
論文まとめ:Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling


- タイトル:Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
- 論文URL:https://arxiv.org/abs/2412.05271
- GitHub:https://github.com/OpenGVLab/InternVL (MIT)
目次
3行要約
- オープンソースのマルチモーダル大規模言語モデル「InternVL 2.5」を公開し、商用モデルとの性能差を縮めることを目指した。
- ビジョンエンコーダ、言語モデル、データセットサイズ、推論時間などのスケーリングが性能に与える影響を調査し、大規模なビジョンエンコーダが学習データへの依存を軽減することを発見した。
- InternVL 2.5はMMMUベンチマークで70%を超える精度を達成し、高品質なデータと効果的なスケーリング戦略がオープンソースモデルの性能を大幅に向上させることを示した。
論文要約By Gemini1.5 Pro
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
この論文は、オープンソースのマルチモーダル大規模言語モデル(MLLM)であるInternVL 2.5について述べています。
・この論文において解決したい課題は何?
商用モデルとオープンソースモデルの性能差を縮め、高性能なオープンソースMLLMを提供すること。
・先行研究だとどういう点が課題だった?
既存のオープンソースMLLMは、商用モデル(GPT-4o、Claude-3.5-Sonnetなど)と比較して性能が低い。また、CoT推論が苦手で、データの質の問題も抱えていた。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
- (1) 新たなオープンソースMLLMであるInternVL 2.5を公開。
- (2) ビジョンエンコーダ、言語モデル、データセットサイズ、推論時間など、MLLMの様々な構成要素のスケーリングが性能に与える影響を調査。
- (3) 大規模なビジョンエンコーダが、MLLMのスケールアップ時の学習データへの依存を軽減することを発見。データの質の重要性と、テスト時スケーリングの有効性を示した。MMMUベンチマークで70%を超える精度を達成した初のオープンソースMLLM。
・提案手法の手法を初心者でもわかるように詳細に説明して
InternVL 2.5は、「ViT-MLP-LLM」パラダイムに基づき、画像エンコーダ(InternViT)、MLPプロジェクタ、大規模言語モデル(LLM)を組み合わせたアーキテクチャです。高解像度画像をタイル分割し、各タイルをInternViTで処理、その出力をMLPプロジェクタでLLMの入力形式に変換し、LLMでテキスト生成を行います。学習は3段階:(1)MLPプロジェクタのみを学習 (2) 必要に応じてInternViTをLLMと共同学習 (3) 全モデルを命令データでファインチューニング。さらに、学習効率向上の為、複数サンプルを連結するデータパッキング戦略を採用。また、LLMの異常動作を防ぐため、データフィルタリングパイプラインで低質サンプルを除去しています。
・提案手法の有効性をどのように定量・定性評価した?
MMMU、MMMU-Pro、MathVista、MATH-Vision、MathVerse、OlympiadBenchなどの多様なベンチマークで評価。MMMUでは70.1%を達成し、オープンソースモデルとして初の70%超えを達成。他のベンチマークでも先行研究や商用モデルに匹敵する性能を示した。また、データフィルタリングの有効性も確認。
・この論文における限界は?
長文応答生成時や実世界の複雑なインタラクションにおいて、GPT-4o等の商用モデルと比較して、ユーザー体験の点で改善の余地がある。また、幻覚の問題も完全には解決されていない。
・次に読むべき論文は?
論文中で比較対象として挙げられている、GPT-4o [192]、Claude-3.5-Sonnet [8]、Gemini-1.5-Pro [200]、Qwen2-VL [246]などの論文。
コードはhttps://github.com/OpenGVLab/InternVLで公開されています。
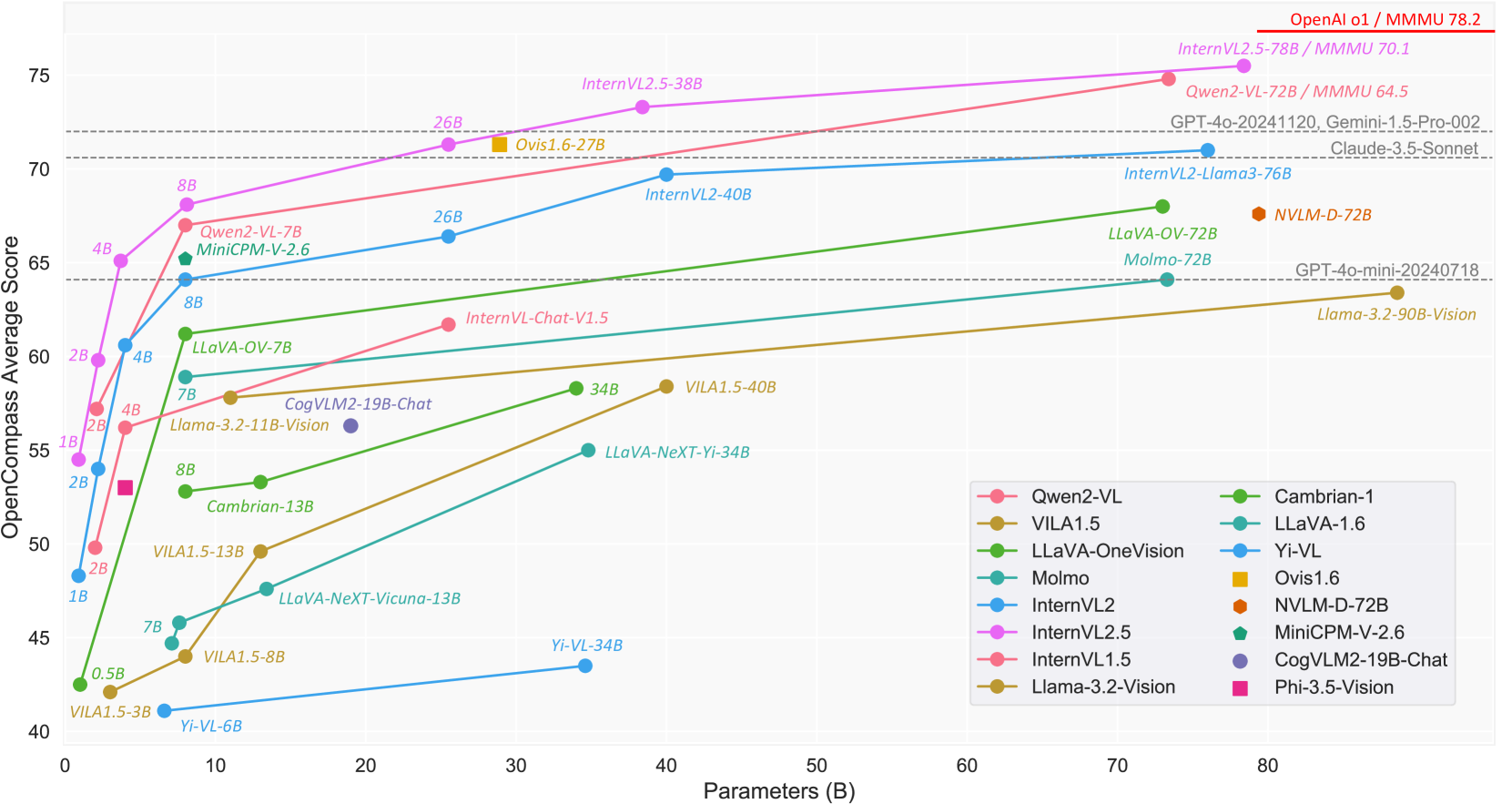
手法
- 以前のバージョンと同様に、Pixel Unshuffleを適用し、448×448画像タイルによって生成される1024個のビジュアル・トークンを256個のトークンに削減。
- 高解像度へのスケーラビリティを高めるため
- Pixel ShuffleとUnshuffle
- InternVL 1.5は既存の単一画像とテキストで訓練していたが、InternVL 2.0と2.5は複数画像とビデオデータを導入。
- MLP Projector:視覚特徴を抽出し、LLMに橋渡しする
- LLMに接続し、MLPをウォームアップした後、Next Token Predictionで学習
Vision Encoder
- V1.0とV1.2では、448×448の固定解像度で学習したが、その後動的解像度の学習に切り替え
- V1.5では、ViTの最後の3層を削除し、ローカル情報よりグローバルアラインメントを優先。ViTが6Bであっても、実際は5.5Bの45層
- InternViT-300M。6BのViTモデルを蒸留
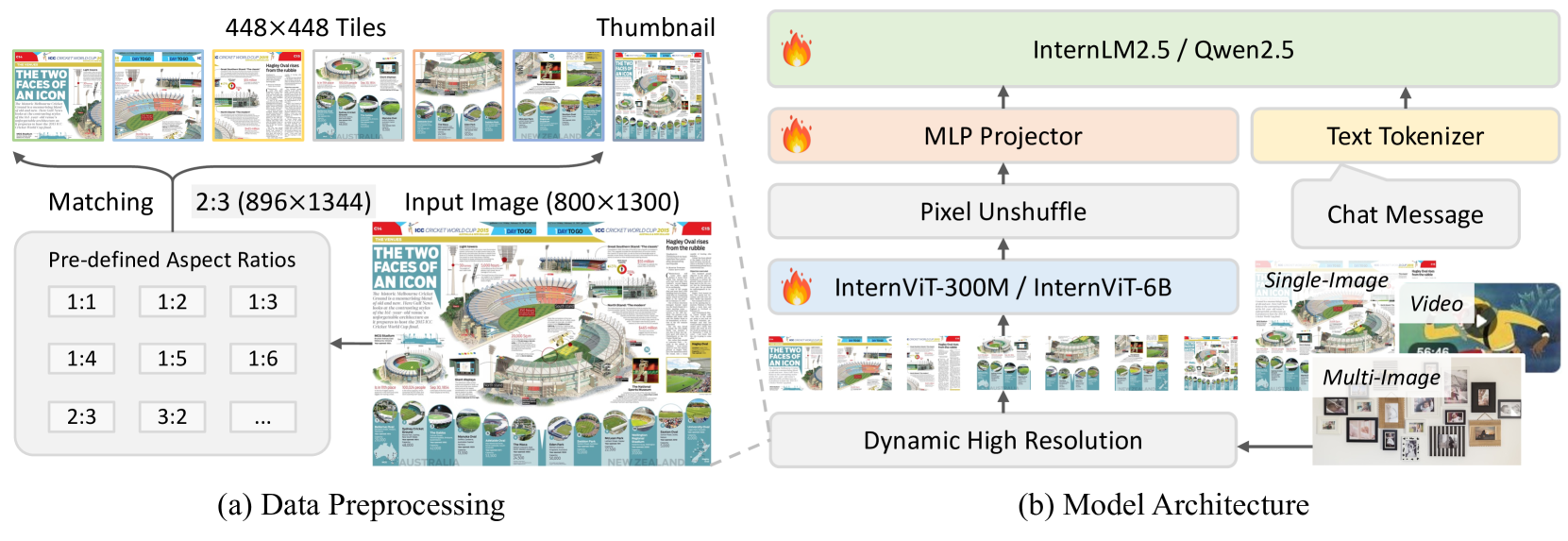
学習戦略:動的高解像度化
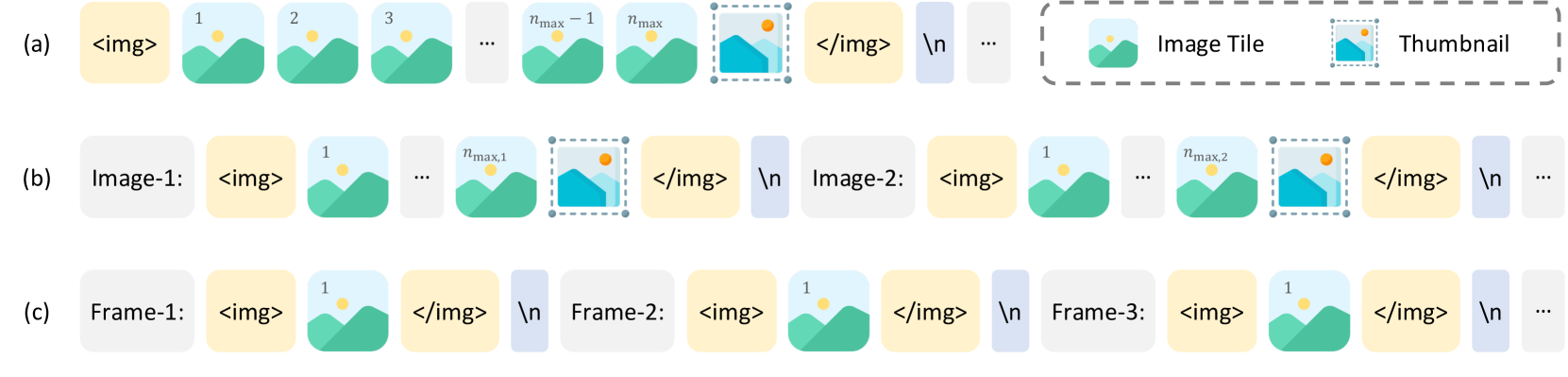
動的高解像度化。GPTに数式読ませてコード化したもの
- 単一画像では、アスペクト比がなるべく歪まないようにタイルを選択
- 複数画像または動画では、画像当たりのタイル数に応じて比例配分する
import math
from PIL import Image
def calculate_tiles_multi_image(n_max, N_images):
"""
Calculate the maximum number of tiles assigned to each image in a multi-image dataset.
Parameters:
n_max (int): Maximum number of tiles allowed for the entire dataset.
N_images (int): Total number of images in the dataset.
Returns:
list: List of tile counts for each image.
"""
tiles_per_image = [max(1, math.floor(n_max / N_images)) for _ in range(N_images)]
return tiles_per_image
def dynamic_high_resolution_multi(images, n_max=10, S=448):
"""
Implements the dynamic high-resolution algorithm for multi-image datasets.
Parameters:
images (list): List of input images (PIL.Image.Image objects).
n_max (int): Maximum number of tiles allowed for the entire dataset.
S (int): Tile size (default is 448).
Returns:
dict: Dictionary where keys are image indices and values are lists of tiles.
"""
N_images = len(images)
tiles_per_image = calculate_tiles_multi_image(n_max, N_images)
all_tiles = {}
for idx, (image, num_tiles) in enumerate(zip(images, tiles_per_image)):
W, H = image.size
aspect_ratio = W / H
# Determine grid dimensions
best_i, best_j = None, None
min_diff = float("inf")
for i in range(1, n_max + 1):
for j in range(1, n_max + 1):
if i * j >= num_tiles:
grid_aspect_ratio = i / j
diff = abs(grid_aspect_ratio - aspect_ratio)
if diff < min_diff:
min_diff = diff
best_i, best_j = i, j
# Resize image
W_new = S * best_i
H_new = S * best_j
resized_image = image.resize((W_new, H_new), Image.ANTIALIAS)
# Split into tiles
tiles = []
for i in range(best_i):
for j in range(best_j):
left = i * S
upper = j * S
right = left + S
lower = upper + S
tile = resized_image.crop((left, upper, right, lower))
tiles.append(tile)
# Limit to num_tiles
all_tiles[idx] = tiles[:num_tiles]
return all_tiles
# Example usage
if __name__ == "__main__":
# Load a list of example images
input_images = [Image.open(f"image_{i}.jpg") for i in range(1, 4)] # Replace with your image paths
n_max = 15 # Maximum tiles allowed for the entire dataset
tiles_dict = dynamic_high_resolution_multi(input_images, n_max)
学習戦略:単一モデルの学習
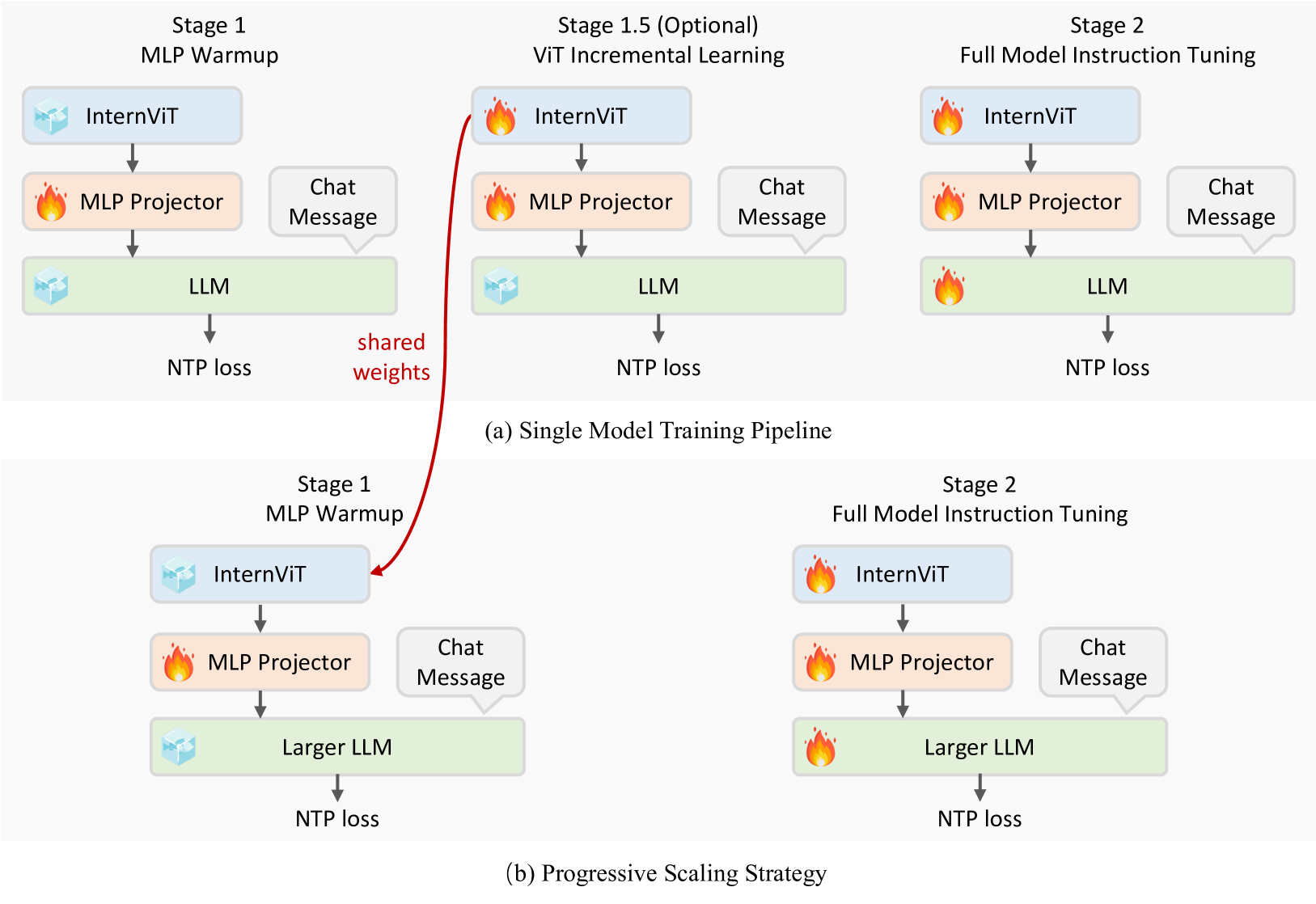
段階的にファインチューニングする。インクリメンタル学習を導入
Stage 1.5の目的
- 視覚エンコーダの視覚的特徴抽出能力を向上させたい
- 特に多言語OCRデータや数学チャートなど、ウェブスケールのデータセットでは比較的少ないドメイン(例:LAION-5B)に対して、より包括的な情報を捉えることを可能
- 多言語OCRやチャートの理解がほしければViTのファインチューニングは必要
学習戦略:プログレッシブスケーリング
InternVL2.5の新規要素で、小さいLLMで学習したViTを大きなLLMに訓練し、プログレッシブに学習することで効率的な学習を実現。
より大きなモデルを学習する場合、以前のステージから最適化されたInternViTモジュールが再利用されるため、ステージ1.5をスキップできる。
学習の強化
- 実世界のシナリオに対応するために、ランダムなJPEG圧縮(75-100)をData Augmentationとして導入
- 損失の再重み付け:NTP損失の重み付けでよく使われる。両方を使う
- トークン平均化:サンプル内の平均ロスを最初に計算
- サンプル平均化:サンプルをまたいで平均を計算
- 各手法の欠点
- トークン平均化:より多くのトークンを持つ応答に偏った勾配が生じ、ベンチマークを低下させる可能性
- サンプル平均化:短い応答を優先させてユーザーエクスペリエンスに悪影響
- 2乗平均をとって両者のバランスを取る
データセットの構成

- モダリティごとにData Augmentationを変える
- 画像ではJPEGのData Augmentationが必要だが、動画では動画内の画質を一定にするためにAugmentationをしない
- モダリティごとに最大タイル数を変える
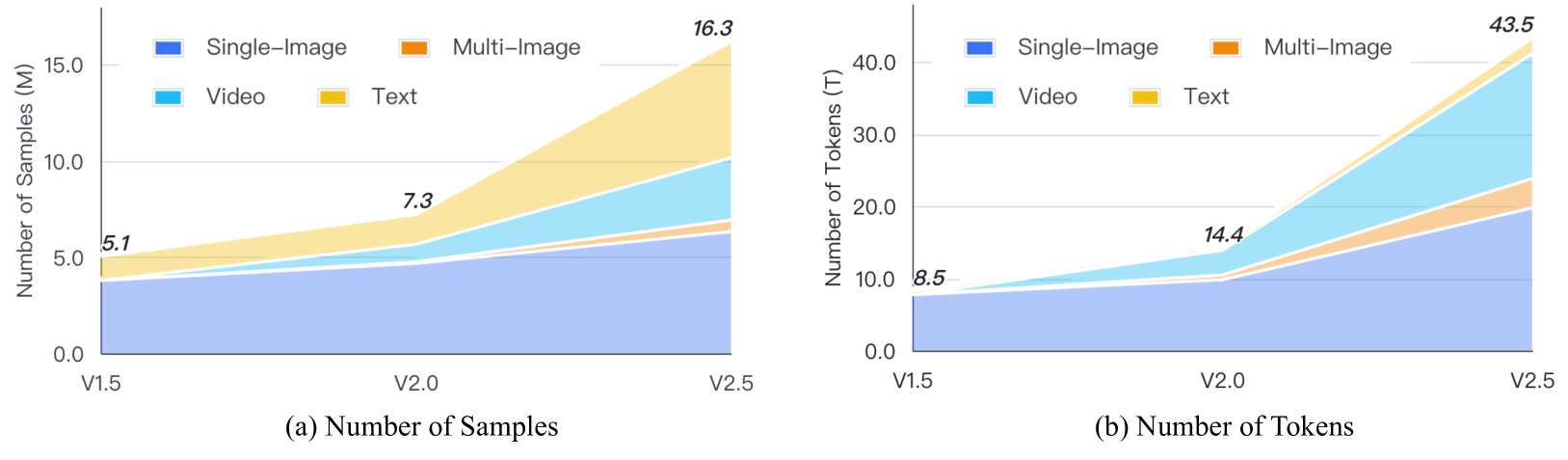
- 全体のデータ構成。モダリティもデータ数も増加
マルチモーダルデータパッキング
- 訓練時のトークン数を有効に活用するために、複数のサンプルを長いシーケンスに結合することでパディングを減らす
- バイナリサーチを使って、選択や探索を行う
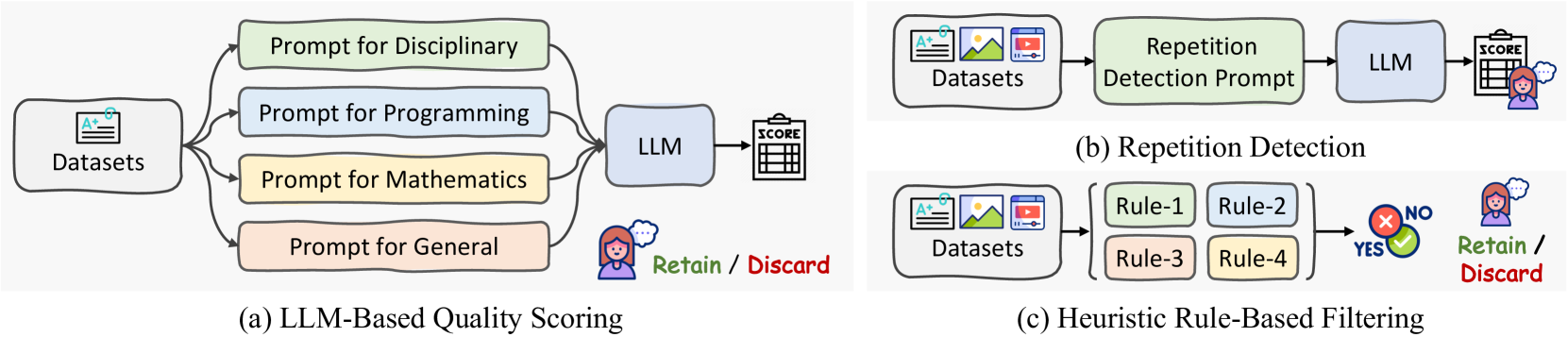
悪いサンプルの除外

- 一番ユーザー体験に影響度の高い課題は、同じ文章が反復生成されること
- これらはデータの質に起因するもので、少量入っただけで全体に影響が出る
- LLMベースの品質スコアリングを行い、低品質のものをフィルタリング
結果
定量評価の記述がだいぶ長いので割愛して紹介
V2.5からは、CoTの効果が明確に出るようになった

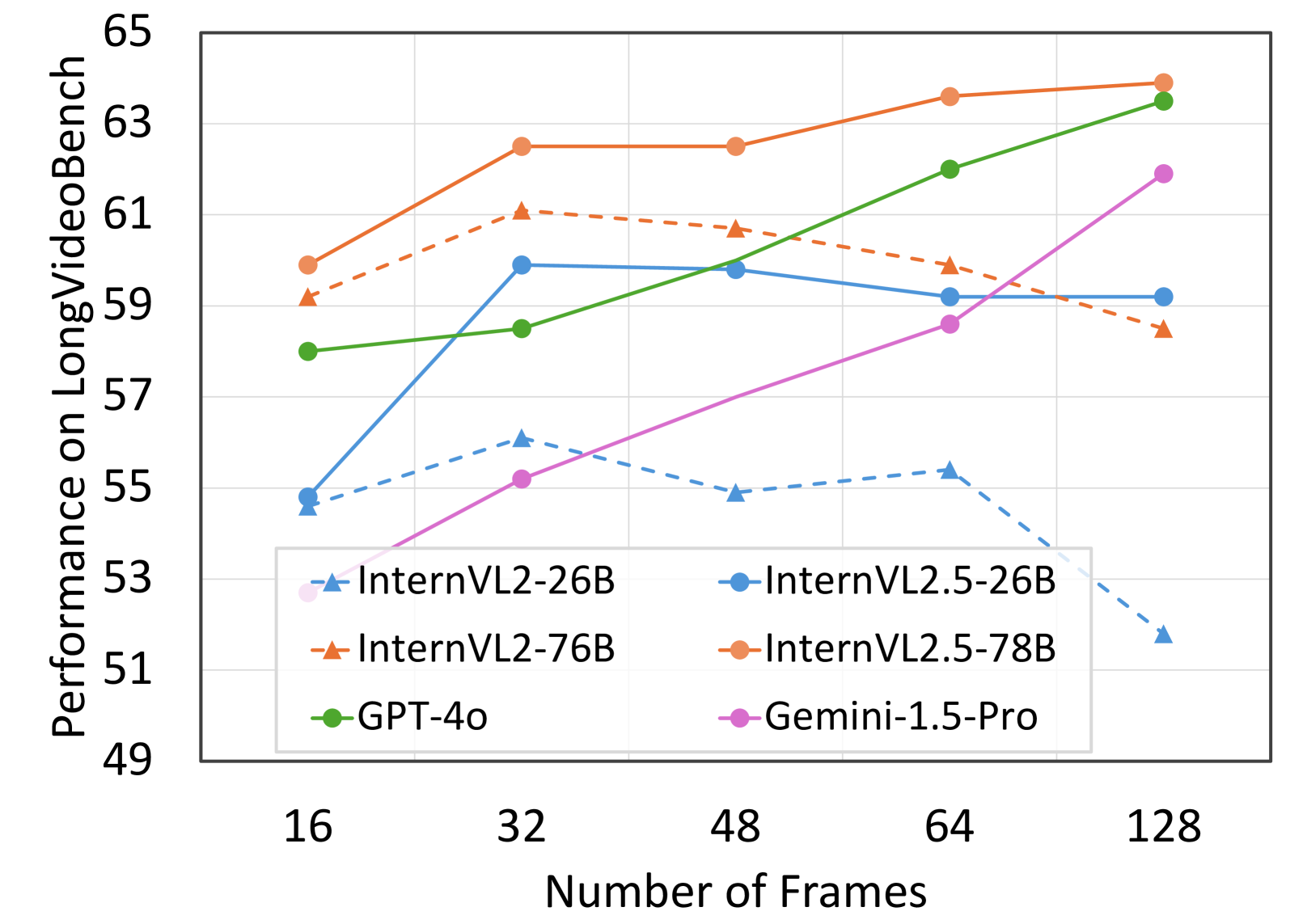
動画ではフレーム数に対してスケールするようになった
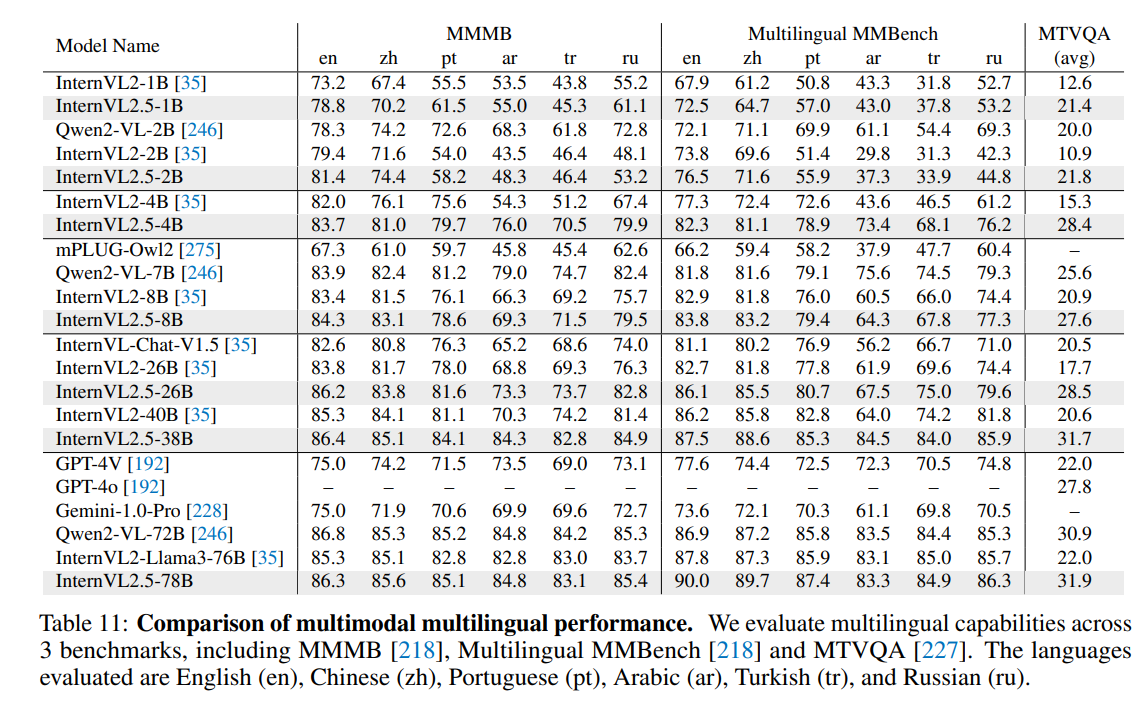
マルチリンガルの性能も高い
所感
- GPT-4oやGeminiの再現をしようとすると大変だなぁ!と印象
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー