
論文まとめ:Generating Images with Multimodal Language Models
Posted On 2023-09-28


- タイトル:Generating Images with Multimodal Language Models
- 著者:Jing Yu Koh, Daniel Fried, Ruslan Salakhutdinov
- 論文URL:https://arxiv.org/abs/2305.17216
- コード:https://github.com/kohjingyu/gill (Apache 2.0)
- カンファ:NeurIPS 2023
- デモ:https://huggingface.co/spaces/jykoh/gill
目次
ざっくりいうと
- マルチモーダルLLMと画像生成モデルに、線形レイヤーをくっつけてプロンプトチューニングと蒸留学習のアプローチを取り入れた
- 先行研究のFROMAGeだと画像検索しかできなかったが、画像生成と検索を両方対応しているのが新規性
- 対話や画像の枚数が多くなったときに、より一貫性のある画像生成ができるようになった
はじめに
- 提案手法:大規模言語モデルによる画像生成(GILL)
- 対話ベースの画像とテキストの入力を処理し、テキストを生成、画像を検索、画像を生成することが可能
- 我々の発見は、両方のモデルが異なるテキストエンコーダを使用しているにもかかわらず、凍結テキストされたLLMの出力埋め込み空間を凍結生成モデル(本研究ではStable Diffusion [43])の出力埋め込み空間に効率的にマッピング可能
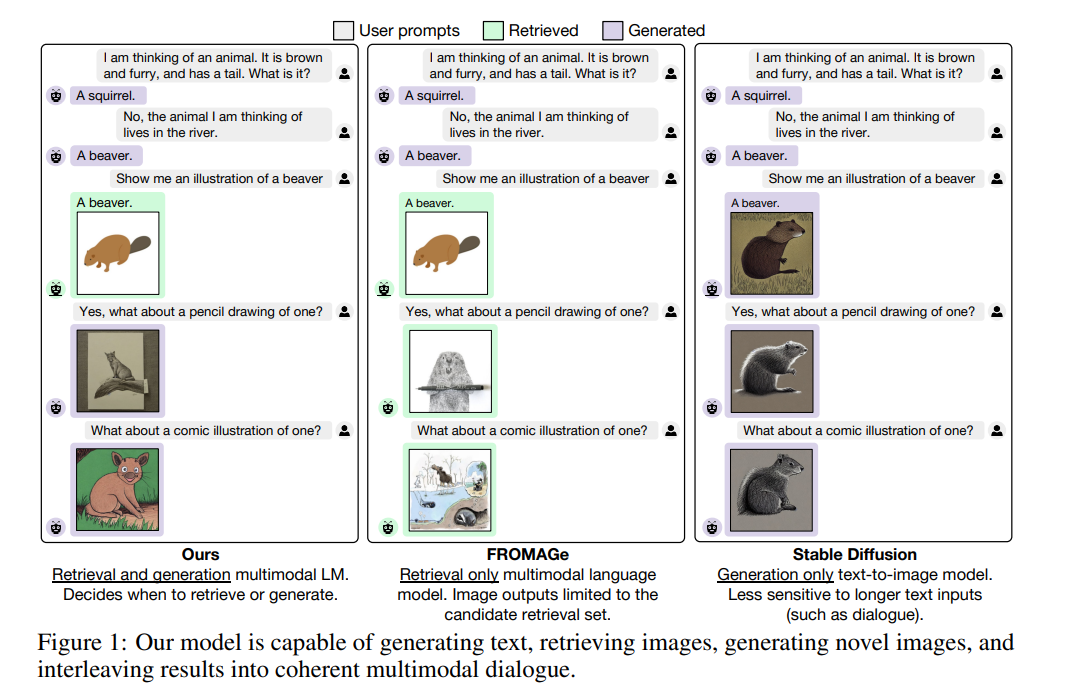
- 画像-キャプションペアに対して少数のパラメータを微調整することでこれを実現。本手法は計算効率が高く、学習時に画像生成モデルを実行する必要がない
- 強力な画像生成を実現するためにGILLMapperモジュールを使用し、LLM-生成のマッピングを効率的に学習する
- GILLMapperは特別な学習済みテキストトークンを条件とする、軽量なTransformer
- LLMの出力と、画像生成モデルのテキストエンコーダーの出力のL2距離を最小化するように訓練(蒸留学習)
背景
- マルチモーダル言語モデルは学習コストが大きい
- Flamingoは1535TPUで15日、RA-CM3は256GPUで5日
- GILLの場合2GPUで2日学習できる
- 似たアプローチは先行研究のFROMAGe
- FROMAGeの場合検索しかできないが、GILLは検索と生成ができる
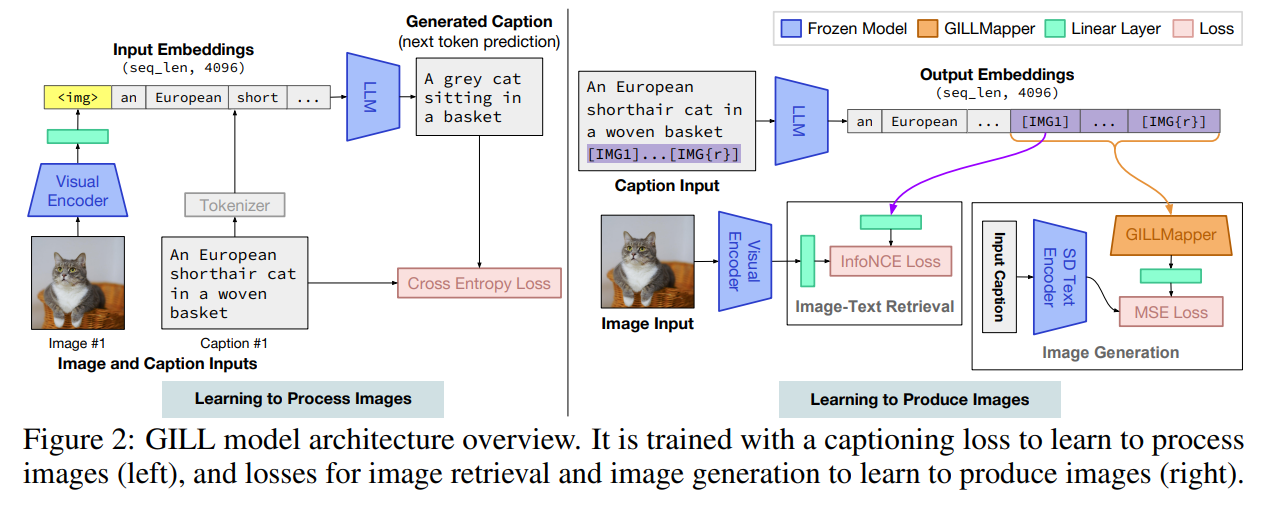
学習方法
2段階からなる
- Learning to Process Images(画像を処理するための学習)
- Learning to Produce Images(画像を生み出すための学習)
Learning to Process Images
- 画像とテキストのマッピングを学習
- 学習するものは、Visual Encoderからの線形レイヤーの学習(トークン)
- LLMの出力と、教師データのキャプションのCross Entropy Lossが最小化されるように学習
- 直感的には、LLMのトークン埋め込み空間において、画像を埋め込みベクトルに変換するためのマッピングの学習
Learning to Produce Images
- モデルが画像を生み出せるようにするために、LLMの語尾に特別な[IMG]トークンを追加
- 検索または生成に使われる
- 先行研究では単一のトークンを用いているが、画像生成においてはきめ細かなテキスト情報が必要であることがこの研究でわかったので、r個のトークン[IMG1], …, [IMG{r}]を使用
- 画像生成のために、GILLMapperという軽量な(4層)Transformerを学習
- この目的は、LLMをの[IMG]トークンから、画像生成モデル(Stable Diffusion)のトークンに変換するため
- クエリの変換を学習するという点では、BLIP2と同じ
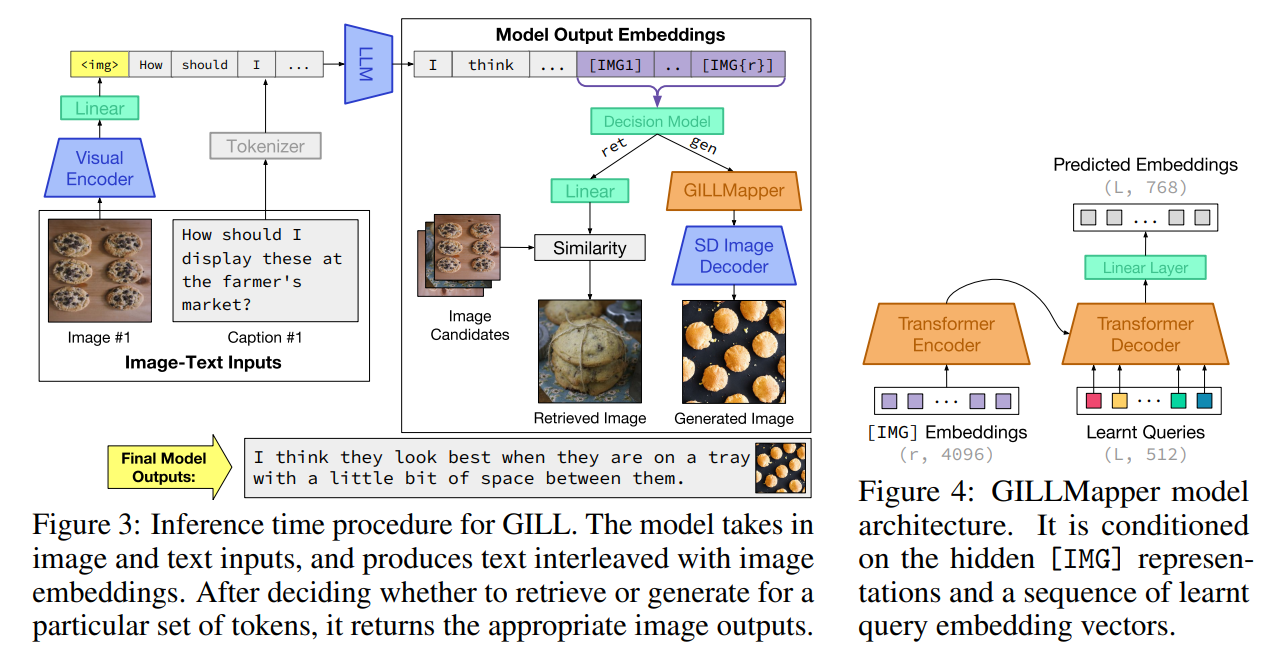
生成か検索かの決定
- 直感的には、与えられたプロンプトに対して強い一致画像があるときはそれを取り出し、そうでなければ生成する
- 検索された画像か、生成された画像かどっちがマッチしているかはアノテーターにデータセットを作らせた
- 決定(分類?)モデルを学習した
結果
定性評価

定量評価

- キャプションの数が多くなったときにGILLが有利になる。キャプションと画像が複数の場合も生成できるのはGILLの独自性
- 対話の場合は、ラウンド数(対話の回数)が多くなったときにGILLが強くなる
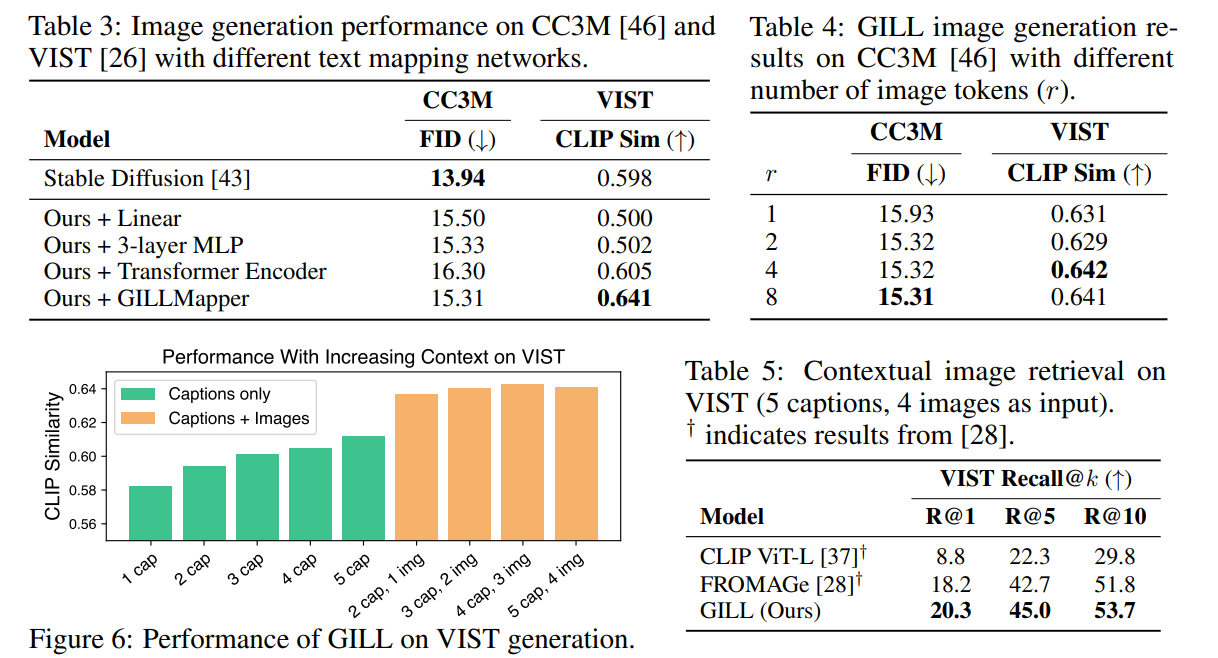
- 画像生成はStable Diffusionとほぼ同じか、単体は若干悪化するぐらい
- 検索性能はかなり向上している(FROMAGeより上、CLIPよりかは全然高い)
試してみた
- なかなか画像出してほしいタイミングとそうでないタイミングをいじれない
- 毎回画像出してほしいんだったら、ハマれば対話ベースでいけそう
- 上からのアングルにしてっていうと上空からの写真をとってきたり結構トンチっぽい挙動をするので対話がハマると楽しい
- ただ「この猫ちゃんをT-シャツにきた女性を出して」みたいにStable Diffusion自体が難しいケースだと難しそう
- これにLoRA入れたらどうなんだろう?
所感
- 発想は面白いし計算量の少なさもすごいが、ChatBot+画像生成+検索というのはテーマ的にまだまだ難しさはありそう
- どうせくっつけるのならFrozon-LLMと画像生成モデルをくっつけたら性能爆上がりしないのかな?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー