
transformersのTrainerでCLIPにLoRAを適用して訓練する


HuggingFaceの提供しているpeftを使うと、LoRAが簡単に訓練できますが、transformersのTrainerベースでの訓練であり、画像分類でどうやるのかがよくわかりませんでした。とりあえず動かすことができたので自分用メモにおいておきます。
目次
やりたいこと
- CLIPのText EncoderとImage EncoderにLoRAを適用して、画像分類を訓練
- 分類方式は画像の特徴量だけとってLinear Probe的なことではなく、画像特徴量とテキスト特徴量のドット積であるゼロショットベースの拡張。
- 扱うデータセットは、CLIPのゼロショットが苦手なFGVCAircraft
参考記事
transformersの公式記事はなぜか日本語版のほうが詳しい(2024/2/25)。英語だとどの関数をオーバーライドすればいいとか出てなかったし
- 日本語版:https://huggingface.co/docs/transformers/ja/main_classes/trainer
- 英語版:https://huggingface.co/docs/transformers/main/en/main_classes/trainer
- huggingfaceのTrainerクラスを使えばFineTuningの学習コードがスッキリ書けてめちゃくちゃ便利です
コード
GPUが2枚あって1枚だけ使う場合のコード。transformersのデフォルトのTrainerをCLIPみたいなマルチモーダルのケースに対応させるのがちょっと大変で、カスタムのTrainerをオーバーライドして作ってしまった。
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
import torch
from torch import nn
from torchvision import datasets
from transformers import CLIPModel, CLIPProcessor, Trainer, TrainingArguments
from torch.utils.data import Dataset, DataLoader
from peft import LoraConfig, get_peft_model
from sklearn.metrics import accuracy_score
class AircraftDataset(Dataset):
def __init__(self, data_dir, split="train"):
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
self.dataset = datasets.FGVCAircraft(root=data_dir, download=True, split=split, transform=self.clip_transform)
class_name_path = os.path.join(data_dir, "fgvc-aircraft-2013b", "data", "variants.txt")
with open(class_name_path, "r") as fp:
self.class_names = [line.strip() for line in fp.read().splitlines()]
def clip_transform(self, image):
return self.processor(images=image, return_tensors="pt").pixel_values.squeeze(0)
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
image, label = self.dataset[idx]
return {"pixel_values": image, "labels": label}
class CLIPwithLoRATrainer(Trainer):
def __init__(self, class_names, *args, **kwargs):
super().__init__(*args, **kwargs)
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
self.criterion = nn.CrossEntropyLoss()
self.class_names = class_names
self.text_inputs = self.processor(text=self.class_names, return_tensors="pt", padding=True)
self.train_loader = DataLoader(self.train_dataset, batch_size=self.args.train_batch_size, shuffle=True, num_workers=4)
self.val_loader = DataLoader(self.eval_dataset, batch_size=self.args.eval_batch_size, num_workers=4)
def compute_loss(self, model, inputs, return_outputs=False):
text_inputs = {k: v.to(self.args.device) for k, v in self.text_inputs.items()}
inputs = {k: v.to(self.args.device) for k, v in inputs.items()}
multimodal_inputs = {**text_inputs, "pixel_values":inputs["pixel_values"]}
outputs = model(**multimodal_inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
loss = self.criterion(logits_per_image, inputs["labels"])
return (loss, logits_per_image) if return_outputs else loss
def training_step(self, model, inputs):
model.train()
self.optimizer.zero_grad()
loss, outputs = self.compute_loss(model, inputs, return_outputs=True)
loss.backward()
self.optimizer.step()
return loss
def prediction_step(self, model, inputs, prediction_loss_only, ignore_keys):
model.eval()
with torch.no_grad():
loss, outputs = self.compute_loss(model, inputs, return_outputs=True)
return loss, outputs, inputs["labels"]
def get_train_dataloader(self) -> DataLoader:
return self.train_loader
def get_eval_dataloader(self, eval_dataset=None) -> DataLoader:
return self.val_loader
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
accuracy = accuracy_score(labels, preds)
return {"accuracy": accuracy}
def main():
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
lora_config = LoraConfig(
r=64,
lora_alpha=64,
target_modules=["k_proj", "v_proj", "q_proj", "out_proj"],
lora_dropout=0.1,
bias="none",
modules_to_save=["classifier"],
)
lora_model = get_peft_model(clip_model, lora_config)
lora_model.print_trainable_parameters()
train_dataset = AircraftDataset(data_dir="./data", split="train")
val_dataset = AircraftDataset(data_dir="./data", split="val")
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=10,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
warmup_steps=100,
learning_rate=1e-4,
logging_dir="./logs",
logging_steps=10,
evaluation_strategy="epoch"
)
trainer = CLIPwithLoRATrainer(
class_names=train_dataset.class_names,
model=lora_model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics
)
trainer.train()
if __name__ == "__main__":
main()
このコードのちょっといけてない点
- DataLoaderまでカスタムで定義したせいか、Train→Valの間で毎回DataLoaderを読みにいっていてちょっと遅い(Windowsの場合)
ただ良い点は、transformersのTrainerで訓練すると、LoRAの部分だけ保存してくれるところ。見ての通り、保存されたsafetensorsは30MB程度で、元のCLIPは6-700MBぐらいある。似たコードはPyTorch lightningでも書けるが、PyTorch lightningの場合は、デフォルトだと元のCLIPごと保存してしまうのでLoRAの良さがなくなる。係数の保存部分だけ引っ張ってきたら、PyTorch lightningでもいけるかもしれない。
また、デフォルトでWarmup+Decayがついてきており、スケジューラーの設定がめんどうくないのが良い。
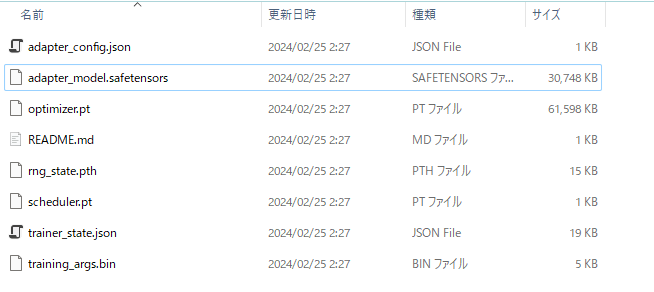
書き方はPyTorch lightningとやや似ているが、training_stepの部分にPyTorchネイティブな書き方がいたり、微妙に取り回しが異なる。
最終的な精度はこんな感じ。varient(100クラス)で、ゼロショット性を維持しつつ55%近いのはなかなか。
{'eval_loss': 2.248544216156006, 'eval_accuracy': 0.5481548154815482, 'eval_runtime': 40.2014, 'eval_samples_per_second': 82.908, 'eval_steps_per_second': 2.612, 'epoch': 10.0}
補足:PyTorch lightningでもいけそう
以下のようにしてみたら、LoRAの部分だけ保存できた。LoRAのconfigもついてくる。
lora_model = get_peft_model(clip_model, lora_config)
lora_model.save_pretrained("lora_model")
{
"auto_mapping": {
"base_model_class": "CLIPModel",
"parent_library": "transformers.models.clip.modeling_clip"
},
"base_model_name_or_path": "openai/clip-vit-base-patch32",
"bias": "none",
"fan_in_fan_out": false,
"inference_mode": true,
"init_lora_weights": true,
"layers_pattern": null,
"layers_to_transform": null,
"lora_alpha": 64,
"lora_dropout": 0.1,
"modules_to_save": [
"classifier"
],
"peft_type": "LORA",
"r": 64,
"revision": null,
"target_modules": [
"k_proj",
"v_proj",
"q_proj",
"out_proj"
],
"task_type": null
}
transformersとlightningで全然ユースケースが違うだろうけど、個人的にはlightningの書き方のほうが好きかな。多分ここまでカスタマイズして書いてしまうなら、lightningのほうが良さそう。LLM訓練するときはtransformers良さそうね(それはそう)
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー