
pandasでグループ別に統計量やヒストグラムを表示する方法
Posted On 2018-07-03

初投稿です。この記事では、pandasでグループ別に基本統計量(describe)をする方法を紹介します。

目次
テストデータ
以下のようなデータを想定します。ある学校の3つのクラスでテストをしてみました。
- A組は40人、平均点は60点、標準偏差は10(分布は正規分布に従うものとする)
- B組は30人、平均点は50点、標準偏差は20
- C組は20人、平均点は65点、標準偏差は5
このとき、「組別の得点の基本統計量」を表示する方法を考えます。また、このテストの赤点40点で、40点以上なら及第(1)、40点未満なら落第(0)とするパラメーターを導入します。つまり次のようなデータになります(スペースの関係上省略して書いています)。
| student | class | score | passed |
|---|---|---|---|
| 1 | A | 70 | 1 |
| 2 | A | 50 | 1 |
| 3 | B | 55 | 1 |
| 4 | B | 30 | 0 |
| 5 | C | 60 | 1 |
Pythonのコードでは次のようになります。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
student_a, student_b, student_c = 40, 30, 20
# クラス
data_classes = np.r_[np.repeat("A", student_a), np.repeat("B", student_b), np.repeat("C", student_c)]
# 得点
np.random.seed(45)
data_scores = np.r_[np.random.randn(student_a)*10+60,
np.random.randn(student_b)*20+50,
np.random.randn(student_c)*5+65]
data_scores = np.round(data_scores, decimals=1)
# PandasのDataFrameにする、40点以上は及第(1)
df_test = pd.DataFrame({"class":data_classes, "score":data_scores, "passed":(data_scores>=40).astype(int)})
グルーピングして基本統計量を表示
以下のコードでOKです。カラム(class, score, passed)が2個ならfilterは不要です。上は得点(score)の基本統計量、下は及第(passed)の基本統計量となります。
# 組別の点数の統計量(カラムが2個ならfilterなしでOK)
score_stat = df_test.filter(items=["class", "score"]).groupby("class").describe()
print(score_stat)
# 組別の及第の統計量
passed_stat = df_test.filter(items=["class", "passed"]).groupby("class").describe()
print(passed_stat)
出力は以下の通りです。
score
count mean std min 25% 50% 75% max
class
A 40.0 57.320000 9.948101 34.0 51.150 56.50 63.000 82.5
B 30.0 47.853333 15.559047 18.2 36.675 49.05 55.200 85.3
C 20.0 66.165000 4.734673 55.6 63.800 64.70 69.925 74.1
passed
count mean std min 25% 50% 75% max
class
A 40.0 0.975000 0.158114 0.0 1.0 1.0 1.0 1.0
B 30.0 0.666667 0.479463 0.0 0.0 1.0 1.0 1.0
C 20.0 1.000000 0.000000 1.0 1.0 1.0 1.0 1.0
describe()は中央値、平均値、クォンタイル値が一目瞭然なのでとても便利な関数です。この例ではB組が1/3落第しているのに対して、C組は全員合格しているのがわかります。
グルーピングしてヒストグラム
組別の得点のヒストグラムは以下のようにします。columnを省略すると、scoreとpassedが同一のグラフに表示されて見づらくなるので注意が必要です。
# 組別の点数のヒストグラム
df_test.hist(column="score", by="class", range=(0,100))
plt.show()
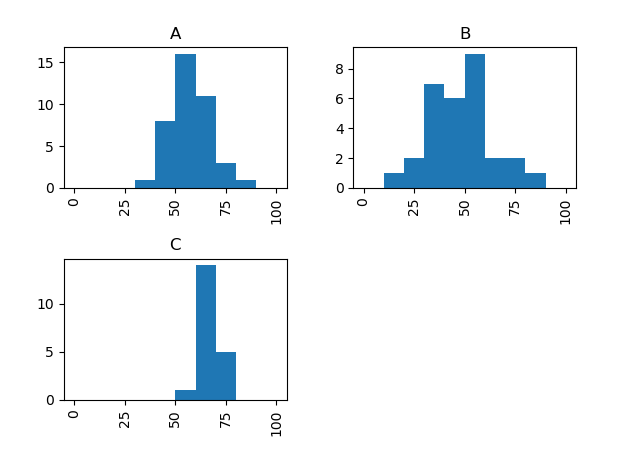
とても簡単でしたね。pandasは集計にとても便利なので、ぜひ活用してくださいね。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー