
論文まとめ:Gemini: A Family of Highly Capable Multimodal Models
Posted On 2024-01-18


- タイトル:Gemini: A Family of Highly Capable Multimodal Models
- 著者:Gemini Team((842 additional authors not shown)と書かれる状態)
- 論文URL:https://arxiv.org/abs/2312.11805
- 記事:https://japan.googleblog.com/2023/12/gemini.html
目次
ざっくりいうと
- Googleが開発したマルチモーダルLLMの「Gemini」の論文
- 文章、音声、映像、画像をすべて1個のTransformerに入れて、テキストと画像を生成可能なモデル
- Ultra、Pro、Nanoのサイズがあり、UltraはGPT-4を一部超えている。Nanoはモバイル特化。UltraはTPUを使い大規模な訓練を実施

著者の人数でギネス記録狙えるんじゃね?ってぐらいの多さ→上がいるらしい
できること
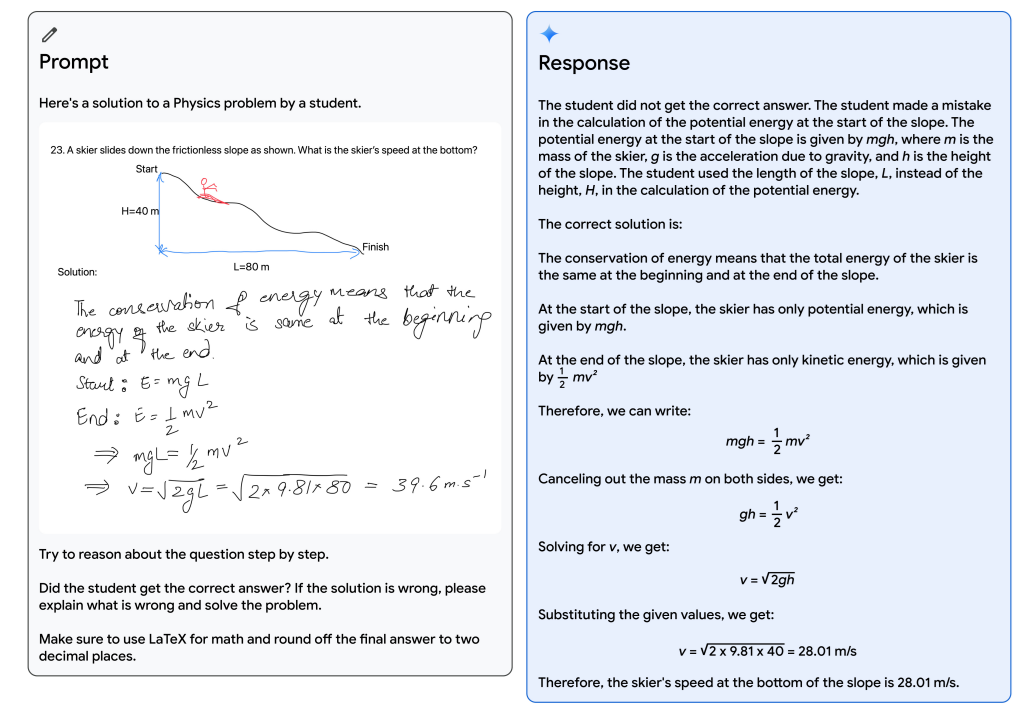
物理の問題に対して、生徒の答案の間違っている部分を指摘することができる
手法
モデルの種類
Gemini 1.0は3サイズに分かれる。コンテクストウィンドウは32k。
- Ultra:複雑なタスク。TPUでスケールアップして効率的にデプロイ
- Pro:拡張されたパフォーマンスと大規模での展開性
- Nano:オンデバイスアプリケーション。1.8B(Nano-1)と3.25B(Nano-2)があり、4ビット量子化

アーキテクチャ
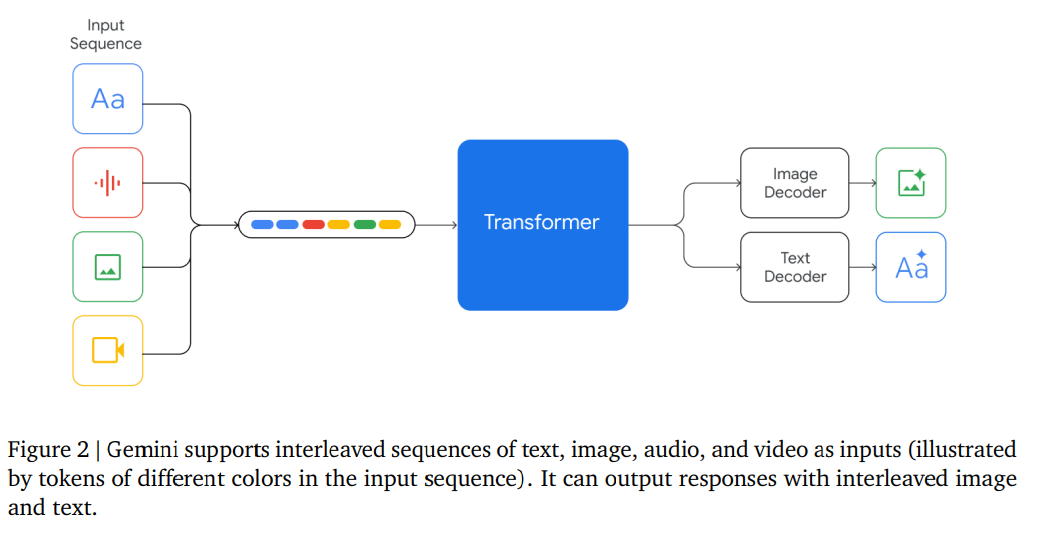
- なんでもかんでもTransformerに突っ込む方式
- Visual EncodingはFalmingoやCoCa、PaLIに触発された
- 音声はUniversal Speech Modelを使う
学習インフラ
- TPUv5eとTPUv4を使用して学習
- Gemini Ultraでは複数のデータセンターを使い、TPUv4を使用
- PaLM-2より規模が大幅に拡大
- TPUのハードウェア障害に対する学習フローの対策が考案されている
学習データ
- 事前学習:ウェブ文書、書籍、コードからのデータを使用し、画像、音声、ビデオデータを含む
- 訓練コーパス全体の大きなサンプルでトークナイザーを訓練すると、推論された語彙が改善され、モデルの性能が向上する
性能
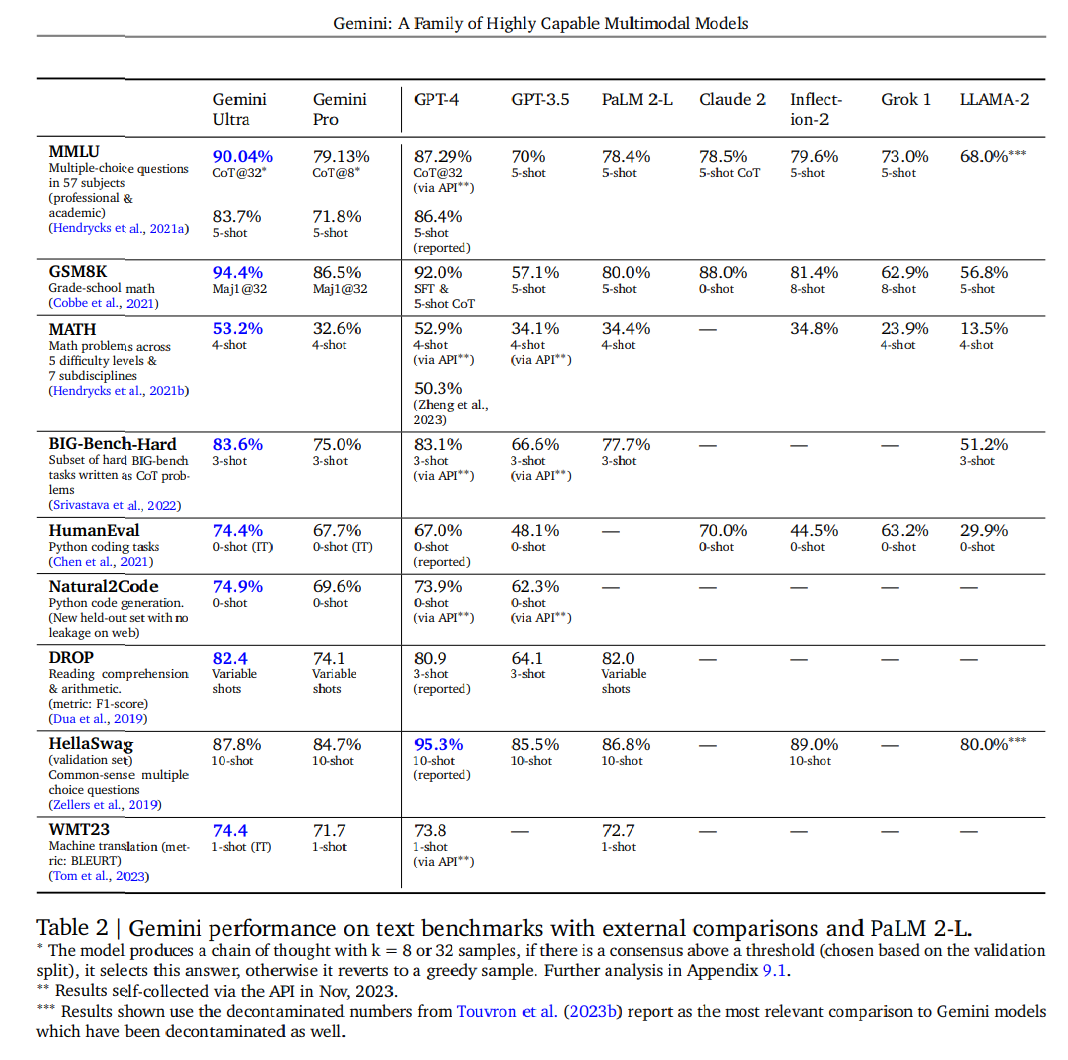
- GPTは
gpt-4-0613を使用
ケイパビリティのトレンド
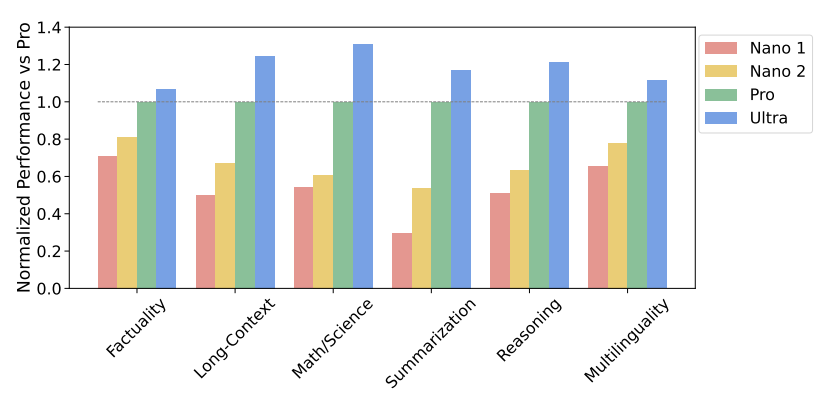
- 「Factuality」: オープン/クローズドブック検索と質問応答タスクをカバー
- 「Long-Context」:長文要約、検索、質問応答タスクをカバー
- 「Math/Science」数学的問題解決、定理証明、科学試験を含む
- 「Reasoning」:算術、科学、常識推論を要する
- 「Multilingual」:多言語翻訳、要約、推論を担当する
多言語性
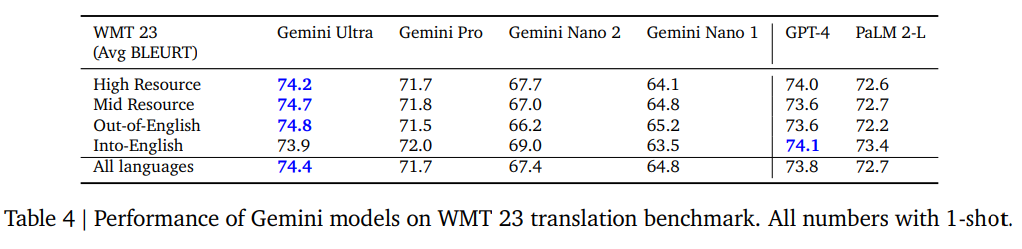
1ショットのAvg BLEURT。Nano2とProの差はそこまで大きくない(翻訳はオンデバイスで動く)。ただUltraでもGPT-4に毛が生えた程度。
マルチモーダル
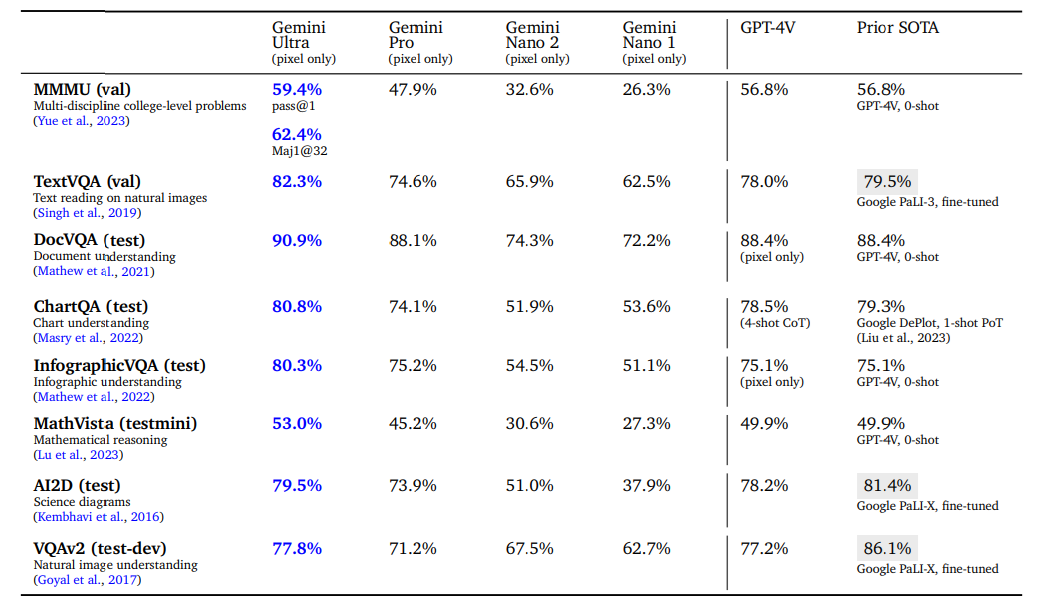
ProだとGPT-4Vより劣る程度。VQAは小さいモデルでもある程度うまくいくが、グラフの読み取りに対するQAは大きいモデルが必要。
動画
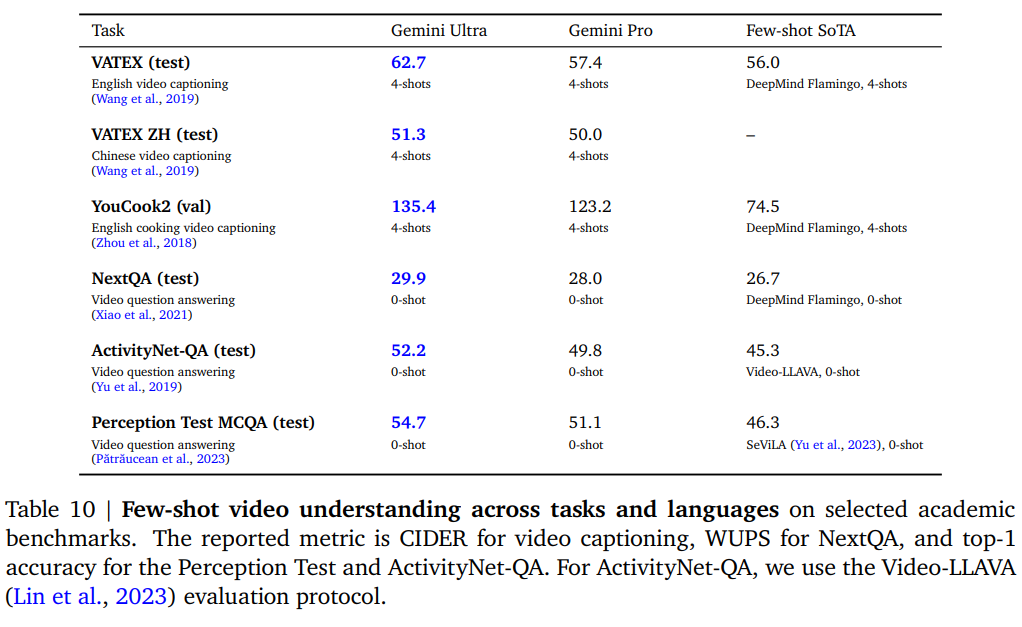
VideoLLaVAより良いと言われてもなんともいえない(VideoLLaVAは速いがそこまで精度高いものではない)。GPT-4Vと比較してほしい
画像生成
対話型ならGILL、同じGoogle製でもImagenと評価してほしかった

責任あるデプロイ
基本的にGoogleの大本営発表なので、飛ばし飛ばしだが興味ある範囲で
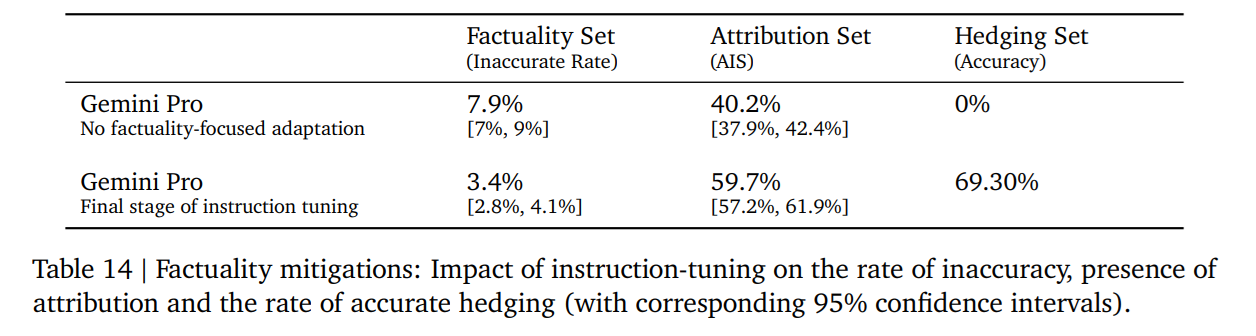
ハルシネーションを減らす取り組み
3つの望ましい行動にインストラクションチューニング
- Attribution:プロンプト内の与えられたコンテキストに完全に帰属させるべき応答を生成す
るように指示された場合、Geminiはコンテキストに最も忠実な応答を生成すべきである。ソースの要約、質問の引用生成の場合 - Closed-Book Response Generation:ソースがない事実探索プロンプトが提供された場合、ハルシネーションで答えてはいけない。例:「インドの首相は誰ですか?」という場合
- Hedge:入力が「答えられない」ようなプロンプトの場合は、応答を提供できないことを認識させる
3種類の行動に対応するような教師あり学習のデータセットを作り、RLHFすることで望ましい動作を引き出した
- メンバーリストで12P
- 引用が11P
付表
テキトーに抜粋
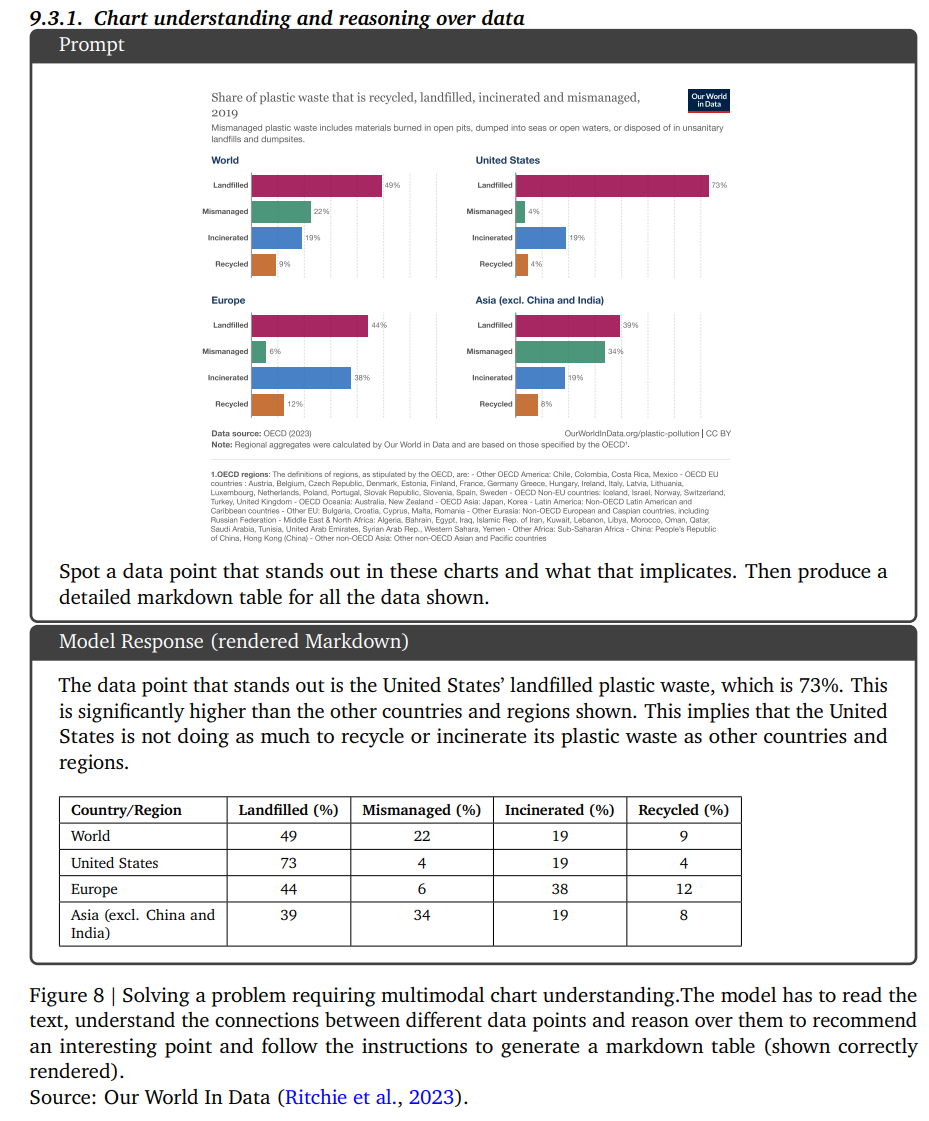
グラフの読み取り
英語にならできそう(ProなのかUltraなのか不明)
多言語設定でのCommonsense reasoning

映像の理解と推論
この人はどうやって技術を向上させることができるでしょうか?

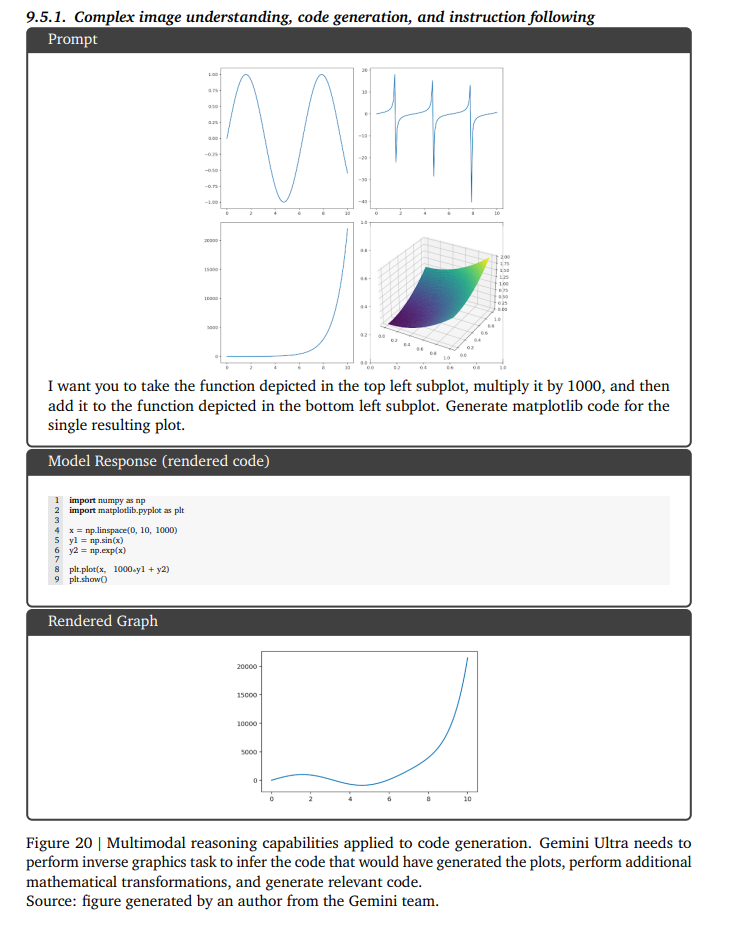
複雑な画像理解、コード生成、命令追従
左上のサブプロットに描かれている関数に1000を掛けて、左下のサブプロットに描かれている
関数に追加してください。結果の単一のプロットに対して、matplotlib コードを生成します
所感
- GPT-4Vとの比較は特に動画や画像生成部分でぼかされていて怪しい部分が多い
- GPT-4Vとの大きな違いが、同じTransformer内で画像生成できるという点。これは試してみないとわからない
- モデルサイズの比較が面白くて、MultilingualとFactualityはモデルサイズを下げてもそこまで極端には悪化しないというのが意外。要約は結構モデルサイズいるのもちょっと意外。
- FlamingoがGPT-3をマルチモーダルに正攻法で拡張するやり方(EmbeddingのProjectionではなく、トークンに変換)だったので、Falmingoの拡張で攻めてきたのが面白い
- TPUのインフラ周りの話がちょろっと出ていたのが面白い
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー