
LLaMA.cpp+(cu)BLASのCPU/GPUのスループット検証(ローカル編)


LLaMA.cppのスループットをローカルで検証してみました。OpenLLaMA 7B/13Bをベースに、CPU/GPUのそれぞれの生成速度(token per second)と量子化の関係を実験的に調査します。
目次
はじめに
LLaMA.cppを使うとモデルを高速に軽量に実行できますが、量子化とスループットの関係、デバイスごとの関係がよくわからなかったので検証しました。
環境
- LLaMA.cpp
- https://github.com/ggerganov/llama.cpp
- 最新版は変換後のモデルがggufフォーマットだが、旧版のggmlのフォーマットを使用(元の利用想定が、MiniGPT4.cppで旧版に統一する必要があったため)
- コミットIDはdadbed9になるように、git cloneしたあとcheckoutする
- ビルドはcuBLASを使ってビルド。実行時のみGPUを使うかどうかを切り替える(mainのnglオプション)
- WindowsのWSL2上のDockerで実行。CPU/GPUを分けて検証
- ローカル環境
- CPU : Core i9-9900K @ 3.60GHz
- RAM : 64GB
- GPU : RTX A6000
- 使用するモデル
検証の流れ
- GPU版のDockerfileを作る
- モデルを量子化
- cuBLASビルド環境なので、CPU/GPU共通の量子化を行う
- 量子化の条件を切り替えて量子化
- 量子化条件:Q2_K Q3_K Q3_K_S Q3_K_M Q3_K_L Q4_K Q4_K_S Q4_K_M Q5_K Q5_K_S Q5_K_M Q6_K
- 2つのモデルに対し、
- 量子化ごとに
- CPU/GPU単位でllama.cppのmainを実行する
- CPUは2回試行
- GPUは5回試行
- 量子化ごとに
llama.cppのmainは公式が用意しているテストプログラムで実行終了時に以下のように、トークンのスループットを標準出力に出してくれる。
llama_print_timings: load time = 2418.52 ms
llama_print_timings: sample time = 15668.21 ms / 16605 runs ( 0.94 ms per token, 1059.79 tokens per second)
llama_print_timings: prompt eval time = 24824.87 ms / 16450 tokens ( 1.51 ms per token, 662.64 tokens per second)
llama_print_timings: eval time = 372292.05 ms / 16540 runs ( 22.51 ms per token, 44.43 tokens per second)
llama_print_timings: total time = 420906.26 ms
これをファイルに書き出すようにしてスループットのデータを取る。この下から2行目の生成時のtokens per second(この例は、44.43)を各条件で比較します。
Dockerfile
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04
RUN apt-get update
ENV TZ=Asia/Tokyo
ENV LANG=en_US.UTF-8
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt-get install -yq --no-install-recommends python3-pip \
python3-dev \
build-essential \
git \
wget \
vim \
cmake \
tzdata && apt-get upgrade -y && apt-get clean
RUN ln -s /usr/bin/python3 /usr/bin/python
RUN git clone https://github.com/ggerganov/llama.cpp
WORKDIR /llama.cpp
RUN git checkout dadbed9
# RUN git clone https://github.com/ggerganov/llama.cpp -b master-31cfbb1
WORKDIR /llama.cpp
RUN pip install --no-cache-dir -r requirements.txt
# develでないとビルド失敗する
WORKDIR /llama.cpp/build
RUN cmake .. -DLLAMA_CUBLAS=ON
RUN cmake --build . --config Release
ENV CUDA_VISIBLE_DEVICES=0
WORKDIR /llama.cpp
LLMの係数のダウンロード
LLMの重みはローカルからマウントさせます。Huggingfaceからのダウンロードコードを事前に実行しておきます。
from huggingface_hub import snapshot_download
def main():
local_root_dir = "G://LLMs/"
snapshot_download(repo_id="openlm-research/open_llama_7b", local_dir=local_root_dir+"openlm-research/open_llama_7b", local_dir_use_symlinks=False)
snapshot_download(repo_id="VMware/open-llama-13b-open-instruct", local_dir=local_root_dir+"VMware/open-llama-13b-open-instruct", local_dir_use_symlinks=False)
if __name__ == "__main__":
main()
この例ではGドライブのLLMsというフォルダに保存していますが、環境に合わせて書き換えてください。
Dockerをビルドしたらrunする前に実行すればいいです。ダウンロードした係数はマウントさせましょう。
docker build -t llama.cpp.compare .
python download_weights
docker run --rm -it --gpus all -v /root/LLMs/:/llms llama.cpp.compare
実験時のシェルスクリプト
open-llama-13b-open-instructのケースでは、特に低量子化ビットのケースで、同じ分を連鎖的に生成して、生成が止まらなくなることがあったので、全てに「–repeat-penalty 1.2 –repeat-last-n 128」のオプションを追加。
以下のシェルスクリプトでは全体にこのオプションが入っているが、open_llama_7bでは入れていない状態で実行しました。
# 量子化
for model in openlm-research/open_llama_7b VMware/open-llama-13b-open-instruct
do
python convert.py /llms/$model
for quantize in Q2_K Q3_K Q3_K_S Q3_K_M Q3_K_L Q4_K Q4_K_S Q4_K_M Q5_K Q5_K_S Q5_K_M Q6_K
do
build/bin/quantize /llms/${model}/ggml-model-f16.bin /llms/${model}/ggml-model-${quantize}.bin ${quantize}
done
done
# スループット
mkdir -p /tmp
for model in openlm-research/open_llama_7b VMware/open-llama-13b-open-instruct
do
for quantize in Q2_K Q3_K Q3_K_S Q3_K_M Q3_K_L Q4_K Q4_K_S Q4_K_M Q5_K Q5_K_S Q5_K_M Q6_K
do
echo COPY ${model}/${quantize}
cp /llms/${model}/ggml-model-${quantize}.bin /tmp/ggml-model-${quantize}.bin
mkdir -p /llms/${model}/result
for i in 1 2
do
echo EVALUATE ${model}/${quantize} ${i}/2 with CPU
build/bin/main -m /tmp/ggml-model-${quantize}.bin -b 512 --repeat-penalty 1.2 --repeat-last-n 128 &>> /llms/${model}/result/${quantize}_cpu_${i}.txt
done
for i in 1 2 3 4 5
do
echo EVALUATE ${model}/${quantize} ${i}/5 with GPU
build/bin/main -m /tmp/ggml-model-${quantize}.bin -ngl 50 -b 512 --repeat-penalty 1.2 --repeat-last-n 128 &>> /llms/${model}/result/${quantize}_gpu_${i}.txt
done
rm /tmp/ggml-model-${quantize}.bin
done
done
まあまあ実行に時間かかるので気長に待ちます(数時間~6時間ぐらい)。
速度の結果
生成時のtokens per second(tps)を箱ひげ図にしました。tpsは多いほうが速いです。縦軸がtpsで、横軸が量子化の条件を表します。
OpenLLaMA 7B
CPU
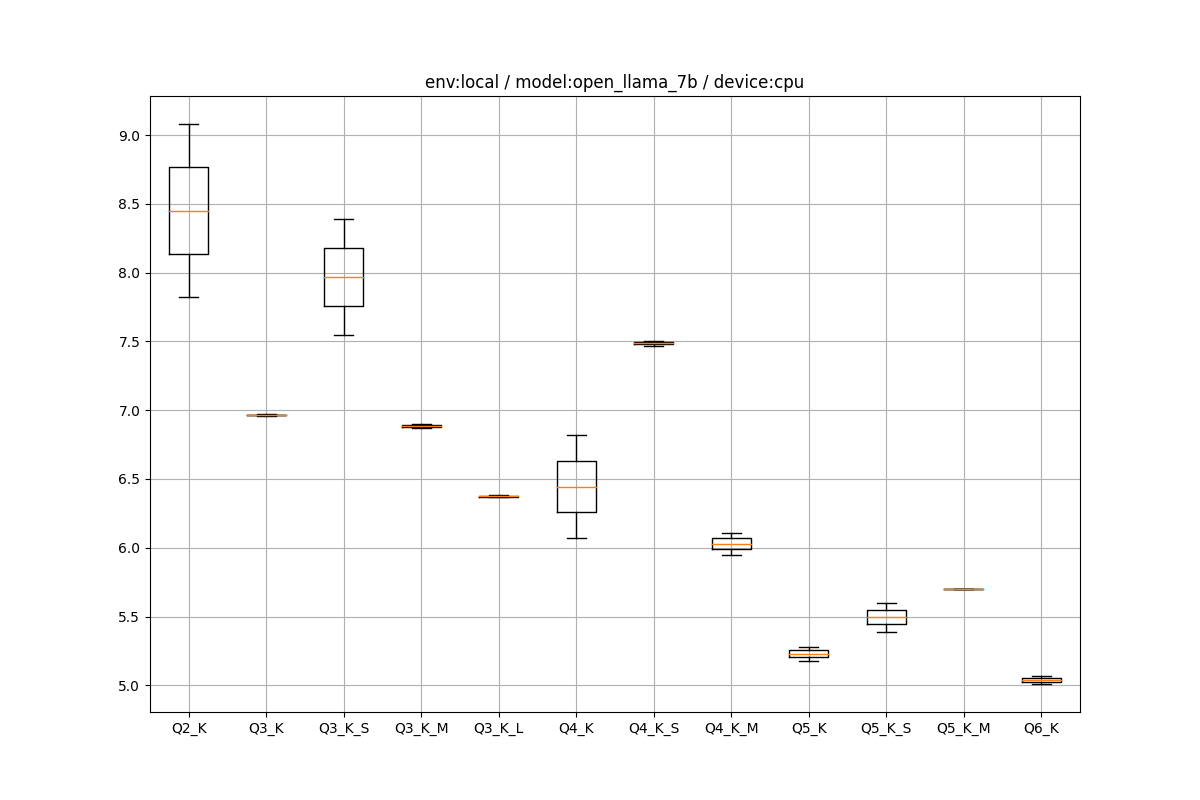
CPUの場合はきれいな関係で、量子化を粗くする(左)とtpsが上がり、量子化を細かくするとtpsが下がります。5~8tpsでした。
GPU
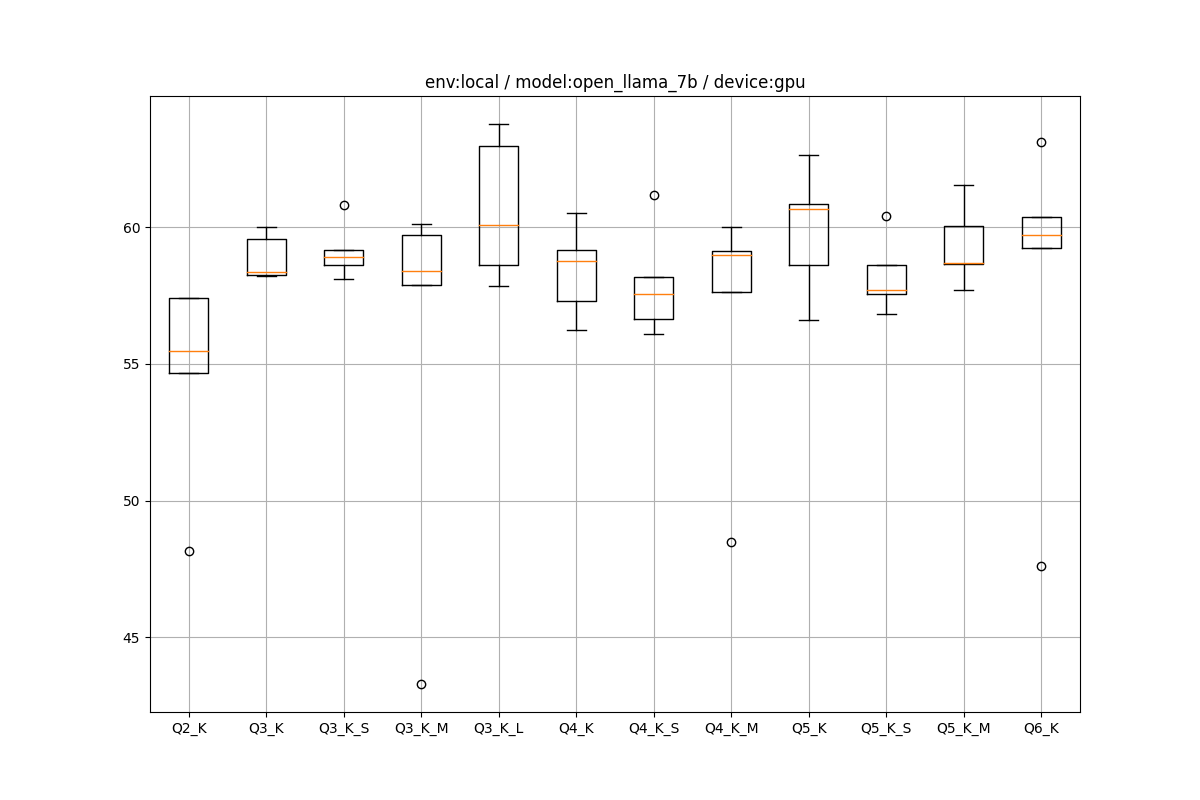
GPUの場合はかなり謎で、量子化が速度にほぼ影響を与えていないという結果になりました。原因は謎ですが、cuBLASにまだ最適化の余地があるのか、5ビットのような中途半端な量子化をGPUがあまり得意としていないのか、I/Oボトルネックが支配的だったのか、GPUのハードウェア依存の問題なのか、もっとオプションを入れるべきなのかなどいろいろ考えられます。
自分が知りたかったのはCPU/GPUの速度比で、7Bの場合はCPUが5~8tps、GPUが60弱tpsという結果になりました。GPUは外れ値も多いのであくまで目安です。
OpenLLaMA 13B Instruct
CPU
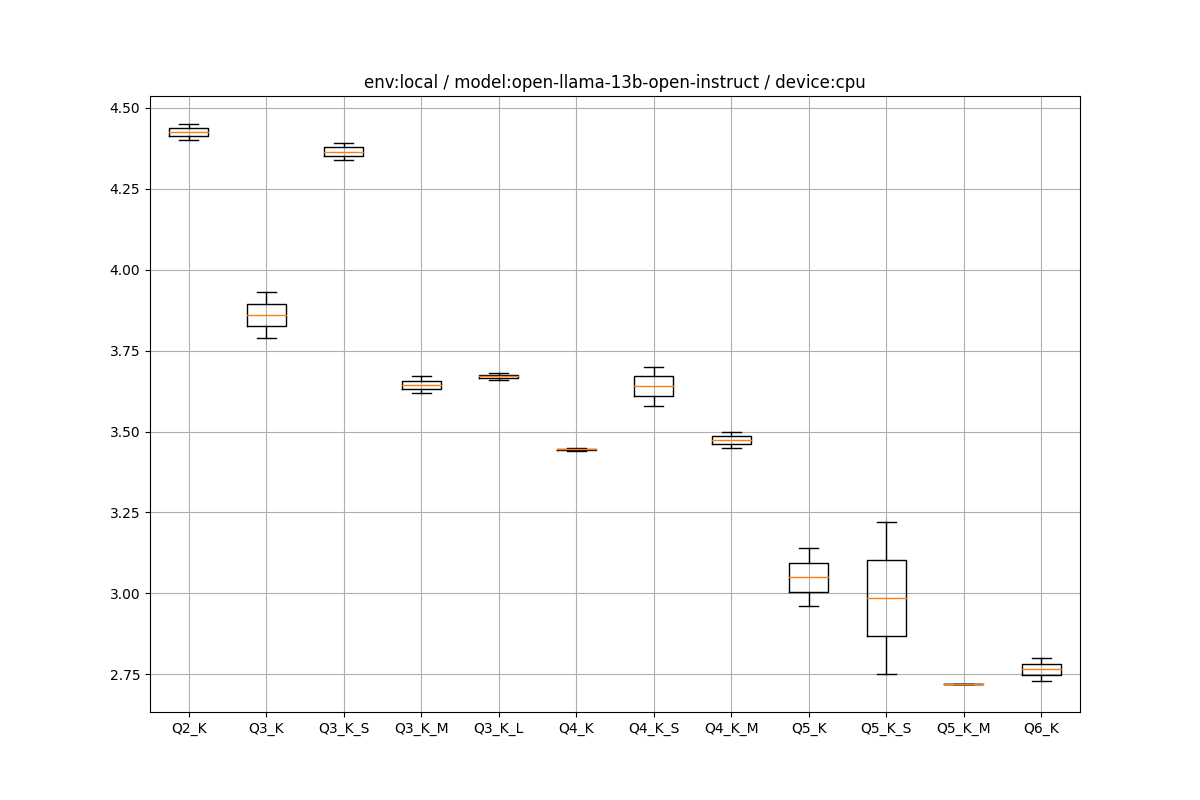
2.75~4.5tpsとなりました。あくまで仮説ですが、tpsはモデルサイズに連動する可能性があります。
- 13BのQ6_Kが2.75tpsで、2.75÷7×13=5.10で、CPU7BのQ6_Kのtpsがだいたいそのぐらい
- 13BのQ2_Kが4.4tpsで、4.4÷7×13=8.17で、CPU7BのQ2Kが8.5なのでおおよそあっている
GPU
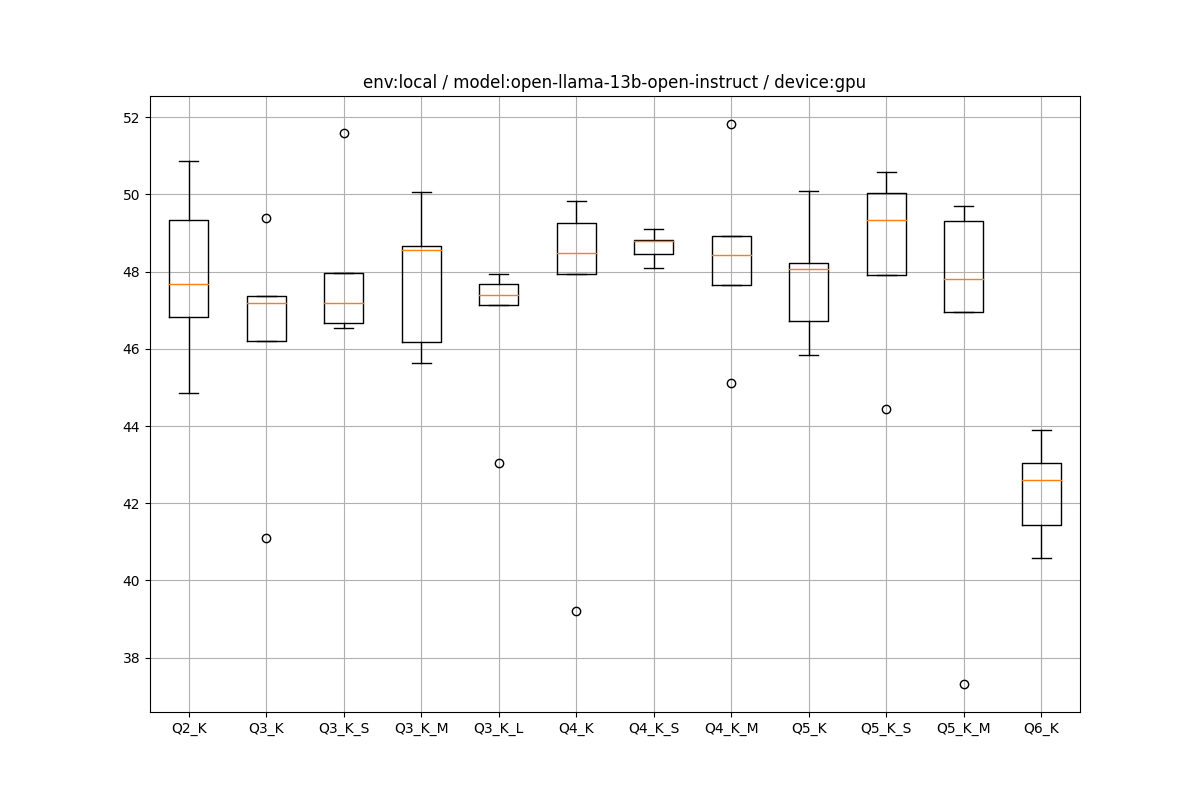
GPUの場合は7Bと変わらなくて、Q6_Kの場合のみちょっと遅くなり、それ以外は約46~50tps内で推移している感じです。
ただ、GPUの場合は7Bで性能を持て余しているのかもしれませんが、7Bのtpsのレンジが60tps程度だったので、モデルサイズとtpsがあまり連動していません。少なくともllama.cppをGPUで使う限りにおいては、小さいモデルや粗い量子化をしたからといって、劇的に速くなるということはなさそうです。劇的に効果出るのはCPUでした。
量子化ごとの生成文章の比較
今回は定量評価でちゃんと検証しませんでしたが、Q2_Kのような極端に粗い量子化をしてしまうと、ほとんど意味のない文章を生成するので注意が必要です。以下の生成結果を示します。
Q2_Kの場合
03:52 PM - djmarty quoted Kip in post What is your favorite 3rd part accessory for your car?
08:19 AM - Kip quoted djmarty in post What is your favorite 3rd part accessory for your car?
07:58 AM - Kip quoted djmarty in post What is your favorite 3rd party accessory for your car? [end of text]
ほとんど意味をなしていません
Q3_Kの場合
#ifndef __CONTEXT_H__
#define __CONTEXT_H__
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/s6trace.h>
#include <asm/machdep.h>
#include <linux/types.h>
#include <pci/pcidevs_pci.h>
#include <pci/pcidevs_cxgbdev.h>
extern int pci_is_root_bus(struct pci_dev *dev);
/* PCI device IDs - PCI-X devices */
enum {
PCIX000000 = 0, /* PCI-X 0 */
PCIX000024 = 1, /* PCI-X 2 */
PCIX001000 = 3, /* PCI-X 4 */
PCIX002000 = 5, /* PCI-X 6 */
PCIX003000 = 7, /* PCI-X 8 */
};
/* PCI device IDs - PCI/PCI-X */
enum {
PCIX100000 = 4, /* PCI/PCI-X 100 */
PCIX200000 = 5, /* PCI/PCI-X 200 */
PCIX300000 = 6, /* PCI/PCI-X 300 */
PCIX400000 = 7, /* PCI/PCI-X 400 */
PCIX500000 = 8, /* PCI/PCI-X 500 */
PCIX600000 = 9, /* PCI/PCI-X 600 */
};
/* PCI device IDs - PCI-X */
enum {
PCIX700000 = 10, /* PCI-X 700 */
PCIX800000 = 11, /* PCI-X 800 */
PCIX900000 = 12, /* PCI-X 900 */
PCIX1000000 = 13, /* PCI-X 1000 */
PCIX1100000 = 14, /* PCI-X 1100 */
PCIX1200000 = 15, /* PCI-X 1200 */
PCIX1300000 = 16, /* PCI-X 1300 */
PCIX1400000 = 17, /* PCI-X 1400 */
PCIX1500000 = 18, /* PCI-X 1500 */
};
[end of text]
C++(?)のコードを吐き出していました。どんなプロンプトを入れたのでしょうか笑
Q4_Kの場合
1. This is a case about how the law should respond to the reality of domestic abuse.
2. In our judgment, this is a case which cries out for legal intervention, because the victim has been left with no real alternative but to take her son home and suffer further indignity and hardship in the context of a violent relationship.
3. The appellant’s submissions were put to us as submissions on two related issues: (1) whether domestic abuse is an “extraordinary” factor which should attract a departure from the ordinary sentencing principles for such cases; (2) the lawfulness or otherwise of a departure from the ordinary sentencing principles under s 143A(7).
4. We heard argument both on each of these issues and also on a separate issue, namely whether the judge erred in her approach to the sentencing exercise by failing to take into account what she identified as the appellant’s “history” of violence towards children, as an aggravating factor.
5. In order to set out the facts of this case, it is necessary to describe the relationship between the appellant and the respondent. The parties have been in a relationship for some 15 or 20 years during which they have had three children. They had another child before the current proceedings, whom they have not sought to remove.
6. In October 2016, the respondent’s parents moved into the family home to help with the running of the home and caring for the three children who were then under 18. The appellant, a former police officer, did not like their presence in the home and began to argue that they should leave. The father, the respondent’s father, asked the appellant to stop arguing with his wife, pointing out that the appellant had once been married to her sister. He told the appellant that, in his opinion, the appellant was behaving badly; he was abusive towards him; he was making unreasonable demands and was preventing her from doing the things she wanted to do. The respondent, at this point, asked him not to intervene. However, the appellant continued to argue with both of them, threatening violence against both of them.
7. The father told the appellant not to shout in their house again and that he would deal with him if he tried it again. On 28 October, the respondent’s sister and mother were woken up by the appellant at about 10.30 in the morning and told to leave the premises. The appellant had been drinking since the previous evening. There was a brief argument between the appellant and his wife before he returned upstairs and the children began packing for the children to go to school that day.
8. The respondent’s parents then went to visit their own parents and, on their return at about 16.30, the appellant returned home after another night of drinking and arguing with his wife. He and the respondents began to argue, and the father told the mother to go upstairs. Eventually, she did.
9. The appellant threw a punch at the father, striking him in the mouth with his right hand. When he realised that his father had been punched, he left the house. At about 17.30, the respondent’s sister and her daughter arrived home. After arguing, the respondents packed the children’s belongings into a bag and took them to school in their car.
10. Before doing this, the appellant was at the car where he told his son and son-in-law that if they went back into the house, he would kill them both. The respondent, having returned to the house, came out of it with the bag and told her father that she was going home. She then drove to school and dropped off the children.
11. The police were called by the appellant at about 20.50. He said he had seen his father punching his brother-in-law and told them he had left his brother and sister-in-law’s house and gone home with the children. He was arrested at 21.09 for assault.
12. The appellant pleaded guilty to assault, and was given a conditional discharge for two years. His appeal was dismissed by the Upper Tribunal Judge. It was held that the appellant had been a heavy drinker and had threatened to kill his sister’s children in front of their parents in the early evening. This was not to be taken lightly, particularly because the threat had been made to the father’s young son, who had also witnessed it.
13. The Upper Tribunal Judge also found that the appellant had assaulted his wife in the previous few months, had threatened to kill her and she had suffered mental health problems, including depression. He had also beaten his wife a number of times. In all those circumstances, he was sentenced on the basis that the assault was motivated by anger and jealousy, and he saw no reason to interfere with the sentence passed at first instance. The Upper Tribunal Judge considered that there was no error in law. [end of text]
このぐらいからだいぶ見れるような文章を出してきます。
Q5_Kの場合
16800.00 sqft. - 29711.00 sqft.
Joyful and bright 2/3 bhk apartment is available for sale in Vaishali, Ghaziabad. Vaishali is the name of a city where the best of contemporary living meets practicality and style. Vaishali is a new residential project built by Vaishali Developers. It is a peaceful township that offers you all the necessary amenities, facilities, and recreational activities.
Vaishali is located at Vaishali, Ghaziabad. Vaishali has many residential as well as commercial properties to cater to the need of its residents. Vaishali is located in close proximity to many schools, colleges, hospitals, malls, shops, markets, and bus stand. Some of the major landmarks around Vaishali include Vaishali Metro Station, Vaishali Railway Station, Raj Nagar Industrial Area, Aliganj, Loni Industrial Area, Ghaziabad Airport, and Noida City Center Mall.
I am interested in 2 BHK Apartment for Sale in Vaishali, Vaishali, Ghaziabad. Please provide me the details . [end of text]
英語の場合は4と5の違いはよくわかりませんでしたが、他の言語や他のドメイン知識を要求する場合は有効かもしれません。
まとめ
- LLaMA.cppのスループットをローカルで検証した
- 現段階のggmlにおいては、CPUは量子化でスループットが上がったが、GPUは量子化してもスループットが上がらなかった
- A6000という良いGPUでやっているからサチっている可能性も否定できないので、もっと性能の悪いGPUでやったら変わるかもしれない
- これだけ見るとGPU優勢だが、GPUのハードウェア別のスループットは気になるので、EC2のインスタンスでも検証してみたい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー