
Amazon Athenaを試す
Posted On 2024-12-11


S3に保存されたデータをSQLで集計できるAmazon Athenaを試してみました。データの整形からAthenaの設定、テーブル作成、クエリの実行、そして後片付けまでの手順をまとめています。
目次
はじめに
S3のデータからSQLを叩けるAthenaをちゃんと試したことなかったので試してみた。
データ整形
- 以下にあるJSONフォーマットのサンプルデータを、1日単位で分割S3にアップロードし、Athenaで集計する
- 分割するのはデータ収集時の想定で、1日単位で元の生データを集計するバッチを走らせて(疑似ETL)S3にJSONデータを保存する仕組み
OpenSearchとOpenSearch Dashboardsによるダッシュボード作成(ローカルDocker)
- Athenaの取り込み時はJSONLのほうが都合がいいようで、以下のようにフラットニングした行単位のJSONに置き換える
- これを例えば
2024-11-01.jsonとし、日数分用意する。
{"date": "2024-11-01", "productId": "P001", "productName": "コーヒーメーカー", "unitsSold": 20}
{"date": "2024-11-01", "productId": "P002", "productName": "ノートパソコン", "unitsSold": 49}
{"date": "2024-11-01", "productId": "P003", "productName": "Bluetoothスピーカー", "unitsSold": 20}
{"date": "2024-11-01", "productId": "P004", "productName": "スマートウォッチ", "unitsSold": 27}
{"date": "2024-11-01", "productId": "P005", "productName": "エアフライヤー", "unitsSold": 87}
{"date": "2024-11-01", "productId": "P006", "productName": "タブレット端末", "unitsSold": 34}
{"date": "2024-11-01", "productId": "P007", "productName": "LEDデスクランプ", "unitsSold": 46}
{"date": "2024-11-01", "productId": "P008", "productName": "ワイヤレスイヤホン", "unitsSold": 52}
{"date": "2024-11-01", "productId": "P009", "productName": "デジタルカメラ", "unitsSold": 70}
{"date": "2024-11-01", "productId": "P010", "productName": "電動歯ブラシ", "unitsSold": 66}
こちらの記事で作成した元データをsales_data_november_2024.jsonとしたときの変換プロセスは以下のコードからなる。
import json
import os
# 入力JSONファイルのパス
input_file = "sales_data_november_2024.json"
# JSONデータをファイルからロード
with open(input_file, "r", encoding="utf-8") as file:
input_data = json.load(file)
# 出力ディレクトリの設定
output_dir = "flattened_sales_data_by_date"
os.makedirs(output_dir, exist_ok=True)
# JSONデータをフラット化して日付単位で書き出し
for entry in input_data["salesData"]:
date = entry["date"]
output_file = os.path.join(output_dir, f"{date}.json")
with open(output_file, "w", encoding="utf-8") as file:
for product in entry["products"]:
flat_record = {
"date": date,
"productId": product["productId"],
"productName": product["productName"],
"unitsSold": product["unitsSold"]
}
file.write(json.dumps(flat_record, ensure_ascii=False) + "\n")
print(f"データがフラット化され、日付ごとに '{output_dir}' ディレクトリに保存されました。")
S3にアップロード
作成された日数分のJSONファイルをs3://sample-salesdata-athena-bucket/raw_data/にアップロード。
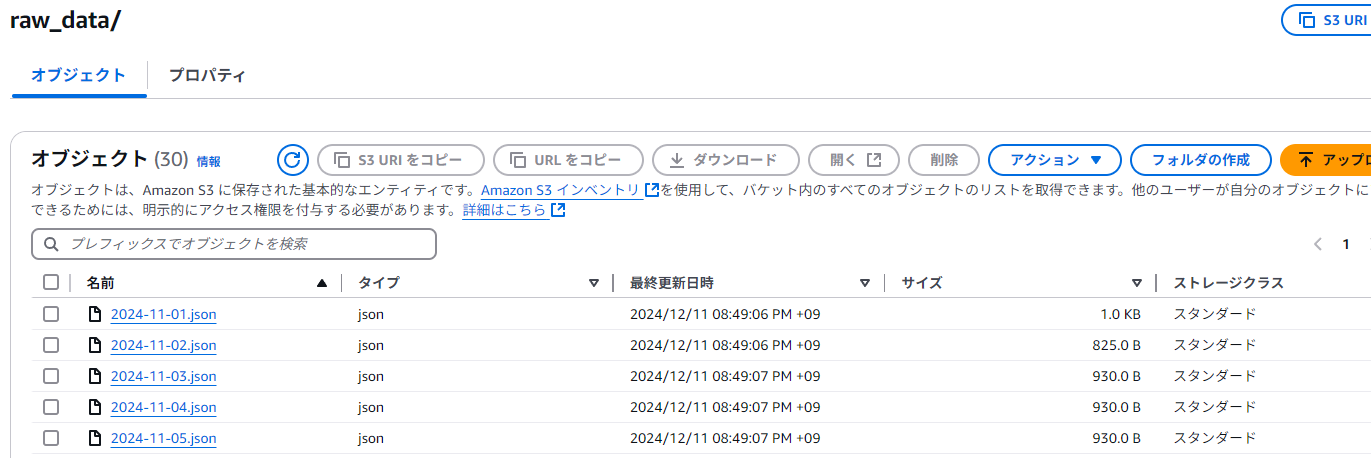
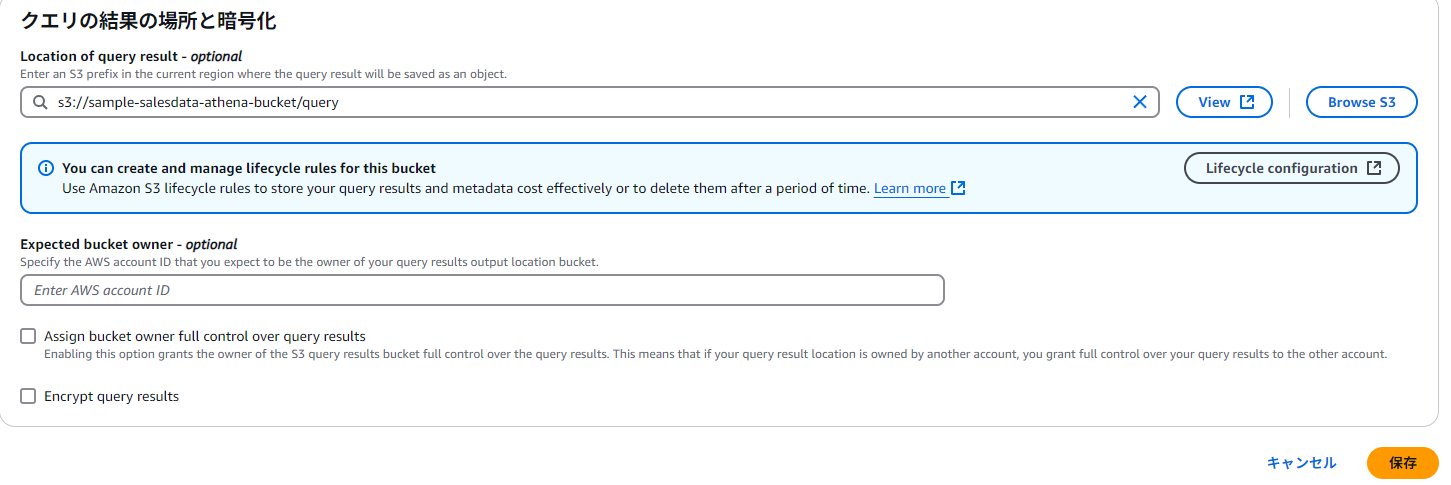
Athenaの設定
最初にクエリのキャッシュのためのS3バケットの設定が必要。後で変更可能。ここではs3://sample-salesdata-athena-bucket/query/とする。
データテーブルの作成
クエリエディタから以下を入力。テーブルが作成される。
CREATE EXTERNAL TABLE IF NOT EXISTS sales_data (
date string,
productId string,
productName string,
unitsSold int
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://sample-salesdata-athena-bucket/raw_data/'

商品単位で集計
商品単位の日次売上推移、累計売上を集計する。GPTの作ったクエリなのでベストではないかもしれないが、これでも機能する。
SELECT
date,
productId,
productName,
SUM(unitsSold) AS units_sold_per_day,
SUM(SUM(unitsSold)) OVER (PARTITION BY productId ORDER BY date) AS cumulative_units_sold
FROM
sales_data
GROUP BY
date,
productId,
productName
ORDER BY
productId,
date;

お片付け
テーブルを選択し、「管理」→「テーブルを削除」すると、テーブルを削除するためのクエリが実行される。
DROP TABLE `sales_data`;
最初に設定したクエリの格納場所も、空欄にするとクエリの保存場所をリセットできる。必要に応じてS3バケットを削除する。
これでなんとなくAthenaの使い方がわかった。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー