
論文まとめ:StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis
Posted On 2023-01-12


- タイトル:StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis
- 著者:Yinghao Aaron Li, Cong Han, Nima Mesgarani(コロンビア大学)
- 論文:https://arxiv.org/abs/2205.15439
- コード:https://github.com/yl4579/StyleTTS
- デモ:https://styletts.github.io/
目次
ざっくりいうと
- 1対多の音声合成が可能なText-to-Speechモデル
- StyleGANに触発され、スタイルや音韻、アラインメントをモデル内で分離し、デコーダーでAdaINで挿入
- VITSよりも豊かなバリエーションを伴った合成結果を示し、単一話者モデルからZeroshot適応が可能
はじめに
- TTSは本質的に1対多のマッピング問題
- 同じテキストでも、文脈、感情、方言などにより、様々な話し方が可能
- 変分推論などいくつものアプローチが提案されているが、異なる話者の話し方や感情のトーンを適切にモデル化し、取り入れることは依然として困難
- 非自己回帰型並列 TTS モデルは、自己回帰型モデルと比較していくつかの利点がある。
- 並列実装を十分に活用して高速な音声合成を可能
- 長い発話やOOD(out-of-distribution)発話に対してより頑健
- 音素の継続時間、ピッチ、エネルギーが音声から独立して予測可能
- 現在のモデルの限界:自己回帰方式に対する並列TTSの改善と、表現力豊かな音声合成を可能にするスタイルの活用は、ほとんど別々に行われていること
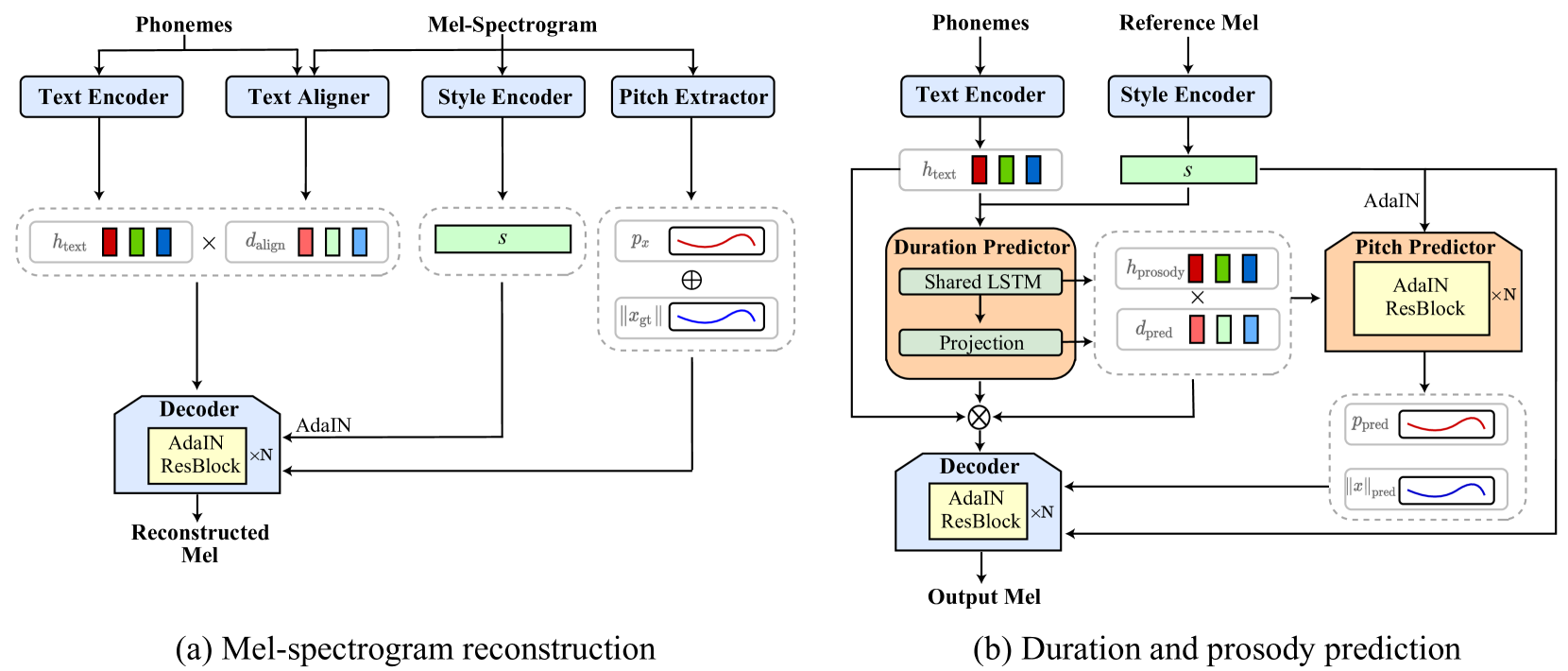
StyleTTS
モデル構造
Input:音素列とReference Sound
Output:メルスペクトログラム(ボコーダーは別)
- Text Encoder:入力が音素t、出力がテキストの特徴量h_text
- Text Aligner:入力が音素t、出力がメルスペクトログラムと音素のアライメントd_align。モデルはTacorton 2のデコーダーの後ろ
- Style Encoder:後のAdaINブロックに差し込むためのスタイルエンコーダー。Residual Blockからなる。
- Pitch Extractor:ピッチF0について、直接Hzを抽出する。独自のピッチ抽出器をデコーダとともに学習させる
- Decoder:出力はメルスペクトログラム。Styleの部分をAdaINで挿入する
- Discriminator:VITSのDiscriminatorを使った
- Duration Predictor:音素の長さの予測。AdaINのあるBidirectional LSTM
損失関数
2段階に損失関数を分けて訓練
- 1段階の損失関数の構成
- Mel reconstruction:メルスペクトログラムのL1ロス
- TMA objects(s2s, mono):アラインメントをクロスアテンションで表現し、そのロスを作りたい
- s2s:音素のクロスエントロピー(分類問題と同じ)
- mono:アラインメントをDPで考え(VITSと思想は同じ)たときのロス
- Adversarial Loss:メルスペクトログラムに対するGANのロス。VITSと同様
- 2段階の損失関数の構成
- Duration prediction:音素の長さ
- Prosody prediction:この論文の新たな仕組みとして、メルスペクトログラムを時系列方向に伸縮するData Augmentationを行い、アライメント、ピッチ、エネルギーを抽出する(音速が変わってもアラインメント以外は変わらないから)
- P_p:prosody predictorの出力
- P_n:エネルギーの出力
- Decoder reconstruction:AugmentationされたメルスペクトログラムのReconstruction
実験
単一話者からなるデータセットLJSpeechで訓練。VITSより良い結果となった
Zeroshotな話者適応生成も可能だった。Styleベクトルのt-SNEを見たところ、感情を分離 or 話者IDの分離をしつつ学習していた。

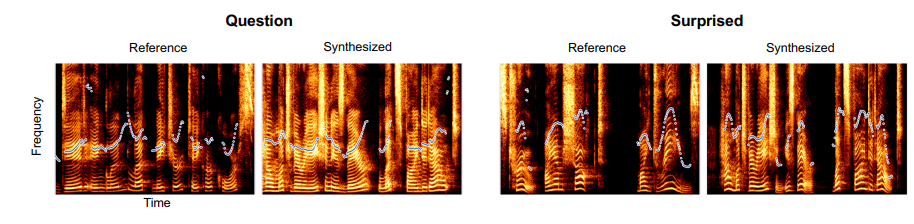
参照の音声を変えて合成したところ、Question・Suprisedといった感情を伴った音声合成が可能だった。参照音声の感情により、合成音声のメルスペクトログラムやピッチが変わっている。
- Synthesizedで読ませたテキスト:How much variation is there? Let’s find it out.
- Referenceで人間が読んだもの:
- 左:Did England let nature take her course?
- 右:It’s true! I am shocked! My dreams!
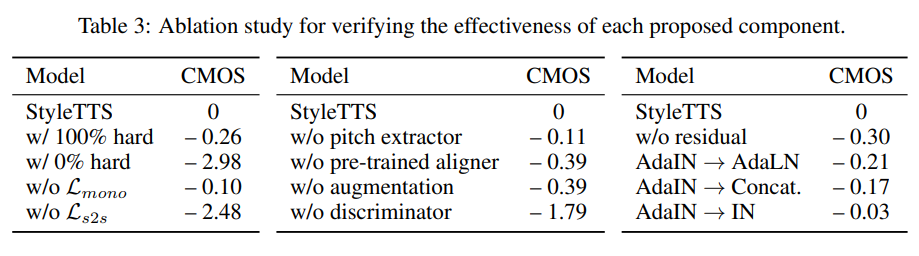
効いている損失関数について
- w/ 0% hard:Transferable Monotonic Aligner (TMA)部分。勾配が伝わらず音素アラインメントの学習がうまくいかなかった
- w/o L_s2s:音素のクロスエントロピーをなくす
- w/o discriminator:GANベースをやめる
所感
- StyleGANを知っている人間にとっては馴染み深いモデル構造だった
- 特殊な学習方法や膨大な学習データを使っているわけでもないのに、単一話者の学習データから、別の人間のZeroshot適応ができるのが不思議で仕方ない
- ボコーダーが別途必要で、PretrainedなHiFi-GANを使っているが、日本語に適用したときにこのボコーダーでいいのだろうか
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー