
論文まとめ:Style Aligned Image Generation via Shared Attention
Posted On 2024-05-09


- タイトル:Style Aligned Image Generation via Shared Attention
- 論文URL:https://arxiv.org/abs/2312.02133
- プロジェクトページ:https://style-aligned-gen.github.io/
- コード:https://github.com/google/style-aligned/
- カンファ:CVPR 2024
目次
ざっくりいうと
- Text-to-Image生成モデルで画像のスタイル一貫性を保ちながら多様なコンテンツを生成することに焦点を当てた研究
- 提案手法は、自己注意機構にわずかな変更を加え、適応的正規化を用いて計算コストを削減し、高品質な画像を生成。
- 任意のT2Iモデルに応用可能であり、今後は生成画像の形状や外観の一貫性向上を目指す。
1分で読む用
要約By Claude3
- この論文において解決したい課題は何?
- この論文では、Text-to-Image (T2I) 生成モデルにおいて、生成された画像の一貫したスタイル解釈を実現することが課題となっている。
- 先行研究だとどういう点が課題だった?
- 従来の手法では、スタイルとコンテンツの分離のために、大量の画像を使ってファインチューニングを行う必要があり、計算コストが高かった。
- 先行研究と比較したとき、提案手法の独自性や貢献は何?
- 本手法では、生成プロセスの自己注意機構にわずかな変更を加えることで、参照画像のスタイルを共有しながら、多様なコンテンツの画像を生成できる。
- 提案手法の手法を初心者でもわかるように詳細に説明して
- 提案手法では、参照画像の特徴に対して適応的正規化を行い、参照画像との注意共有を行うことで、スタイル一貫性を保ちつつ、コンテンツの多様性も実現している。
- 提案手法の有効性をどのように定量・定性評価した?
- 定量的・定性的評価の結果、提案手法は高品質な画像生成と優れたスタイル一貫性を示しており、既存手法と比べて優位性があることが確認された。
- この論文における限界は?
- 提案手法は、最適化やファインチューニングを必要とせず、任意のT2Iモデルに適用できるという利点がある。
- 次に読むべき論文は?
- 今後の課題として、スタイルとコンテンツの関係性をより深く理解し、生成画像の形状や外観の一貫性をさらに高めることが挙げられる。
手法のポイント
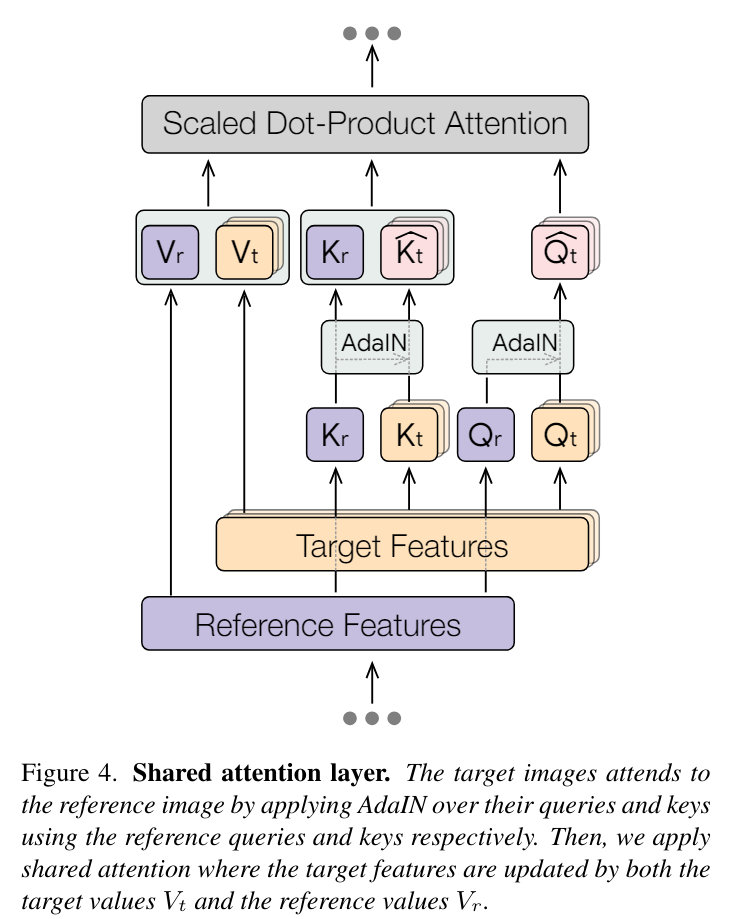
- 1度の推論の中で、複数のサンプルを同時生成し、スタイル統一をゼロショットで行いたい。さらにこれが任意のモデルでできるようにしたい
- これを実現するために、Self Attentionレイヤーの中で、サンプル間の互いの特徴の更新を行う
- 本研究の独自性は、生成画像間の通信を可能にするために、Self Attentionを利用すること
- しかし、サンプル間で完全にSelf Attentionを共有してしまう(*1)と図(*3)の下の段のように悪影響が出てしまう
- 悪影響:多様性の損失(スタイルの崩壊)、コンテンツのリーク
- AdaINではなく、Self AttentionでReference→生成画像の一方向の通信のみに限定したのが、図(*3)の中段。
- 下段よりかはよくなったが、中段は異なる画像のスタイルが一致していない。
- Attentionの計算の前段にAdaINを入れて(*2)、Projectionレイヤーでの画像間の通信を行うことで悪影響を回避。図(*3)の上の段
- これを実現しているのがQuery-KeyのAdaIN。
- しかし、サンプル間で完全にSelf Attentionを共有してしまう(*1)と図(*3)の下の段のように悪影響が出てしまう
*1

*2

*3

評価
- オブジェクト+スタイルのテキストプロンプトをChatGPTの支援で100個作成
- > “{A guitar, A hot air balloon, A sailboat, A mountain} in papercut art style.”
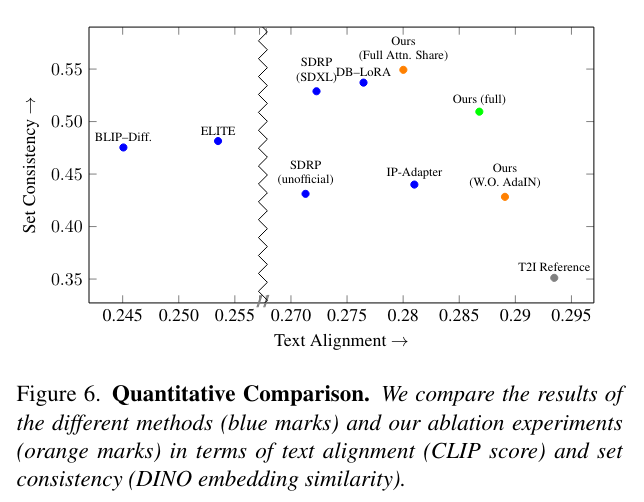
- メトリックス
- テキストアラインメント:CLIPのCosine類似度で画像とテキストのアラインメントを計測
- スタイルの一貫性:各生成間のDINO VIT-B/8の埋め込みのペア平均Cosine類似度
- CLIPはクラスラベルで学習されているため、類似の内容だがスタイルが異なる集合に高いスコアを与える可能性があるため、代替モデルが必要。DINOはSelf-Supervisedで学習しているためこの点強い

応用例
- DDIM反転と組み合わせることで、Referenceを画像として与えることも可能
- DDIM反転=画像を潜在空間に戻す
- ただし、DDIMは誤ったTrajectoryになるかもしれないし、失敗するかもしれない
- Multi-Diffusionを組み合わせて切り絵のようなパノラマ生成をすることが可能

- ControlNetとの組み合わせ(ControlNetならなんでもかんでもできるってわけではなさそう?)

試してみた
Animagine XL3.1で試す
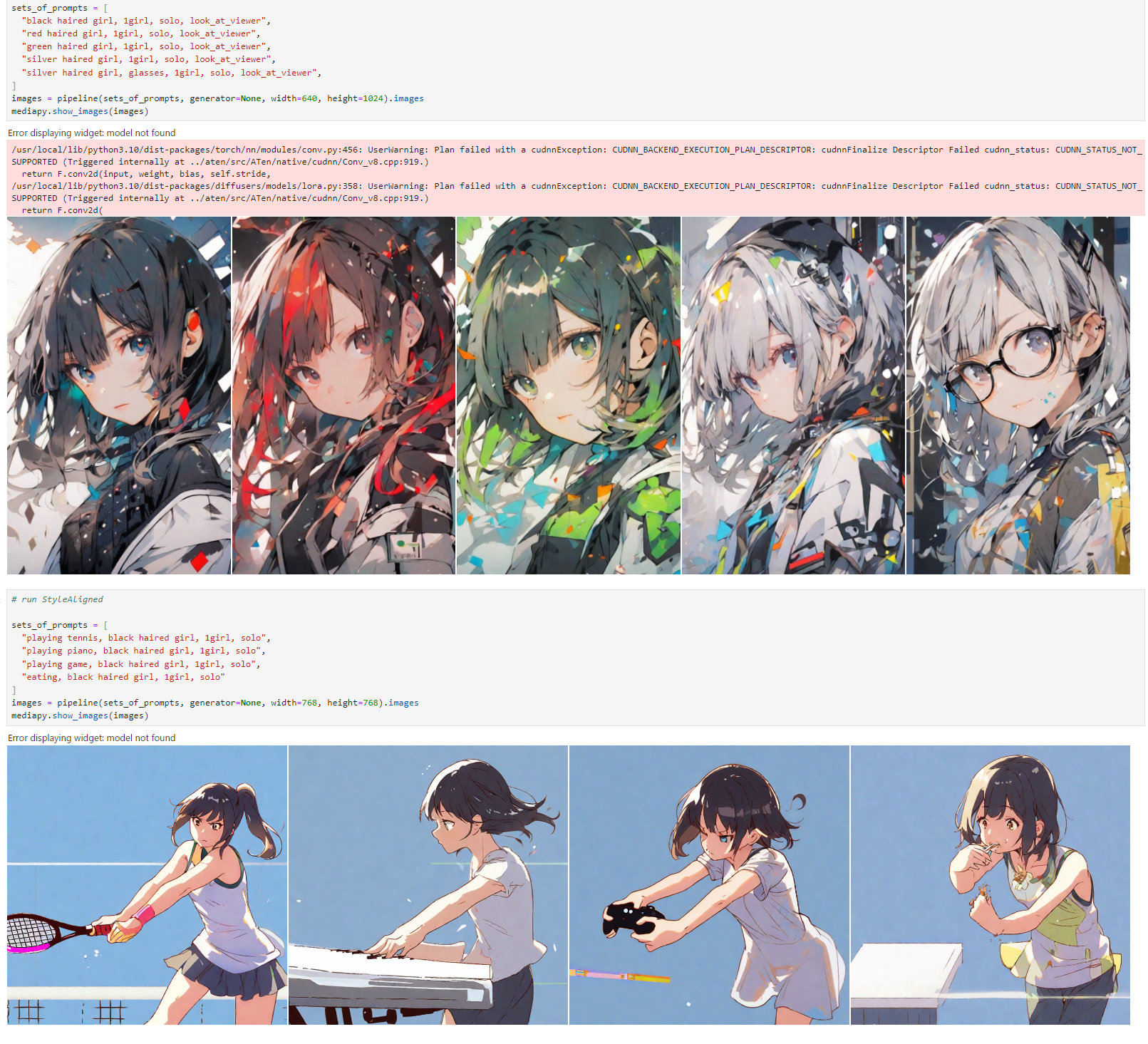
- 一発の生成で構図が揃うのは結構強い。T2Iで一貫する結構うまくいく
- Referece Imageがあるケースは、論文に書いてあるとおりDDIM反転があんまりうまくいかないことがある
- 一発で複数枚生成しないといけないというのが結構なネックで、SDXL系は複数枚同時だとVAEの部分でVRAMをいっぱい消費するので、Latentで生成して1枚ずつVAEに通す的な工夫が必要かもしれない
所感
- アイディアがシンプルな割に強くて面白い
- サンプルコード試してみたが、Jupyterやデモアプリが充実していて優秀
- Dreambooth-LoRAより、訓練なしのほうが一貫性があるというのは面白い(Dreambooth-LoRAはそんなに優秀ではなく、T2I-LoRAとの比較ではないってのもありそう)
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー