
論文まとめ:Domino: Discovering Systematic Errors with Cross-Modal Embeddings
Posted On 2022-11-16


- タイトル:Domino: Discovering Systematic Errors with Cross-Modal Embeddings
- 著者:Sabri Eyuboglu, Maya Varma, Khaled Saab, Jean-Benoit Delbrouck, Christopher Lee-Messer, Jared Dunnmon, James Zou, Christopher Ré
- 所属:スタンフォード大学
- カンファ:ICLR 2022
- 論文URL:https://arxiv.org/abs/2203.14960
- コード:https://github.com/HazyResearch/domino
目次
ざっくりいうと
- 訓練済みV&Lモデルの特徴量を使い、分類モデルの性能を悪化させている評価データセットのスライスを検出する
- 当該スライスを定量的に判定できるだけでなく、理由も記述できる
- Sklearn-likeのAPIが用意され、OSSとして手軽に利用できる
スライスとは
- 共通の特徴を持つデータサンプルの集合
- 例:車の検出するための分類モデルがある
- ビンテージカーで推論すると精度が下がる
- ビンテージカーの写真の集合がパフォーマンスを落としているスライス
- クラス(車)よりももう少し細かいレベルでの、共通の特徴(ビンテージカー)を持ったデータの集合
- この論文では、データ内の「パフォーマンスを劣化させているスライスを特定」したい
- 医用画像では、潰れた肺の検出、メラノーマ検出
- 物体認識では、西側の家電製品の画像で訓練したモデルを、発展途上国で推論すると性能が下がる といった具体的な問題がある
- パフォーマンスを劣化させているスライスを特定し、その理由を説明するためのツールを作ったよというのがDominoの貢献
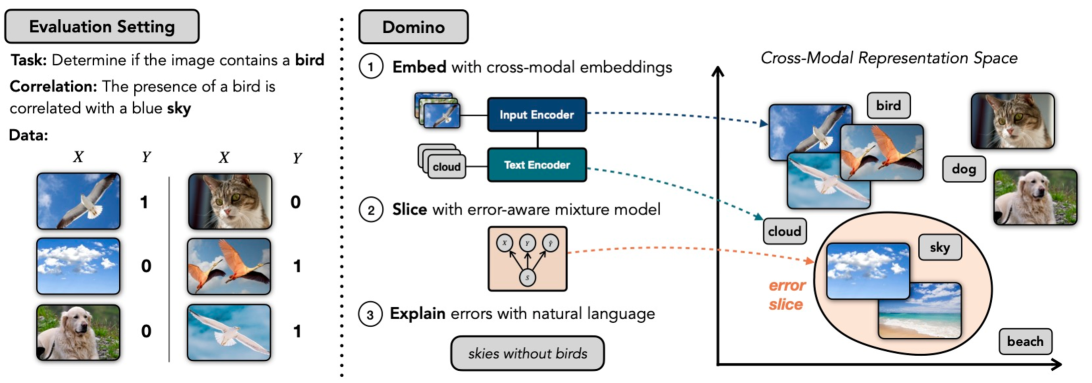
- 鳥を分類するモデルがあるとする。このときパフォーマンスを劣化させているスライスは「空の画像」
- 「鳥のいない空」の画像では偽陽性がおこる
- SDM:slice discovery methods
関連研究
- 既存の研究:埋め込み表現をとる→クラスタリング(d’Eon et al., 2021; Sohoni et al., 2020; Kim et al., 2018).
- SDM間のトレードオフを示せない
- クロスモーダルモデルから影響を受けた
- 自然画像用のCLIP(Radford et al., 2021)
- 医療画像用のConVIRT(Zhang et al., 2020)
- 衛星画像用のWikiSatNet(Uzkent et al., 2019)
SDMの一般論?

- (この式を見てもおそらく意味不明だと思うので)、X=画像、Y=ラベルがある
- Ground Truthのスライスの値(どのスライスに割り当てられたか)が別途ある
- これをk個のスライスに分割したい。分割自体は、0-1の二値分類を複数並べたようなものを作る(と想像)
- ただし、スライスの個数は推定値$\hat{k}$とkが必ずしも一致しないのでちょっと複雑
- あるデータが、特定のスライスvに割り当てられるような推論がされたとき、Ground Truthのスライスとは違う割当が多いのが「性能を低下させているスライス」
- Ground Truthのスライスに対して「偽陽性の割当」をトリガーとしたいというお気持ち
- 最終的には、スライスの予測値とGround Truthに対して、何らかの類似度の指標Lを計算する
Ground TurthのスライスはImageNetならタグのメタデータから作れる

Dominoの手法

- Embed, Slice, Describeの3段階からなる
- Embed:CLIPのようなVision & Langの特徴量をとる
- Slice:ここが難しい。何らかのクラスタリングモデルでスライスを作っているのではないか
- Describe:BERTで生成
- 数式の変数が多く、SDMの一般論とDominoの境目が曖昧なまま議論していて、この論文むずい!
- お気持ちとしては、Sliceの部分は、混合ガウス分布のようなクラスタリング手法を使ってスライスを定義、Y_predとY_trueの差を見て、エラーのスライスを何らかの確率計算してスコアリングしている(と勝手に理解)
Describeの部分

- 「MASK」の部分にコーパスからの単語を突っ込んで、BERTやGPT2で生成している
結果
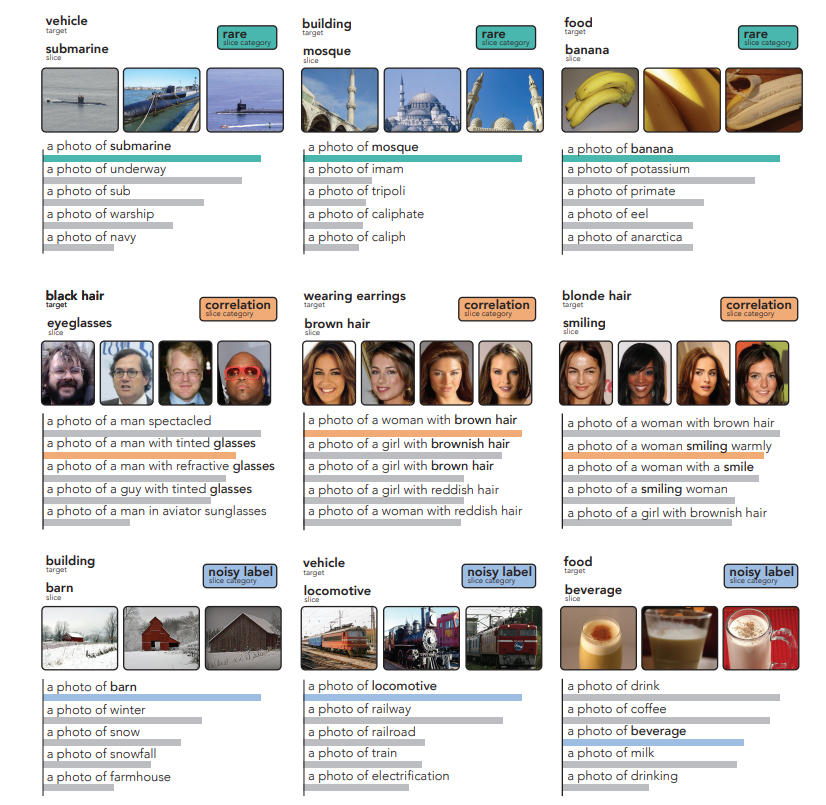
- ルールベースで、「rare slice」「correlation slice」「noisy label slice」を定義するとそれっぽい結果が出る
- このルールベースは、母数のうち何%か、相関係数を見るなどで定義
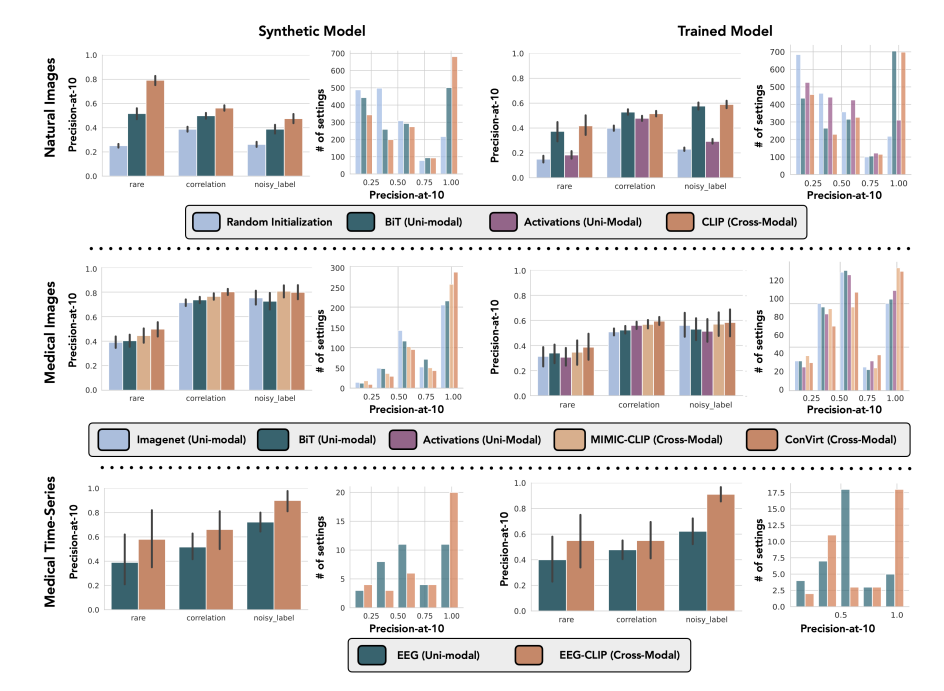
- 特徴量抽出のためのモデルは、自然画像ならCLIPが最も良かった
- 評価指標は性能を悪化させているスライスのPrecisionを見ている
まとめ
- 「モデルの性能を悪化させているデータはどれか」という実用的にも非常に需要のありそうな内容
- コードが非常に整備されているのでSklearn感覚で手軽に使える(はず)
- サンプルプログラム動かしてみたところ、若干バグがある(2022/11時点)
- 論文はあまりに難解すぎて自分は挫折したので、これを理解できた人は偉い!
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー