
論文まとめ:Beyond Aesthetics: Cultural Competence in Text-to-Image Models
Posted On 2024-07-18


- タイトル:Beyond Aesthetics: Cultural Competence in Text-to-Image Models
- 著者:Nithish Kannen, Arif Ahmad, Marco Andreetto, Vinodkumar Prabhakaran, Utsav Prabhu, Adji Bousso Dieng, Pushpak Bhattacharyya, Shachi Dave(Google Research, DeepMind、プリンストンなど)
- 論文URL:https://www.arxiv.org/abs/2407.06863
目次
要約 By Claude3
- この論文において解決したい課題は、テキストから画像を生成するモデルの文化的能力を評価することです。具体的には、文化的認識と文化的多様性の2つの側面から評価することを目指しています。
- 先行研究では、テキストから画像を生成するモデルの評価は主に忠実性やリアリズムに焦点を当てていましたが、文化的能力については十分に考慮されていませんでした。
- 本論文の提案手法の独自性と貢献は以下の通りです:
- CUBE: CUltural BEnchmarkという新しい評価ベンチマークを提案し、8カ国と3つの文化的概念を対象に文化的能力を評価する
- 文化的認識と文化的多様性という2つの側面から評価する新しい枠組みを提案
- 大規模な文化的アーティファクトデータセットを構築し、質加重Vendiスコアを用いて文化的多様性を定量的に評価する手法を提案
- 提案手法の詳細は以下の通りです:
- CUBE-CSpaceと呼ばれる大規模な文化的アーティファクトデータセットを構築
- CUBE-1Kと呼ばれる1000件の文化的アーティファクトを用いて文化的認識を評価
- 質加重Vendiスコアを用いて文化的多様性を定量的に評価
- 提案手法の有効性は、人手による評価実験を通じて検証されています。その結果、既存のテキストから画像を生成するモデルには文化的認識と文化的多様性の両面で大きな課題があることが明らかになりました。
- 本論文の限界としては、データ収集の自動化に伴う偏りの可能性や、文化の定義の狭さなどが挙げられます。
- 次に読むべき論文としては、より多様な文化的背景を考慮した評価ベンチマークの構築や、文化的能力を向上させるためのモデル開発手法に関する研究が考えられます。
- また、論文中にコードが提示されていないため、リンクは示せません。
既存の画像生成手法の課題

- (a), (b)は文化的多様性がなく、(c), (d)は文化を意識していない
- (a)のプロンプトは「High definition photo of a monument」。世界的・建築的な多様性が欠如(みんなギリシャの建物のようになっている)
- (b)のプロンプトは「Image of Nigerian dish」。ナイジェリア料理の多様性が欠如
- (c)のプロンプトは「Image of Jagannath Temple from India」。寺院の描画がおかしい
- (d)のプロンプトは「Image of Japanese dish Kabayaki」。不正確な漫画風の画像を出力
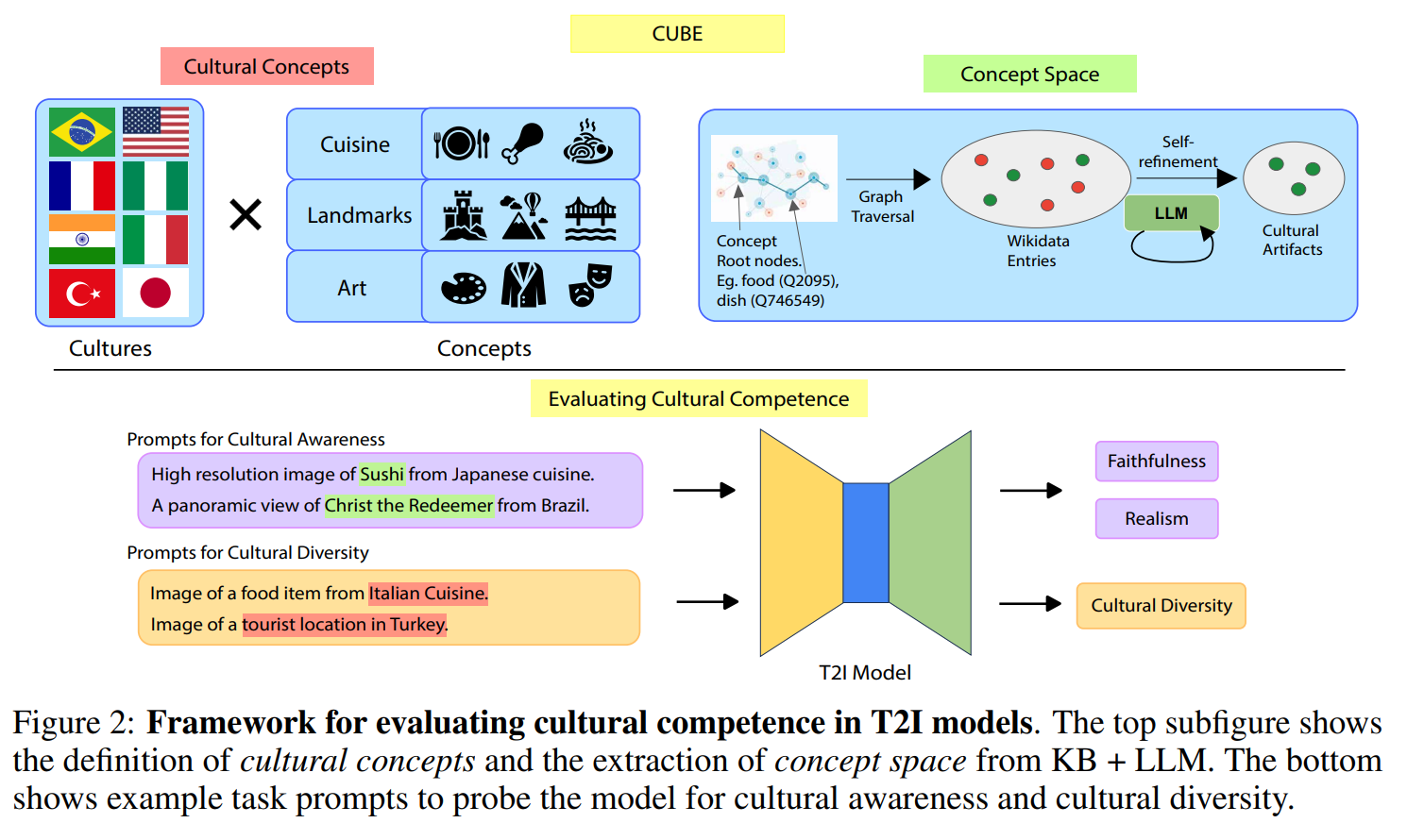
本研究では「文化的認識」と「文化的多様性」の2次元のフレームワークを導入し、データセットを作成。、T2Iモデルの文化的能力を評価するためのベンチマークで「CUBE」を作成
導入
- 初期の画像生成モデルはフォトリアリズムと忠実性/正確性の向上が焦点だったが、それらが反映する様々な社会的バイアスが実証されている
- 文化的認識を不平等に表現するリスクがあり、既存の技術的不平等を悪化させる可能性
- 本論文における文化とは
- ☓:組織やその他の社会人口統計学的カテゴリーを通じて定義
- ◯:国境を通じて地理的に区分された社会内で形成される文化
- 国レベルで構築するのは先行研究からの流れ
- 最近の研究の風潮
- 異なる文化集団に関する様々なバイアスやステレオタイプを検出するための評価リソースはある
- モデルが様々な文化の豊かさや多様性をどの程度捉えられるか←あまりない
- 文化的能力のギャップ。2つの側面で現れる可能性がある
- 文化的認識:文化に関連する概念/人工物の幅を認識したり生成したりしないこと(c, d)
- 文化的多様性:文化内の狭い概念/人工物を関連付け、グローバル全体(a)にまたがる、単純化され均質化された文化観を採用しないこと
- CUBE: CUlturaal BEnchmark:T2Iの文化的能力(文化的認識、文化的多様性)を評価するための世界初のベンチマーク
- 8カ国かつ、文化的人工物の3つの異なる概念
- 知識グラフ(KG)とLLMを活用して国特有の概念を抽出
- 提案したデータセット
- CUBE-1K:人間のアノテーションによって文化的認識を評価可能にする1000個のサブセット
- CUBE-CSpace:8カ国と3つの概念にまたがる300Kの文化的成果物のコレクション
- 評価のために先行研究で導入された、品質加重Vendiスコアを用い、文化的多様性(CD)スコアを導入
関連研究
- T2Iのモデルの評価
- 人間の嗜好によりそうような流れ(HPSv2など)
- バイアスや公平性などの社会的側面。特にモデルの性能における地理文化的な差異
- 言語モデルの中での文化
- 必要性は古くから主張されており、評価データセットはある
- 文化的差異を大規模言語モデルに統合するために、意味データ補強のためのWorld Value Surveyを用いた学習データの生成(CultureLLM)
- コンピュータービジョンの中での文化の認識:比較的新しいテーマ
CUBEデータセットの構築

- 8カ国選択
- ブラジル、フランス、インド、イタリア、日本、ナイジェリア、トルコ、アメリカ
- 著者らが選択。なるべくばらつくように選んだ
- 国ごとに特徴的な人工物を3つ選択
- 「食べ物」「ランドマーク」「芸術」
- CUBEの構築のために、知識ベース(KB)拡張LLMアプローチを採用
CUBE-CSpace
WikiDataを知識ベースとして以下のアルゴリズムで抽出

- ’instance of’ (P31) and ’subclass of’ (P279)
- ’country-of-origin’ (P495) or the ’country’ (P17)
cの例:ビリヤニ(Q271555)→これがインドの属性と紐づいているので、インドの食べ物に追加
抽出した結果に対し、GPT-4-Turboでリファインさせる(必ずしも属す必要がないものを落とす)。50万件→30万件
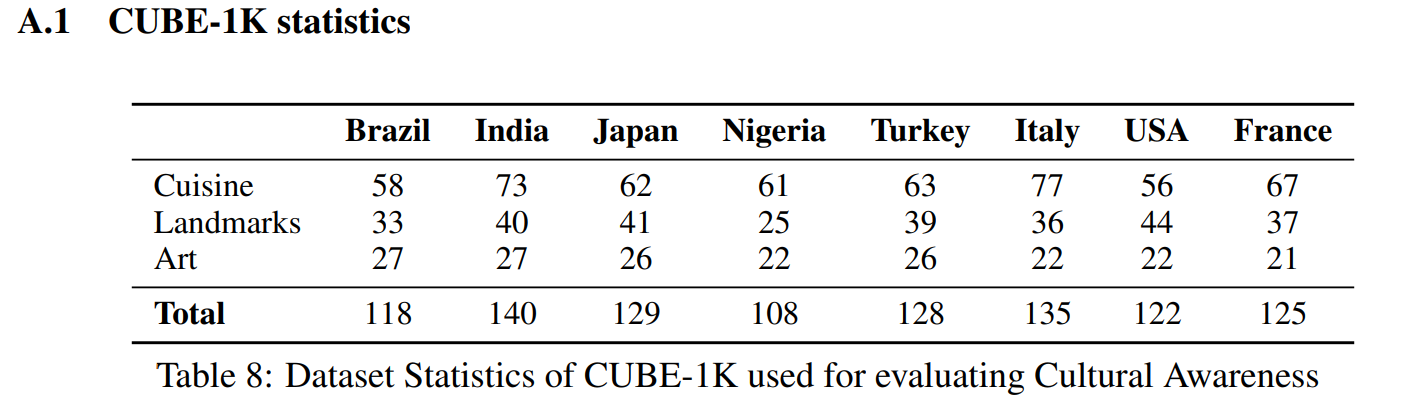
CUBE-1K
- CUBE-CSpaceをさらにキュレーションする
- 画像生成モデルはロングテールなキーワードの生成に苦労する
- ロングテールかどうかを判定するために、地域内の人気度の代理指標として、Google Search APIを使い、ジオロケーションキーワード(gl:)を条件として検索結果の数を用いる
結果
T2Iの文化ごとの生成結果の評価
人間に以下の評価をさせる(検討した各国から多様な評価者グループを募集したと書いてある)。CUBE-1Kデータセットのプロンプトから画像を生成し、以下の項目を評価。
- 文化的関連性: 画像のみから、描かれている項目はアノテーションの国に属しているか?(はい/いいえ)
- 忠実度: 画像が注釈者の国のものであれば、テキスト記述の項目とどの程度一致しているか?(1-5リッカート尺度)
- リアリティ:忠実度に関係なく、画像はどの程度リアルに見えるか?(1-5リッカート尺度、得点≦3の場合は任意コメント)
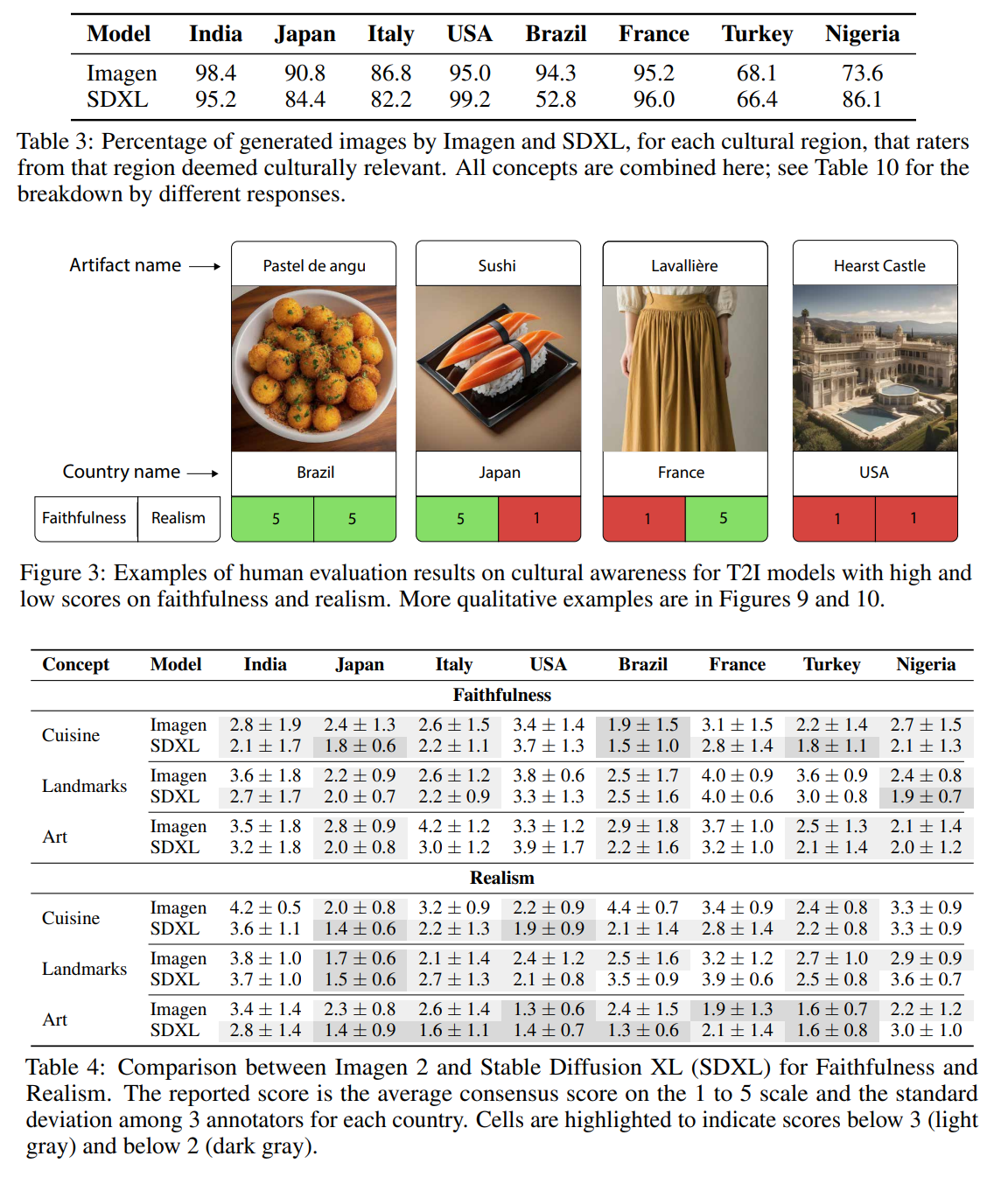
- 2段階に定量評価し、最初は「1がはい」の割合を求める。
- 国レベルでは結構あう。ただ、SDXLのブラジルが非常に低く、Imagenは高い。学習データの選択の関係かと思われる
- 中央
- 寿司の例:忠実度は高いはリアリティは低い。「魚は硬く見え、光沢のあるプラスチックのようだ」
- ラ・ヴァリエール:忠実ではないらしい
- 先行研究と一致し、グローバル・サウスとみなされる国(ブラジル、トルコ、ナイジェリアなど)ではスコアが低い傾向にあり、忠実性に格差が見られる
- 忠実度に比べ、地中文化圏では平均してリアリズムのスコアが低い
文化的多様性の評価
Vendiスコア
Vendiスコアは、生態学的多様性の公理を満たす解釈可能な多様性指標のファミリー(先行研究より)

論文では、これに品質の条件を入れた、品質加重Vendiスコアを使用。品質のスコアリングはHPS-v2を使用。
文化的多様性の評価
カーネルを定義し、係数を変えることで、大陸レベル、国レベルといった異なる縮尺での多様性を評価可能。個々のカーネルはVSが普通のVendiスコアで、qVSが品質荷重Ventiスコア

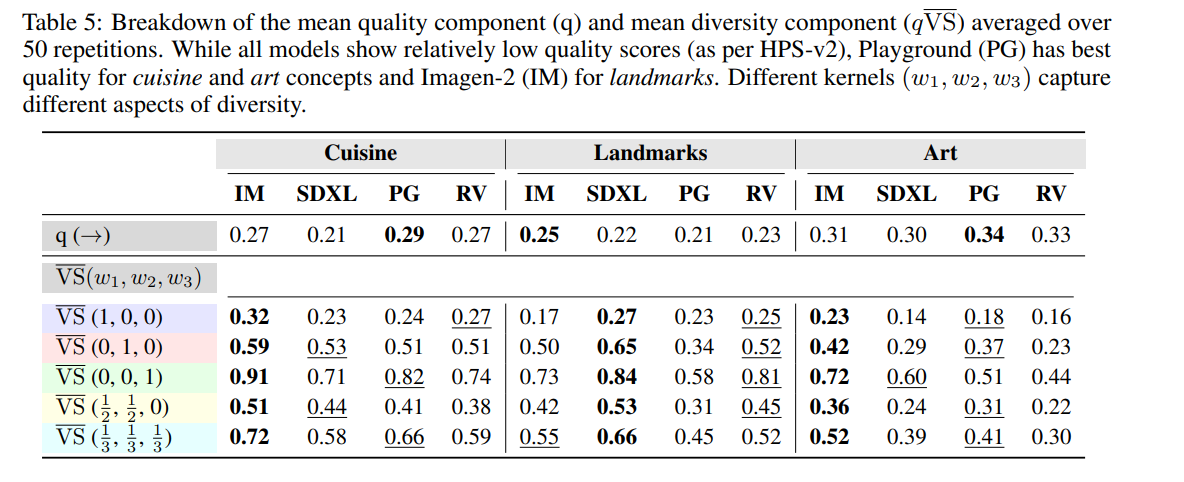
色は大陸/国/アーティファクト…といった区分。スコアが1なら多様性が高い。スコアが低く、多様性が課題
議論
論文中では結構注意深く議論している
- 南半球の概念に対する能力向上の枠組みが必要
- 提案手法はノイズが多い
- WikiDataそのものにバイアスがあること
- VLM/LLM自体のバイアス
- 国/大陸にマッピングすることのバイアス
- アノテーター自身のバイアス
- 「文化」の定義。地政学的境界の国という狭い概念での文化しか議論できておらず、文化自体は越境して一枚岩ではない
- CUBE-CSpaceとCUBE-1Kは、トレーニングや緩和のよりも、評価パイプラインでの使用を意図している、とのこと
私の所感
- なるほどこう評価するのか感。文化的多様性という点だと議論が発散しがちなので、もう少し閉じたドメインの話でこのフレームワークを使うのは有用ではないかだろうか感(例えば、キャラクターの生成結果にどの程度の多様性やスタイルを反映できるのかという視点)
- あんまりよくある機械学習の論文っぽくなく、文化の話をすると結構学術的な内容になるんだなという所感
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー