
論文まとめ:GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis
Posted On 2023-06-22


- タイトル:GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis
- 著者:Ming Tao, Bing-Kun Bao, Hao Tang, Changsheng Xu(南京郵電大学、鵬城実験室など)
- カンファ:CVPR 2023
- 論文URL:https://arxiv.org/abs/2301.12959
- コード:https://github.com/tobran/GALIP
目次
ざっくりいうと
- 訓練済みCLIPを活用したGANベースの新たな画像生成のフレームワーク
- プロンプトチューニングに触発され、Meta-D/Gという追加のレイヤーを画像エンコーダーに結合
- 拡散モデルよりも120倍高速に生成可能で、必要な訓練リソースも少ないながら、Latent Diffusionと同程度の生成品質を達成
GANとは
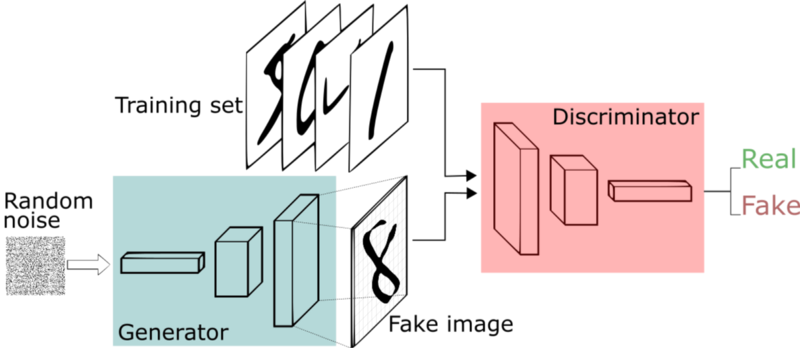
イントロ
- 拡散モデルの問題
- 事前学習に膨大なデータとパラメーターが必要
- GANと比べて遅い。ノイズ除去に何百もの推論ステップがある
- GAN(のInterpolationの)ような滑らかな潜在空間は存在せず、視覚表現を潜在ベクトルにマッピングする
- 意味空間が散乱しており、合成プロセスを制御するために巧妙に設計されたプロンプトが必要
- GANを再考したいが、デメリットがある
- 学習の不安定さ
- 生成の多様性の低さ。複雑なシーンで満足のいく合成結果が得られていない
- GANにCLIPを適用する。CLIPを導入するメリット
- 複雑なシーンの理解力の向上
- ViTの画像エンコーダーは有益な視覚表現を抽出することができる
(現在のStable DiffusionはCLIPを使っているものの、Image Encoderはなくても成立するので、この特徴抽出能力に着目しているのが良い)
- ViTの画像エンコーダーは有益な視覚表現を抽出することができる
- 写真、図面、漫画など汎用ドメインのゼロショット転移能力
- 複雑なシーンの理解力の向上
- 本手法の特徴
- Mate-D
- 固定のCLIPの画像エンコーダーと、学習可能なMate-D(Mate Discriminator)からなる
- Mate-Dの役割:合成画像と実画像を区別するために、収集されたCLIP特徴から有益な視覚的特徴を抽出
- Mate-G
- CLIP-empowered Generator:固定のCLIPの画像エンコーダーと、学習可能なMate-G(Mate Generator)からなる
- 発想はプロンプトチューニングに近く、Mate-Gの役割はCLIPと生成画像の間の、暗黙なブリッジ特徴の予測で、ギャップを埋めること
- 従来の手法だと、スケッチやレイアウトをガイドに入れるものがあったが、そういったタスクスペシフィックなことをせずCLIPを特徴に全て任せる
- Mate-D
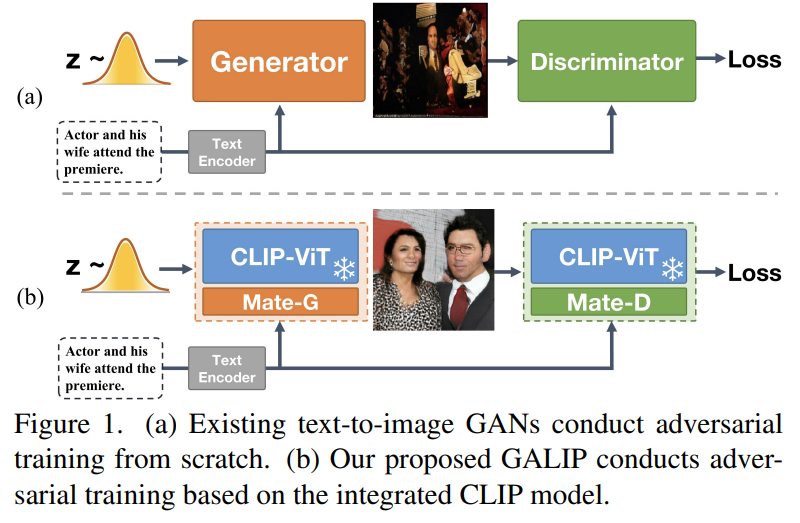
CLIPとGANを組み合わせるアプローチは前からあったが、ほぼバニラからの訓練か、StyleGANのように訓練済みのモデルを使うことが大半だった。固定の画像エンコーダー+追加の学習パラメーターという、プロンプトチューニング(PEFT)にインスパイアされたアプローチを組み込むことで、画像生成の効率化を図ったというのが、この手法の大きな新規性。CLIPの画像エンコーダーに焦点を当てたのも大きい。
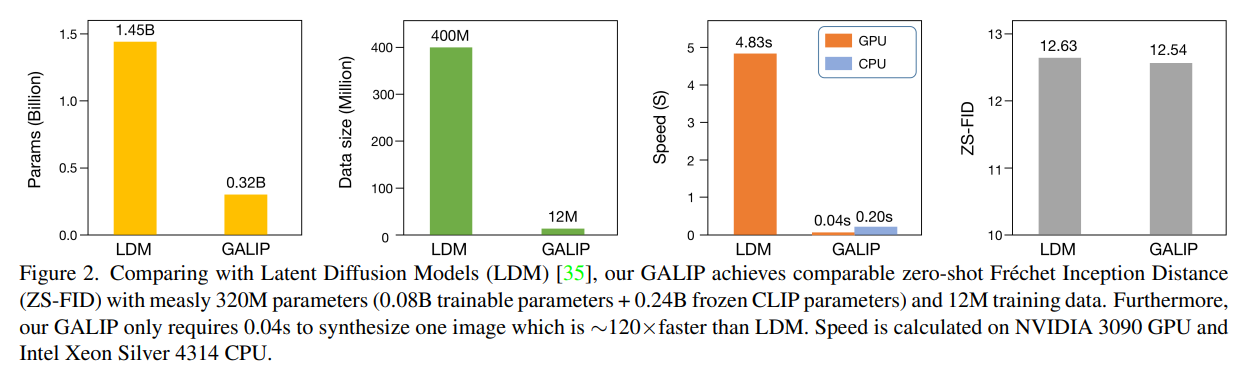
- その結果どうなったの?
- 訓練パラメーター数や必要なデータ数が大幅削減された
- 訓練は最低RTX 3090 1枚~でよく、推論はCPUでも0.20sになった
- それにも関わらず、Latent Diffusionと同じ生成品質を達成
プロンプトチューニングとは
学習可能なトークンを導入し、下流タスクに最適化する方法。手動のプロンプトエンジニアリングの必要性を軽減。
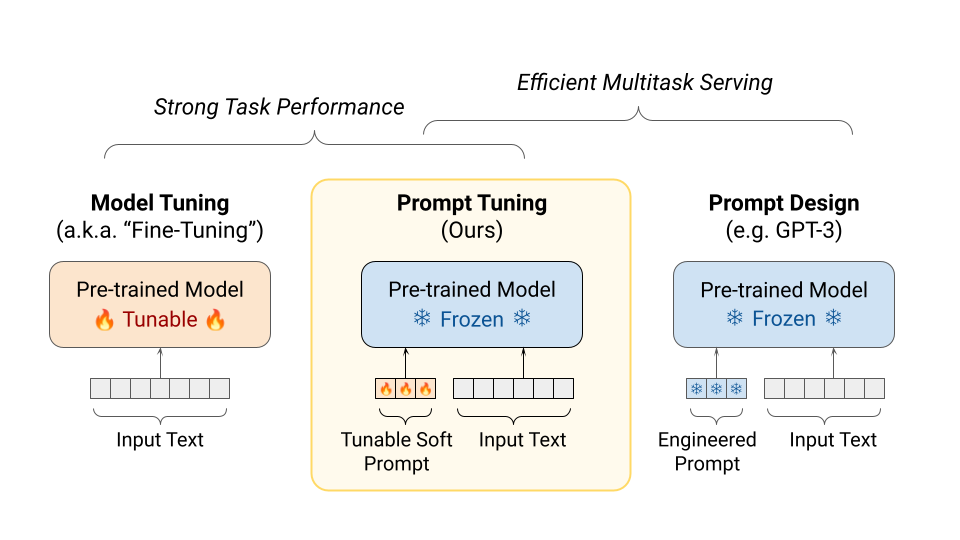
https://ai.googleblog.com/2022/02/guiding-frozen-language-models-with.html
敵対的生成CLIP(手法)
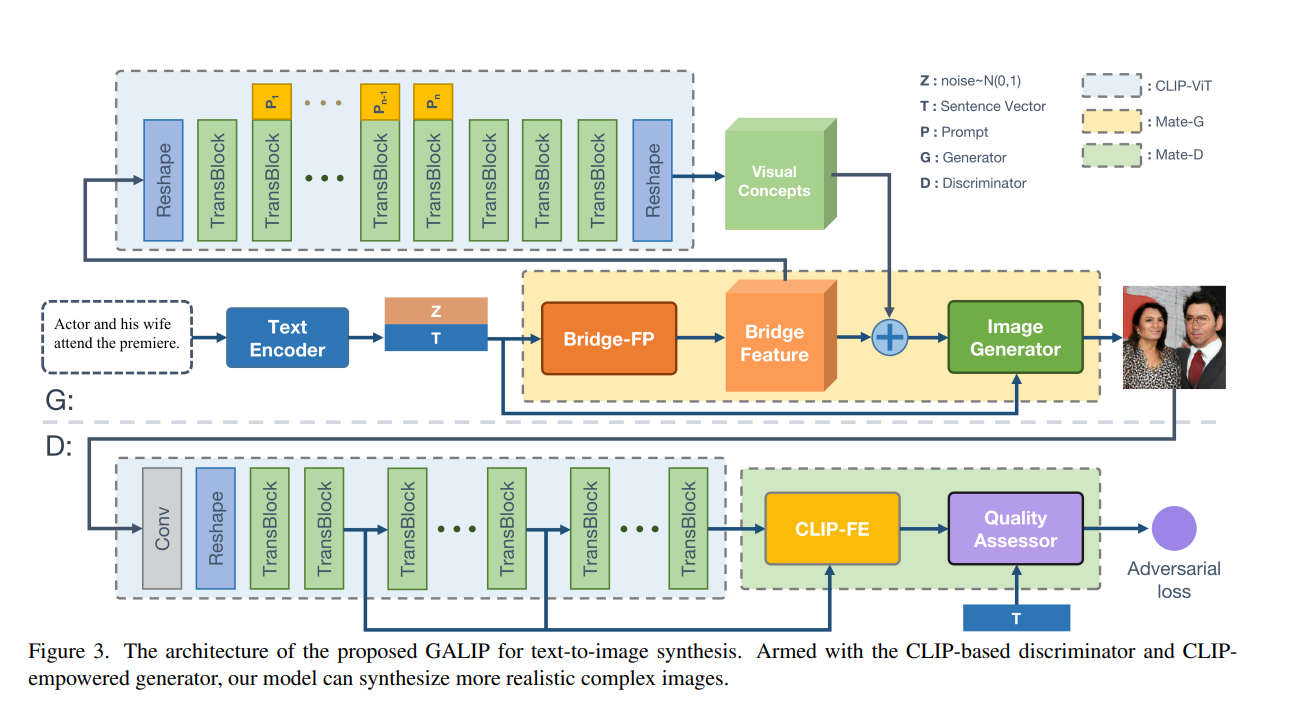
- 生成(G)側
- Text Encoderの出力にノイズを付与し、Bridge-FPでマッピング(Bridge Feature)
- Bridge FeatureをCLIPのViT(画像エンコーダー)に入れてVisual Comceptをゲット。それを足し合わせる
- なぜこんな単純なフレームワークでうまくいくの?:CLIPはもともとテキストと画像がアラインメントされているから
- 識別(D)側
- 生成画像をCLLIPのViTに通し、CLIP Featureを識別するという普通のやり方。中間層(2、5、9層)の値も考慮
- 収集されたCLIP特徴量と対応するテキスト特徴量に対して、マッチング考慮勾配ペナルティ(MAGP)を導入。これは先行研究ベース
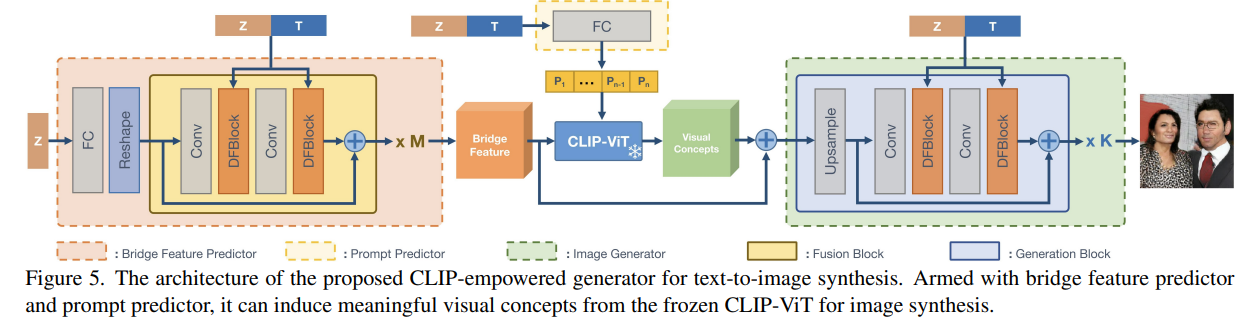
- Brideg Freature PredictorとImage Generatorの構造(G側)
- 「ノイズ+Text Embedding」を随所にアフィン変換として挿入
- 損失関数。昔なつかしのGANの損失関数。Gradient Penaltyが入っている

実験と結果
データセット
- CUB bird、COCO、CC3M、CC12Mで実験
- 8×3090で、CUBに0.5日、COCOに1.5日、COCO3Mは2日、CC12Mは3日
FID

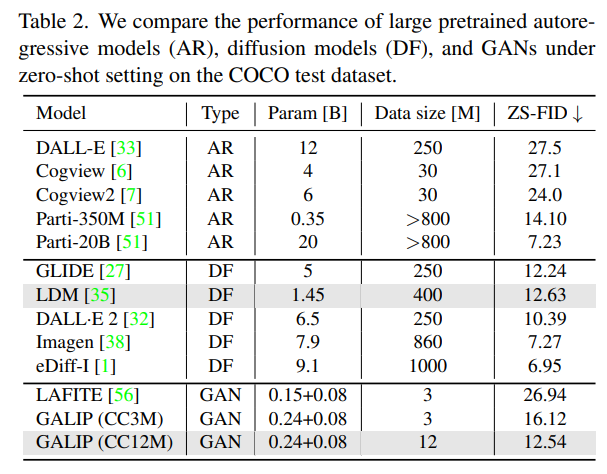
インドメインの設定を見ても面白くないのでゼロショットの設定で
- Latent Diffusion(≠Stable Diffusion)と同程度の生成クォリティ(FID)だが、パラメーター(1.45B vs 0.32B)やデータ数(400M vs 12M)が明らかに少ない
- (所感)直感的にはDALL-E 2からImagenの間にかなり大きなクォリティギャップがあり、Stable Diffusionはこの間に位置しているため、DALL-E 2の壁を越えてこられればかなり実用的になってくる
- クォリティの強化が今後の課題
内挿が可能

- GANで得意だったスタイルの内挿(Interpolation)が可能
- 4つの同じプロンプトから生成された画像に対し、スタイルを補間し、新たなスタイルを形成
- ノイズの補間
提案手法の効果
用語の説明
* CD : CLIP-based D / CG : CLIP-empowered G
* CLIP-empowered Gの中の構造
* BFP : Bridge Feature Predictor
* PP : Prompt Predictor
* CLIP-based D
* CFE : CLIP-FE(CLIP Feature Extractor)
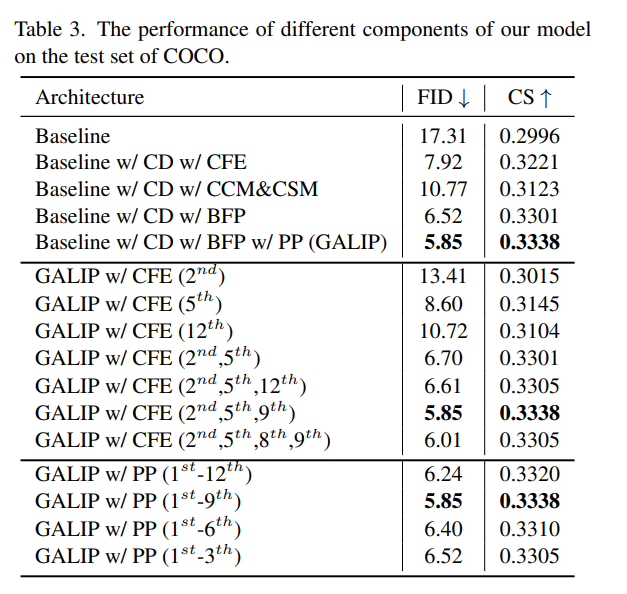
- 特に効いているのがDのCLIPの特徴抽出
- G側の特徴抽出(PP)もある程度効いている
- (所感)全般的にCLIPの深い層の特徴を使うと悪化するというのは、Stable DiffusionのCLIP-Skipと同じ話
失敗例

- 現実には存在しない例ではいくつか失敗
- 対策:モデルサイズを大きくする、データサイズを大きくする
- モデルサイズを大きくする→T5を使う
- データサイズを大きくする→現在は大規模な画像モデルよりは遥かに少ない設定だからある程度仕方ない
- 今後の研究でやるらしいので期待
所感
- GAN復権の流れがくるかもしれない
- Stable DiffusionはCLIPの画像エンコーダーを全然使っていなく「これCLIPじゃなくてもよくない?」とすごくモヤモヤしていたので、画像エンコーダーに焦点を当ててプロンプトチューニングの流れを組み込んだのはお見事
- 経験的にはこのようなGANは崩壊しにくいのが理解できるが、学習データの分布再現の点からは理論的に拡散モデルのほうが優れているので、この点はどうなのだろうか?
- ライセンスファイルはMITと書いているのに「商用利用はコンタクトしてくれ」と書いてあるのはどうなんだろうか?
- コンタクトで難儀しているらしい😂 https://github.com/tobran/GALIP/issues/1
- T5ベースのGALIPができたら、ぜひMITとかCreativeML Open RAIL-Mとかフリーなライセンスで公開して
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー