
論文まとめ:ControlVideo: Training-free Controllable Text-to-Video Generation
Posted On 2023-05-25


- タイトル:ControlVideo: Training-free Controllable Text-to-Video Generation
- 著者:Yabo Zhang, Yuxiang Wei, Dongsheng Jiang, Xiaopeng Zhang, Wangmeng Zuo, Qi Tian(ハルビン工業大学、Huawei Cloud)
- 論文URL:https://arxiv.org/abs/2305.13077
- コード:https://github.com/YBYBZhang/ControlVideo
目次
ざっくりいうと
- ControNetの動画版で、Depthやエッジなどの動画を条件としてプロンプトから生成する研究
- 各フレームのLatentを結合してAttentionをとる「Fully Cross-Frame Attention」や、サンプラー内での平滑化、動画クリップごとの階層的なAttentionを導入
- ちらつきや外観不一致の問題を軽減し、2080Tiが1枚でも100フレーム程度の動画生成が可能
概要
- Text-Drivenの画像生成は、静止画ではうまくいっているが、動画生成ではまだ遅れをとっている
- 時間的モデリングを考える必要があり、過剰な学習コストがかかる
- 特に長時間の動画合成で、外観不一致や構造のちらつきがある
- ControlVideo:入力列の粗い構造一貫性を活用して一貫性を上げるために3つのモジュールを導入(Video2Videoの文脈)
- フレーム間の一貫性を確保したい:Self Attentionをフレーム間で適用(Fully cross-frame interaction)
- フリッカー効果(ちらつき)を軽減したい:サンプラーを改良して、交互に配置されたフレームを補間する(Interleaved-frame smoother)
- 長い動画を効率的に作成したい:全体的な一貫性を持って短い動画クリップを別々に合成する階層的サンプラーを利用(Hierarchical sampler)
- ControlNetと同様に、推論時に追加訓練は不要
- 2080Tiを1個で512×512の100フレームの動画を作れる!←すごい
- 他にxFormersを利用
- 動画なのに、Imagenベースの静止画DeepFloyd IFよりも要求スペックが少ない
先行研究
- Tune-A-Video
- Fate/Zero
- Text2Video-Zero
- FollowYourPose
サービスやツールレベルも含めると
- Gen-2
- Stable Animation SDK
手法
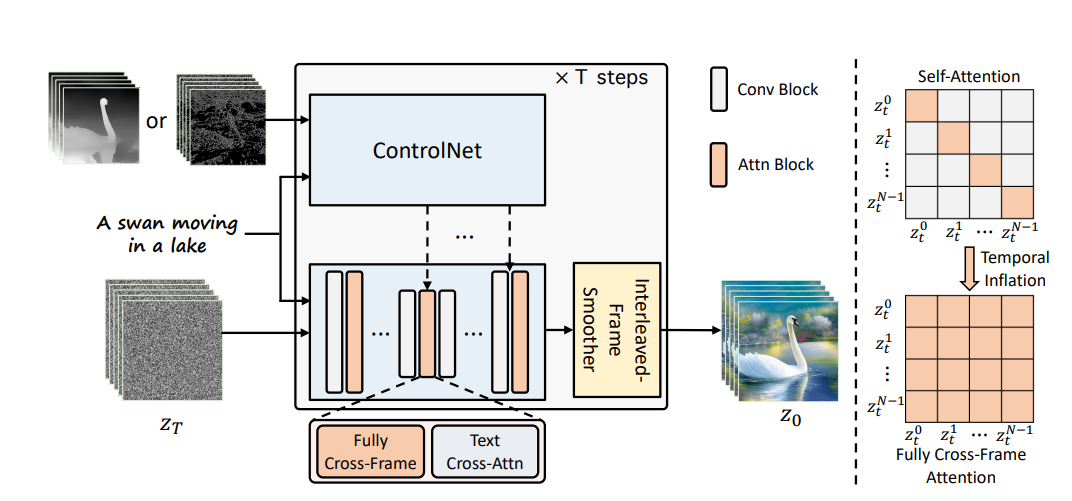
Fully cross-frame interaction

- 同じ初期ノイズを使用しても、すべてのフレームをControlNetで個別に生成すると、外観に大きな矛盾が生じる
- すべてのフレームを連結して「大きな画像」とし、フレーム間の相互作用を共有することで、映像の見た目の一貫性を保つ
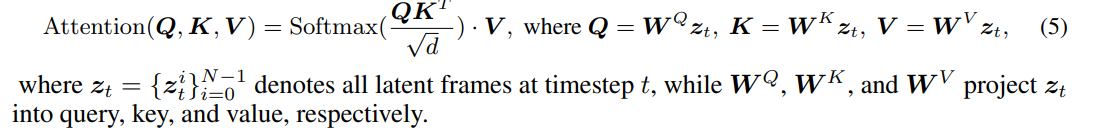
z_tはフレームごとのLatentを結合したもの
- 計算を効率化することで、短いビデオ生成(<16フレーム)なら、メモリも計算負荷も許容範囲
Interleaved-frame smoother
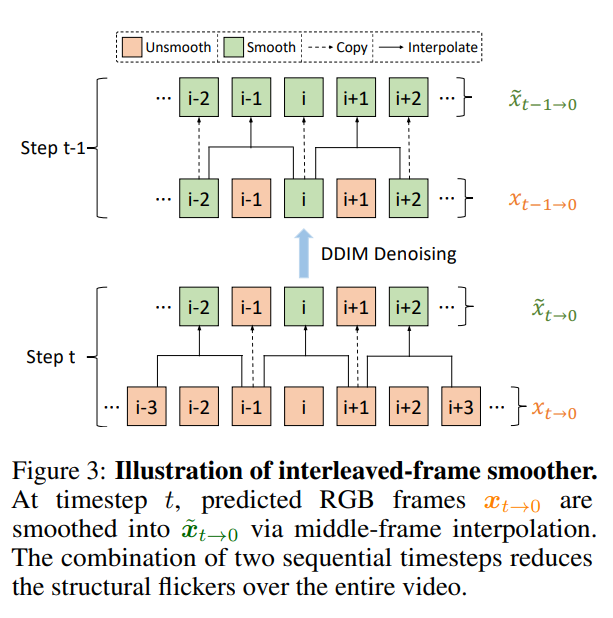
DenoiseとSmoothを交互に行う
Hierarchical sampler
- 長時間の動画を複数の動画クリップに分割(N個)
- 各動画クリップについて、キーフレームを決める
- 動画クリップ間では、キーフレーム同士のAttentionをとる
- 動画クリップ内では、そのクリップに属するフレーム同士のAttentionをとる

結果
実験設定
- 解像度は512×512
- xFormersを使用
- サンプラーはDDIMで50syテップ
- 2080Tiが1台で、短時間の動画は2分、長時間の動画は10分で作成可能
データセット
- DAVISデータセットから25のオブジェクトを中心にビデオを収集し、キャプションを手動作成
- それらに対して編集キャプション5個をChatGPTで作成
- 125個のビデオ-プロンプトのペアを作成
評価指標
- CLIPを採用し、以下の2点から生成映像を評価
- (i) Frame Consistency:連続するフレームの全ペア間の平均コサイン類似度
- (ii) Prompt Consistency:入力プロンプトと全ビデオフレーム間の平均コサイン類似度
結果
人間による定性評価

定量評価
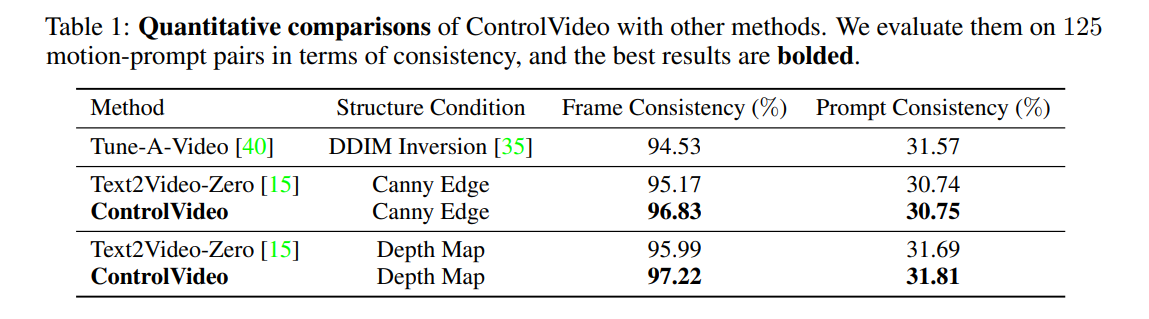
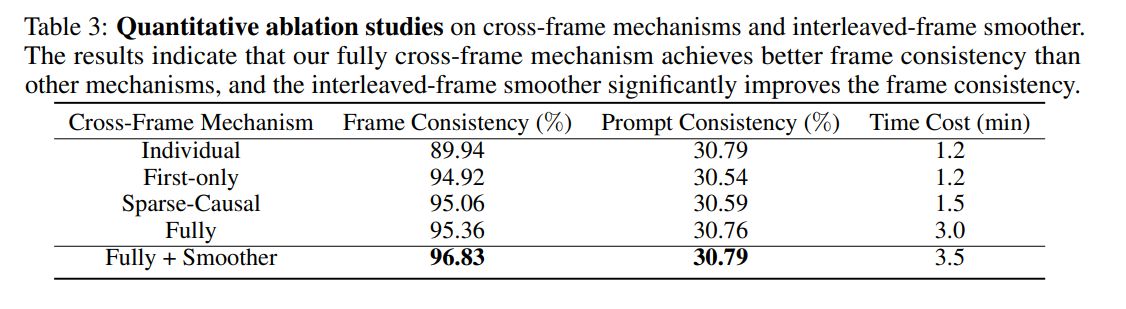
評価指標が楽ちんなのがいい
Cross-Frame Mechanismの意味
- Individual:フレーム間で独立
- First-Only:最初のフレームのみ注目
- Sparse-Causal:それぞれのフレームが最初と、直前のフレームに注目
- Fully:本手法
- Fully+Smoother : さらに本手法のinterleaved-frame smootherを追加したもの
限界
- 入力モーションシーケンスを超えるビデオを生成することにまだ苦労
- マイケル・ジャクソンのムーンウォークのような連続したポーズが与えられた場合、Iron man runs on the streetのようなテキストプロンプトに従って鮮やかな動画を生成することは困難
所感
- Attentionの工夫がかなり頭いい
- 3DCNNの計算量の暴力で動画生成するのかなり頭悪いなと思っていたが、Attentionの工夫でできるのはすごい
- サンプラー側に工夫いれるのはかなり大きなブレイクスルーな気がする
- キーフレームを使った考え方は動画認識でも見るから、そこをAttentionと繋げているのがなるほど感
- ControlNetのReferece Onlyもそうだが、Attentionハッキングが画像生成のキモでは?感
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー