
CVPRの論文の被引用数の深読み(GitHub, arXiv, Sematic Scholar APIの活用)


CVPR2022・2023の論文を対象に、GitHubリポジトリやarXivの公開有無と被引用数の関係を調べた結果、リポジトリを公開している論文ほど被引用数が高い傾向が確認された。さらに、GitHubスター数と被引用数には明確な相関が見られ、コードの可視化や充実度が研究のインパクトに寄与している可能性が示唆された。
目次
はじめに
- CVPRの論文の被引用数を分析・予測してみたでは、CVPR 2022、2023に公開された論文について、GitHubリポジトリの公開有無、arXivによるプレプリントの公開有無と、論文の引用数の関係を調べた。結論は「明らかに関係がありそう」だった。
- ただそのときは、GitHubのリポジトリもCVPRが公式に出していたデータを使用し、CVPR 2022のデータはGitHubの登録数が非常に少なく(全体の6-7%程度)、登録漏れが相当あるのではないかという疑惑があった。
- そこで、今回はGitHubのAPIを使って論文のリポジトリを探し、arXivやSemantic ScholarのAPIを使ってプレプリントを探した上で引用数との関係を調べた。
- 結論は「特にGitHubは明らかに関係ある」だった。
- 「どのAPIを使えばどの程度リポジトリやプレプリントを引き出せるのか」という汎用的な知見としても有効で、GitHubはGitHubのAPI+ChatGPTのAPI、arXivはSemantic ScholarのAPIで探すのが良さそうだった。
結論
- GitHubリポジトリの有無や検索しやすさは、論文の被引用数にかなり影響しそうである。
- 公式データとGitHub API検索結果にはお互いに抜け漏れがあるため、両方向を併用するのがベスト。
- arXivに関してはカバー率が高めだが、Semantic ScholarのAPIを組み合わせるとさらに増える。
- GitHubで多くのスターを獲得しているリポジトリは、結果として論文の引用数も伸びやすい。
- 特にCVPRのように実装ベースでの検証が重んじられる分野では、コード公開=再現性の担保が大きく研究の影響力に関わっていると考えられる。
以上から、「引用を集めたい論文は(1)早期にarXivにプレプリントを出す、(2)GitHubに公式実装を作って検索でも引っかかるようにしておく」ことが、地味ながら意外にとても重要そう。
論文のリポジトリ探索を自動化する
GitHubのAPI
- 論文についているソースコードを探すには、論文タイトルでGitHubを検索してしまうのがストレートなやり方。
- GitHubのAPIがあり、Personal Access Tokenを使えば1時間に5000リクエストまで使える。
- PyGitHubを使うと、エラー時のバックオフまでやってくれるので便利。
GitHub APIの実行
PyGitHUbを使って次のようにする。readmeとタイトルの両方に論文タイトルがあるかどうかを見る。公式リポジトリは特にReadmeに書いてあるケースが多いことが経験的にわかっているので、それで引っ掛ける。
from github import Github
g = Github(login_or_token="<your github personal token>")
def find_papaer_repo(paper_title, authors):
# GitHub APIの実行
query = f'"{paper_title}" in:name,readme'
search_result = g.search_repositories(query=query, sort="stars", order="desc")
スター順に降順ソートする。
OpenAIのAPIによるフィルタリング
ただし、これだとAwesome◯◯のような論文をひたすらリンクしたリポジトリがよくヒットするので除外する必要がある。ここにOpenAIのAPI(GPT-4o)を使う。
「どこまでの情報を使うか」という点だが、リポジトリのタイトルと説明は検索APIでそのまま取れる(Readmeを取ろうとすると、リポジトリ単位でAPIを1コールする必要があり、トークン数が増えるため一旦除外した)。
そこで、検索をスター数で降順ソートして、論文タイトル、著者、リポジトリ名、URL、説明、スター数をOpenAIのAPIにひたすら与えて、公式リポジトリっぽそうなのをGPT-4oに選択させるということを行う。論文タイトルと著者はCVPRのデータで既にある。以下のようなシステムプロントで行う。プロンプトで「Awesome◯◯を明確に弾け」と指摘してある。
"""You are a great machine learning engineer. You are currently looking for an official implementation of this paper.
Paper: {paper_title}
Author: {authors}
What you are looking for most is an official implementation of the paper. An official implementation contains the code to run the techniques proposed in the paper.
A third-party implementation is fine if you don't have one.
You will be given the repository ID, name, URL, description, and number of stars below, so please determine whether it is the implementation you are looking for.
It is given by users in the following format.
-----
ID: 1
Name: user-name/Repository-title
URL: https://github.com/user-name/Repository-title
Description: Repository description. It may not be here.
Stars: 2
-----
However, many of the repositories listed are repositories introducing papers such as "Awesome **", and do not include implementations.
Please ignore repositories without implementations. Some papers do not have implementations.
Please respond with a list of numbers containing the IDs of repositories with the desired implementation. If the desired implementation does not exist, please return an empty list."""
これはゼロショットでも結構精度が出るようである。ゼロショットの場合は、プロンプトのトークン数が500~870程度で、平均750と仮定しても、3000論文で2.25Mトークンしか無く、4oを使っても十分に安い金額である。抽出できると以下のような例になる。
{
"paper_id": 3,
"title": "Estimating Example Difficulty Using Variance of Gradients",
"authors": "Chirag Agarwal, Daniel D'souza, Sara Hooker",
"valid_repos": [
{
"id": 3,
"full_name": "chirag-agarwall/VOG",
"html_url": "https://github.com/chirag-agarwall/VOG",
"description": "Estimating Example Difficulty using Variance of Gradients",
"stargazers_count": 61
}
],
"usage": {
"prompt_tokens": 836,
"completion_tokens": 6
}
}
{
"paper_id": 4,
"title": "One Loss for Quantization: Deep Hashing With Discrete Wasserstein Distributional Matching",
"authors": "Khoa D. Doan, Peng Yang, Ping Li",
"valid_repos": [
{
"id": 2,
"full_name": "khoadoan106/single_loss_quantization",
"html_url": "https://github.com/khoadoan106/single_loss_quantization",
"description": null,
"stargazers_count": 22
}
],
"usage": {
"prompt_tokens": 435,
"completion_tokens": 6
}
}
どうも論文の著者名を入れるのが大事そうで、これがGitHubのアカウント名と紐づいていると本物っぽいと判定されるようだ。
ただReadmeを見ていないため、「Code will be available soon」と書いてあって放置されているリポジトリは考慮していない。とりあえず公式リポジトリっぽそうなものだけ取ってきている。
GitHubリポジトリのカバー率
CVPR2022、アクセプトされた論文数に対する、GitHubリポジトリの取得率(カバー率)を比較する。
公式データはこちら。公式データには「GitHub」というカラムがあり、GitHubリポジトリが記録されているがカバー率が低い。GitHub APIは2025年時点。
| カンファレンス | データソース | カバー率(%) |
|---|---|---|
| CVPR 2022 | Hugging Face(公式) | 7.1 |
| CVPR 2022 | GitHub API | 69.4 |
| CVPR 2023 | Hugging Face(公式) | 42.4 |
| CVPR 2023 | GitHub API | 69.3 |
GitHub APIを使えば、アクセプトされた全論文に対して69%をリポジトリを取得できた。公式データのカバー率が低い理由はなんとなく想像できて、おそらくこの公式データは、論文の投稿時にCVPRに提出したものかと思われる。おそらくGitHubが投稿時に用意されていなかったか、レビューの関係で公開していなかったの関係で、「現在はリポジトリがあるのに、公式データに載っていない」リポジトリであると思われる。
CVPRの全論文に対して、(その信憑性はおいておき)7割は公式リポジトリらしきものがあるというのはなんとなく直感的に正しい。
カバー率のクロス集計
「元データでリポジトリが記録されていた/いない」×「GitHub APIで取得できた/できない」のクロスで比較する。縦軸が元データ、横軸がGitHub APIである。
CVPR 2022の場合
| 元データ / GitHub API | GitHubなし | GitHub あり | % / 合計 |
|---|---|---|---|
| GitHubなし | 595 | 1332 | 92.9% |
| GitHub あり | 40 | 107 | 7.1% |
| % / 合計 | 30.6% | 69.4% | 2074 |
CVPR 2023の場合
| 元データ / GitHub API | GitHubなし | GitHub あり | % / 合計 |
|---|---|---|---|
| GitHubなし | 310 | 688 | 42.4% |
| GitHub あり | 412 | 943 | 57.6% |
| % / 合計 | 30.7% | 69.3% | 2353 |
こうしてみると、GitHub APIは完全な公式データの包含ではなく、「公式データにはGitHubが記載されていたが、GitHub APIでは検出できなかった」(表の左下のケース)が一定存在する。
この理由は、公式実装がなにかのフレームワーク(例:mmシリーズ)に吸収されていて、論文タイトルとリポジトリ名が全く違うケースが一定数あると考えられる。あとはリポジトリ内で論文のフルの名前を書いていなく、検索で引っかかっていない例かと思われる。
なので、純粋にGitHubリポジトリの存在しない論文というのは、表の左上のケースのみで、論文実装を探す際は公式データとGitHub APIの両方を併用して母集団を築くというのが良いかと考えられる。
論文の被引用数との関係
表の2×2のグループについて、4グループ間で被引用数に有意差があるかを調べた。被引用数はSemantic ScholarのAPIを使った。検定はクラスカル・ウォリス検定を用いた。
| カンファレンス | Kruskal-Wallis統計量 | p値 |
|---|---|---|
| CVPR 2022 | 118.74 | 1.439e-25 |
| CVPR 2023 | 147.75 | 8.038e-32 |
グループ間では強い有意差が見られた。グループ間の被引用数の分布を見ると、
| CVPR 2022 | min | 25% | 50% | 75% | max |
|---|---|---|---|---|---|
| group_11 | 1.0 | 25.5 | 55.0 | 92.0 | 791.0 |
| group_10 | 1.0 | 13.3 | 33.5 | 61.5 | 579.0 |
| group_01 | 0.0 | 22.0 | 44.0 | 87.0 | 11817.0 |
| group_00 | 0.0 | 12.0 | 26.0 | 49.0 | 1448.0 |
| CVPR 2023 | min | 25% | 50% | 75% | max |
|---|---|---|---|---|---|
| group_11 | 0.0 | 11.0 | 21.0 | 40.0 | 2152.0 |
| group_10 | 0.0 | 5.0 | 12.0 | 22.0 | 881.0 |
| group_01 | 1.0 | 10.8 | 22.0 | 43.3 | 4912.0 |
| group_00 | 0.0 | 6.0 | 12.0 | 23.0 | 935.0 |
group_11:CVPRの公式データでGitHubが記載されており、GitHubのAPIでも公式リポジトリらしきものが存在確認できたグループgroup_10:CVPRの公式データでGitHubが記載されており、GitHubのAPIでは公式リポジトリらしきものが存在確認できなかったグループgroup_01:CVPRの公式データでGitHubの存在は確認できなかったが、GitHubのAPIで公式リポジトリらしきものが存在確認出来たグループgroup_00:CVPRの公式データでGitHubの存在が確認できなく、GitHubのAPIでも公式リポジトリらいきものが存在確認できなかったグループ
group_00が明らかに被引用数が伸びないのは当然だろう。他の人が引用しようと思っても再現できないので、先行手法の研究を再現しようにも再現するのが大変だからである。group_11が伸びやすいのはわかりやすい。
なんともいえないのは、group_10とgroup_01で、これはCVPR 2022とCVPR 2023で傾向が違うようである。CVPR 2022では、group_10であってもgroup_00よりは伸びている。しかし、CVPR 2023では、group_10はgroup_00とほぼ同じぐらいになっている。それに比べてgroup_01はCVPR 2022とCVPR 2023両方とも伸びている。
ここからわかるのは、GitHubの検索に引っかかることが割と大事で、GitHubのAPIに引っかかることが(GitHub用のSEOをしていることが)、リポジトリの認知性を上げることが被引用につながると考えられる。つまり、今まで研究を知らなかったような浮動票(引用してくれそうな人たち)は結構GitHubからくるのではないかという仮説が立てられる。公式データ側に記載すると長期的には伸びるのだが、浮動票としてはそこまで大きい票田ではなく、即効性を求めるならGitHub側のSEOが大事ということだろう。
arXivのデータ取得
arXivのリンクも公式データには記載されている。より厳密に行うなら以下の2つのAPIも検討してもいいだろう。
- arXivのAPIで論文タイトルで検索
- Semantic ScholarのAPIに紐づいているarXivを検索
Semantic Scholarには実はarXivのリンクがあることがわかったので、これを情報源ともしてみた。
検索の実装
arXivの検索でも、Semantic Scholarの検索でも、論文のタイトルのフルネームで検索し、出てきた候補について以下のコードでタイトル間の類似度を計算し、類似度0.9以上かつ、最大のものを対象の論文として紐づけた
from rapidfuzz import fuzz
# 類似度計算の関数
def sentence_similarity(sentence1, sentence2):
s1 = sentence1.lower().strip()
s2 = sentence2.lower().strip()
score = fuzz.ratio(s1, s2)
normalized_score = score / 100.0
return normalized_score
arXivのAPIの場合
arXivの場合はフィールドをallにしてそのままタイトルで検索。arXivのライブラリを使用。ただしよくリクエスト過多でエラーになるため、そこらへんをうまく取り回してあげる必要がある。
import arxiv
arxiv_client = arxiv.Client()
def search_arxiv(paper_title):
# arxiv.Search を用いて検索クエリを構築
search = arxiv.Search(
query=f'all:{paper_title}',
max_results=20,
sort_by=arxiv.SortCriterion.Relevance
)
Semantic Scholarの場合は、requestsでそのまま投げる。こちらもよくリミットかかるので根気がいる。externalIdsにarXivのリンクが含まれていることがある。
import requests
url = "https://api.semanticscholar.org/graph/v1/paper/search"
# クエリパラメータの設定。externalIdsフィールドを追加。
params = {
"query": paper_title,
"limit": limit,
"fields": "title,abstract,tldr,citationCount,externalIds"
}
try:
# GETリクエストを送信
response = requests.get(url, params=params)
Sematic ScholarのAPIで取得できると以下のようになっている。externalIds内にArXivがあるものをフィルタリングすればOK。
{
"total": 6,
"offset": 0,
"next": 3,
"data": [
{
"paperId": "5ee775484fcdab1013e1f644b2626832e15057ea",
"externalIds": {
"ArXiv": "2211.08542",
"DBLP": "conf/cvpr/XuGLZ23",
"DOI": "10.1109/CVPR52729.2023.00111",
"CorpusId": 253553455
},
"title": "CXTrack: Improving 3D Point Cloud Tracking with Contextual Information",
"abstract": "3D single object tracking plays an essential role in many applications, such as autonomous driving. It remains a challenging problem due to the large appearance variation and the sparsity of points caused by occlusion and lim-ited sensor capabilities. Therefore, contextual information across two consecutive frames is crucial for effective object tracking. However, points containing such useful information are often overlooked and cropped out in existing methods, leading to insufficient use of important contextual knowledge. To address this issue, we propose CXTrack, a novel transformer-based network for 3D object tracking, which exploits ConteXtual information to improve the tracking results. Specifically, we design a target-centric transformer network that directly takes point features from two consecutive frames and the previous bounding box as input to explore contextual information and implicitly propagate target cues. To achieve accurate localization for objects of all sizes, we propose a transformer-based localization head with a novel center embedding module to distinguish the target from distractors. Extensive experiments on three large-scale datasets, KITTI, nuScenes and Waymo Open Dataset, show that CXTrack achieves state-of-the-art tracking performance while running at 34 FPS.",
"citationCount": 27,
"tldr": {
"model": "tldr@v2.0.0",
"text": "CXTrack is proposed, a novel transformer-based network for 3D object tracking, which exploits ConteXtual information to improve the tracking results and designs a target-centric transformer network that directly takes point features from two consecutive frames and the previous bounding box as input to explore contextual information and implicitly propagate target cues."
}
},
{
"paperId": "7d711d35772ba2ff247cccfef3efcf0b22d9650e",
"externalIds": {
"CorpusId": 260972199
},
"title": "Supplementary Material for “CXTrack: Improving 3D Point Cloud Tracking with Contextual Information”",
"abstract": "For the SOT task, the network only needs to consider a sub-region of the whole scene where the tracking target may appear. For training, we enlarge the ground truth bounding box by 2 meters to obtain the sub-region. We then sample 1024 points inside the region to generate the input point clouds Pt−1 and Pt. To simulate the inaccurate predictions during inference, we augment the input 3D bounding box Bt−1 by performing random translation with a range of [−0.3m, 0.3m] in all directions as well as random rotation around the up-axis.",
"citationCount": 0,
"tldr": {
"model": "tldr@v2.0.0",
"text": "To simulate the inaccurate predictions during inference, the input 3D bounding box Bt−1 is augmented by performing random translation with a range of [−0.3m, 0.3M] in all directions as well as random rotation around the up-axis."
}
},
{
"paperId": "6092cd34968f77b77c8880a97b2f340f0279dad2",
"externalIds": {
"DBLP": "conf/3dim/RaWMLYL24",
"DOI": "10.1109/3DV62453.2024.00050",
"CorpusId": 270396509
},
"title": "Exploit Spatiotemporal Contextual Information for 3D Single Object Tracking via Memory Networks",
"abstract": "The point cloud-based 3D single object tracking plays an indispensable role in autonomous driving. However, the application of 3D object tracking in the real world is still challenging due to the inherent sparsity and self-occlusion of point cloud data. Therefore, it is necessary to exploit as much useful information from limited data as we can. Since 3D object tracking is a video-level task, the appearance of objects changes gradually over time, and there is rich spatiotemporal contextual information among historical frames. However, existing methods do not fully utilize this information. To address this, we propose a new method called SCTrack, which utilizes a memory-based paradigm to exploit spatiotemporal contextual information. SCTrack incorporates both long-term and short-term memory banks to store the spatiotemporal features of targets from historical frames. By doing so, the tracker can benefit from the entire video sequence and make more informed predictions. Additionally, SCTrack extracts the mask prior to augmenting the target representation, improving the target-background discriminability. Extensive experiments on KITTI, nuScenes, and Waymo Open datasets verify the effectiveness of our proposed method.",
"citationCount": 0,
"tldr": {
"model": "tldr@v2.0.0",
"text": "A new method called SCTrack is proposed, which utilizes a memory-based paradigm to exploit spatiotemporal contextual information and incorporates both long-term and short-term memory banks to store the spatiotemporal features of targets from historical frames."
}
}
],
"id": 1,
"query": "CXTrack: Improving 3D Point Cloud Tracking With Contextual Information"
}
カバー率の計測
アクセプトされた論文に対して、arXivのリンクがどの程度の割合で取得できたか(カバー率)を計算する。以下の3つで調べる
- Hugging Faceにある公式データ
- arXivのAPI
- Semantic ScholarのAPI
| カンファレンス | データソース | カバー率(%) |
|---|---|---|
| CVPR 2022 | Hugging Face(公式) | 64.8 |
| CVPR 2022 | arXiv API | 48.4 |
| CVPR 2022 | Sematic Scholar API | 80.6 |
| CVPR 2023 | Hugging Face(公式) | 73.9 |
| CVPR 2023 | arXiv API | 42.5 |
| CVPR 2023 | Sematic Scholar API | 75.9 |
arXivの場合は公式データで既にガバー率が高いので、これが使えるならそのまま使っても良いだろう。Sematic Scholarを使うともう少しカバー率が上がる。arXivのAPIはそのまま検索するのでは精度が悪くてカバー率が良くない。
クロスのカバー率
- 縦軸:元データでのArxivのデータが登録されていたか
- 横軸:Semantic Scholar APIでArxivのデータが登録されていたか
CVPR 2022の場合
| 元データ / Semantic Scholar API | Arxiv なし | Arxiv あり | % / 合計 |
|---|---|---|---|
| Arxiv なし | 150 | 580 | 35.2% |
| Arxiv あり | 252 | 1092 | 64.8% |
| % / 合計 | 19.4% | 80.6% | 2074 |
CVPR 2023の場合
| 元データ / Semantic Scholar API | Arxiv なし | Arxiv あり | % / 合計 |
|---|---|---|---|
| Arxiv なし | 163 | 451 | 26.1% |
| Arxiv あり | 404 | 1335 | 73.9% |
| % / 合計 | 24.1% | 75.9% | 2353 |
なぜこのような差が出るのかわからないが、「公式データにarXivの記載があるが、Semantic ScholarにarXivが登録されていない例」「公式データにarXivの記載がないが、Semantic ScholarにarXivが登録されている例」のケースが一定あるようだ。
引用数との関係について
これら4グループについてGitHubと同様にクラスカル・ウォリス検定をしてみたが、CVPR2022、CVPR2023有意な結果になった。各グループごとの統計量は以下の通りだった。
| CVPR 2022 | min | 25% | 50% | 75% | max |
|---|---|---|---|---|---|
| arxiv_group_11 | 0.0 | 22.0 | 45.0 | 89.3 | 6387.0 |
| arxiv_group_10 | 0.0 | 9.0 | 19.5 | 35.3 | 282.0 |
| arxiv_group_01 | 0.0 | 22.0 | 41.0 | 78.0 | 11817.0 |
| arxiv_group_00 | 1.0 | 11.0 | 23.0 | 39.0 | 381.0 |
| CVPR 2023 | min | 25% | 50% | 75% | max |
|---|---|---|---|---|---|
| arxiv_group_11 | 0.0 | 11.0 | 22.0 | 41.0 | 2152.0 |
| arxiv_group_10 | 0.0 | 5.0 | 9.0 | 17.0 | 158.0 |
| arxiv_group_01 | 0.0 | 12.0 | 22.0 | 43.0 | 4912.0 |
| arxiv_group_00 | 0.0 | 5.0 | 10.0 | 20.3 | 192.0 |
ここで、4グループは以下の意味である。
arxiv_group_11:公式データにもSemantic ScholarにもarXivが登録されているケースarxiv_group_10:公式データには登録されているが、Semantic ScholarにはarXivが登録されていないケースarxiv_group_01:公式データには登録されていないが、Semantic Scholarには登録されているケースarxiv_group_00:公式データ、Semantic ScholarにもarXivが登録されていないケース
表を見る限りは「Semantic ScholarにarXivが登録されているほうが引用数が伸びやすくなる」と言いたくなる。しかし、そもそもの被引用数のデータをSemantic Scholarからとってきているので、Semantic ScholarにarXivが登録されていないケースでは、被引用数をSemantic Scholar側でトラックできておらずに、データとして反映されていない可能性がかなりある。あとは、プレプリントとカンファレンスに投稿時にタイトルが変わってしまって(検索結果を見ているとこれが一定ある)、それがSemantic Scholar上でマージできていないなどが考えられる。なので、GitHub側の信憑性は結構あるが、arXiv側の信憑性は結構怪しいものかもしれない。
少なくとも、開催後1年以上経過したカンファについて、arXivにプレプリントをおいてないケースは相当珍しいため、これが大きな差分になるとはあまり思えない。
GitHubのスター数と被引用数の関係
GitHubのAPIでリポジトリのスター数も取れるため、公式リポジトリらしきもののスター数と論文の被引用数の関係をプロットしてみた。スター数も被引用数も+1して対数をとってある。
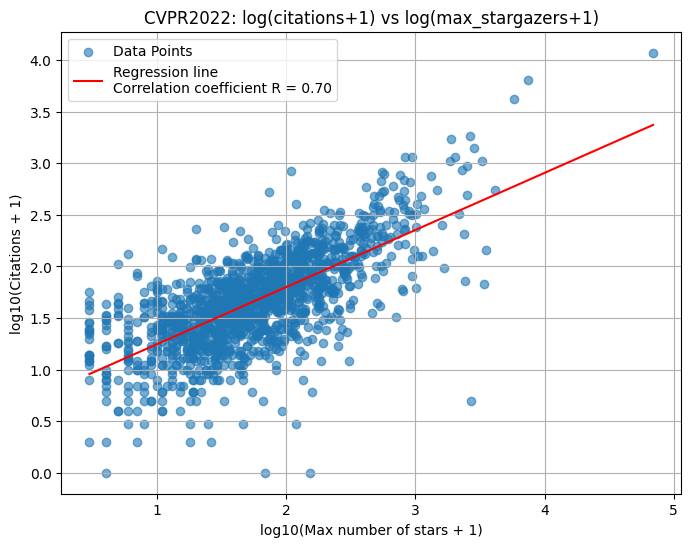
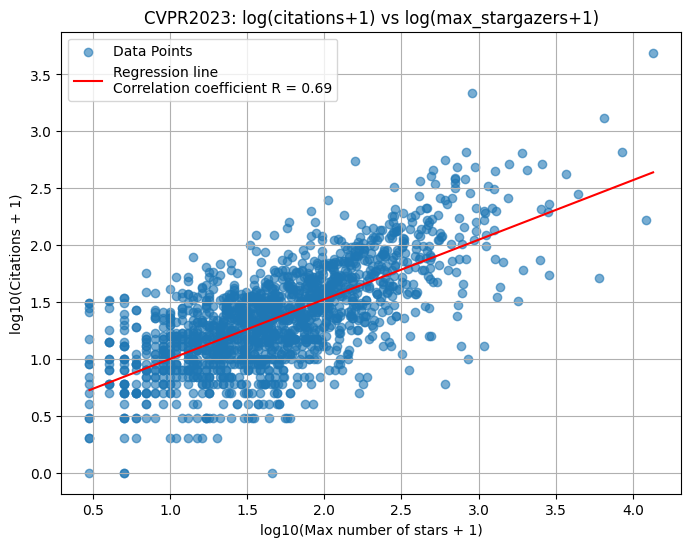
CVPR 2022, 2023と相関係数は0.7近くと割とはっきりした相関を確認できた。つまり「被引用数を稼ぎたければ、Starがいっぱい付けられるようなOSSを作るといい」という話になる。特にこれはCVPRみたいなカンファレンスだと特に顕著な傾向だろう。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー