
LLaMA.cpp+(cu)BLASのCPU/GPUのスループット検証(AWS編)


AWSのEC2環境でのLLaMA.cppのスループットをCPU,GPUインスタンスで比較してみました。結論としてはGPUのほうが良さそうということですが、インスタンスあたりのコストを考慮した比較なども行っています。
目次
はじめに
前回の記事に引き続き、LLaMA.cppのOpenBLAS/cuBLASでのCPU/GPUのスループットについて比較していきます。前回はローカル環境での実行でしたが、今回はAWSのEC2インスタンスで実験してみました。
検証内容
やっていることは前回と同じです。以下の3種類のインスタンスで検証します。価格は東京リージョンのEC2のものです
- c6a.4xlarge
- 16vCPU / 32GiB RAM
- GPUなし
- 0.7704 USD / hr
- g4dn.2xlarge
- 8vCPU / 32GiB RAM
- T4 GPU (16GB VRAM)
- 1.015 USD / hr
- g5.2xlarge
- 8vCPU / 32GiB RAM
- A10g GPU (24GB VRAM)
- 1.75776 USD / hr
c6a.4xlargeがCPUインスタンス、g4dn.2xlargeとg5.2xlargeがGPUインスタンスです。
今回はCPUのインスタンスはOpenBLASで、GPUインスタンスはcuBLASでLLaMA.cppをビルドしました。CPUのインスタンスの場合はCPUのみ、GPUインスタンスの場合はGPUのみで検証します。各ケースCPUは3回、GPUは5回試行しました。
前回のローカル編のときは、すべてcuBLASでビルドして、CPUとGPUの両方を同時に検証したのでそこは違いあります。
EC2インスタンスの詳細
- EC2はAWSが用意しているUbuntu22.04のイメージを使用
- GPUインスタンスでは、GPU周りのセットアップが必要だったので、以下の記事を参考に行った
- CUDA Container Toolkit https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
- CUDA Driver https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/install-nvidia-driver.html
- セットアップがやや面倒だったので、AWSが用意しているPyTorchのイメージなどを使ってもよかったかも
- また、EC2の中でDockerイメージをビルドして実行した。Dockerはdocker.ioを使った
- CPU/GPU問わず、300GBのEBS(g2)を追加した。I/Oスループットは900IOPS
Dockerfile
GPU版は前回と同じなので省略。CPU版は以下の通り
FROM ubuntu:22.04
RUN apt-get update
ENV TZ=Asia/Tokyo
ENV LANG=en_US.UTF-8
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt-get install -yq --no-install-recommends python3-pip \
python3-dev \
build-essential \
git \
wget \
vim \
cmake \
libopenblas-dev \
pkg-config \
tzdata && apt-get upgrade -y && apt-get clean
RUN ln -s /usr/bin/python3 /usr/bin/python
RUN git clone https://github.com/ggerganov/llama.cpp
WORKDIR /llama.cpp
RUN git checkout dadbed9
WORKDIR /llama.cpp
RUN pip install --no-cache-dir -r requirements.txt
WORKDIR /llama.cpp/build
RUN cmake .. -DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS
RUN cmake --build . --config Release
WORKDIR /llama.cpp
モデルごとの速度比較
前回と同じく、モデルごとの各環境・各量子化ビットごとの生成部分のtokens per second(tps)を比較します。tpsは多いほど生成が速いことを意味します。
前回のローカルCPU/GPUとクラウド環境を同時にプロットしてみました。ローカル環境は以下のとおりです。
- CPU : Core i9-9900K @ 3.60GHz
- RAM : 64GB
- GPU : RTX A6000
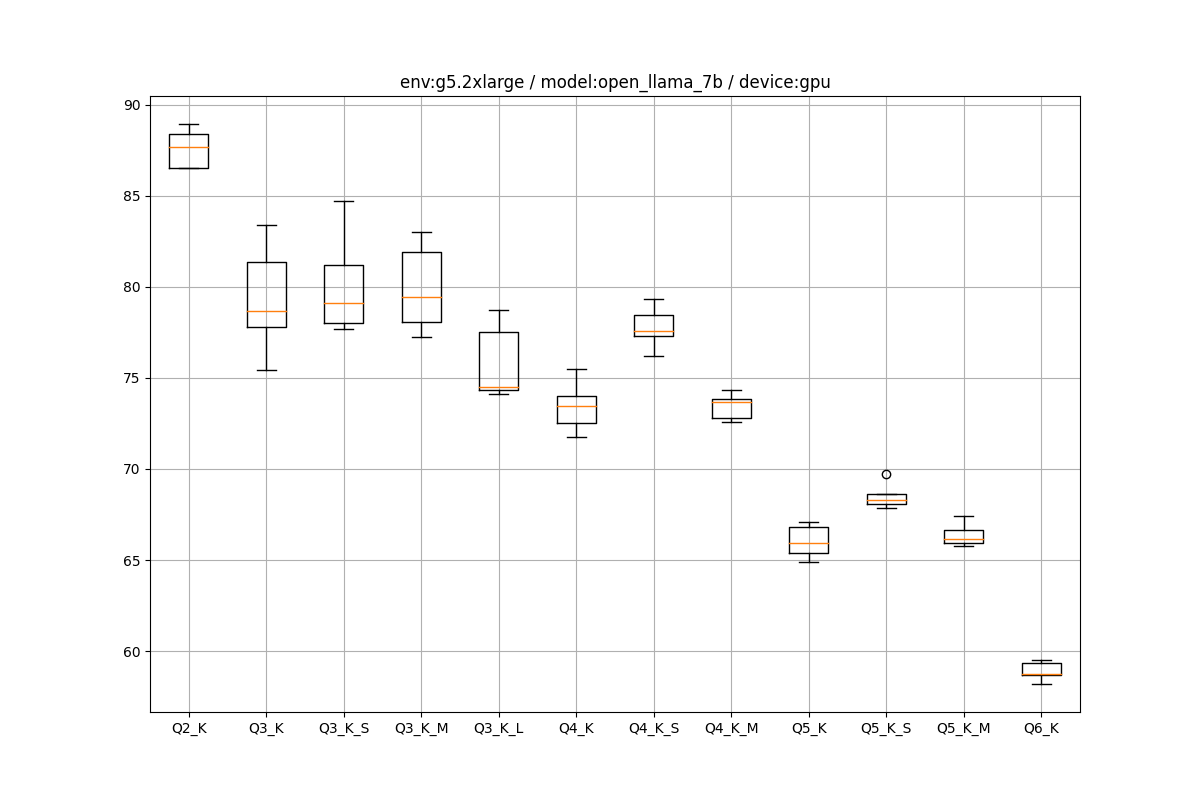
OpenLLaMA 7B
全条件
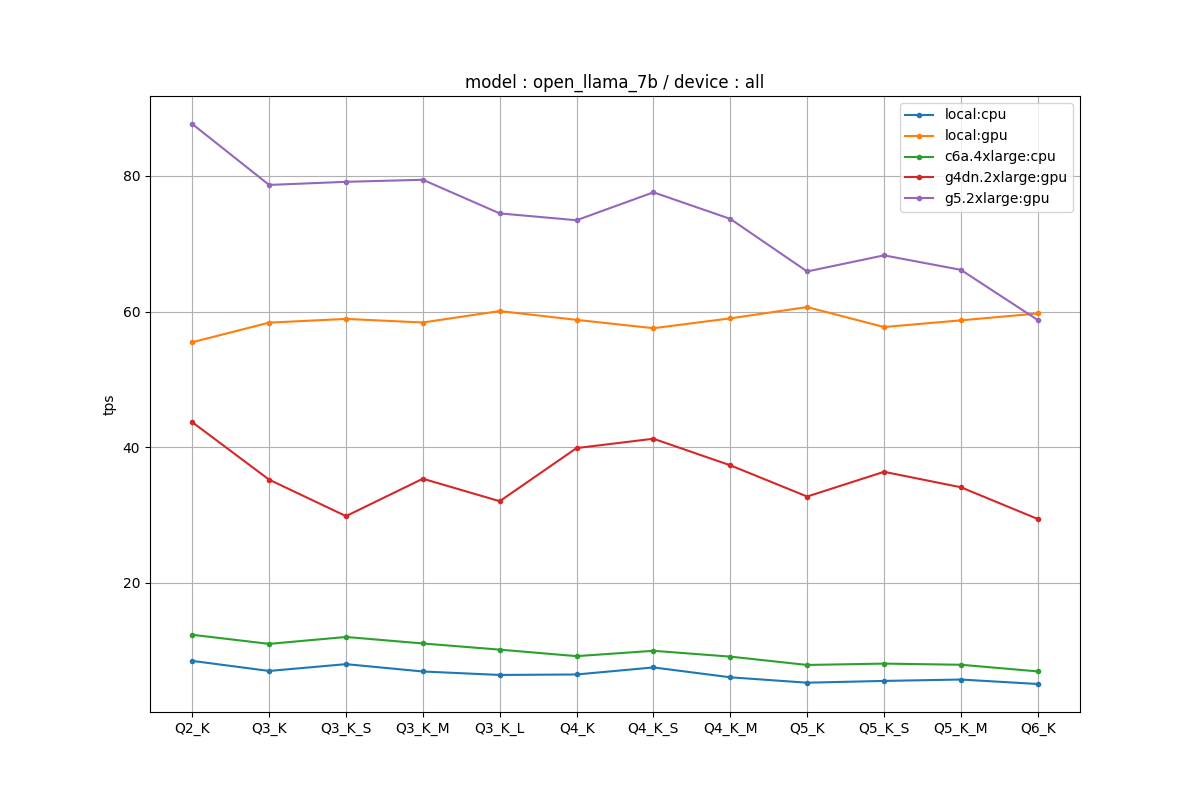
CPUよりGPUが圧倒しているのは、EC2でも同じでした。
プロットの点は同一条件での複数試行の中央値をとっています。
CPUの場合
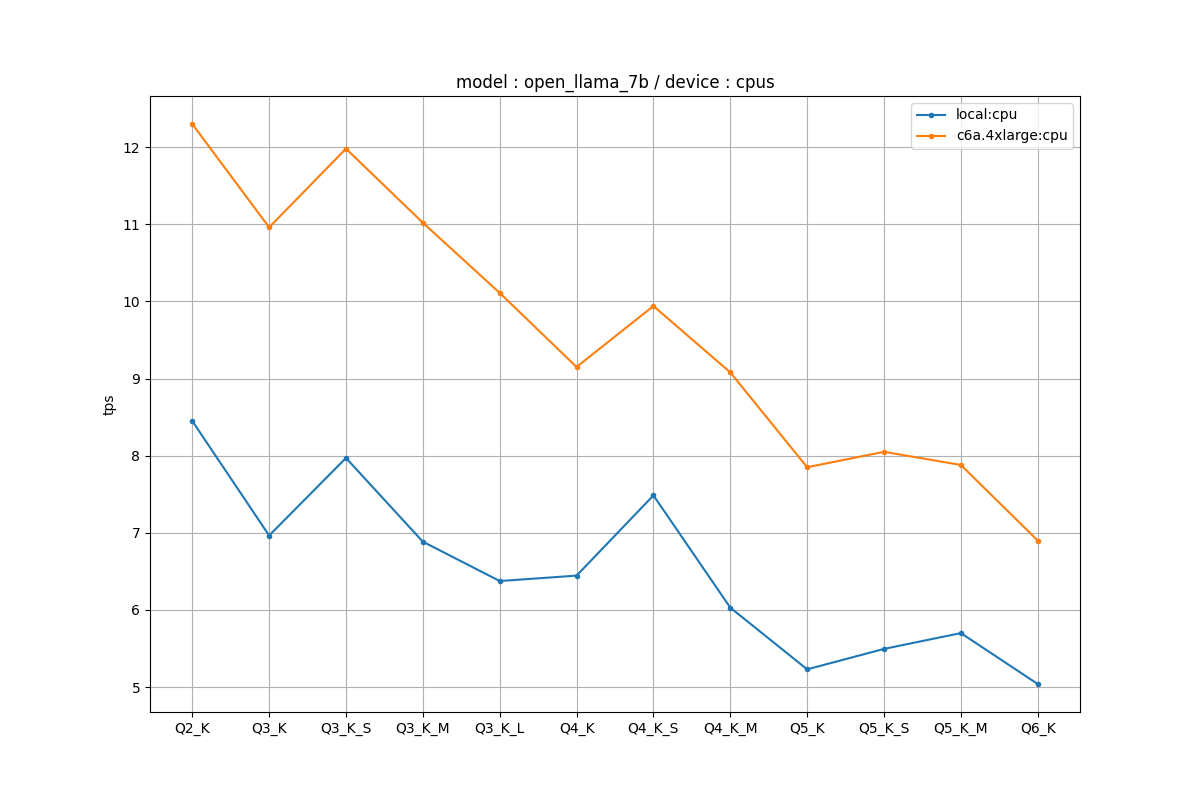
c6aインスタンスのほうがローカルの1.5倍ぐらいの速度を叩き出しました。
ローカルのCPUはi9-9900Kで8コア16スレッド、Passmark18441とやや年式は古くはなっているものの、そこまで悪いスペックではありません。それの1.5倍ぐらいの速度のインスタンスが割りとお手頃な価格で使えるのいいですね。
GPUの場合
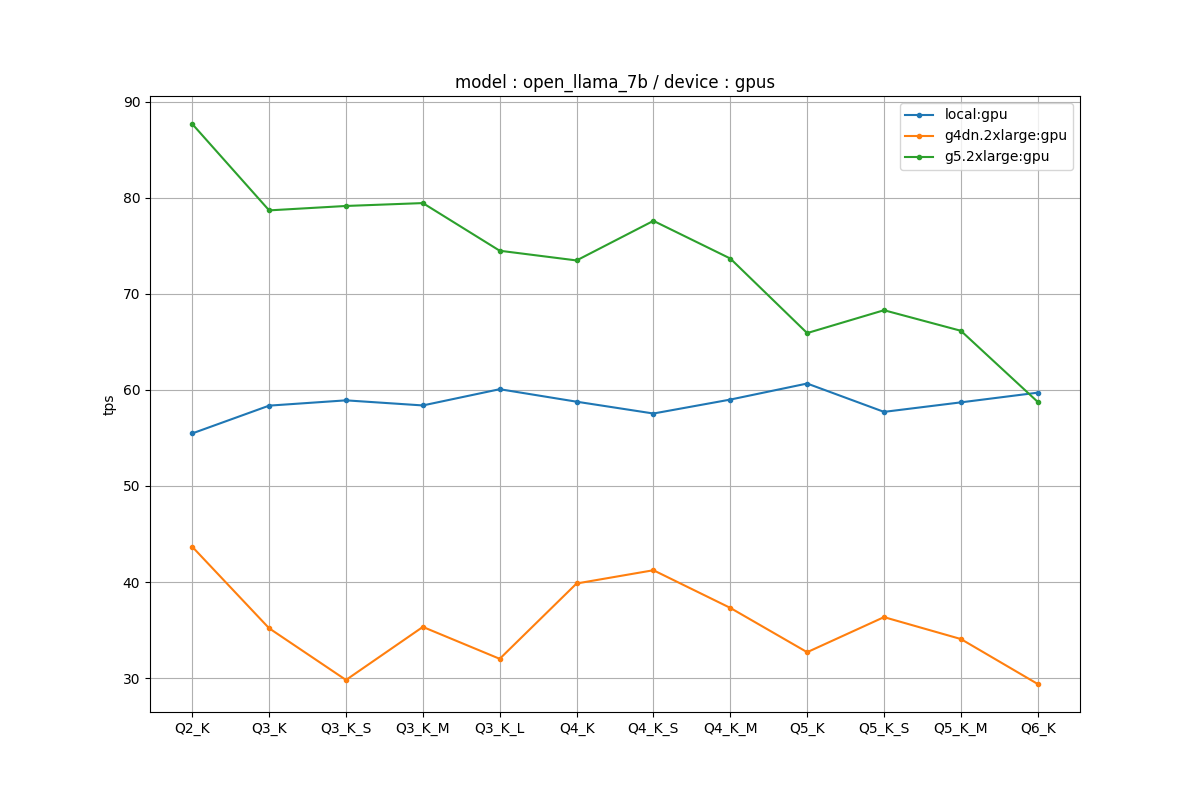
ローカルGPUの場合は量子化に対してtpsが頭打ちになっていましたが、クラウド環境で動かしたらきちんとスケールするようになりました。ローカルGPUの場合はI/Oのどこか(ディスクかマザボ?)の部分がボトルネックになったのかもしれません。
クラウドでもg5インスタンスはきれいな量子化と速度のトレードオフを示したのに対し、g4dnはあまりぱっとしない感じだったのが年式による違いでしょう。A10gのほうがおそらく低ビット環境での推論を意識した作りにはなっていると思います。
興味深かったのは、A6000のスペックはだいたいA10gと同等か若干劣るぐらいっていうところでした。FP16で検証したらまた変わると思います。
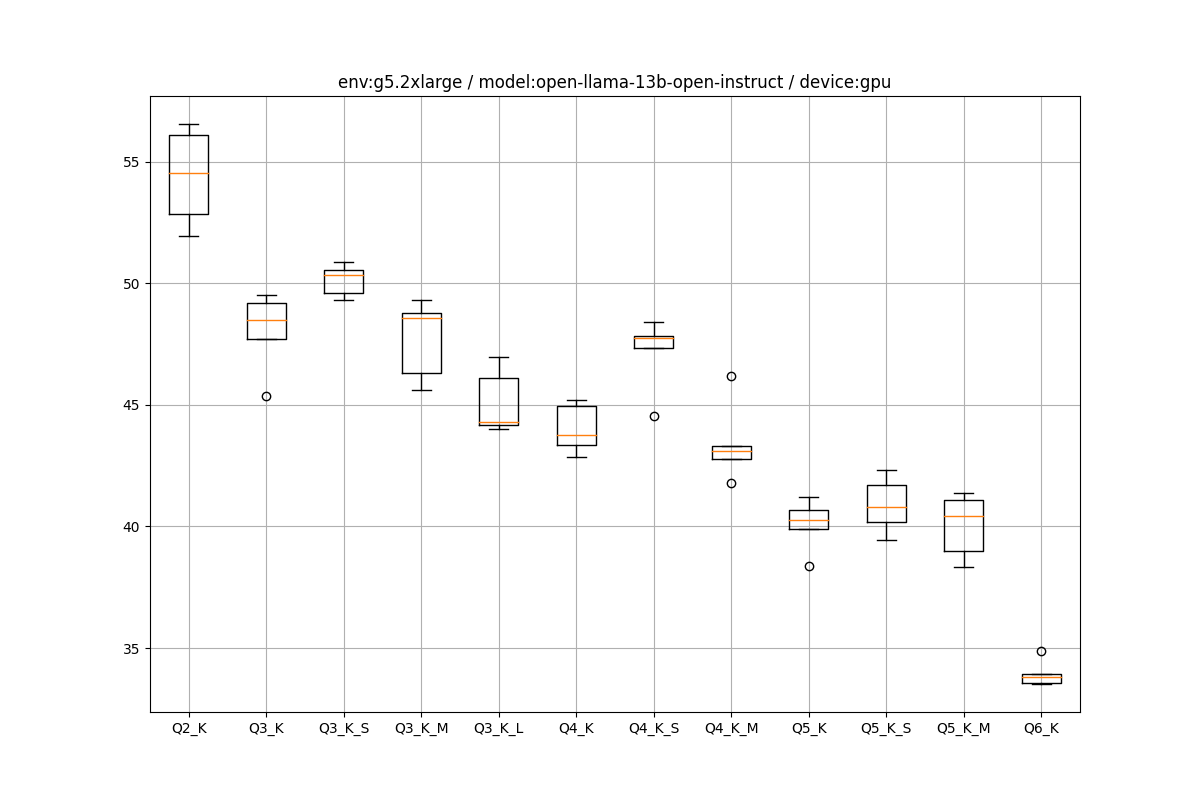
OpenLLaMA 13B Instruct
全条件
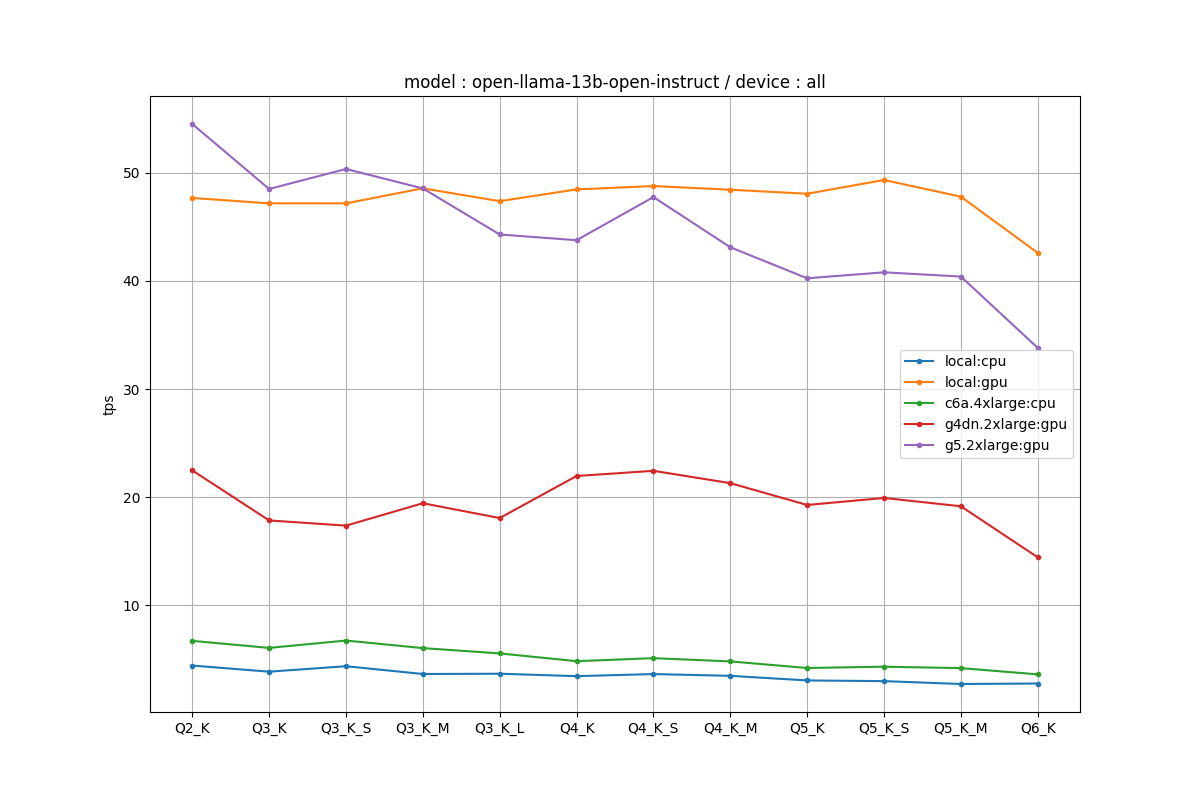
ほぼ7Bと同じぐらいという感じです
CPUのみ
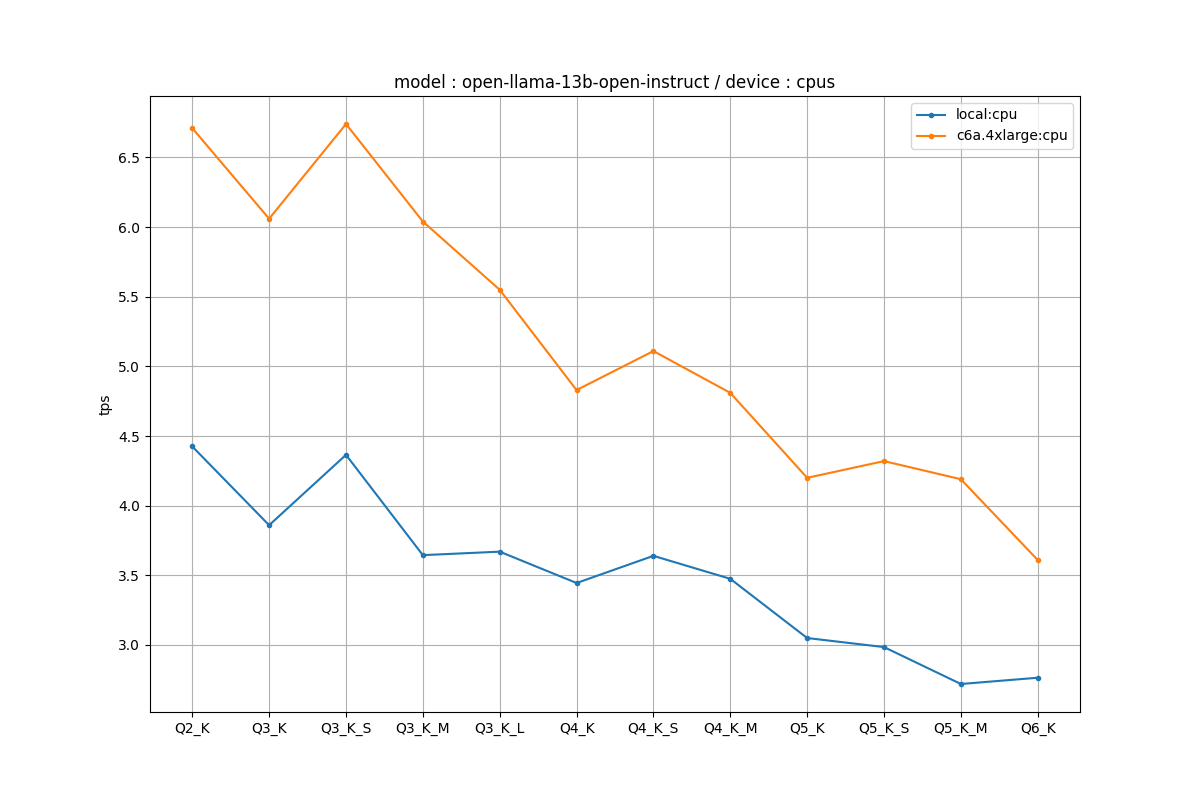
c6aでQ4_Kで5tps付近というのが一つの目安でしょうか。
GPUのみ
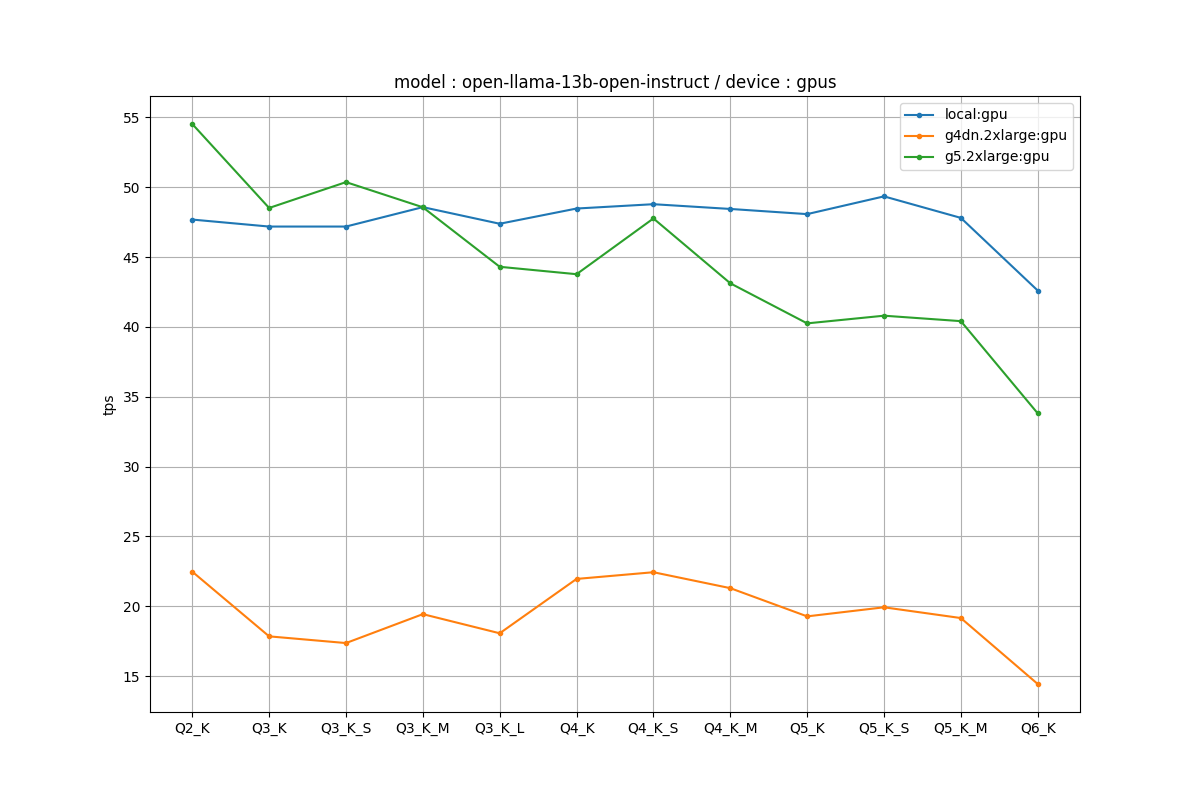
実はこっちのほうがローカルのA6000とEC2のA10gが拮抗しています。ローカルのI/Oボトルネックよりも、計算量のほうが支配的になってきたのだと思います。
ローカルももうちょいパーツ変えればもっと速くなりそうですね。
EC2の価格を考慮した比較
今までの比較だと「強いインスタンスを使えば速くなるよね」という結論にしかならなかったのですが、「結局CPU/GPUどっちを使えばいいの?」「どのインスタンスを使えばいいの?」というのが問題になります。
そこで、EC2の時間あたりの価格で、tpsを正規化してEC2インスタンス別にプロットしてみます。EC2の3ケースをモデルごとに比較します。
- c6a.4xlarge
- 0.7704 USD / hr
- g4dn.2xlarge
- 1.015 USD / hr
- g5.2xlarge
- 1.75776 USD / hr
次から求める値は、各環境のtpsをこれらの価格で割った(tps / (USD/hr))で比較します。
ただ、ここで計算している値はテキスト生成速度のみを考慮しており、モデルの読み込み時間の差やインスタンスの立ち上げのラグなどは全く考慮していません。あくまで参考値として見てください
OpenLLaMA 7B
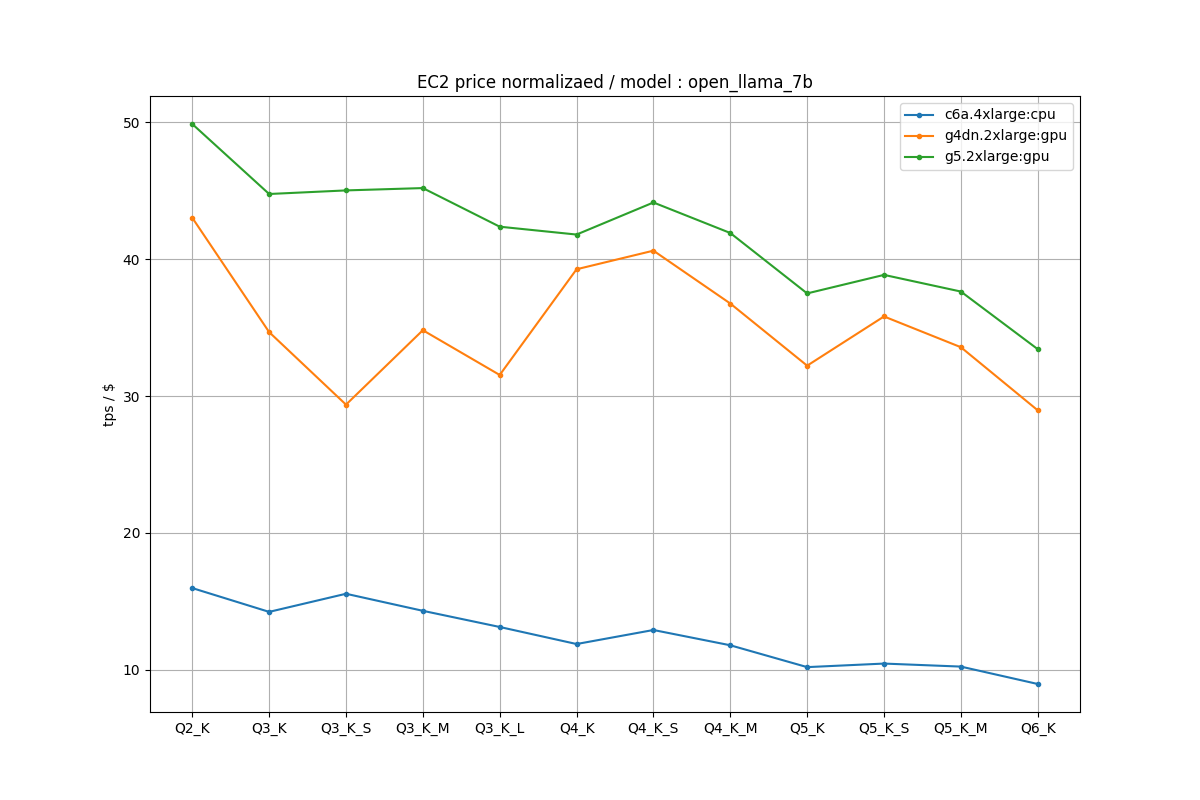
CPUよりGPUのほうが値段あたりでも見ても2倍程度効率的でした。ただ、GPUはモデルのロードがCPUに比べて遅いというデメリットがあるので、モデルロードの短縮が大事になるケースだともしかしたらCPUのほうがいいケースもあります。
以下はOpenLLaMA 7BをQ4_Kで量子化したときの、CPU/GPUごとのプロファイリングです。
## CPUの場合
llama_print_timings: load time = 291.75 ms
llama_print_timings: sample time = 120.86 ms / 244 runs ( 0.50 ms per token, 2018.81 tokens per second)
llama_print_timings: prompt eval time = 112.03 ms / 2 tokens ( 56.02 ms per token, 17.85 tokens per second)
llama_print_timings: eval time = 26430.29 ms / 243 runs ( 108.77 ms per token, 9.19 tokens per second)
llama_print_timings: total time = 26713.21 ms
## GPUの場合
llama_print_timings: load time = 1485.62 ms
llama_print_timings: sample time = 2170.36 ms / 1059 runs ( 2.05 ms per token, 487.94 tokens per second)
llama_print_timings: prompt eval time = 4269.43 ms / 773 tokens ( 5.52 ms per token, 181.05 tokens per second)
llama_print_timings: eval time = 26935.05 ms / 1055 runs ( 25.53 ms per token, 39.17 tokens per second)
llama_print_timings: total time = 33626.36 ms
GPUのほうがロードに時間かかっているのがわかります。
OpenLLaMA 7Bの場合は、一番効率良いのはg5だったものの、g4dnとg5の差はそれほど大きくはなかったのでg4dnでも良いのではないかなとは思われます。
OpenLLaMA 13B Instruct
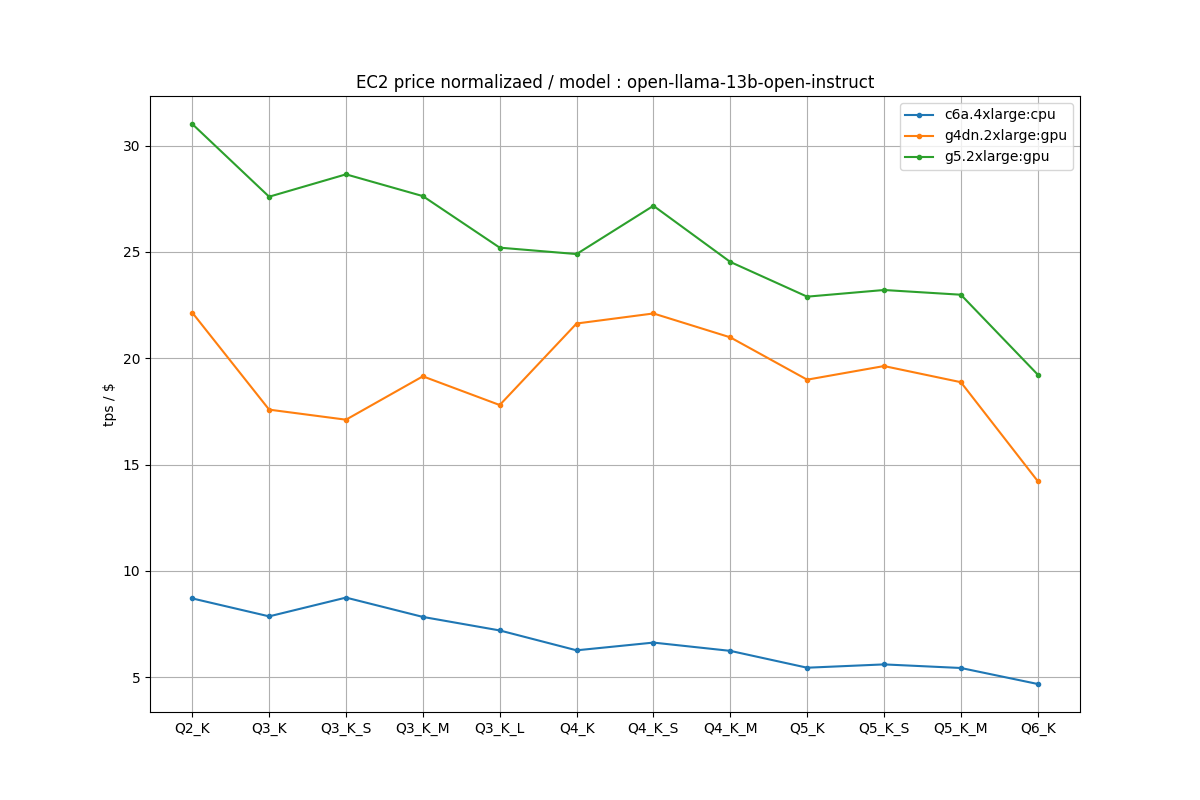
GPU、特にg5の効率の良さが際立ちます。A10gとT4の違いはFlopsも大きく違うのですが、GPUメモリの帯域幅で、T4が320GB/s、A10gが600GB/sとかなり大きく確保されているので、13Bのような巨大なモデルになってくるとここらへんの差が出てくるのではないかと思われます。
T4は量子化に対してなんか頭打ちしているような印象がありますよね。
- https://www.nvidia.com/ja-jp/data-center/tesla-t4/
- https://www.nvidia.com/ja-jp/data-center/products/a10-gpu/
13Bのg4dnのエラー
g4dnの場合は、13Bで1回以下のようなエラーが出て、以降の推論がすべて失敗したことがあります。
main: build = 1011 (dadbed9)
main: seed = 1693663811
CUDA error 100 at /llama.cpp/ggml-cuda.cu:4883: no CUDA-capable device is detected
その直前に大きめの推論(ログファイルで29KB)が走ってCUDA OOMになったのか、デバイス不調なのかは知りませんが、多分たまたまかもしれませんが若干扱いづらさは感じました。実践的にはインスタンスのヘルスチェックが必要だと思います。
結論
- とりあえず使えるならGPU前提で考えるのが良さそう。状況によってはCPUもあり(EC2ではなくLambdaならワンチャンコスパ良い説のありそう)
- バッチ処理として使うか、立ち上げっぱなしにしてチャット的に使うか、といったユースケースでもかなり変わりそう
- 7Bならg4dn、13Bならg5が良さそう
- 困ったのはMiniGPT-4.cppのLLM部分だけをGPUで動かそうとしたらエラーになったこと。全部CPUならいけた
- AutoGPTQのような最近の量子化も合わせて考える必要がありそう
Appendix
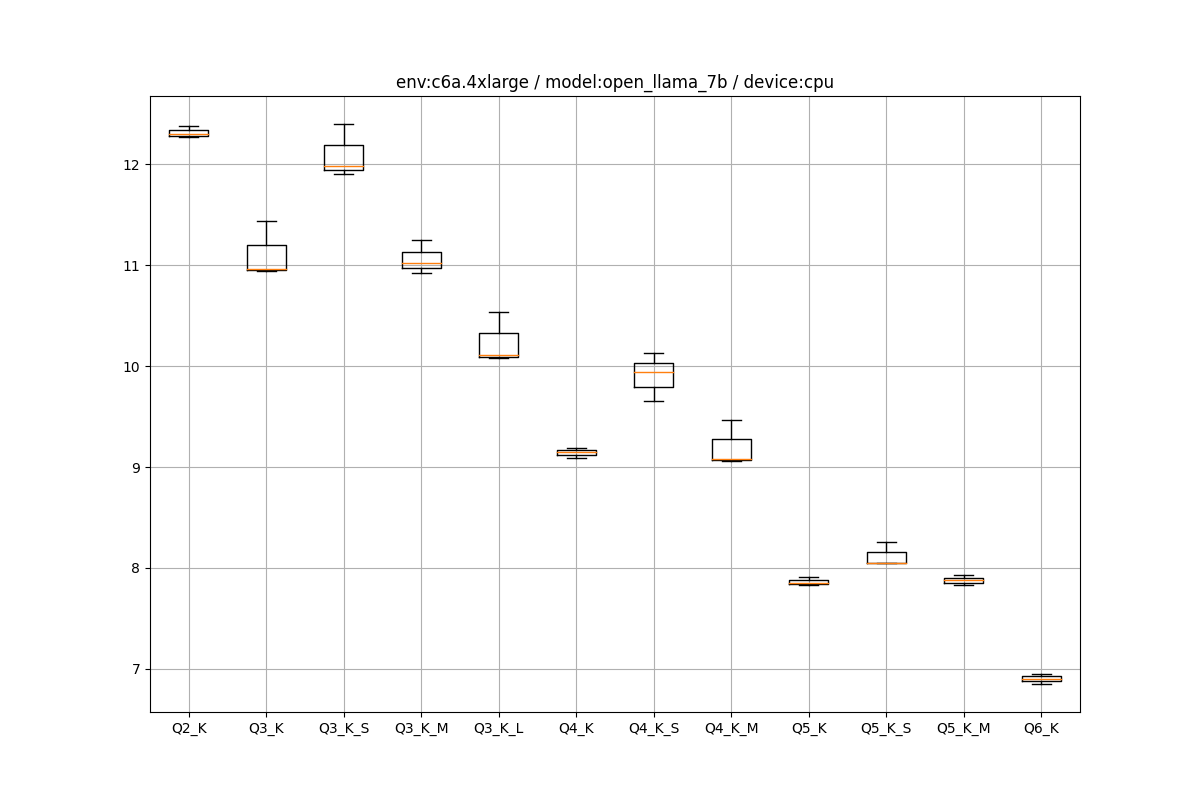
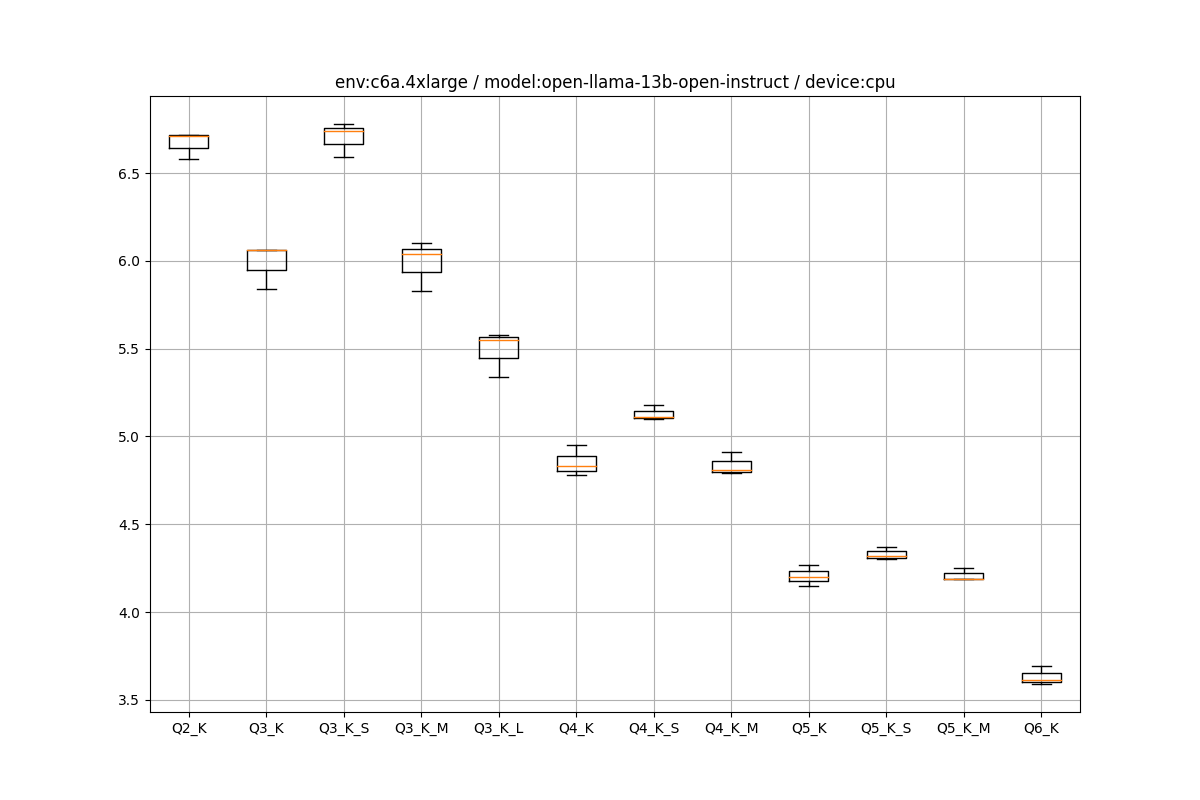
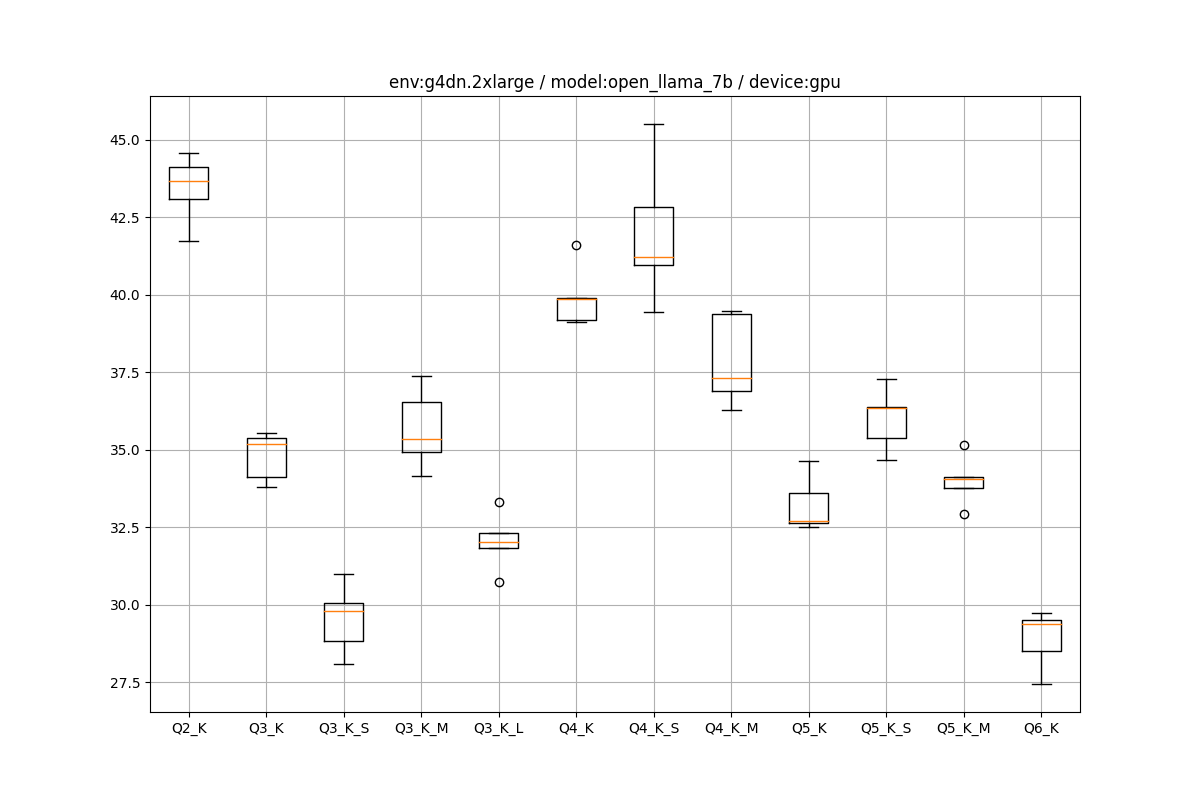
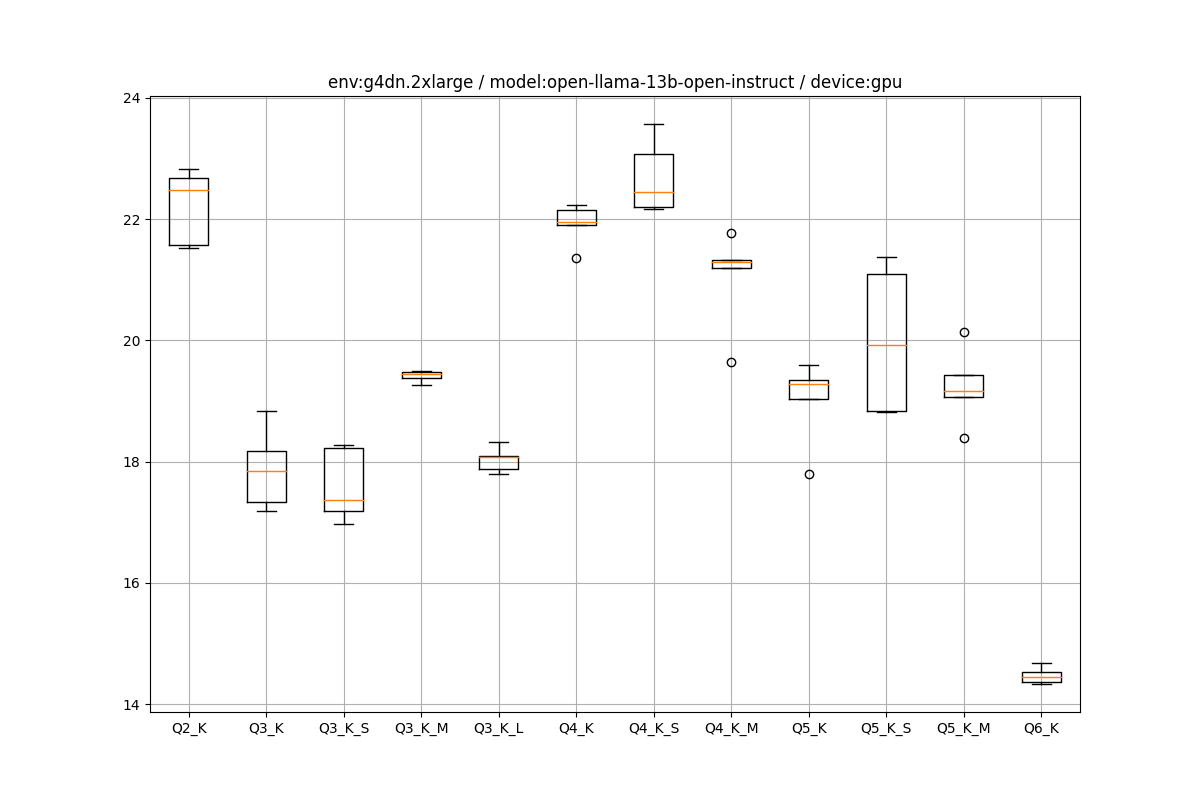
EC2環境の推論の箱ひげ図をペタペタ貼っていきます。
c6a.4xlarge
g4dn.2xlarge
g5.2xlarge
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー