
論文まとめ:SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Posted On 2023-10-19


* タイトル:SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
* 著者:Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, Robin Rombach
* 論文URL:https://arxiv.org/abs/2307.01952
* プロジェクトページ:https://ja.stability.ai/blog/sdxl10
目次
ざっくりいうと
- Stable Diffusionの改良「SDXL」の論文
- 全般的にモデルを重くし、U-Netが3倍、Text EncoderがCLIPを2つアンサンブル
- 解像度に対する条件付(Encoding)を導入し、ランダムクロップや訓練画像の解像度の低さの問題に対処
- Refinerを追加し、局所的な粗さを改良
Stable Diffusionの改善
モデル構造
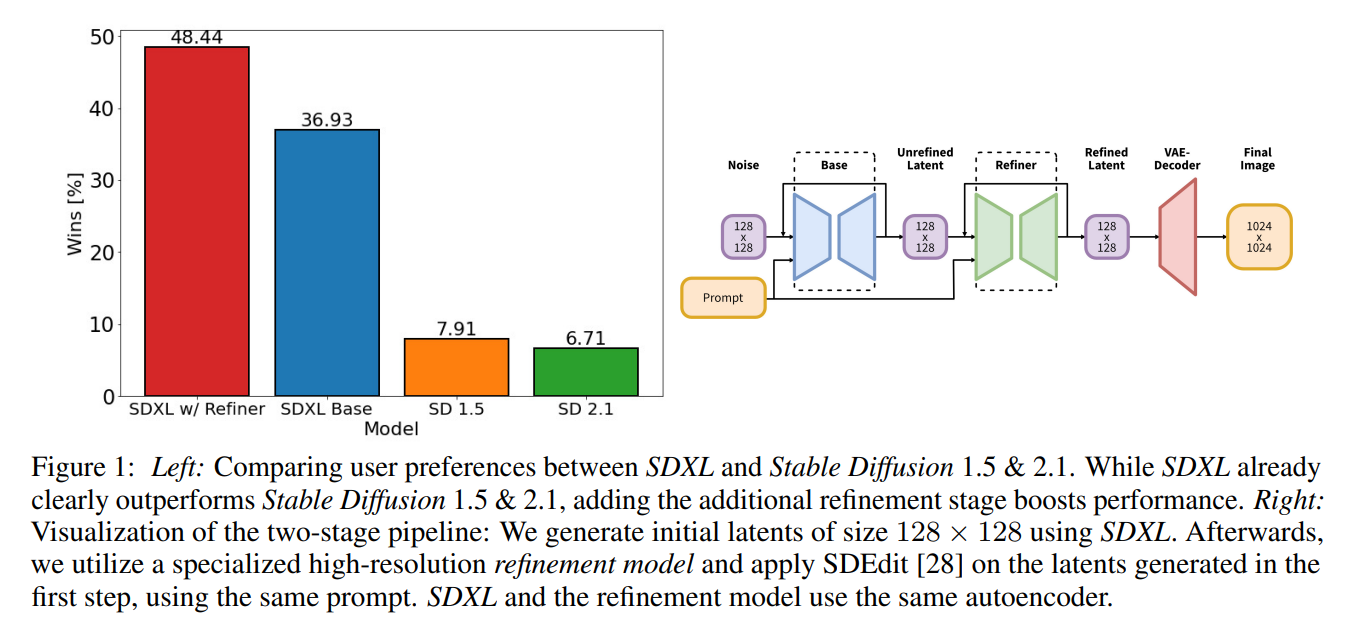
- 今まではU-Netのループ1回だったが、Refinerが入っている
- BaseとRefinerの両方に、プロンプトの条件付を入れ、Text Encoderは共通
- その結果、人力評価でSD1.5/2.1よりもユーザーベース評価で高い勝率を得た

- U-Netは確実に大きくなっている
- 私の感想:2.6BなのでLLMよりは可愛い(8GB VRAM推奨らしい)
- Text EncoderをOpenAIのCLIP ViT-Lと、OpenCLIPのViT-bigGでアンサンブルというもりもり仕様
- 私の感想:VLMだとVision Encoderは軽くする傾向があるので、ここが意外。大きくしているのに頑なに今風の言語モデルを使わない(謎)
画像サイズの条件付
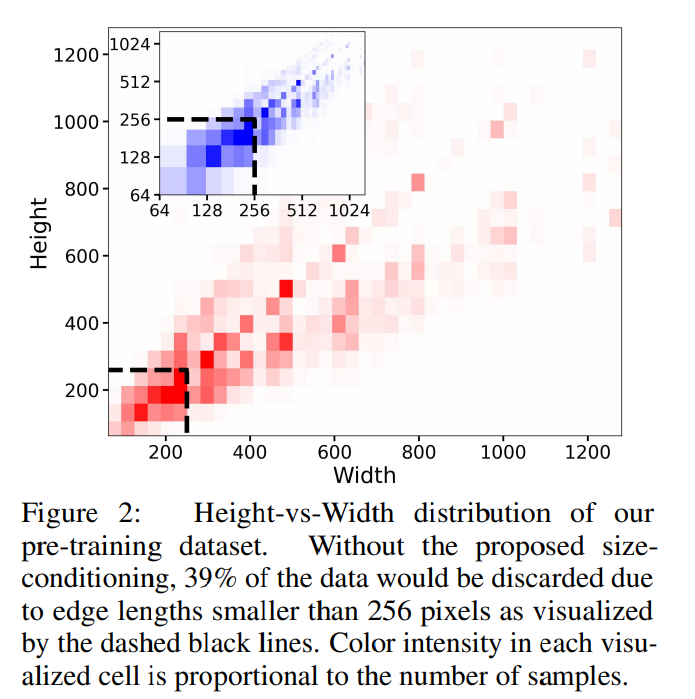
- SD1.4/1.5のように512×512で学習すると、512×512未満の学習データは破棄することになる。学習データのロスが大きい。これが性能悪化につながる
- 例:256×256で足切りすると、学習データの39%を失う
- 2段階にして1段階目の出力解像度を下げれば、学習データを有効に活用できる
- ただ、これはアップスケーリングするときに、アーティファクトが発生する
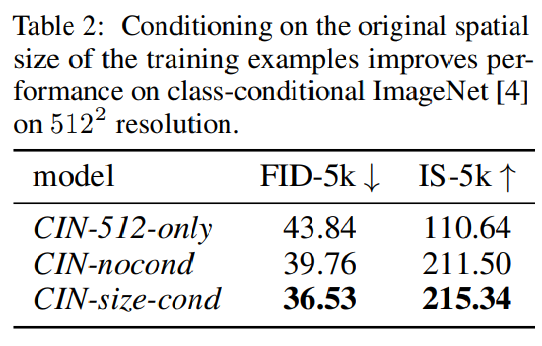
- アップスケーリングの悪影響を軽減するために、モデルに解像度(h_original, w_original)を条件として、Timestep Encoding(TransformerのPositional Encoding的なもの)として埋め込む
- 実際FIDとISを比較すると、両方効いている

クロップの改良
- Data Augmentationとして使われるRandom CropはSDでは悪影響を引き起こしている
- 例:短辺を基準にリサイズし、長辺をランダムでトリミング
- 生成されたサンプルに漏れ込み、敵対的な効果を起こす。具体的には以下の上2行

- 改良として、クロップの座標のc_top, c_leftを先程の画像サイズの条件付に使うようにした
- 推論時には、c_top=c_left=0とし、ランダムクロップの影響が出ないようにする
- 正方形の画像で学習するのはおかしい画像もある(例:風景画)ので、アスペクト比を変わるようにバケットサンプリングしている
- 私の感想:画像処理としてはそこまで新しいものではないので割愛
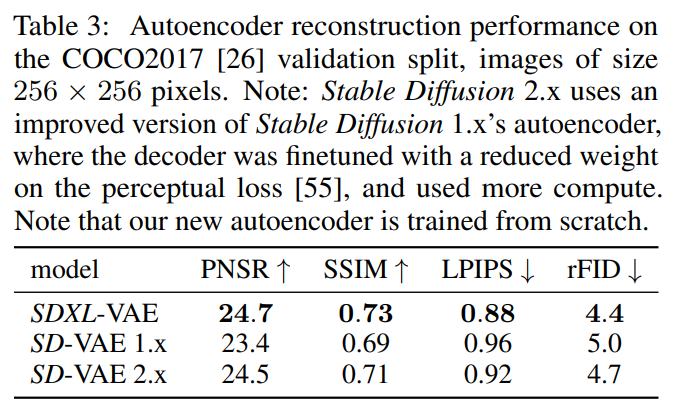
VAEの改良
- オリジナルのStable Difffusionと同じアーキテクチャのVAEを、大きなバッチサイズで学習し(256 vs 9)、係数に指数移動平均を追加
- 私の感想:このへんはBigGANでも昔からやってた発想なのでわかりやすい!
- これにより、局所的な高周波なディテールを改善
Refinerの追加
- 局所的に品質が低いサンプルを生成することがわかったので、同じ潜在空間で別のLDMを訓練する
- 私の感想:このへんはオリジナルのSDでも経験的にやられていたことなので発想はわかりやすい
- 左がRefinerなし / 右があり

今後の課題
- 単一モデル
- 2段階モデルは大きなモデルを2つメモリロードする必要があり、アクセシビリティとサンプリング速度が低下する。性能を保ちつつ単一モデルにしたい
- テキスト合成
- 大きなText Encoder(ViT-bigG)はテキストレンダリング能力を向上させるのに効いている。バイトレベルのトークナイザーを追加するか、単にサイズの大きなモデルを追加すればテキスト合成を改善できるかも
- アーキテクチャ
- UViTやDiTのようなTransformerベースのアーキテクチャを実験したが、すぐには効果がないことがわかった。ハイパラを慎重に選べば将来的にはTransformer優位になるかも?
- 私の感想:Transformer黎明期によくあった、訓練が難しいという話なのかもしれない
- UViTやDiTのようなTransformerベースのアーキテクチャを実験したが、すぐには効果がないことがわかった。ハイパラを慎重に選べば将来的にはTransformer優位になるかも?
- 蒸留:推論コストが重いので、推論計算量削減したい。蒸留しよう
SDXLの限界
- 手が相変わらず苦手(左上)
- 空間配置がむずい(右上)
- 概念の出血(右下)
- 私の感想:手はともかくCLIP使ってる限りこうなるのは明白なんじゃないの? もっとちゃんとした言語モデルだと係り受けしっかり見そう
- 概念の出血に対して論文で書かれていたこと
- テキストエンコーダーに根本的な原因がある
- すべての情報を1つのトークンに圧縮するように訓練されているため、正しい属性とオブジェクトの結合に失敗
- 単語関係を明示的にエンコードする、Contrastive Lossが研究されている
- 私の感想:VLMみたいに複数トークン使えばいいんじゃないの?

- テキスト生成能力がまだ困難
- 文字レベルのテキストトークナイザーを介してレンダリング能力を向上させる
- 私の感想:OCRモデルの工夫や事前訓練がなんか効きそうな気がする
- 文字レベルのテキストトークナイザーを介してレンダリング能力を向上させる

- 定性なので実際はどれぐらいかわからないが、定量評価が知りたいが、DeepFloyd IF(Imagen)といい勝負かそれ以上なのは「おっ」となる
- 私の感想:SD同士の定量比較はしているものの、IFとの定量評価はしてないからびみょーだったんだろうね
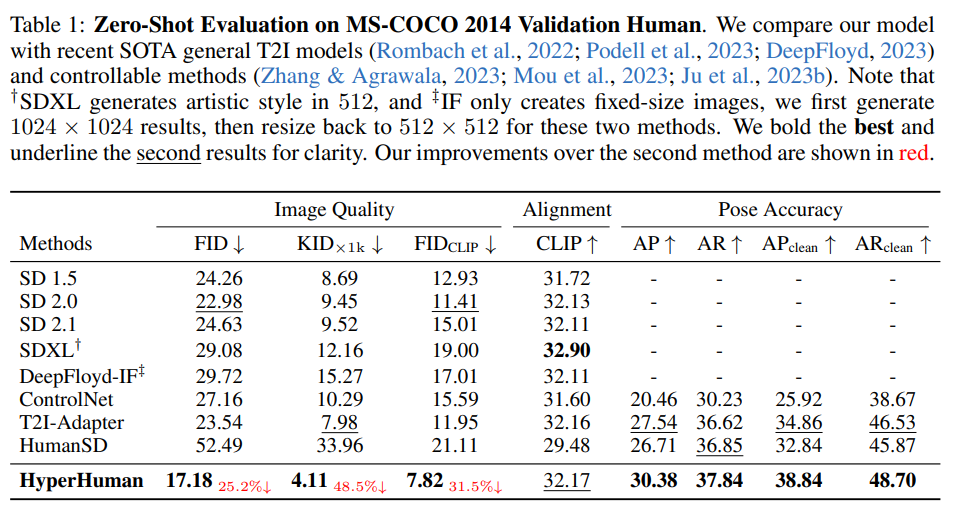
ちなみにHyperHumanという別の研究で定量評価載っていた。人間の生成限定なので注意が必要。SDXLのどのバージョン?
所感
- 私がざっくり使ってみた感じだと、SDXLはかなりいい感じになってるので、前よりかは使いやすくなってると思う
- SDはOSSとしてはとても優秀だが、研究としては現状いまいち垢抜けない
- 最近こんなのが出て、速さが売りでDiffusersで使えるが、性能はどうなんだろう?
- 相変わらずCLIPにこだわろうとするのは謎。分類で事前訓練したモデル、画像生成のようなDenseタスクで使うのはあんまり良くないというのは結構見るのに…
- VLMと比べると、まだNLP的な知見が弱く、出してくる発想がユニモーダルCVチックで古臭い。まだ開拓の余地がありそう(あまりうまくいかなかったのだろうか)
- DALL-E 3レベルがOSSになるのは何年後?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー