
CIFAR-10/100のバイナリを画像ファイルに書き出す方法


CIFAR-10/100は画像分類として頻繁に用いられるデータセットですが、たまに画像ファイルでほしいことがあります。配布ページにはNumpy配列をPickleで固めたものがあり、画像ファイルとしては配布されていないので個々のファイルに書き出す方法を解説していきます。
コード
まずは配布ページから、CIFAR-10の場合は「CIFAR-10 Python Version」、CIFAR-100の場合は「CIFAR-100 Python Version」をダウンロードし、tar.gzアーカイブを解凍します。以下CIFAR-100の場合で解説しますが、アーカイブは「cifar-100-python」のフォルダに解凍されているものとします。
次に書き出し先のフォルダを作ります。これを「cifar100-raw」とします。この中に訓練データとテストデータの2つのフォルダ「cifar100-raw/train」と「cifar100-raw/test」を作っておきます。この2つはPythonでコードを書いて作ってもいいです。
import pickle, os
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
with open("cifar-100-python/train", "rb") as fp:
train = pickle.load(fp, encoding="latin-1")
with open("cifar-100-python/test", "rb") as fp:
test = pickle.load(fp, encoding="latin-1")
def parse_pickle(rawdata, rootdir):
for i in range(100):
dir = rootdir + "/" + f"{i:02d}"
if not os.path.exists(dir):
os.mkdir(dir)
m = len(rawdata["filenames"])
for i in range(m):
if i % 100 == 0:
print(i)
filename = rawdata["filenames"][i]
label = rawdata["fine_labels"][i]
data = rawdata["data"][i]
data = data.reshape(3, 32, 32)
data = np.swapaxes(data, 0, 2)
data = np.swapaxes(data, 0, 1)
with Image.fromarray(data) as img:
img.save(f"{rootdir}/{label:02d}/{filename}")
parse_pickle(train, "cifar100-raw/train")
parse_pickle(test, "cifar100-raw/test")
順に追って解説していきます。まずはPickleを解凍します。中は辞書(dictionary)形式で記録されており、Python3環境ではPickleの読み込み時にUnicodeErrorが出てしまうので対策に「encoding=”latin-1″」と指定します。
次にparse_pick関数の中身ですが、まずは分類ラベルごとに画像をまとめたフォルダを、train, testの直下にそれぞれ作ります。CIFAR-100の場合はクラスが100あるので100個、CIFAR=10の場合は10個作ります。
ちなみに、pickleの辞書のキーは
dict_keys(['filenames', 'batch_label', 'fine_labels', 'coarse_labels', 'data'])
という5項目からなります。filenamesは拡張子(.png)を含んだ元ファイルの名前を示します。batch_labelは1万個のバッチの中のどれに位置するかですが、これはあまり意味がないので気にしなくていいです。fine_labels, coarse_labelsはCIFAR-100専用の項目で、それぞれ小分類、大分類を示します。CUFIR-10の場合は大小の分類がないので、labelsに分類クラスが直接入っています。dataはnumpy配列で、最初の1024エントリーが赤チャンネル、次の1024エントリーが緑チャンネル、最後の1024チャンネルが青チャンネルとなります。各1024エントリーは行が最初になっています。
さてreshapeの部分ですが、Numpy行列→画像に変換するには「y, x, ch」の形式の配列(テンソル)に変換します。CIFARのオリジナルの形式だとチャンネルの軸が先になっているので、「np.reshape(3, 32, 32)」で適切な形に変形したのち、np.swapaxesで0番目と2番目の軸を入れ替えます。次にyを先に出すために同様に0番目と1番目の軸も入れ替えます。これをしないと横に90度反転して画像が出てきます。
あとはim.saveで記録すればOKですね。結果はこのようになります。
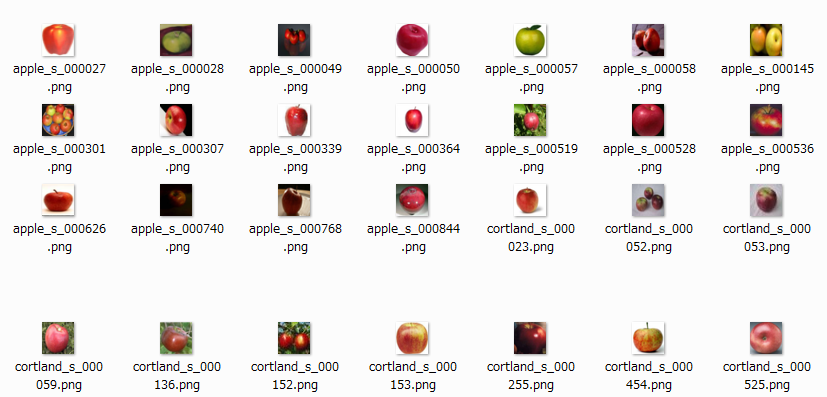
以上です。数分で展開が終わるはずです。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー