
論文まとめ:TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
Posted On 2023-06-29


- タイトル:TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
- 著者:Ronen Eldan, Yuanzhi Li(所属:Microsoft Research)
- 論文URL:https://arxiv.org/abs/2305.07759
目次
ざっくりいうと
- 小規模な言語モデル(10M以下)で一貫性をある文章生成を可能にした研究
- 3-4歳児が理解できる単語に絞り、GPT-3.5/4から合成されたデータセットを生成。データの多様性を保つためにサンプリングを工夫
- 小規模モデルでもスケーリング則が確認できたほか、文法、創造性、一貫性の向上の仕方、モデル構造との関係を分析
導入
- 自然言語モデルで一貫性のある生成をするには、文法や語彙の知識だけでなく、事実情報と論理的・文脈的な推論能力が必要
- 例:Jack was hungry, so he went looking for ⟨…⟩ の穴埋め
- 空腹の動機、空腹を満たせる食べ物のカテゴリを知り、状況や背景知識からもっともらしい単語を選択
- 例:Lily wanted to get either a cat or a dog. Her mother didn’t let her get a dog so instead she ⟨…⟩の穴埋め
- 推論能力が必要。リリーが犬か猫を欲しがっていて、犬がダメなら猫…
- 例:Jack was hungry, so he went looking for ⟨…⟩ の穴埋め
- 自然言語モデルは、大規模なコーパスで学習すると「要約、算術、翻訳、常識的推論」といった様々なタスクの能力を獲得
- どのようなスケールで獲得するのか、どのようなモデルアーキテクチャーか、どのようなデータ分布かは明らかではない
- これらのモデルで共通して行っているのは、一貫性のある文章生成
- 小規模な言語モデルの場合(GPT-Neo SmallやGPT-2 Small)
- 大規模なコーパスで学習すると、支離滅裂で反復的な生成をする
- 今まではこれはモデルを大きくしないとダメというのが定説だった
- 実はこれはコーパスの過剰性と多様性によるものなんじゃね?というのが本論文の着眼点
- 小型で洗練されたデータセット設計をすれば小規模の言語モデルでも一貫性のある生成ができるんじゃない?
- TinyStoriesの手法
- GPT3.5/GPT-4によって生成された、3~4歳児が通常理解できる単語のみを含む短編小説の合成データセットを作った
- SoTAより遥かに小さな言語モデル(Embeddingが256次元、パラメーターが10M以下)または、Transformerブロックが1つのモデルをTinyStoriesで訓練したら、推論や一般的な事実や知識、特定の指示に従う能力が出た
- 学習はGPU1台で1日以内に完了するが、スケーリング則、幅と深さのトレードオフなどLLMで観測される性質が観測された
- モデルのニューロン数や層の数が少ない場合、アテンションヘッドはローカルヘッドとセマンティックヘッドが明確に分離される。これを分析した

上が1.5BのパラメーターのGPT2-XL / 下がTinyStoriesデータセットで訓練された28Mのモデル
TinyStoriesの特徴
- 3~4歳児の語彙を模倣するため、名詞、動詞、形容詞の約1500の基本単語からなる語彙を収集
- 3つの単語がランダムに選ぶ(動詞、名詞、形容詞が1つずつ)
- ランダムな単語を組み合わせてストーリーを生成するように指示
- ストーリーが持ちうる特徴(セリフ、ひねり、バッドエンド、道徳的価値など)のリストを作成
- 各ストーリーについて、これらの特徴のランダムなサブセットを生成し、ストーリーがこれらの特徴を持つという追加要件をモデルに追加

TinyStories Instruct
Instruction用のデータセットを作成

Word以外はGPT3.5で作成
GPT-4での生成結果の評価
- 訓練したLLMに生成させた部分が黄色
- それをCoTを使い、「文法」「創造性」「一貫性」「年齢層」の4カテゴリで評価

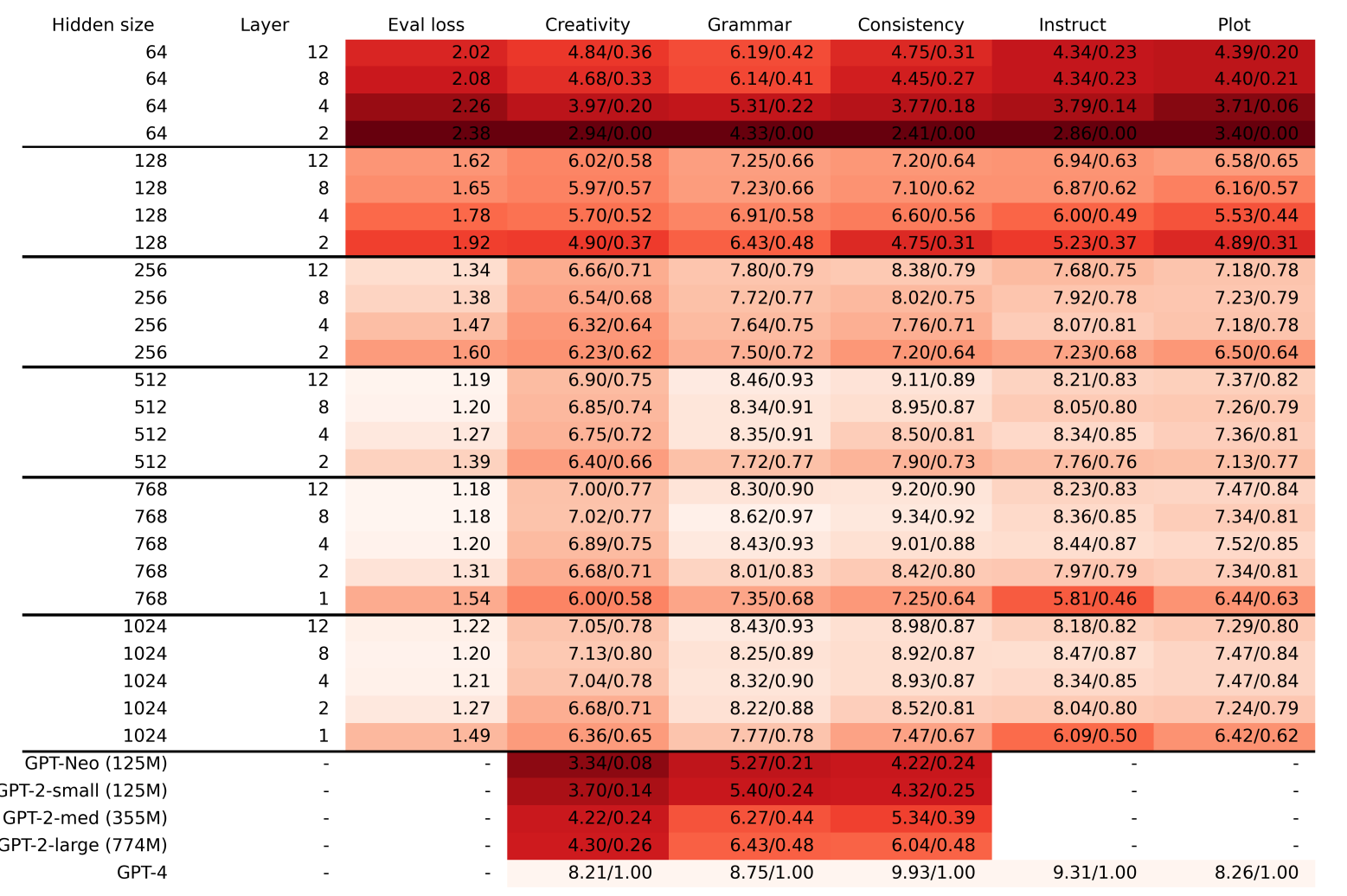
GPTの評価を評価関数として、損失関数と比較する。横軸は訓練ステップ。ロスときれいに連動している。nlはレイヤー数
- モデルを深くすることは、文法の正しさや一貫性を保証するためにも重要
- 文法は小さなモデルでも身につくが、一貫性や創造性は大きなモデルになって初めて生まれるもの
- 隠れ層のサイズを64→128にすると、一貫性スコアが急速に向上
- TinyStoriesの最大モデル(80Mparam)は、文法や一貫性はサチっているが、創造性はGPT-4に及ばない
- 創造性はデータセットの肥大化により大幅に改善され続けることの示唆
- Instructに従うには、レイヤー数を増やすのが大事(レイヤー数が2だと苦戦)
- GlobalなAttentionが必要だから
出力結果の定性評価
- 埋め込み次元=単語の意味や関係を捉える上で重要、層の数=長距離依存関係を捉える上で重要
- レイヤー数が1のモデル:一貫性は得られないが、いくつかの事実は正しく得られる
- 埋め込み次元が64のモデル:事実は正しくないが、いくつかの一貫性を維持することは成功
- 詳細は論文中の図9~11を参照。成功(緑)、失敗(赤)、部分的成功(黄)
多様性の定量評価
Rouge score:n-gramの重なりを用いてストーリーの多様性を定量評価

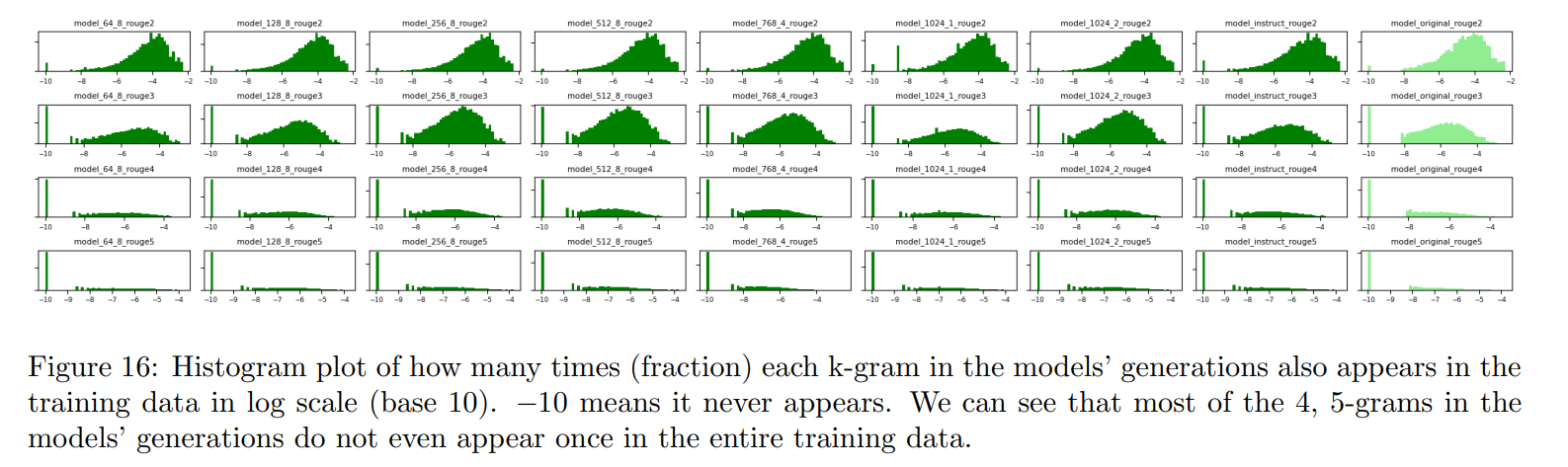
訓練データに対するRouge score。-10は決して現れないことを意味。4-5gramだと訓練データにほとんど現れない。近い部分でもデータセットからかなり遠い
→ 斬新で多様なストーリーを生成していることの証拠と主張。テンプレートマッチングを行っている可能性は完全には排除できなく、この評価の限界
Attentionヘッドの分析
- 1層からなるモデルを作った
- 主にトークン間の距離に基づくAttentionパターンを持つヘッドと、意味的な意味により強く依存するAttentionパターンを持つヘッドの間で、明確に分離されることが観察された
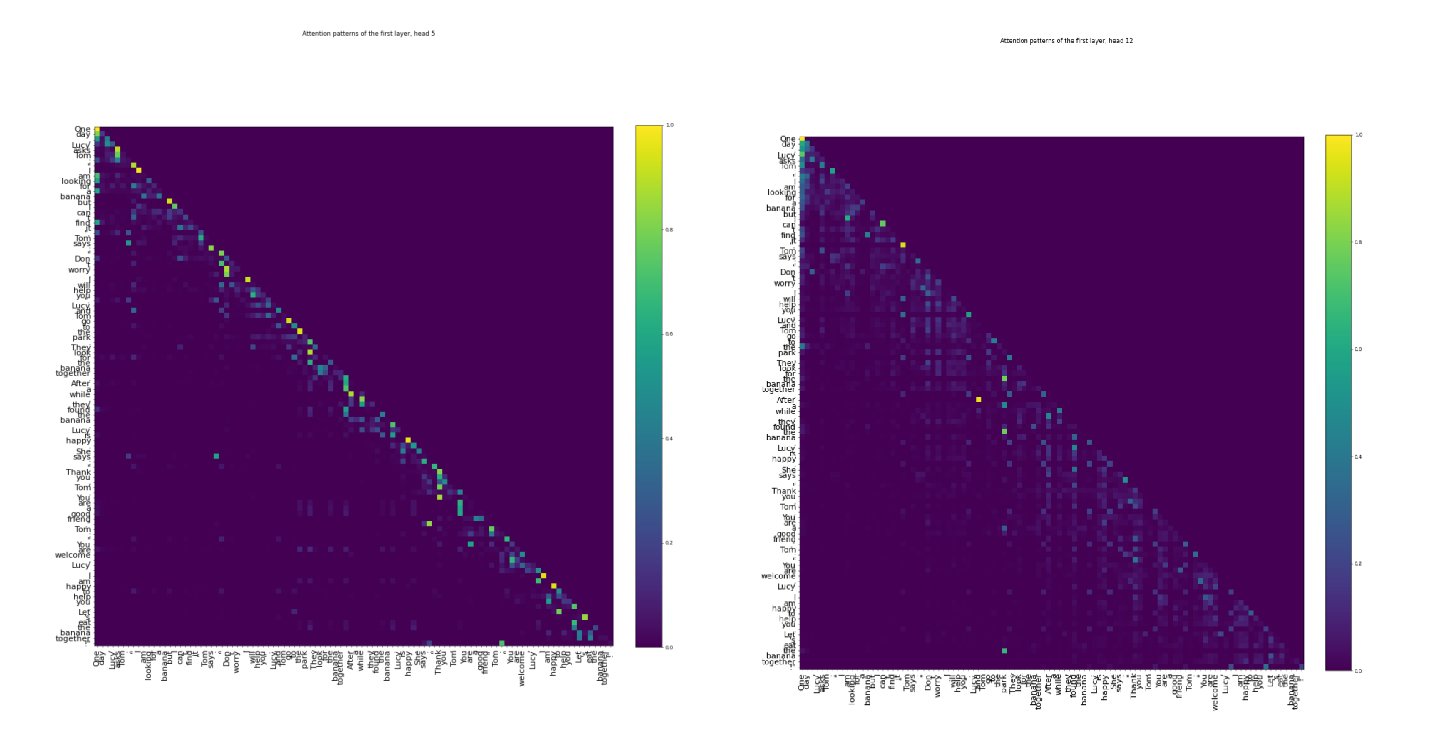
左が距離ベースのヘッド、右が意味ベースのヘッド
ニューロンの役割
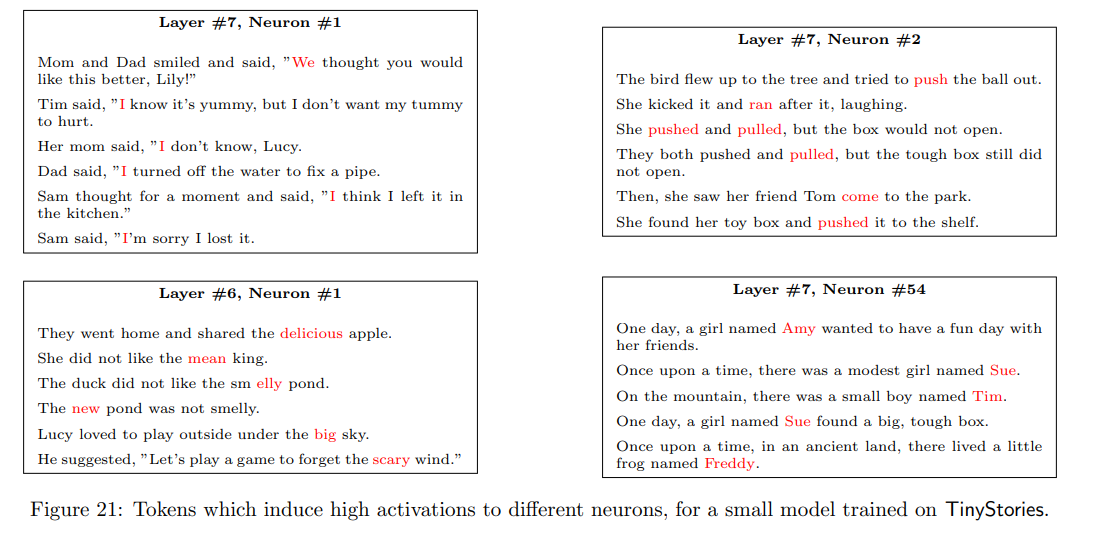
TinyStoriesで訓練されたモデルのニューロンを分解したところ、名前や動詞、形容詞に着目するニューロンがそれぞれ確認された

TinyStoriesで訓練されていないGPT-XLの場合、ニューロンごとの役割は明確ではなかった
→ 所感:層が違うからちゃんとした比較ではない気がする
結論
- 小さな言語モデルでも、コーパスを絞れば首尾一貫した文章生成ができた
- LLMで報告されているようなスケーリング則が、小さな言語モデルでも確認できた
- 層の深さと埋め込み次元の関係が明らかになった。埋め込み次元は単語の意味や関係性を捉えるのに効き、層の深さは長期依存関係に効く
- 性能の向上のしやすさは、文法>一貫性>創造性
所感
- BERT並かそれ未満のパラメーター数で、一貫性のある生成ができるようになったのがやばい!
- 今までずっとモデルサイズを大きくする方向だったが、小さくする方向に進化するのではないか
- 「多様性を保ちつつコーパスを絞る」という考え方が重要になりそう
- ニューロンの注目の部分は、画像生成の「特定のプロンプトが無視される」現象にも似ている気がするから、研究的に輸入されるかも?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー