
論文まとめ:Lightweight Attentional Feature Fusion: A New Baseline for Text-to-Video Retrieval
Posted On 2022-12-08


- タイトル:Lightweight Attentional Feature Fusion: A New Baseline for Text-to-Video Retrieval
- 著者:Fan Hu, Aozhu Chen, Ziyue Wang, Fangming Zhou, Jianfeng Dong, Xirong Li
- 所属:中国人民大学、浙江工商大学
- カンファ:ECCV 2022
- 論文URL:https://arxiv.org/abs/2112.01832
- コード:https://github.com/ruc-aimc-lab/LAFF
目次
ざっくりいうと
- 動画検索を目的として作られた、クロスモダリティのネットワークモジュールLAFFを提唱
- Attentionフリーな単純な構造ながらSoTA
- 訓練済みの静止画・動画・テキストモデルをFusionし、類似度を学習できる
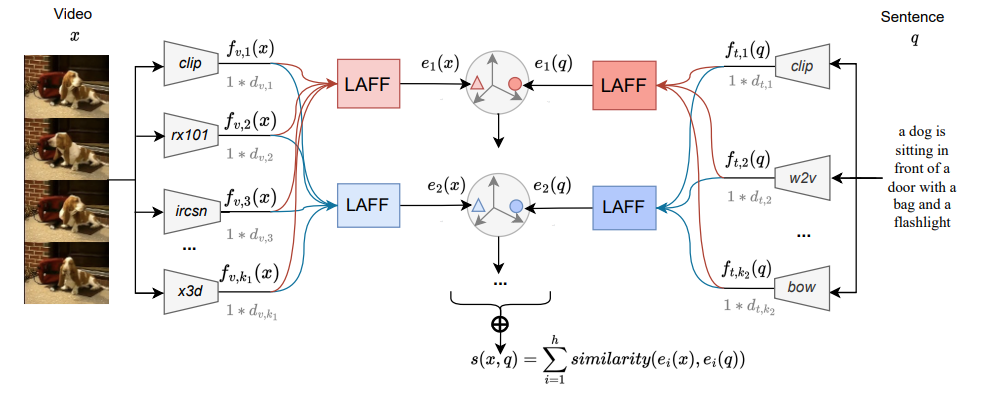
手法
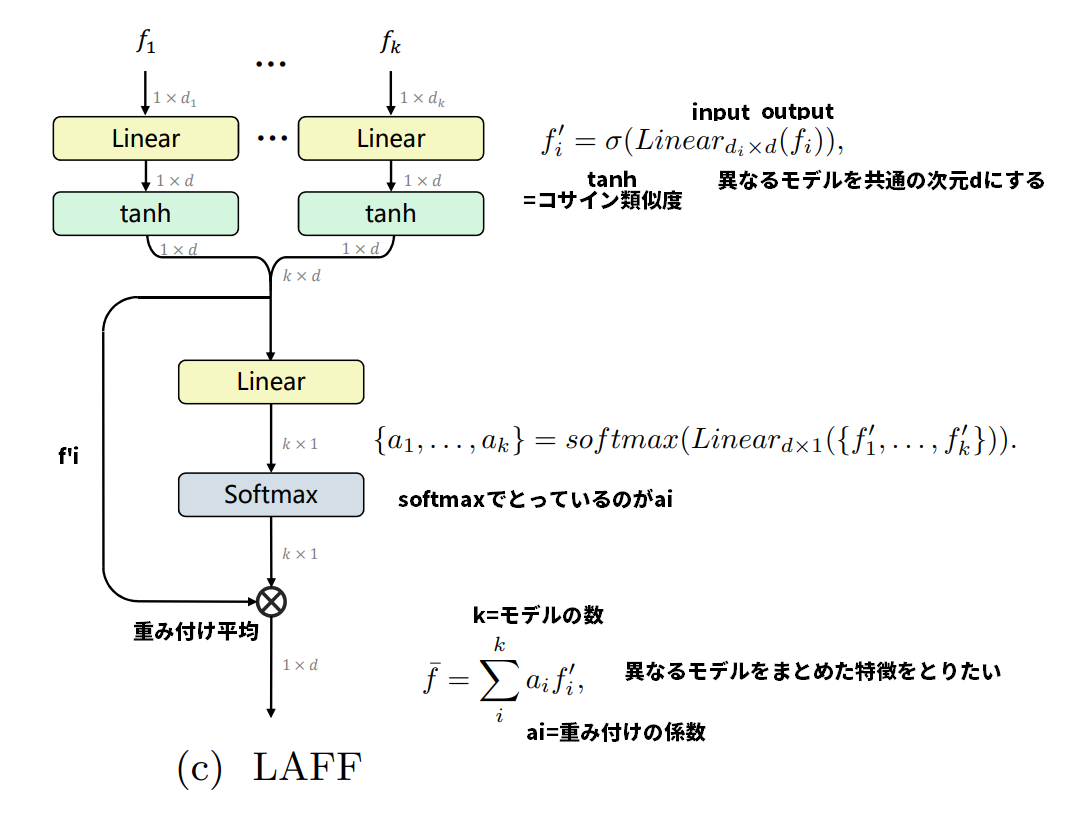
LAFFモジュール
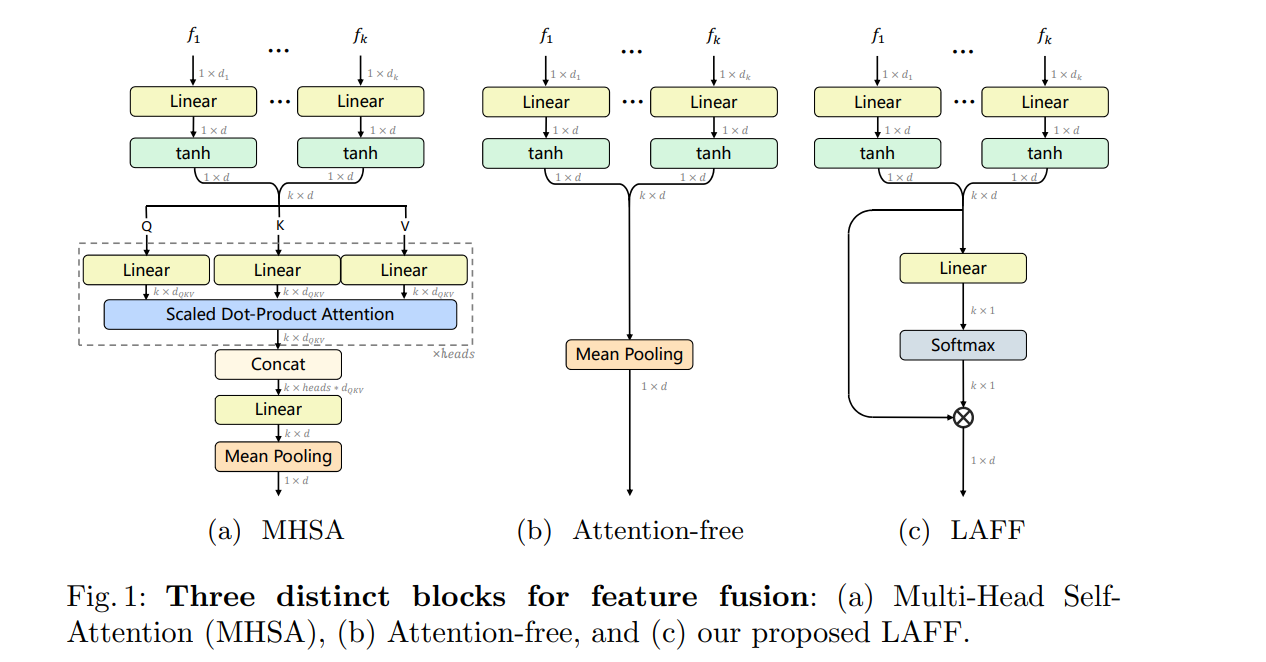
MHSAはAttentionあり。Ours(LAFF)はTransformerのようなAttentionを使っていない
Attentionフリーにすることで、計算量が軽くなる

バックボーンのモデル
画像モデルもテキストモデルもPretrainedモデルを大量にもってくる。コードを見たら、CLIPやBERTのエンコーダーは明示的に訓練しないようになっていたが、基本的にはLAFFの部分のみ訓練するのではないか。

動画のモデルと静止画のモデルをFusionできる
重み付き平均を取るだけなので、CLIPやRX101などの静止画のモデルと、X3Dの動画のモデルをFusionできる
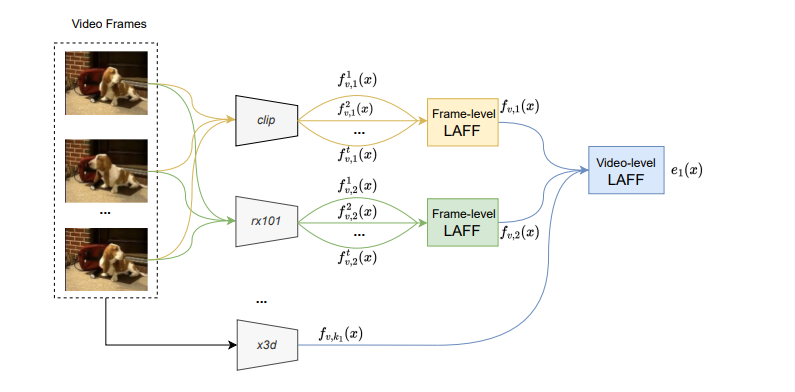
画像/テキストといったモダリティの次元だけでなく、時間軸など様々な次元で集約可能
損失関数
先行研究にあった「triplet ranking loss with hard-negative mining」という損失関数を使用

sは類似度の関数、αはマージン。argmaxの実装は微分可能な形に工夫されていた
結果
動画検索タスクにおいてSoTAだった
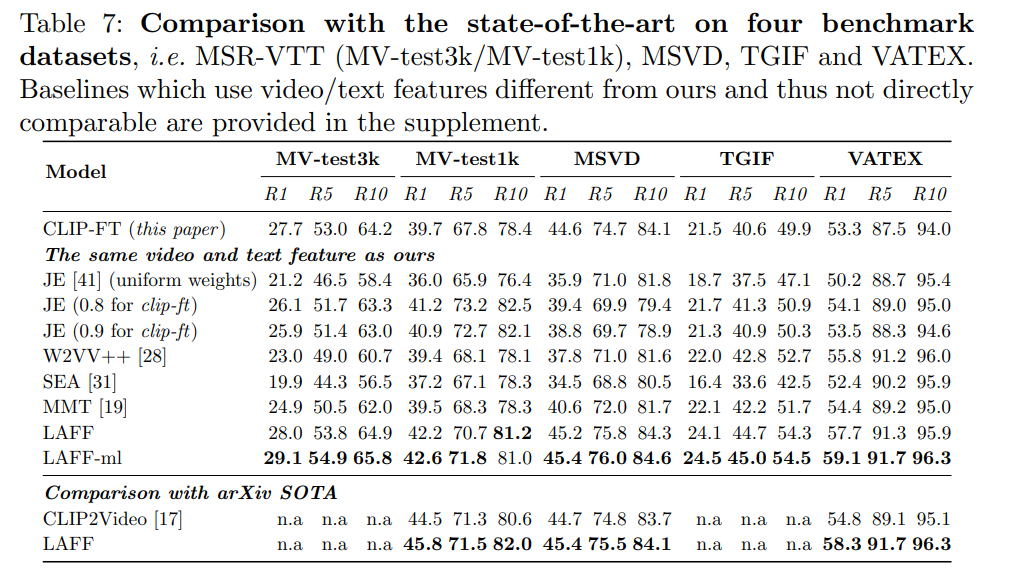
MHSAのようなAttention-likeなモジュールより、一貫してLAFFのほうがよかった。
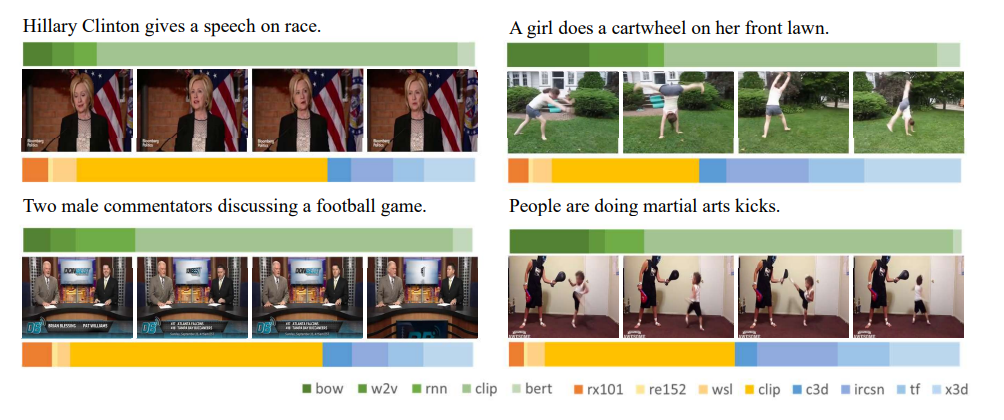
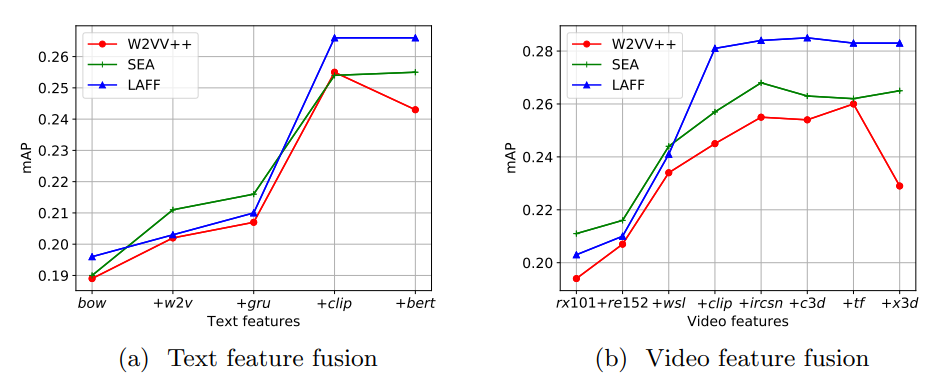
モデル別のLAFFの重み(寄与率)を見ると、CLIPがかなり支配的になっているものが多い。側転のように動きが大事なものは、動画モデルの寄与率が大きくなっている。
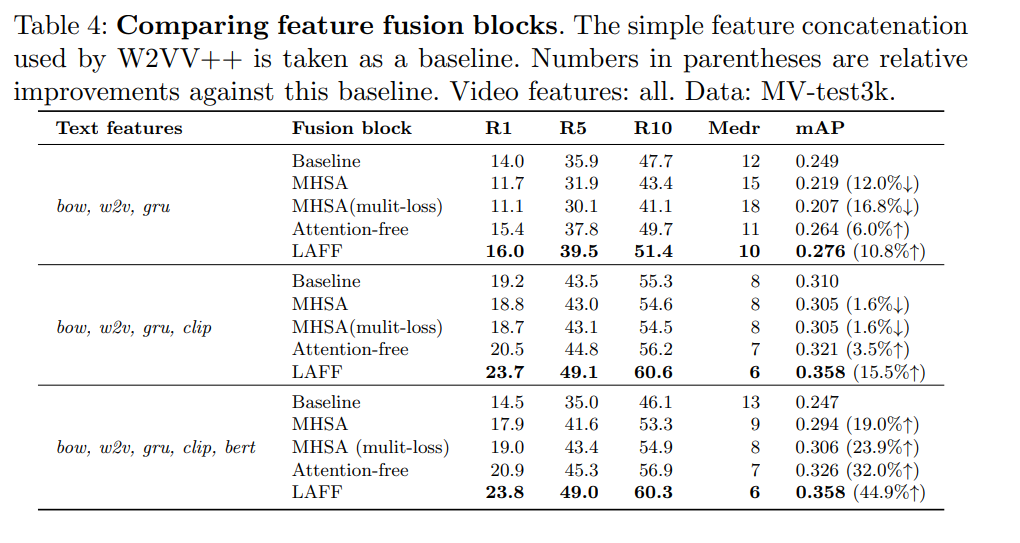
モデルをもりすぎると悪化する(例:CLIPにBERTを盛ると悪化する)。特にここは議論はなかったが、次元の呪い?
議論
- ネットワークをマシマシにしたのだから、精度が上がるのはある意味当然とも言える
- 計算量重そうだが特に議論はなかった(2080Ti1枚で全実験をやったとは書いてある)
- アンサンブル学習の文脈ではありそうだがなかった手法
- 異なるモダリティのFusion(静止画、動画、テキストモデル混ぜ混ぜ)が面白く、動画検索以外でやっても面白いのではないか
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー