
HMAC(メッセージ認証)をAWS Lambdaで動かしたときのスループットを確かめる


API Gatewayなどに対してLambdaで認証をかける場合に、SHAベースのHMAC(メッセージ認証)のスループットを調べてみました。Lambdaのスペックを変えながら、ペイロードに対する認証のスループットやメモリ使用量を比較し、おおよそのスペック感を見ていきます。
目次
はじめに
特にプライベートAPIの実装などで、お手軽な認証方式としてメッセージ認証の一種であるHMACがよく使われることがあります。
「これをAWS Lambdaで動かしたときのスループットがどの程度のものか?」「認証部分のボトルネックがどの程度か?」を調べるのが本記事の目的です。認証周りはボトルネックになることが多いので。
想定
以下のような想定です。HMAC SHA-512を前提しています。
- API GatewayのLambdaオーソライザーで使用前提
- 使用するHMAC認証は、クライアントとサーバーに共通のAPIキーをおいておいて、クライアントからsaltを発行して、送信するデータに対してトークンを計算、それをデータと一緒にサーバーへ送るというものです
- クライアントで以下のように計算します
- ランダムなsaltを発行
- saltを共有鍵でハッシュ化し、誘導鍵を作る(SHA-512)
- 誘導鍵で、送信データをハッシュ化し、トークンを作る(SHA-512)
- クライアント→サーバーでは以下のものを送信
- salt
- トークン
- 送信データ
- サーバーでは、クライアントからの送信をベースに以下の計算をします
- クライアントからのsaltで共有鍵をハッシュ化し、誘導鍵を作る(SHA-512)
- 誘導鍵で、クライアントから受信したデータをハッシュ化し、復元トークンを作る(SHA-512)
- 復元トークンと、クライアントから送られてきたトークンが一致するかを計算し、一致しなければ弾く
- トークンの計算が送信データを条件としているので、これで認証かつ、改竄検知ができるというわけです
今回実装した認証は以下の記事の方法を参考にしています。
概念の実装
言葉で説明すると難しいのですが、実装はめっちゃ単純でPythonで数行レベルでOKです。クライアントとサーバーの実装を同時に書いてみます。
import hmac
import hashlib
import json
SECRET_KEY = "MySecretKey" # 実際はもっと複雑な値を使う
def client(content_obj):
# salt:ここでは決め打ちだが実際はランダムな値を使う
salt = "1234"
# 導出鍵
derived = hmac.new(SECRET_KEY.encode("utf-8"),
salt.encode("utf-8"),
hashlib.sha512).hexdigest()
# トークン
content_json = json.dumps(content_obj)
token = hmac.new(derived.encode("utf-8"),
content_json.encode("utf-8"),
hashlib.sha512).hexdigest()
# 送信ペイロード
payload = {
"data": content_json,
"key": salt,
"token": token,
}
return payload
def server(request_obj):
# 導出鍵の再現
derived = hmac.new(SECRET_KEY.encode("utf-8"),
request_obj["key"].encode("utf-8"),
hashlib.sha512).hexdigest()
# トークンの再現
verified_token = hmac.new(derived.encode("utf-8"),
request_obj["data"].encode("utf-8"),
hashlib.sha512).hexdigest()
# トークン一致検証
print("Token verified ? : ", hmac.compare_digest(request_obj["token"], verified_token))
if __name__ == "__main__":
send_obj = {"hello": "world"}
send_payload = client(send_obj)
print(send_payload)
server(send_payload)
例えばこれで{“hello”: “world”}と送ると、
{‘data’: ‘{“hello”: “world”}’, ‘key’: ‘1234’, ‘token’: ‘c6d1113a01fa912ba908c7c895ad6b3a9ffee696e90bf3d1cc775062e76b867f52d1d4b967811dba9296867d242ffd79dfd83c7fa66fd2f04458fe82e470424c’}
Token verified ? : True
のようになります。改竄検知に有効というのは、例えばデータを少し変えて{“hello”: “work”}にすると、
{‘data’: ‘{“hello”: “work”}’, ‘key’: ‘1234’, ‘token’: ‘15878661cc672e054da45b6aa513d11ef4edb4ac64a5abd80fd4bcefbb07f160dc48fec8384b159c25a52c33de24110c0721f70ce85457e7ff5f95dff18c76aa’}
Token verified ? : True
のようにトークンが大きく変わるからです(ハッシュ計算の関係です)。
共有鍵の発行
なんでもいいのですがこんな感じにローカルで共有鍵を発行しておきます。
import secrets
def generate_secret_key():
x = secrets.token_urlsafe(64)
with open("secrets.txt", "w") as fp:
fp.write(x)
Lambdaにデプロイ
まずはサーバーの推論部分をLambdaにデプロイしましょう。すべてデフォルトのPythonライブラリでできるので、Lambdaにコード直書きでOKです
import os
import hmac
import hashlib
def lambda_handler(event, context):
## Assume that evemt contains
# {
# "key": str = public key (salt),
# "token": str = generated token based on the data,
# "data": str = base64 encoded messagepack
# }
# Derived Key
derived_key = hmac.new(os.environ["SECRET_KEY"].encode("utf-8"),
event["key"].encode("utf-8"),
hashlib.sha512).hexdigest()
# Verification token
verification_token = hmac.new(derived_key.encode("utf-8"),
event["data"].encode("utf-8"),
hashlib.sha512).hexdigest()
return hmac.compare_digest(event["token"], verification_token)
Lambdaの環境変数で先程登録したSECRET_KEYを登録しておきます(割りとどうでもいい値ですが念のためマスクしておきます)。
ペイロードの作成
バイナリを含むペイロードを想定します。JSONで送るのですが、以下のようなペイロードを認証Lambdaに対して送り付けます。
## Assume that evemt contains
# {
# "key": str = public key (salt),
# "token": str = generated token based on the data,
# "data": str = base64 encoded messagepack
# }
keyがsalt、tokenがクライアントで計算したトークン、dataがメインの送信データです。送信データはバイナリが含むことも加味し、MessagePackでバイナリにエンコードし、base64で文字列化します。
dataの中身は以下のようなオブジェクト構造です。
## Assume that inside data
# {
# "a": 123,
# "b": 456,
# "obj": fixed length binary (10KB, ..., 1MB, ...)
# }
特定サイズのファイル作成
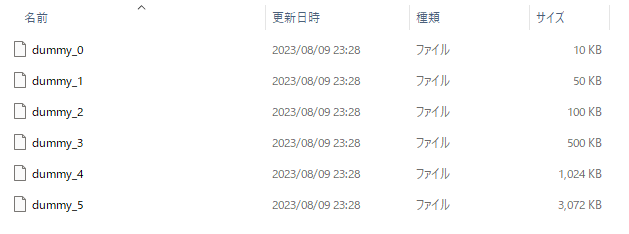
まずはobjに相当する特定サイズのファイルを作成します。
def make_dummy_file():
sizes = [10, 50, 100, 500, 1024, 3*1024]
for i, size in enumerate(sizes):
with open(f"dummy_file/dummy_{i}", "wb") as fp:
fp.seek(size*1024-1)
fp.write(b"\0")
10KB、50KB、100KB、500KB、1MB、3MBのダミーファイルを作成します。
ペイロード作成
MessagePackでバイナリデータ込でシリアライズ(バイナリ)し、BASE64で文字列化します。バイナリをBASE64化するとやや容量が膨らみますが、そういう仕様なのでここでは諦めます。
import os
import glob
import hmac
import hashlib
import json
import msgpack
import base64
os.environ["SECRET_KEY"] = "8Ntr.....54tw"
def make_dummy_payloads():
files = sorted(glob.glob("dummy_file/*"))
os.makedirs("dummy_json", exist_ok=True)
for f in files:
# 非バイナリ
data = {
"a": 123,
"b": 456
}
# バイナリをBASE64の文字列としてエンコード
with open(f, "rb") as fp:
data["obj"] = fp.read()
binary = msgpack.packb(data, use_bin_type=True)
base64_binary = base64.b64encode(binary)
# salt
salt = secrets.token_hex(16)
# 導出鍵
derived = hmac.new(os.environ["SECRET_KEY"].encode("utf-8"),
salt.encode("utf-8"),
hashlib.sha512).hexdigest()
# APIトークン
api_token = hmac.new(derived.encode("utf-8"),
base64_binary,
hashlib.sha512).hexdigest()
# ペイロード
payload = {
"data": base64_binary.decode(),
"key": salt,
"token": api_token,
}
with open(f"dummy_json/{os.path.basename(f)}.json", "w", encoding="utf-8") as fp:
json.dump(payload, fp)
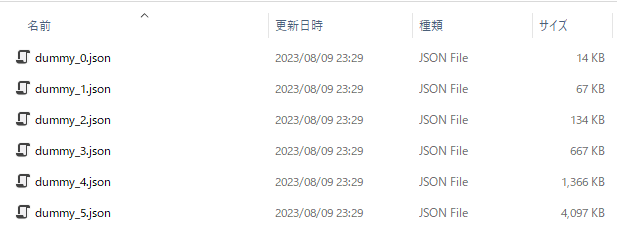
容量がおよそ1.3~1.5倍になっていますね。実際は、LambdaやAPI Gatewayのペイロード上限にかからないように気をつけたいところです。
テスト
AWSコンソールのLambda→テストイベントを設定より、JSONをコピペして何回か呼び出します。
Lambdaはインスタンススペックが割当メモリに連動するという重要な性質があるので、割当メモリを変えても試してみます。
メモリ上限10Gで Lambdaのコア数はどうなった!!(Re:Invent2020対応版)
もっと賢い方法絶対あると思いますが、手動でテストしてコンソールに出てくるレイテンシー(ms)と、メモリ使用量(MB)を記録しました。以下の条件で試しました。
- Lambdaの割当メモリ:128MB、512MB、1024MB
- ダミーファイルのサイズ:10KB、50KB、100KB、500KB、1MB、3MB
各ケース5回試行し、以下の値で比較します
- レイテンシー(ms)の最悪値
- レイテンシー(ms)の中央値
- メモリ使用量(MB)の中央値
レイテンシーはかなり動くのに対し、メモリ使用量はほとんど変わらなかったため、レイテンシーのみ最悪値と中央値を比較しています。
結果
レイテンシー(ms)の最悪値
| Max Latency(ms) | 128 MB | 512 MB | 1024 MB |
|---|---|---|---|
| 10 KB | 1.56 | 1.9 | 1.15 |
| 50 KB | 2.02 | 1.57 | 1.42 |
| 100 KB | 3.64 | 3.11 | 3.2 |
| 500 KB | 53.66 | 10.56 | 12.14 |
| 1 MB | 158.05 | 40.21 | 16.23 |
| 3 MB | 606.09 | 210.62 | 68.12 |
縦軸がダミーファイルのサイズ、横軸がLambdaの割当メモリです。
ダミーファイルが100KBまではほとんど変わらないのに対し、500KB以降はかなり大きく変わっていきます。これはダミーファイルのファイルサイズが大きくなるほど、SHAの計算量が支配的になってくるためです。
hexdigest周りのエンコード実装がやや冗長な感はあるので、もう少し設計工夫すればパフォーマンス追求できるかもしれません。
レイテンシー(ms)の中央値
| Median Latency(ms) | 128 MB | 512 MB | 1024 MB |
|---|---|---|---|
| 10 KB | 1.16 | 1 | 1.12 |
| 50 KB | 1.44 | 1.43 | 1.31 |
| 100 KB | 3.06 | 2.48 | 2.24 |
| 500 KB | 34.02 | 8.92 | 6.72 |
| 1 MB | 116.85 | 31.09 | 14.68 |
| 3 MB | 345.27 | 93.76 | 55.89 |
だいたいの傾向として、各ケースの試行1回目は遅く、2回目・3回目以降はまあまあ速いことがわかったので、どこかでキャッシュが働いているのかもしれません。なのでこの中央値は参考程度でいいと思います。
割当メモリ1024MBは1MB越えてこないと普通にサチってますね。
最大メモリ(MB)使用量の中央値
Lambdaの最大メモリ使用量の中央値です
| Median Memory Usage (MB) | 128 MB | 512 MB | 1024 MB |
|---|---|---|---|
| 10 KB | 43 | 43 | 72 |
| 50 KB | 44 | 44 | 72 |
| 100 KB | 45 | 44 | 72 |
| 500 KB | 49 | 48 | 72 |
| 1 MB | 54 | 54 | 72 |
| 3 MB | 77 | 79 | 72 |
1024MBの場合でも安定して72MBなのが面白いです。おそらくLambdaの中で最小確保メモリ数があって、それを越してくるとスワップが発生して遅くなるような傾向があるのだと思われます。
まとめ
LambdaのHMACのパフォーマンスがわかったのが収穫でした。どこにチューニングするかはペイロードのサイズやコスト次第なのでケースバイケースですが、SHA-512を2回も使っても、思ったより遅くならないのがわかったのが興味深い点でした。
Lambdaに数行レベルのコード足すだけでDockerもECRもいらないので、あまりAWS詳しくない人がお手軽認証かけたいときは便利そうです。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー