
論文まとめ:OCR-free Document Understanding Transformer


- タイトル:OCR-free Document Understanding Transformer
- 著者:Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park
- カンファ:ECCV 2022
- 所属:NAVERなど
- 論文URL:https://arxiv.org/abs/2111.15664
- コード:https://github.com/clovaai/donut
目次
ざっくりいうと
- OCRに頼らない、End-to-Endの画像からの文章解析モデル
- SynthDoGという合成データによる事前学習を行い、任意の言語にスケール可能
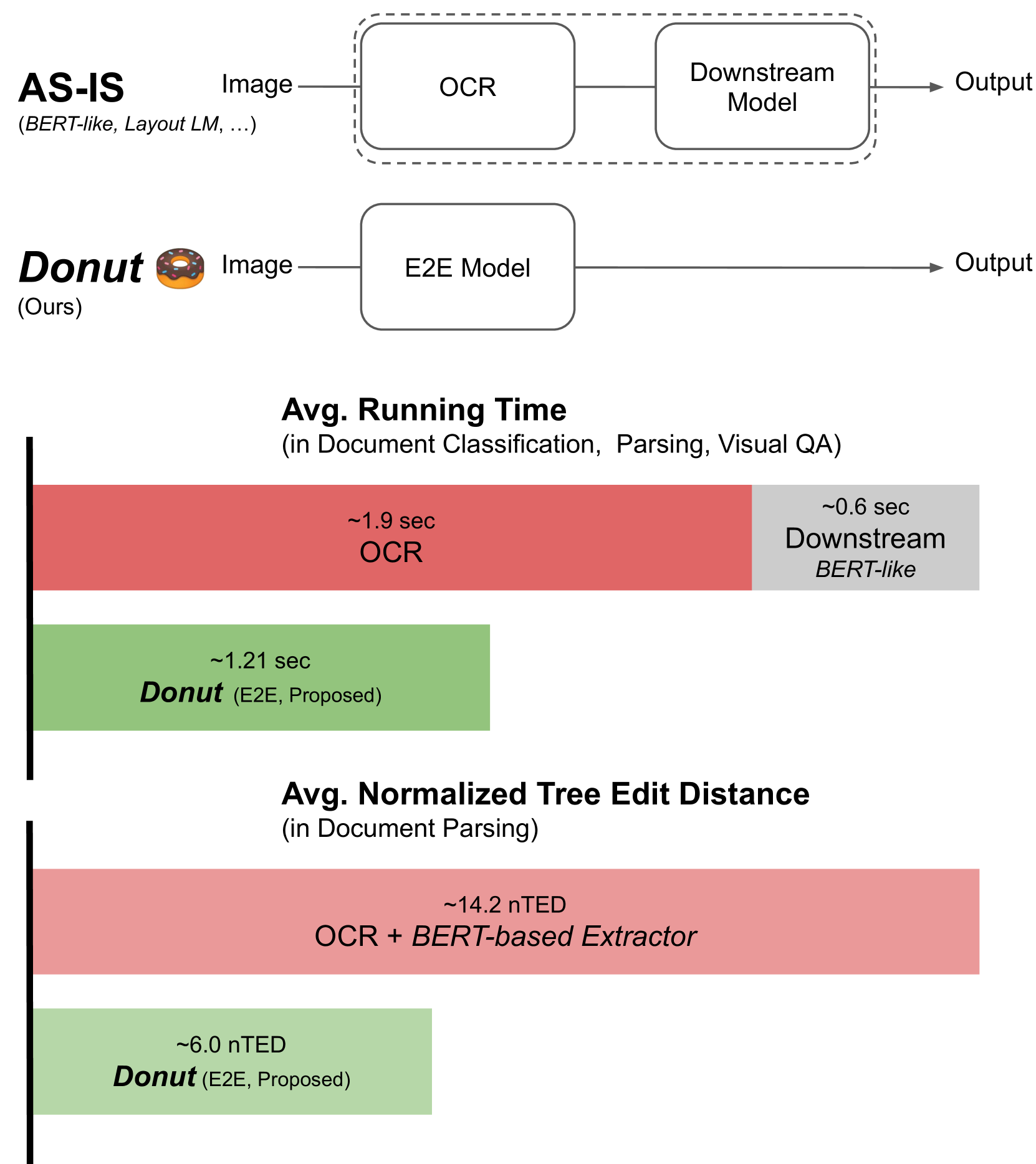
- クラウドOCRベースよりも、処理時間・精度ともに良い結果を示した
- 日本語版のSynthDoGが公開されている
概要
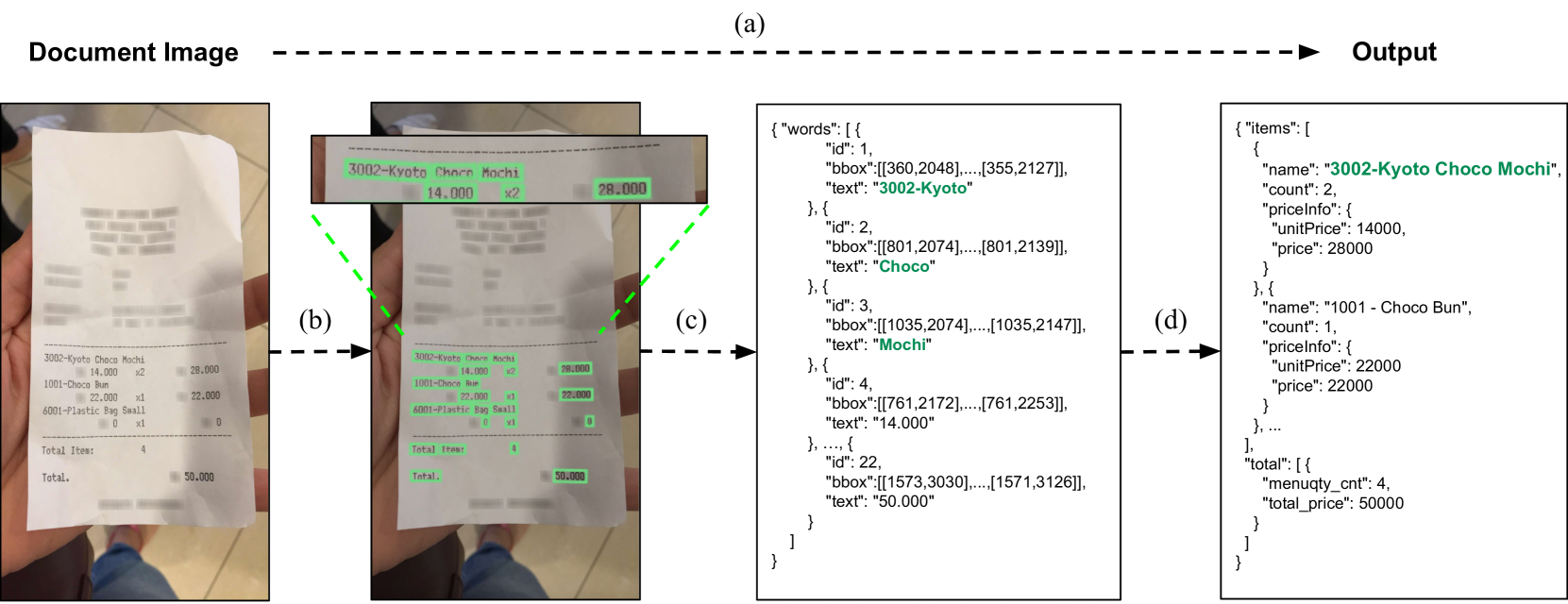
現在使われている文章解析パイプライン。例:Hwang et al.(2019)
- (a)Input:半構造化情報のある画像→Output:構造化情報の抽出
- (b)テキストの物体検出
- (c)Bounding Box内のテキストの認識
- (d)構造化情報への変換
→これをEnd to Endにしたよ、というのがDonut
従来手法の問題点
- OCRが高価
- 独自OCRを訓練するには大規模なデータセットが必要 Baek et al.(2019)
- 例:IIT-CDIP(Lewis et al., 2006)
- Donutでは、合成文書生成器SynthDoGを提案し、事前学習
- 最新のモデルは推論にGPUが必須
- 独自OCRを訓練するには大規模なデータセットが必要 Baek et al.(2019)
- OCRのエラーがその後の処理に影響を及ぼす
- 日本語のように文字種が多いデータセットではOCRは比較的困難
- 別のOCR補正モジュールを配置する(Schaefer and Neudecker, 2020; Rijhwani et al., 2020; Duong et al., 2021)方法もあるが、システムのメンテナンスコストを増大させ実応用には程遠い
手法
モデル構造
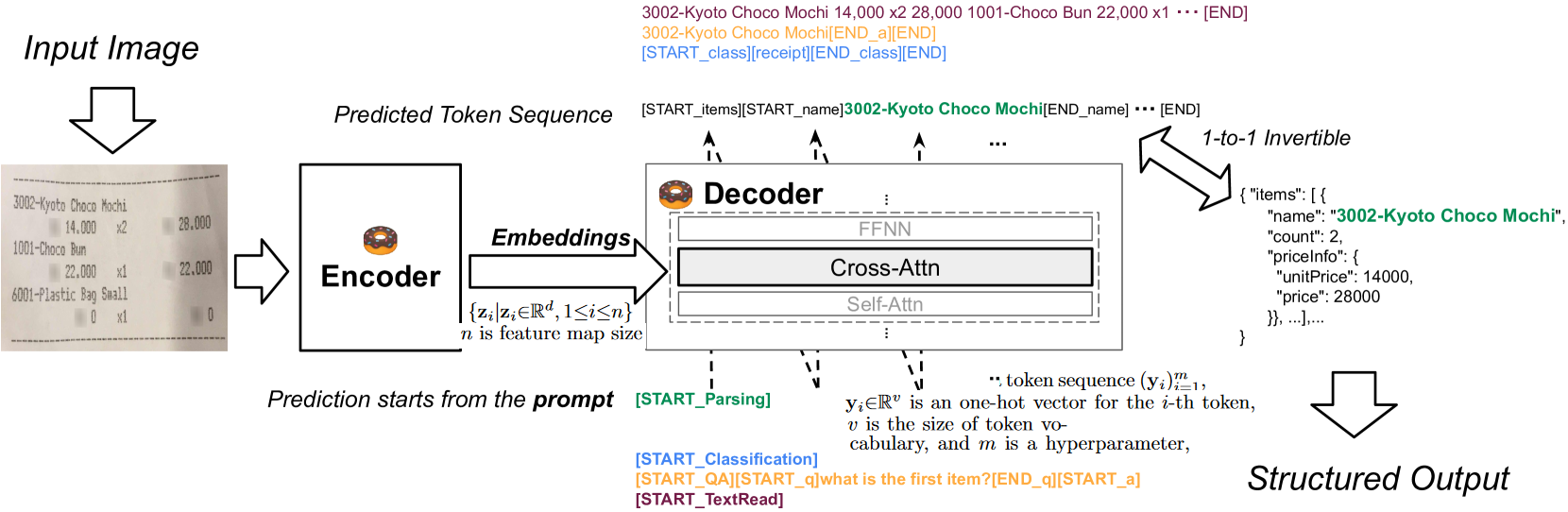
- Encoder
- SwinTransformerを使用
- Inputは画像で、Outputはパッチ単位のEmbedding
- Decoder
- BARTを使用
- Outputはトークン列のOne-hotベクトル
- 疑問点:単語単位のOne-hotベクトルを出している?
- BARTの最初の4層を使用
- 疑問点:最初の層を使用するとどういう表現が得られる?
- モデルの入力
- 「What is the first name」のようなプロンプトを入力し、それに対する出力を得る
- モデルの出力
- JSONを出力する
- [START_∗]、[END_∗]のトークンを各フィールドにつける
事前学習
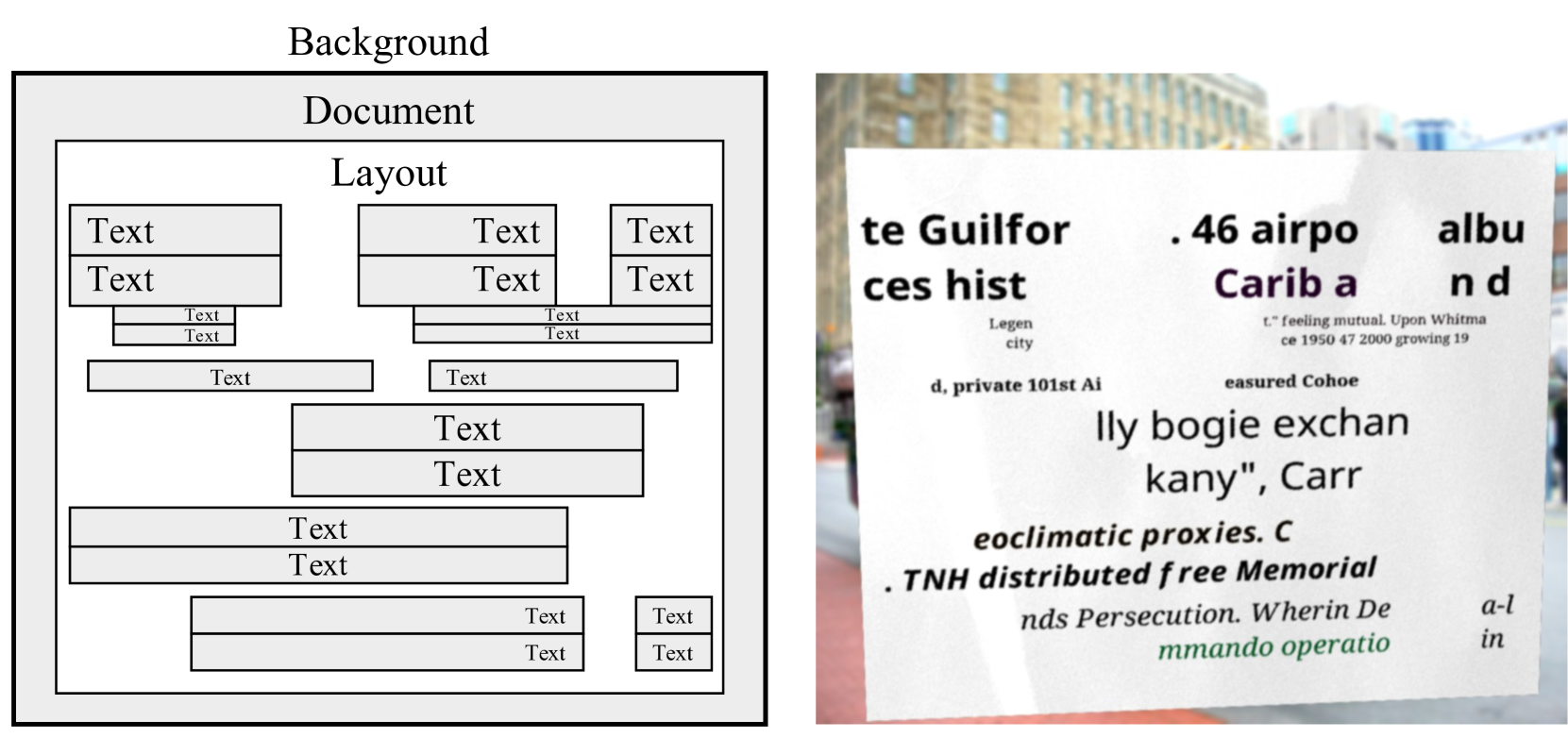

- SynthDoGという合成文章生成器を提案した
- 大規模な実文章画像は、英語以外では利用が難しいから
- 背景、文書、テキスト、レイアウトからなる
- 背景:ImageNetからサンプリング
- 文章・テキスト:
- 文章のテクスチャ(フォントやスタイル)は実際の画像からサンプリング
- 単語とフレーズは、Wikipediaからサンプリング
- レイアウトは実際の文章を模倣するランダムなルールーベースのものを作った
- 1.2Mの合成文書画像を生成
- 英語、韓国語、日本語のWikipediaから抽出したコーパスを用い、1言語あたり40万枚の画像を生成
- JSON解釈問題として応用可能
- デコーダはJSON{“class”: “memo”}に1対1で反転可能
- これは[memo]のような特殊なトークンで実践
結果
定量評価
Donut(End-to-End)のほうが、従来のOCRベース手法より良かった
RVL-CDIP:画像から文章の分類問題を行うデータセット
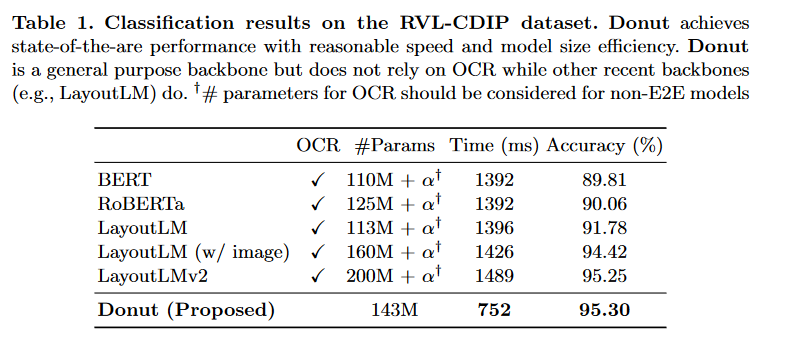
データの種類
- CORD:The Consolidated Receipt Dataset。ラテンアルファベットからなる公開データセット。1万枚
- Ticket:公開データセット。中国語のチケット。1900枚。
- Japanese Business Cards:日本語の名刺のデータセット。2.6万枚。実運用されているクローズドデータ
- Korean Receipts:韓国語のレシートのデータ。4.2万枚。実運用されているクローズドなデータ
モデル構造や事前学習
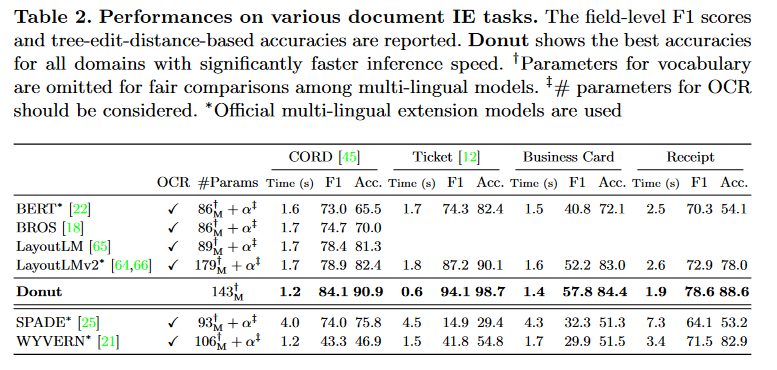
- 事前学習の戦略
- 分類やキャプション問題による事前学習はほぼ意味をなさない
- 実データ(CORD)による訓練が最良であるが、これは英語以外へのスケールが困難
- 合成データSynthDoGによる手法は、実データに迫る精度を出せた
- バックボーン
- CNNよりSwin Transformerのほうが良かった
- 解像度
- 文字が潰れない程度の解像度があればよさそう
クラウドサービスのOCR手法との比較
LayoutLMv2やBERTのようなOCRベースの手法は、OCRのエンジンによって大きく左右される。DonutはEnd-to-Endなので、そのような問題はなく、一貫してそれらよりよい結果となった
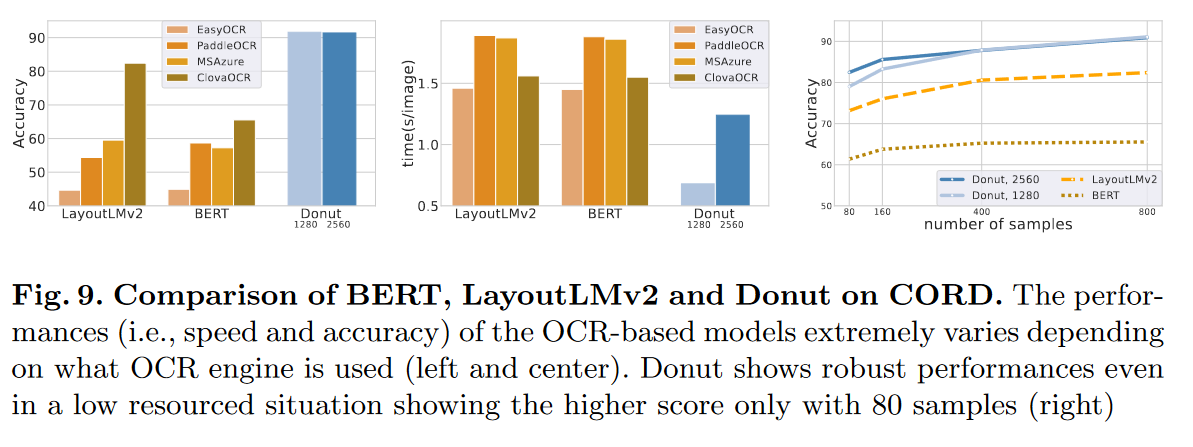
メモ
- End-to-Endでできるのは泥臭い作業が減って良さそう
- 合成データで訓練していい結果できるの面白い(サンスクリット語のOCRとかできそう)
- Pretrainの計算量がやばい
donut-base: trained with 64 A100 GPUs (\~2.5 days), number of layers (encoder: {2,2,14,2}, decoder: 4), input size 2560×1920, swin window size 10, IIT-CDIP (11M) and SynthDoG (English, Chinese, Japanese, Korean, 0.5M x 4).
donut-proto: (preliminary model) trained with 8 V100 GPUs (~5 days), number of layers (encoder: {2,2,18,2}, decoder: 4), input size 2048×1536, swin window size 8, and SynthDoG (English, Japanese, Korean, 0.4M x 3).
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー