
YOLOX+ByteTrackでお手軽トラッキングやってみた


YOLOX+ByteTrackでトラッキングをやってみました。「とりあえずサクッと訓練済みモデルでトラッキングしたい」というときに使える手法です。
目次
背景
トラッキング、需要ある割に個人的に食わず嫌いしていて、「ちょっと動かしておかないとまずいよなー」と思ってサクッと訓練済みモデルを動かしてみました。
参考
高橋かずひとさんのブログとリポジトリがとても便利なので、このサンプルコードをアレンジして動かしてみました。
https://kazuhito00.hatenablog.com/entry/2022/02/19/001641
https://github.com/Kazuhito00/yolox-bytetrack-mcmot-sample
想定環境
Google ColabのCPUインスタンスを想定します。
判定対象動画
以下の動画をトラッキングします。フリー素材からとってきたものです。
セットアップ
前提ライブラリをインストールします
!pip install onnxruntime lap cython_bbox
リポジトリをクローンします
!git clone https://github.com/Kazuhito00/yolox-bytetrack-mcmot-sample
%cd yolox-bytetrack-mcmot-sample
これはどちらでもいいですが、デフォルトのモデルがYOLOX-Tinyで、今回の用途としては軽すぎるので、YOLOX-Sを使います。YOLOXの公式リポジトリからダウンロードします。もともとこのリポジトリも同じ場所からダウンロードしているらしく、任意のサイズのYOLOXを利用できます。
!wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.onnx -P model
サンプルプログラムの改変
コードのsample.pyですが、ウィンドウ操作が入っておりColabで動かすとエラーになってしまうため、動画を書き出す方式に書き換えます。また、どの程度の精度で見ているのか詳しく見たかったので、トラッキングID単位で動画を切り出してみました。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import copy
import time
import argparse
import cv2
import numpy as np
import os
from yolox.yolox_onnx import YoloxONNX
from bytetrack.mc_bytetrack import MultiClassByteTrack
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--device", type=int, default=0)
parser.add_argument("--movie", type=str, default=None)
parser.add_argument("--width", help='cap width', type=int, default=960)
parser.add_argument("--height", help='cap height', type=int, default=540)
# YOLOX parameters
parser.add_argument(
"--yolox_model",
type=str,
default='model/yolox_nano.onnx',
)
parser.add_argument(
'--input_shape',
type=str,
default="416,416",
help="Specify an input shape for inference.",
)
parser.add_argument(
'--score_th',
type=float,
default=0.3,
help='Class confidence',
)
parser.add_argument(
'--nms_th',
type=float,
default=0.45,
help='NMS IoU threshold',
)
parser.add_argument(
'--nms_score_th',
type=float,
default=0.1,
help='NMS Score threshold',
)
parser.add_argument(
"--with_p6",
action="store_true",
help="Whether your model uses p6 in FPN/PAN.",
)
# motpy parameters
parser.add_argument(
"--track_thresh",
type=float,
default=0.5,
)
parser.add_argument(
"--track_buffer",
type=int,
default=30,
)
parser.add_argument(
"--match_thresh",
type=float,
default=0.8,
)
parser.add_argument(
"--min_box_area",
type=int,
default=10,
)
parser.add_argument(
"--mot20",
action="store_true",
)
args = parser.parse_args()
return args
class dict_dot_notation(dict):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.__dict__ = self
def main():
# 引数解析 #################################################################
args = get_args()
cap_device = args.device
cap_width = args.width
cap_height = args.height
if args.movie is not None:
cap_device = args.movie
# YOLOX parameters
model_path = args.yolox_model
input_shape = tuple(map(int, args.input_shape.split(',')))
score_th = args.score_th
nms_th = args.nms_th
nms_score_th = args.nms_score_th
with_p6 = args.with_p6
# ByteTrack parameters
track_thresh = args.track_thresh
track_buffer = args.track_buffer
match_thresh = args.match_thresh
min_box_area = args.min_box_area
mot20 = args.mot20
# カメラ準備 ###############################################################
cap = cv2.VideoCapture(cap_device)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, cap_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, cap_height)
cap_fps = cap.get(cv2.CAP_PROP_FPS)
# 出力ファイル
if args.movie is not None:
outpath = os.path.splitext(args.movie)[0] + "_tracked.webm"
else:
outpath = "camera.webm"
writer = cv2.VideoWriter(
outpath,
cv2.VideoWriter_fourcc(*'vp80'),
cap_fps, (cap_width, cap_height)
)
# モデルロード #############################################################
yolox = YoloxONNX(
model_path=model_path,
input_shape=input_shape,
class_score_th=score_th,
nms_th=nms_th,
nms_score_th=nms_score_th,
with_p6=with_p6,
providers=['CPUExecutionProvider'],
)
# ByteTrackerインスタンス生成
tracker = MultiClassByteTrack(
fps=cap_fps,
track_thresh=track_thresh,
track_buffer=track_buffer,
match_thresh=match_thresh,
min_box_area=min_box_area,
mot20=mot20,
)
# トラッキングID保持用変数
track_id_dict = {}
# COCOクラスリスト読み込み
with open('coco_classes.txt', 'rt') as f:
coco_classes = f.read().rstrip('\n').split('\n')
# トラッカー別のフレーム保持用
track_id_frames = {}
while True:
start_time = time.time()
# カメラキャプチャ ################################################
ret, frame = cap.read()
if not ret:
break
debug_image = copy.deepcopy(frame)
# 推論実施 ########################################################
# Object Detection
bboxes, scores, class_ids = yolox.inference(frame)
# Multi Object Tracking
t_ids, t_bboxes, t_scores, t_class_ids = tracker(
frame,
bboxes,
scores,
class_ids,
)
# トラッキングIDと連番の紐付け
for trakcer_id, bbox in zip(t_ids, bboxes):
if trakcer_id not in track_id_dict:
new_id = len(track_id_dict)
track_id_dict[trakcer_id] = new_id
elapsed_time = time.time() - start_time
# デバッグ描画
debug_image = draw_debug(
debug_image,
elapsed_time,
score_th,
t_ids,
t_bboxes,
t_scores,
t_class_ids,
track_id_dict,
coco_classes,
track_id_frames
)
# 書き込み
writer.write(debug_image)
cap.release()
writer.release()
# トラッキングID単位の動画
write_track_id_wise_video(
track_id_frames,
outpath.replace(".webm", ""),
cap_fps)
def get_id_color(index):
temp_index = abs(int(index)) * 3
color = ((37 * temp_index) % 255, (17 * temp_index) % 255,
(29 * temp_index) % 255)
return color
def write_track_id_wise_video(
track_id_frames_dict,
base_dir, cap_fps
):
if not os.path.exists(base_dir):
os.makedirs(base_dir)
for track_id, track_frames in track_id_frames_dict.items():
width, height = 0, 0
for frame in track_frames:
height = max(frame.shape[0], height)
width = max(frame.shape[1], width)
writer = cv2.VideoWriter(
f"{base_dir}/{track_id}.webm",
cv2.VideoWriter_fourcc(*'vp80'),
cap_fps, (width, height)
)
for frame in track_frames:
pad_left = (width - frame.shape[1])//2
pad_right = width - frame.shape[1] - pad_left
pad_top = (height - frame.shape[0])//2
pad_bottom = height - frame.shape[0] - pad_top
frame_pad = cv2.copyMakeBorder(frame,
pad_top, pad_bottom, pad_left, pad_right,
cv2.BORDER_CONSTANT, (0, 0, 0))
writer.write(frame_pad)
writer.release()
def draw_debug(
image,
elapsed_time,
score_th,
trakcer_ids,
bboxes,
scores,
class_ids,
track_id_dict,
coco_classes,
tracker_id_frames,
):
debug_image = copy.deepcopy(image)
for tracker_id, bbox, score, class_id in zip(trakcer_ids, bboxes, scores,
class_ids):
x1, y1, x2, y2 = int(bbox[0]), int(bbox[1]), int(bbox[2]), int(bbox[3])
if score_th > score:
continue
color = get_id_color(int(track_id_dict[tracker_id]))
# バウンディングボックス
debug_image = cv2.rectangle(
debug_image,
(x1, y1),
(x2, y2),
color,
thickness=2,
)
# トラックID、スコア
score_txt = str(round(score, 2))
text = 'Track ID:%s(%s)' % (int(track_id_dict[tracker_id]), score_txt)
debug_image = cv2.putText(
debug_image,
text,
(x1, y1 - 30),
cv2.FONT_HERSHEY_SIMPLEX,
0.7,
color,
thickness=2,
)
# クラスID
text = 'Class ID:%s(%s)' % (class_id, coco_classes[class_id])
debug_image = cv2.putText(
debug_image,
text,
(x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX,
0.7,
color,
thickness=2,
)
# ID別のフレームを記録
crop = debug_image[max(y1-30,0):y2, x1:x2, :]
if not tracker_id in tracker_id_frames.keys():
tracker_id_frames[tracker_id] = [crop]
else:
tracker_id_frames[tracker_id].append(crop)
# 推論時間
text = 'Elapsed time:' + '%.0f' % (elapsed_time * 1000)
text = text + 'ms'
debug_image = cv2.putText(
debug_image,
text,
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
0.7,
(0, 255, 0),
thickness=2,
)
return debug_image
if __name__ == '__main__':
main()
ID単位での動画の書き出したものがいらなければ「write_track_id_wise_video」などを削除してください(私が追加した部分は適当に書いたコードです)
実行
!python sample.py --movie ../pexels-grace-wu-6022014.mp4 --width 1280 --height 720 --yolox_model model/yolox_s.onnx --input_shape 640,640
このようにバックエンドのYOLOXのモデルも変えられます。
できたもの
※51MBもあるので注意
ぱっと見るといい感じでした。しかし、ID単位のビデオを見ると、「全体の流れを考え、できるだけ少ないIDで統合している」というところに弱さを感じました。おそらくYOLOXの閾値を調整すればある程度カバーできるでしょうが、小さいオブジェクトのトラッキングはやはり物体検出同様難しそうです。ここの求められるさじ加減ユースケースによると思います。
以下の画像は、私が手動で細切れの動画をつなぎ合わせたときのタイムラインです。1秒に満たない小さな動画で細分化されているのがわかります。こういう小さなIDはルールベースで弾いてもいいかもしれません。
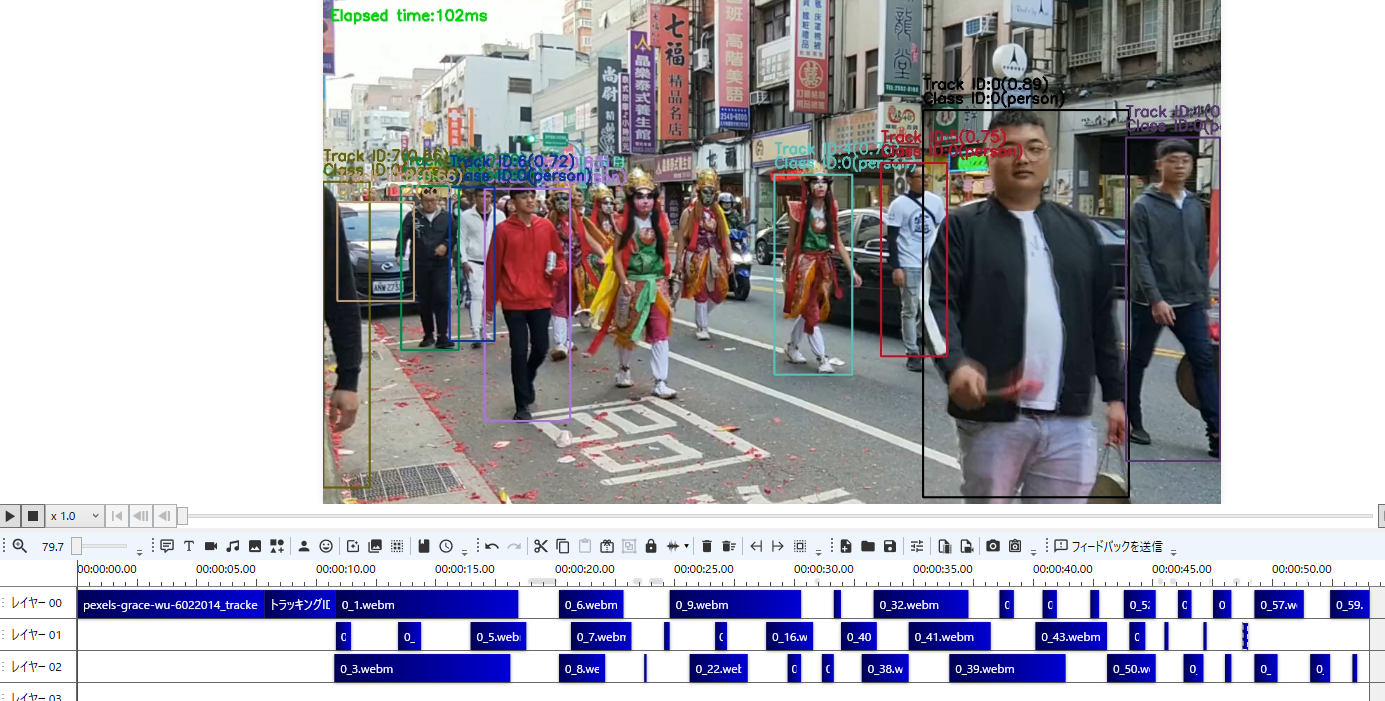
とりあえずさっくりトラッキングできたので、当初の目標はクリアできました。とても使いやすいリポジトリだったので高橋かずひとさん感謝です!
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー