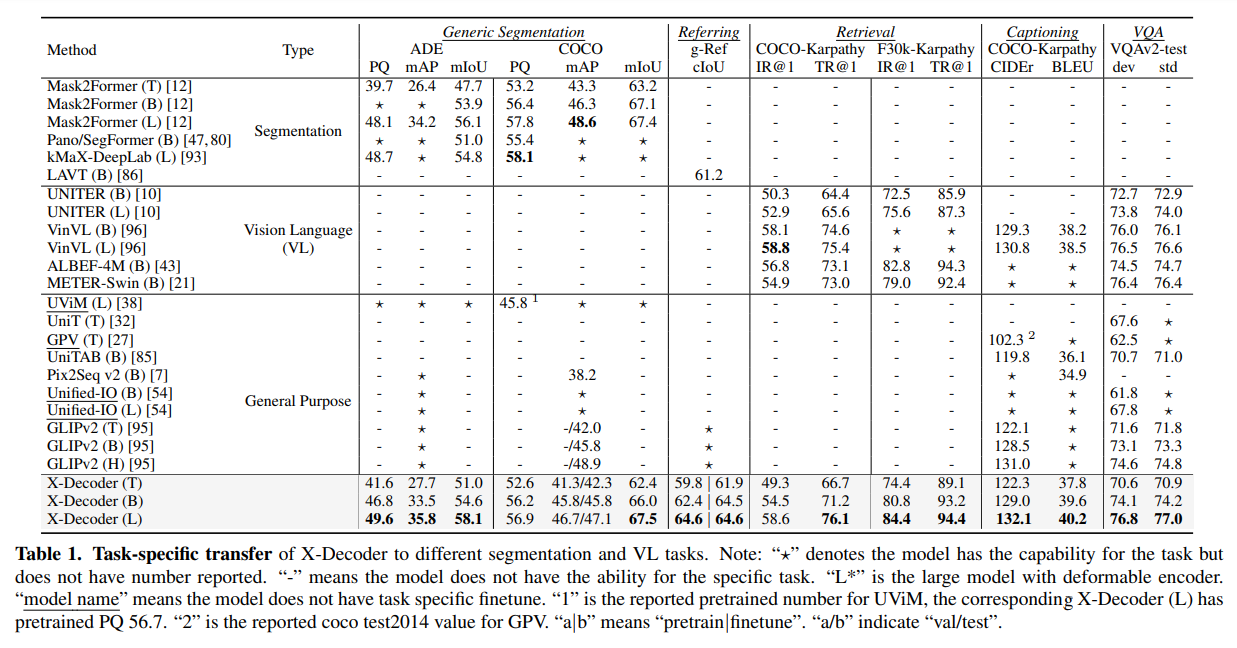
Zeroshotな設定でも、既存モデルよりよい。特にVOCでの精度が急激に良くなっている(事前訓練でリークしてる?)
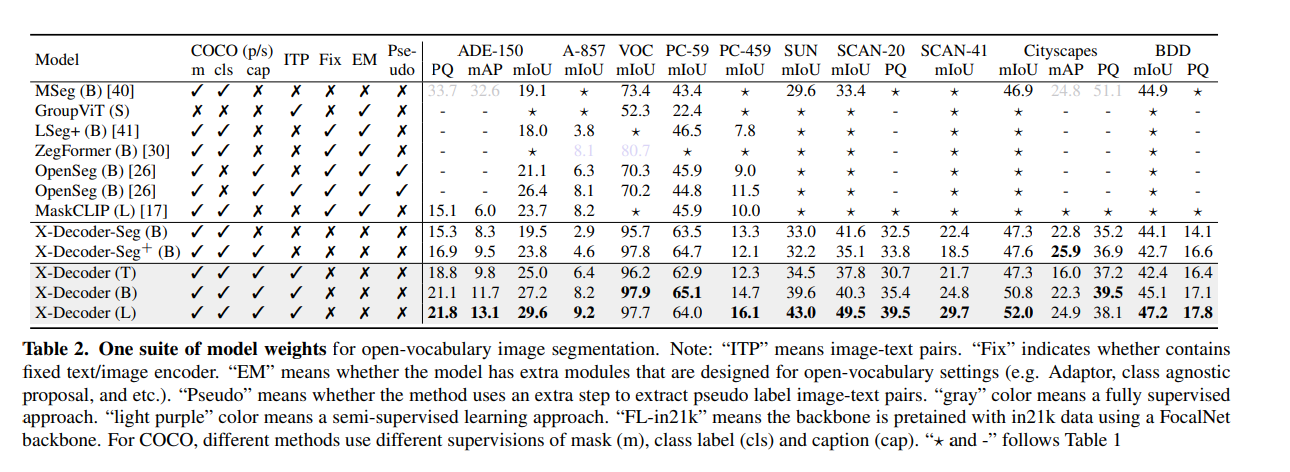
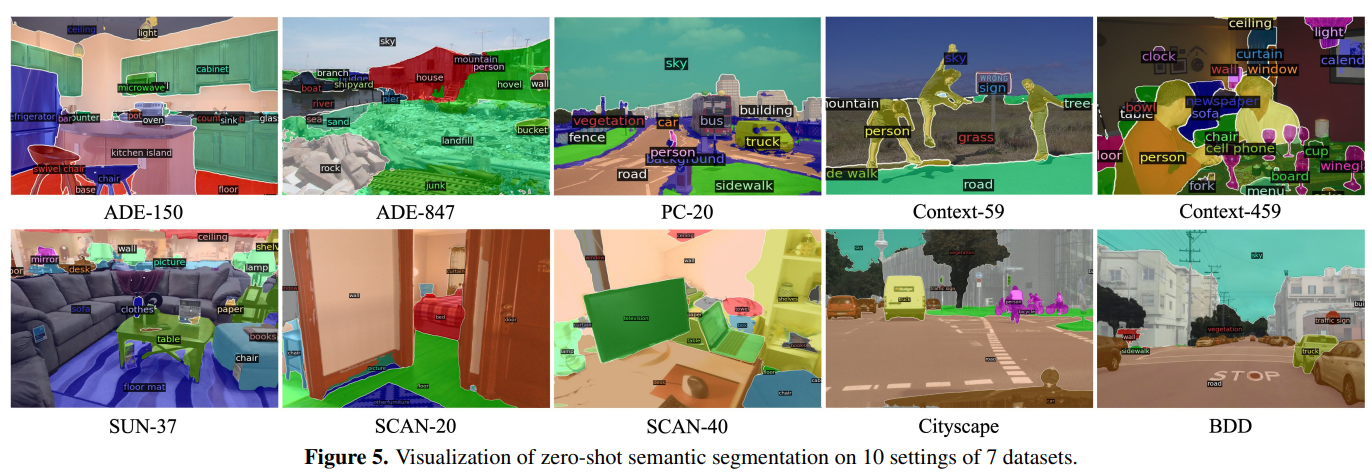
精度あんまりこだわらない例なら使えそうな印象
インスペクション
- 事前訓練タスクによる補完
- 画像-テキスト検索:Vision-Sematicのアラインメント形成に効く
- キャプション生成:参照セグメンテーションに大きく効く
- Fig4のマスクパターンは、全盛りが最も良かった。クエリの相互作用はある
- バッチサイズは1024から下げると急速に精度が下がる
- (CLIPなどでも大きなバッチサイズ要求してるので、V&Lモデルあるあるかも)
遊んでみた
手前の果物までスイカと誤認する
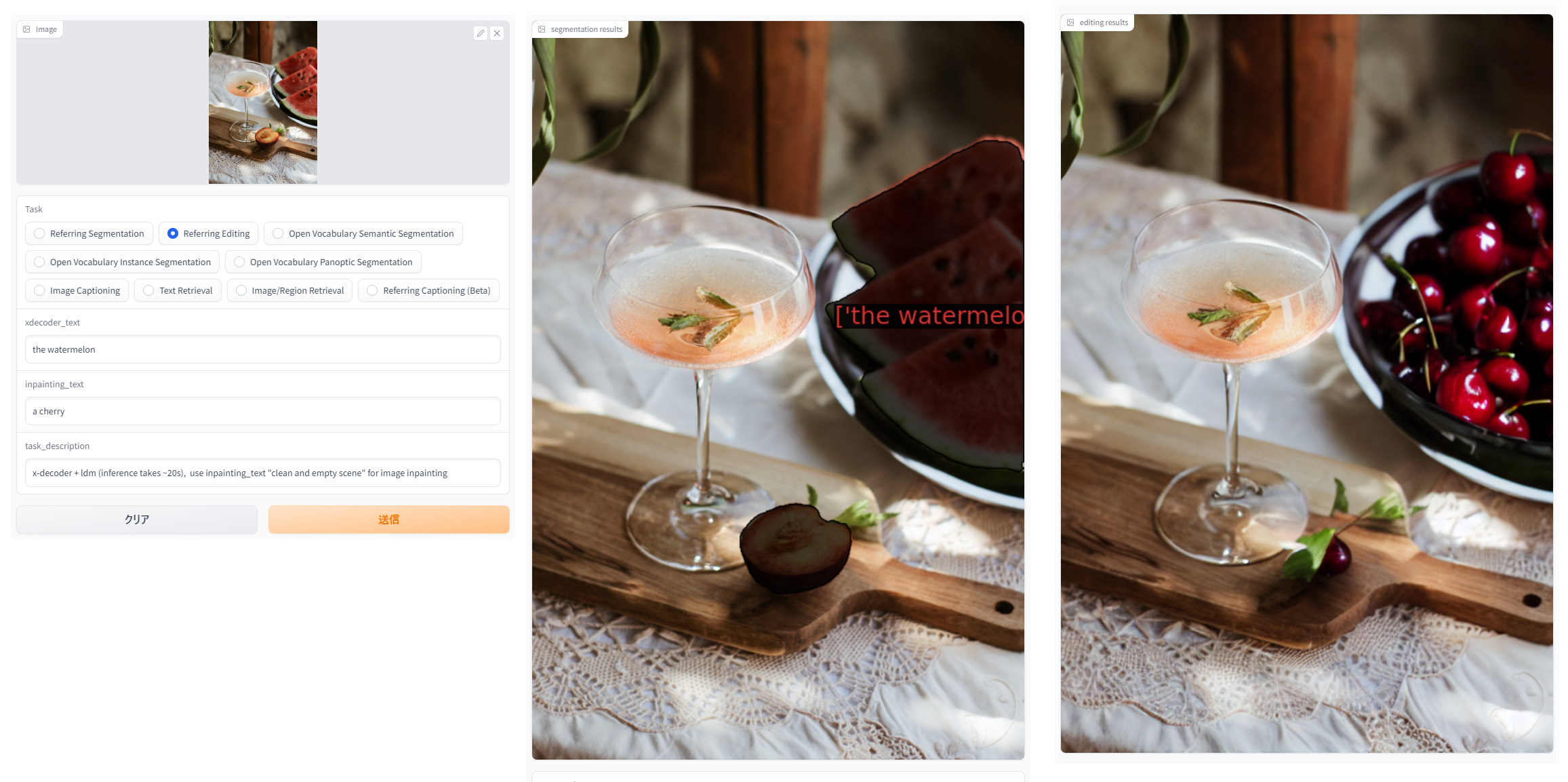
インスタンスセグメンテーションは厳密さ求めなければ割りと良さそう
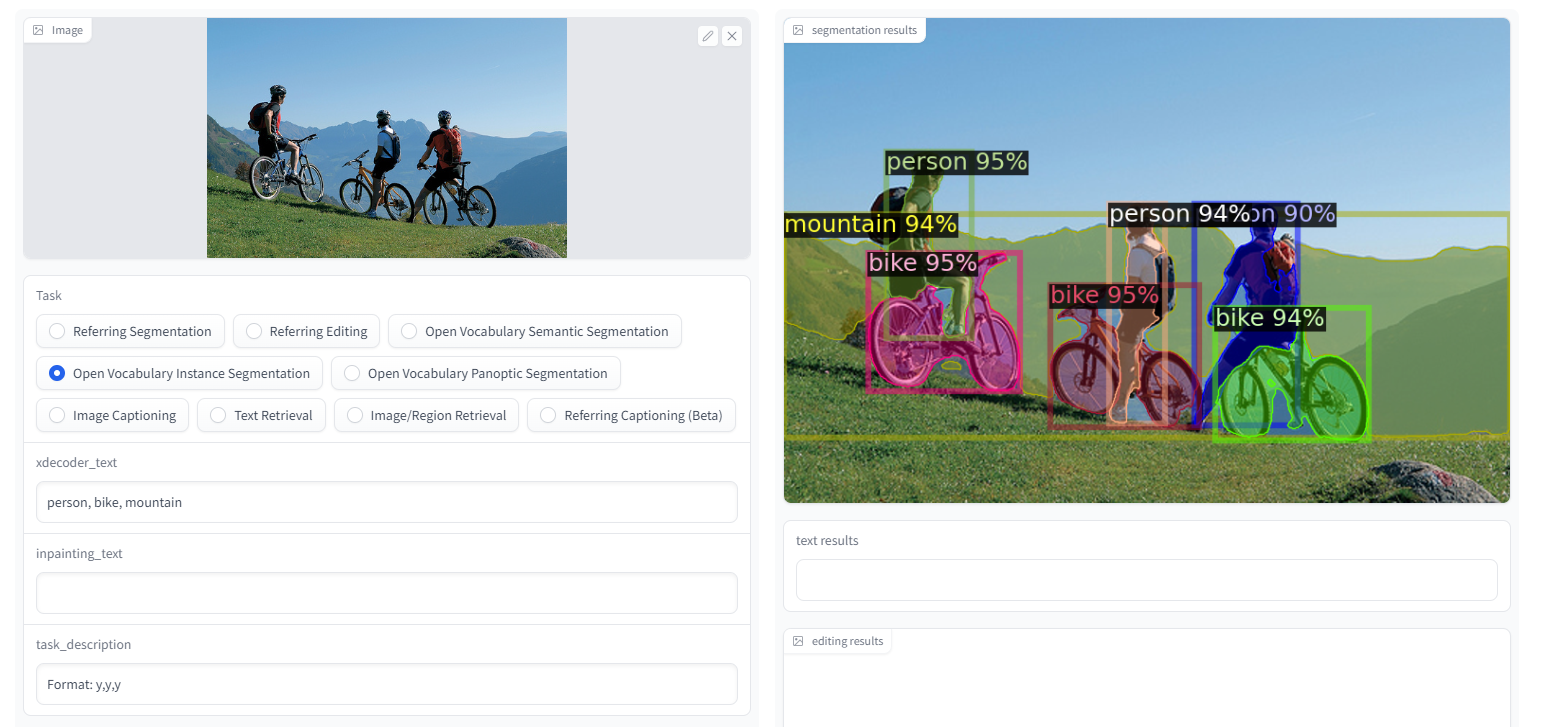
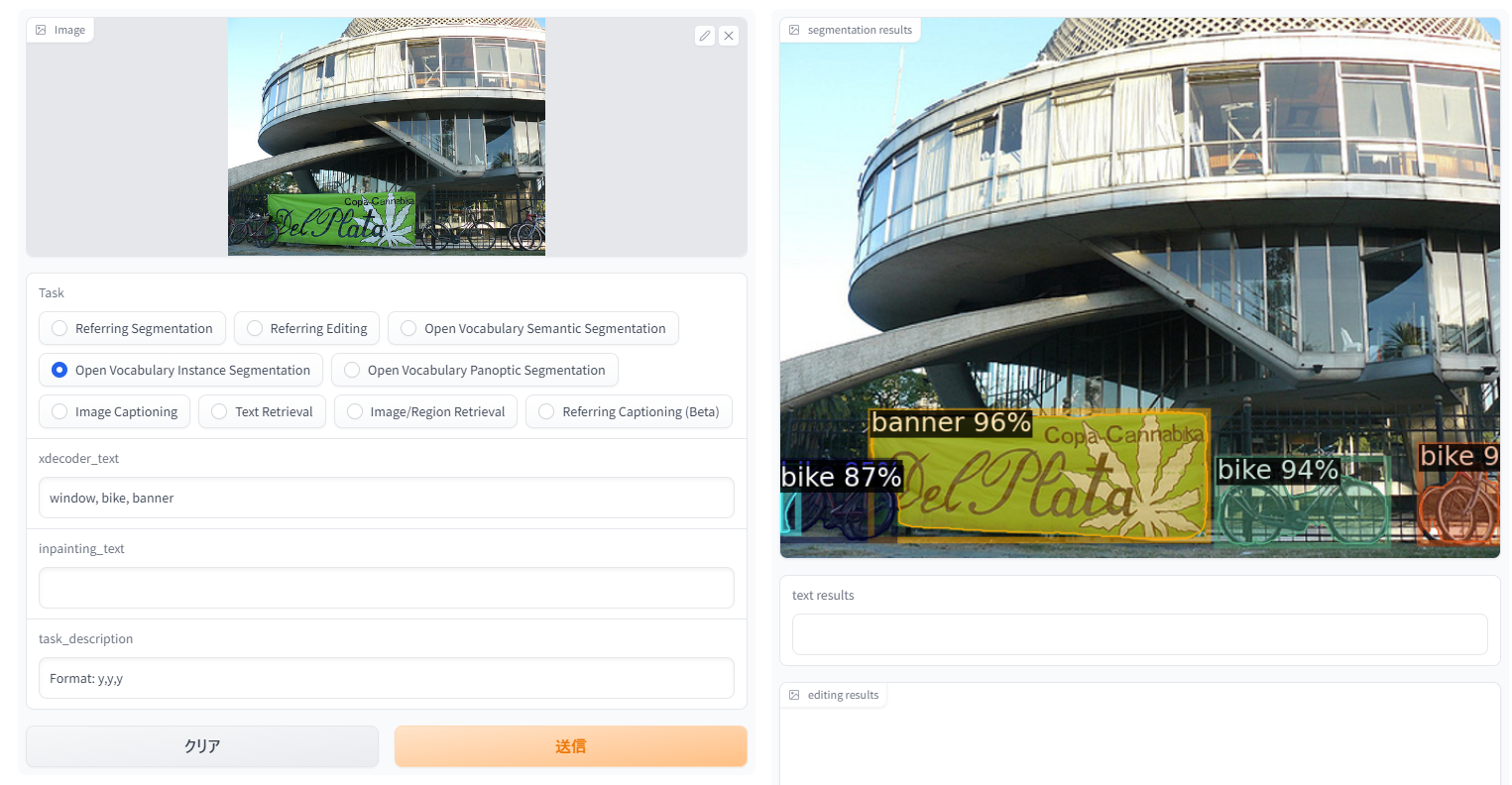
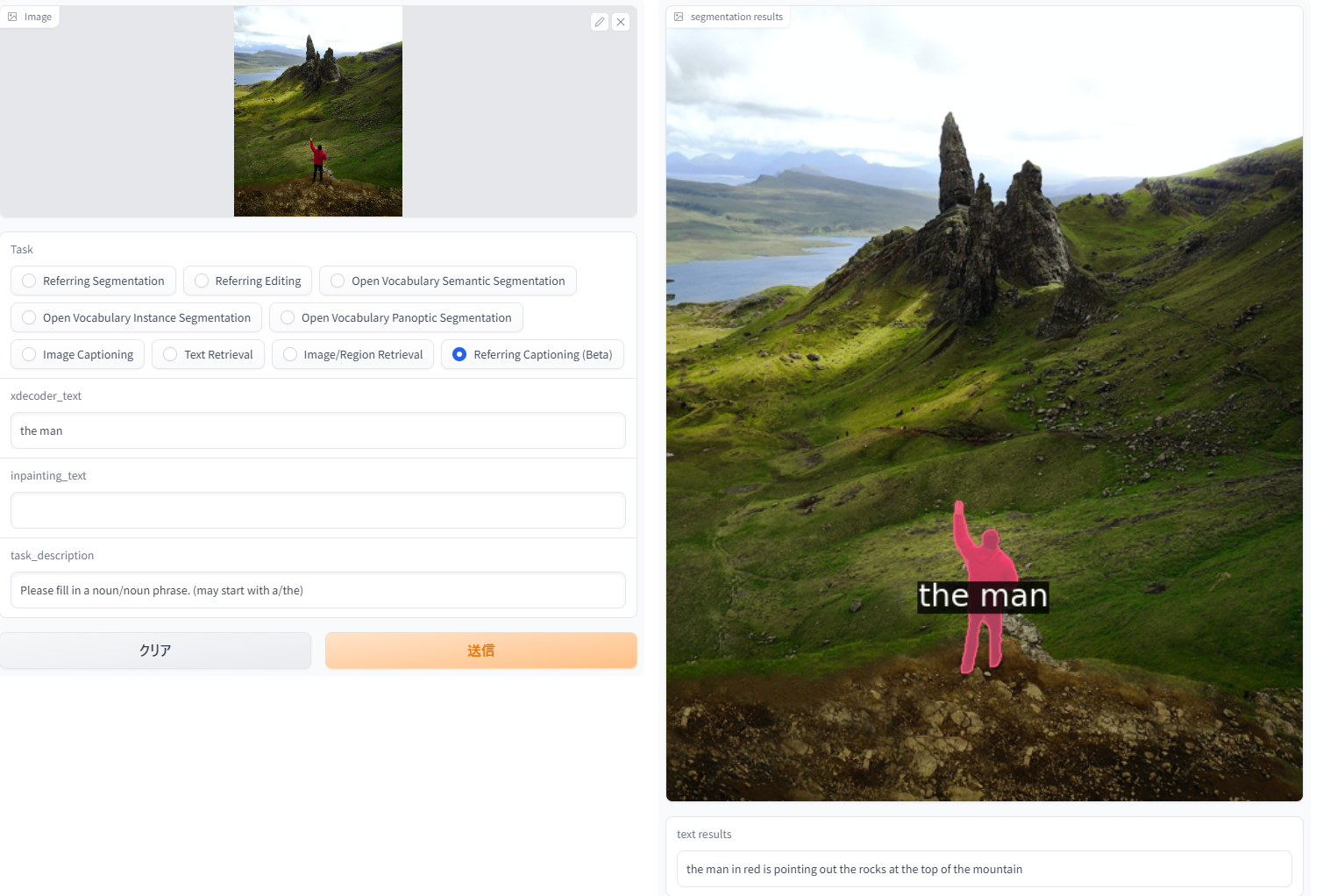
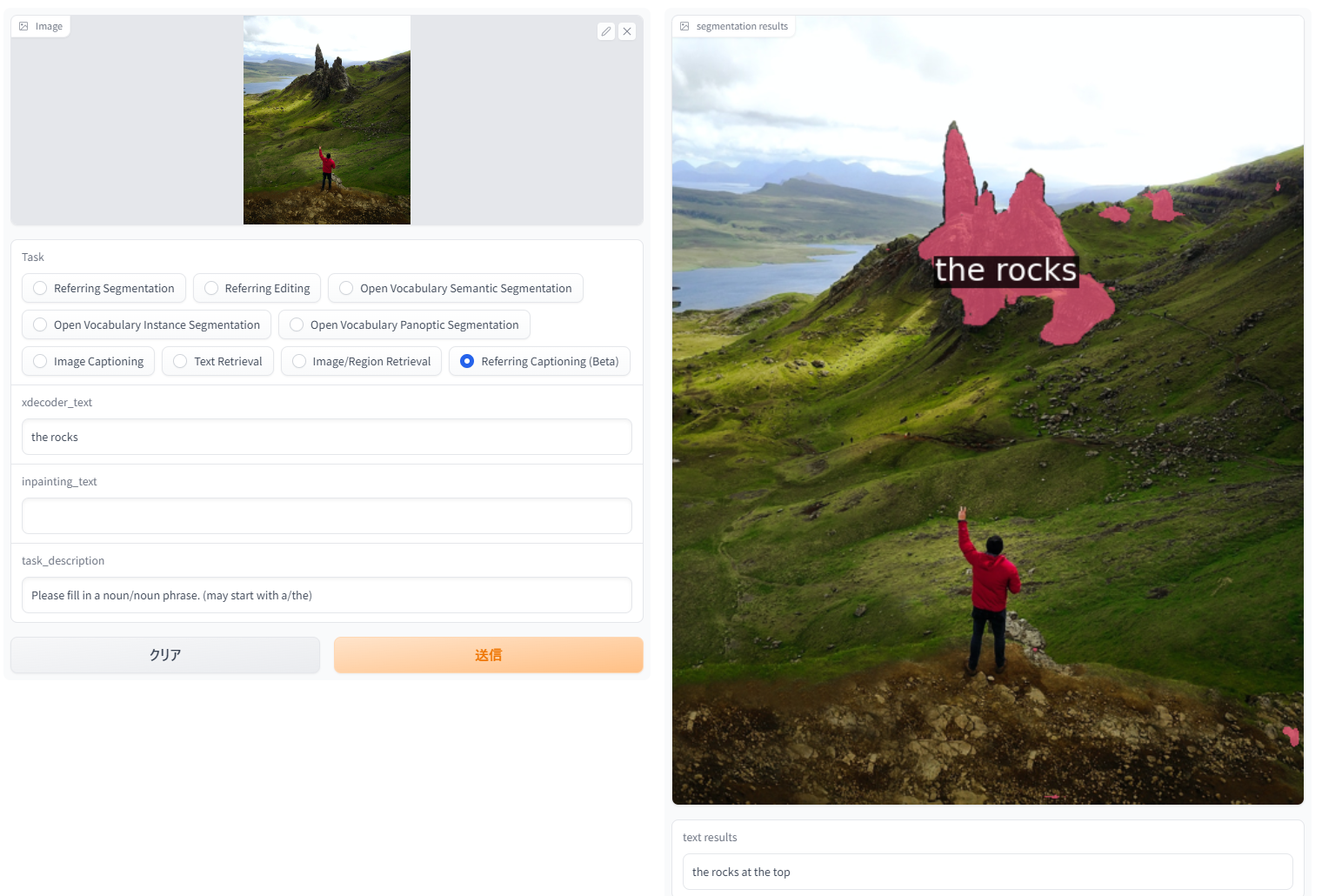
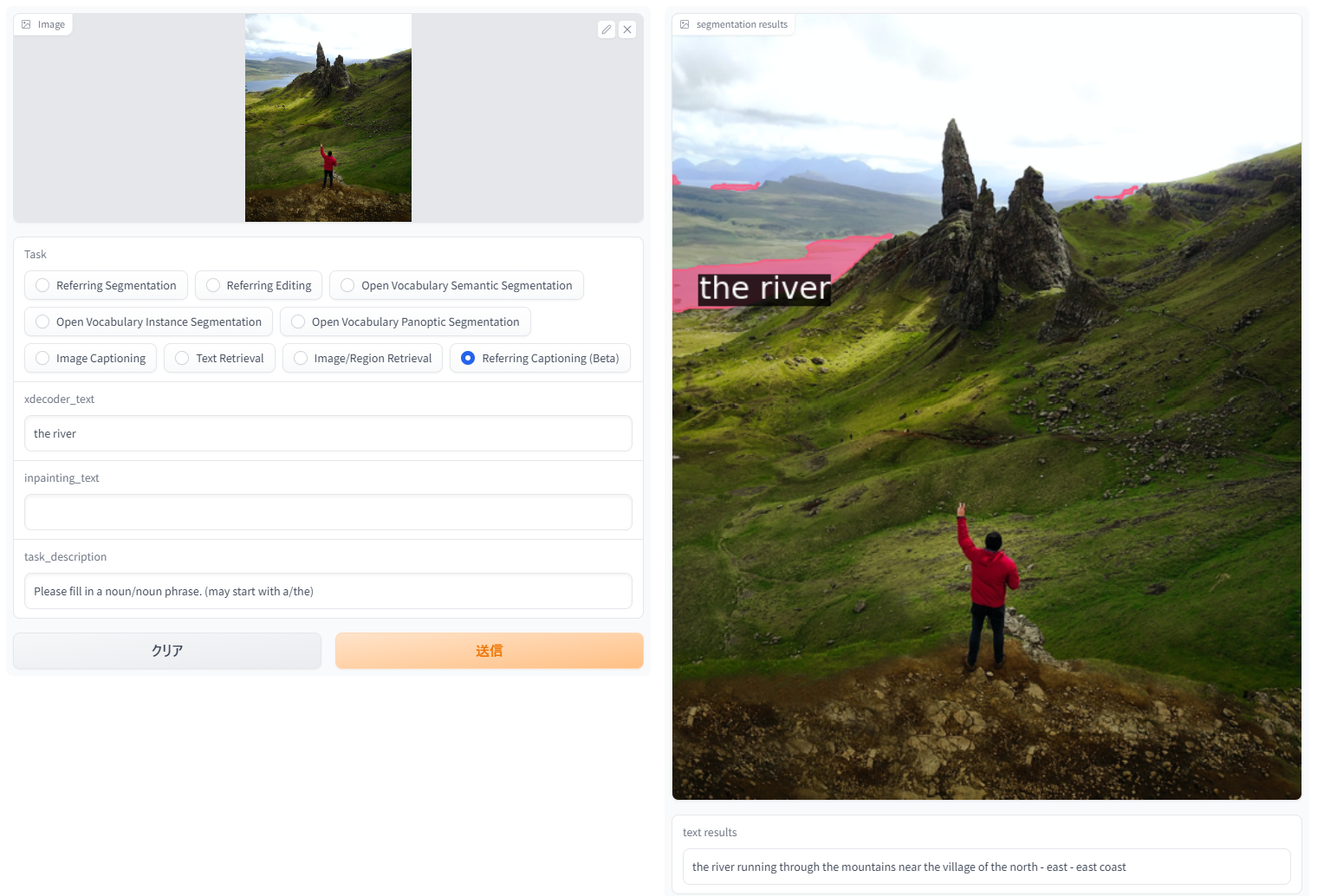
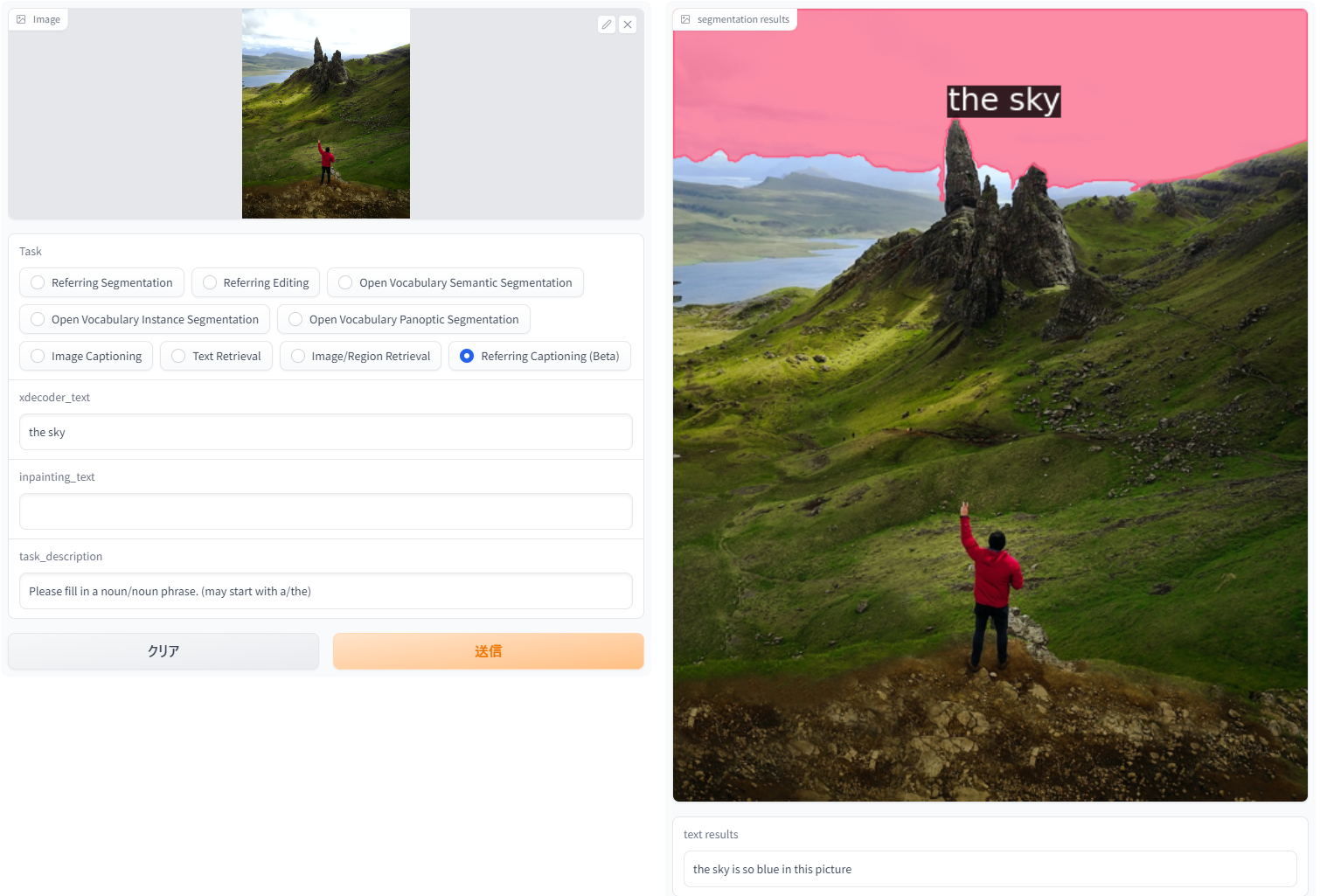
「Reffering Captioning」。新しいタスクで、領域を指定したキャプション生成。主観を変えてキャプション生成できて個人的にお気に入り。
| input | output |
|---|---|
| the man | the man in red is pointing out the rocks at the top of the mountain |
| the rocks | the rocks at the top |
| the river | the river running through the mountains near the village of the north-east-east coast |
| the sky | the sky is so blue in this picture |
所感
- HuggingFaceで使えるデモやコードが用意されていてとても良い。ライセンスもMIT
- ゼロショットのセグメンテーションがだいぶ使い物になってきたなという印象
- このモデルのオープンボキャブラリー設定は、特にインスタンスセグメンテーションが強そう
- 主観を変えてのキャプション生成はとても可能性を感じる
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー