
論文まとめ:(DALL・E 2論文)Hierarchical Text-Conditional Image Generation with CLIP Latents


- タイトル:Hierarchical Text-Conditional Image Generation with CLIP Latents
- リンク:https://cdn.openai.com/papers/dall-e-2.pdf
- 所属:OpenAI
- コード:DALL・E 2の前の段階のGLIDEは公開されているが、これは非公開(2022年4月時点)
目次
ざっくりいうと
- 訓練済みCLIPと拡散モデルを使った、テキスト→画像による生成モデル
- CLIPの画像埋め込み特徴を生成するような、拡散モデルベースの事前分布モデルを開発
- 先行研究のGLIDEの改良という位置づけだが、多様性に富む画像生成に成功
要旨
2段階のモデルを提案
- テキストキャプションを与えてCLIP画像埋め込みを生成する事前処理
- 画像埋め込みを条件として画像を生成するデコーダ
画像表現を明示的に生成することで、写実性とキャプションの類似性の損失を最小限に抑えながら、画像の多様性を向上できる。
画像表現を条件とするデコーダは、画像表現にない非本質的な部分を変化させながら、意味とスタイルの両方を保持した画像のバリエーションを生成できる。
デコーダーに自己回帰モデルと拡散モデルを使ったところ、拡散モデルのほうが良かった。

拡散モデルとは
ガウスノイズを加えていって劣化させ、正規分布の純粋なノイズにする方法。逆の操作をすることで、画像を復元できるモデルになる。図は超解像のSR3の論文より。

破損プロセスを逆転させることでノイズを取り除くのが拡散モデル。SR3は超解像に応用している。
お気持ち
Zero-shotのCLIPと拡散モデルを組み合わせる。
キャプションが与えられたとして、それにマッチするようなCLIPの画像特徴量を求めたい。これを論文では「反転」と呼んでいる。
CLIP画像エンコーダを反転させるための、拡散モデルベースの事前分布を学習させる。
- 反転モデルは非決定的で、与えられた画像埋め込みに対応する複数の画像を生成できる(拡散モデルに乱数の要素があるため)
- CLIP空間を用いる顕著な利点は、任意の符号化テキストベクトルの方向に移動することで画像を意味的に修正できること(GANだと地道な作業が必要)
生成結果はGLIDEと同等の品質で、世代における多様性がより大きい。
潜在空間における拡散事前分布の学習方法を開発し、自己回帰モデルと同等の性能を達成しつつ、より効果的に学習できた。
テキスト→CLIPの画像特徴量は、CLIP画像エンコーダを反転して画像を生成するため、「unCLIP」と論文中では呼んでいる。
手法
※数式のメモは私が追加
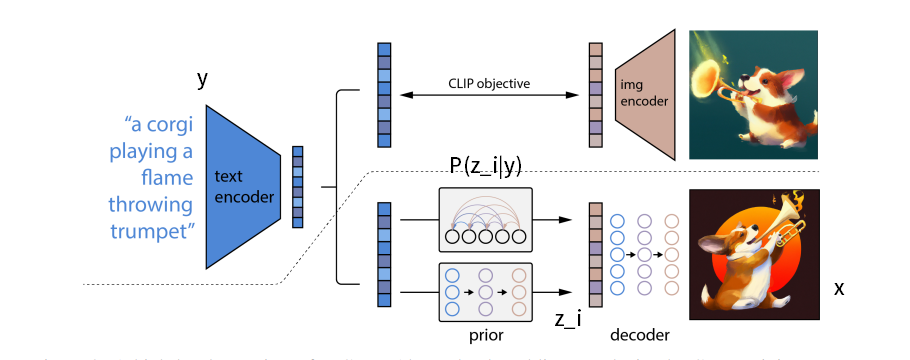
- 訓練データ:$(x, y)$、$x$が画像、$y$がキャプション
- CLIPの埋め込み特徴量を、画像$x\to (z_i, z_t)$とする(画像、テキスト)
第一段階として、事前分布$P(z_i|y)$を作りたい。これはキャプション$y$を与えたときに、CLIPの画像埋め込み特徴量$z_i$を生成するもの。
第二段階として、画像$x$を生成するデコーダー$P(x|z_i, y)$を作りたい
理論的にはただのベイズの定理。

事前分布から$z_i$をサンプリングして、デコーダーを使って$x$を生成。これが$P(x|y)$のサンプリングメソッド
CLIPのモデルは両段階で係数固定で、特徴抽出器として使う。
事前分布
第一段階。自己回帰モデル(AR)と、拡散モデルを考えた。拡散モデルのほうが良かった。
自己回帰(AR)の事前分布
$z_i$を離散コードに変換し、キャプション$y$を条件として自己回帰で予測
- CLIPの1024次元をPCAし319次元に落とす。特にSAMを用いてCLIPを学習すると、評価指標を改善しつつ、CLIPの次元を劇的に落とせる
- 319次元を1024の離散量に量子化し、Transformerを使って自己回帰
拡散モデルの事前分布
連続量の$z_i$を、キャプション$y$からガウス拡散モデルで直接予測
- ARのように、$z_i, z_t$で条件付けてモデル化はしない。あくまでCasual attention mask。
- $z_i$の2つのサンプルを生成し、$z_t$とのドット積が高いものを選択するように学習し、生成画像の品質を上げていく。
- モデル構造では、デコーダーのみのTransformerにCasual attention maskでシーケンスを追加していく
- 符号化されたテキスト
- CLIPのテキストの埋め込み特徴量
- 拡散タイムステップの埋め込み
- ノイズのないCLIP画像の埋め込み
- Transformerの最終層の埋め込み:CLIPのが画像埋め込みの予測に用いられる直前
事前分布の損失関数。L2回帰で予測

私の感想:事前分布のモデル構造がかなりのキー手法なのに、ここの言及が少なく、図がなかったのが残念。
デコーダー
第二段階。先行研究のGLIDEをベース。GLIDEは拡散モデル+CLIPで、拡散モデルとCLIPをつなぎ合わせるのはDALL-E 2が初ではない。
DALL・E2では、具体的には、既存のタイムステップ埋め込みにCLIP埋め込みを投影して追加する。GLIDEテキストエンコーダからの出力のシーケンスに連結される、コンテキストの4つの追加トークンにCLIP埋め込みを投影することによって、GLIDEのアーキテクチャを修正。
高解像度生成には、64×64→256×256、256×256→1024×1024の2つの拡散アップサンプリングモデルを学習する。アップサンプリングモデルの頑強性を向上させるため、学習時にガウスぼかしなどの劣化プロセスを教師画像に対して行う。
画像にバリエーションを持たせる
2つの画像のCLIP埋め込み$z_i, z_j$を考える。先行研究のDDIMに基づき、
- $z_i$と$z_j$を球面補間し、$z_θ=\rm{slerp}(z_i, z_j, \theta)$を求め、デコーダを通すことにより$z_θ$のバリエーションを生成
unCLIPデコーダーでCLIPの潜在空間を探索

CLIPの画像埋め込みをとり、PCAの次元を増やして再構成し、固定シードのDDIM付きデコーダーで可視化したもの。低次元では粗い意味情報に対応、高次元ではオブジェクトの形状や形の詳細をエンコーディングしている。
テキスト→画像の生成
事前分布の重要性
キャプション→画像の生成には事前分布は必ずしも必要ないが、あったほうが生成画像はより正確にキャプションを捉える。

- 1番目:キャプションだけ
- 2番目:キャプションとCLIPのテキスト埋め込み特徴
- 3番目:キャプションと、キャプションの自己回帰事前分布によって生成されたCLIPの画像埋め込み特徴を渡す
→3番目が最もキャプションのコンテクストを捉えている。事前分布をおくのが重要。
人間による評価

unCLIP(Dall-e 2)とGLIDEの比較。人間による評価。自己回帰と拡散のいずれもGLIDEよりよく、特に多様性が改善した。
多様性においては次のような4×4のグリッドを見せて「どっちが多様性に富むか」を選択させている。

MS-COCOによるゼロショット評価
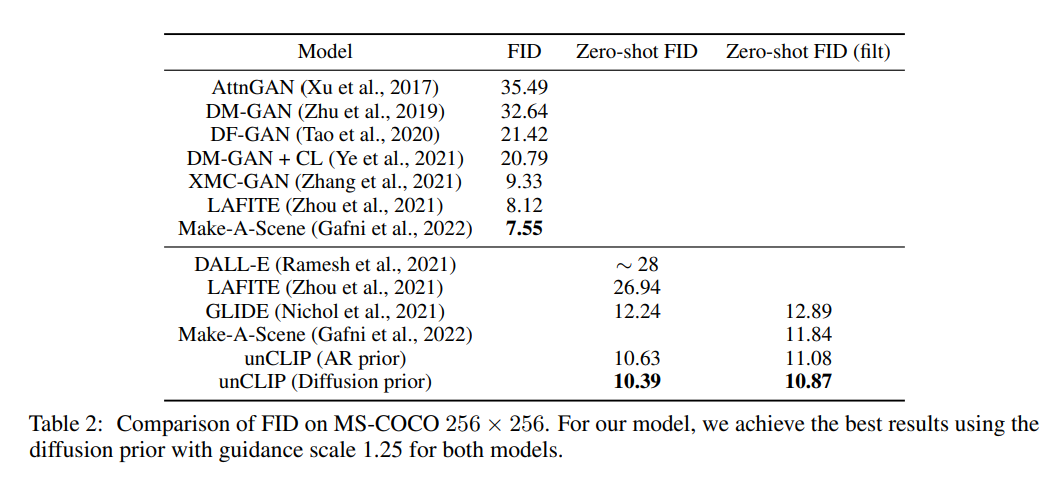
MS-COCOによるZero-Shot。話題になっている割には、GLIDEやMake a senceからよくある性能改善で、爆発的に良くなったというほどではない。
私の感想
- ベイズの定理でシンプルに理論立てたのと、拡散モデルの強力さ、CLIPの潜在空間のPCAが面白い
- OpenAIのプロモーションが上手くて注目されている感は否めない。CLIPに拡散モデル加えて、Transformerに特徴量全盛りしたのをかっこよく見せているだけではないか
- 位置づけはGLIDEの改善で、話題とは裏腹に定量的なゲインも地味。多様性を強調したいなら、もう少しここの定量評価が必要(例えば、BigGANでしていたような、Inception-ScoreとFIDのトレードオフの話はどうなのか)
- プロモーション的には良くても、これを良い研究論文と言っていいのかは疑問が残る
- 2022年4月時点で、ソースコードやモデルを公開してくれなく、あれするなこれするなうるさいので自分としては辛めの評価。OpenAI(モデルを公開するとは言っていない)
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー