
【12モデル比較】OpenAI・Gemini・ローカルLLMをファインチューニングしてGitHubライセンス判定


ModernBERTでの敗北から一転、OpenAI・Gemini・OSS LoRAを含む計12モデルのファインチューニング性能をGitHubライセンス判定タスクで徹底検証しました。APIモデルの圧倒的な精度とOSSモデルの持続可能性を天秤にかけ、コスト対効果や将来の廃止リスクまで踏まえた「今選ぶべき現実解」を明らかにします。
目次
はじめに:Encoder の限界からLLMへ
前回の記事では、ModernBERT を使って GitHub リポジトリのライセンス属性を自動判定するシステムを構築しました。結果は macro F1 = 0.675 で、OpenAI のファインチューニング (0.816) に大差で敗北。encoder モデルは「パターンマッチ」には強いものの、ライセンスの商用利用可否のような「推論」を要する判定には限界があることが分かりました。
では、LLM(生成モデル)のファインチューニングならどうでしょうか。
前回は「コストが許容できるなら OpenAI fine-tuning 一択」と結論でしたが、気になる点がいくつかあります。
- OSS のLLMで LoRA を訓練すれば、API に匹敵する精度が出るのではないか
- OpenAI 以外の API (Gemini 等) はどうか?
- そもそも API FT モデルはいつまで使えるのか?
今回はこれらの疑問に答えるべく、OpenAI 5 設定 / Gemini 1 設定 / OSS LoRA 6 設定の計 12 モデルを一気に比較しました。
タスク設計:13 ラベルの分類
入力
GitHub リポジトリの README と LICENSE ファイルを結合したマークダウンテキストです。1 リポジトリあたり数百〜数千トークンになります。
出力スキーマ
モデルには以下の 13 の boolean 属性を JSON で出力させます。
| # | ラベル名 | 判定内容 |
|---|---|---|
| 1 | has_license_file |
LICENSE ファイルが存在するか |
| 2 | has_license_in_readme |
README にライセンス記述があるか |
| 3 | is_license_consistent |
LICENSE と README の記述が一貫しているか |
| 4 | is_model_public |
モデルの重みが公開されているか |
| 5 | has_separate_model_license |
モデル専用のライセンスがあるか |
| 6 | has_commercial_usage_warning |
商用利用に関する警告があるか |
| 7 | is_code_commercial_use_allowed |
コードの商用利用が許可されているか |
| 8 | is_code_license_commercially_permissive |
コードライセンスが商用に寛容か |
| 9 | requires_author_contact_for_commercial_use |
商用利用に著者への連絡が必要か |
| 10 | is_model_commercial_use_allowed |
モデルの商用利用が許可されているか |
| 11 | is_model_license_commercially_permissive |
モデルライセンスが商用に寛容か |
| 12 | is_dataset_paper |
データセットに関する論文か |
| 13 | is_dataset_license_commercially_permissive |
データセットライセンスが商用に寛容か* |
※ ラベル 13 は is_dataset_paper=True のサンプルのみを対象に評価する条件付きラベルです。
データ構成
| 件数 | 用途 | |
|---|---|---|
| 訓練データ | 140 件 | 全モデル共通 |
| テストデータ | 60 件 | 評価用(訓練には未使用) |
評価指標
条件付きラベル (13) を除く 12 ラベルの F1 スコアの平均 (macro F1) を主指標とします。各ラベルについて Precision / Recall も算出しています。
各モデルのアプローチ
今回試した 12 モデルは、大きく 3 つのアプローチに分けられます。
アプローチ 1:API ファインチューニング (OpenAI)
OpenAI のファインチューニング API を使い、JSONL 形式の訓練データでモデルを学習させます。最も手軽な方法で、GPU 不要、数分〜数十分で訓練が完了します。
| ベースモデル | 備考 |
|---|---|
| gpt-4o-mini | デフォルト設定。前回記事で使用したモデル |
| gpt-4.1-mini | デフォルト設定。4o-mini の後継 |
| gpt-4.1-nano | デフォルト設定 |
| gpt-4.1-nano | 中間チェックポイント (step-840) |
| gpt-4.1-nano | epoch=3(学習量を抑制) |
gpt-4.1-nano については、デフォルト / 中間チェックポイント / epoch 削減の 3 パターンで学習量の影響を調べています。
アプローチ 2:API ファインチューニング (Gemini)
Google の Vertex AI を使い、Gemini モデルをファインチューニングします。OpenAI と同様に GPU 不要で、JSON スキーマを指定した構造化出力が可能です。
訓練データのフォーマットが OpenAI とは若干異なり、Gemini 側のスキーマにはライセンス名を出力する文字列フィールド(code_license, model_license, dataset_license)も含まれています。
※この理由は、以前試しいたコードを流用したためで、そこまで細かくチューニングしていなかたたからです。
アプローチ 3:OSS モデル LoRA
オープンソースの生成モデルに LoRA (Low-Rank Adaptation) を適用して訓練します。API に依存せず、モデルの重みを完全に手元に置けるのが最大の利点です。
| ベースモデル | パラメータ | 方式 | エポック |
|---|---|---|---|
| Qwen3-8B | 8B | LoRA | 3 |
| Qwen3-14B | 14B | QLoRA (4-bit) | 6 |
| Llama-3.1-8B-Instruct | 8B | LoRA | 5 |
| Ministral-8B-Instruct | 8B | LoRA | 5 |
| Ministral-8B-Instruct (retry) | 8B | LoRA | 5 |
| Ministral-14B-Instruct | 14B | LoRA | 5 |
全モデル共通で LoRA rank=16, alpha=32, 学習率 2e-4, 最大シーケンス長 8192 を使用しています。訓練には completion-only loss を採用しており、プロンプト部分の損失を無視してモデル出力部分のみで学習させます。
Ministral-8B の「retry」は、JSON パース失敗時にリトライする戦略を加えた評価です。モデル自体は同一の重みを使用しています。
エポック数は最初3で試したら、少し学習が足りていないようだったので、少し調整しました。
訓練環境
OSS LoRA の全モデルは EC2 g6e.2xlarge (NVIDIA L40S 48GB) で訓練しました。訓練時間は 8B モデルで約 30 分、14B モデルで約 1 時間です。
なお、Windows 環境での訓練も試みましたが、WDDM ドライバの TDR (Timeout Detection and Recovery) により長いバッチの処理でフリーズする問題が発生しました。Windows でローカル訓練する場合は WSL2 の利用を推奨します。
結果:macro F1 ランキング
12 モデルの macro F1 を一覧にすると、以下のようになります。
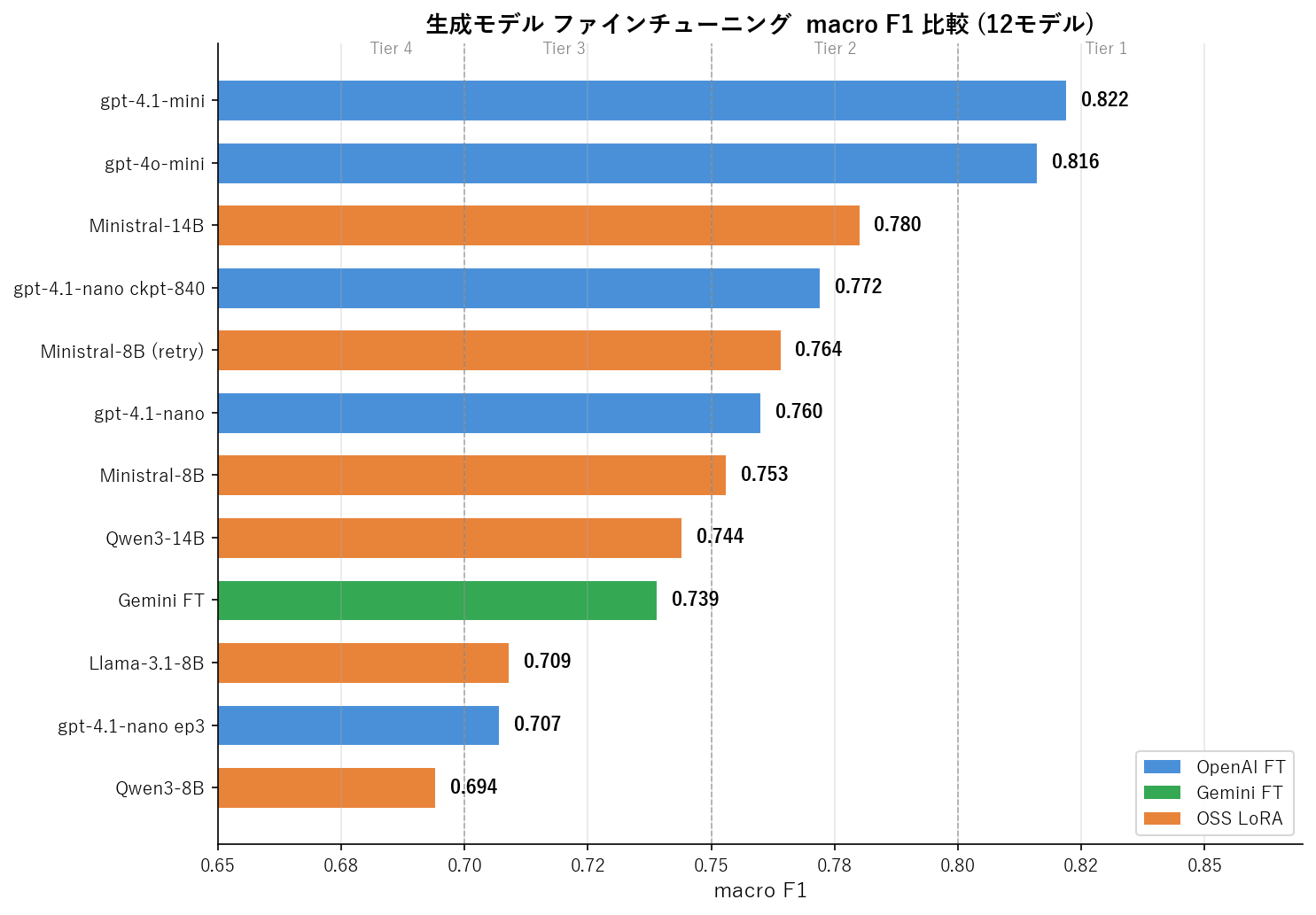
| 順位 | モデル | 方式 | サイズ | macro F1 | parse 失敗 |
|---|---|---|---|---|---|
| 1 | gpt-4.1-mini | OpenAI FT | – | 0.822 | 0/60 |
| 2 | gpt-4o-mini | OpenAI FT | – | 0.816 | 0/60 |
| 3 | Ministral-14B | LoRA | 14B | 0.780 | 2/60 |
| 4 | gpt-4.1-nano ckpt-840 | OpenAI FT | – | 0.772 | 0/60 |
| 5 | Ministral-8B (retry) | LoRA | 8B | 0.764 | 3/60 |
| 6 | gpt-4.1-nano | OpenAI FT | – | 0.760 | 0/60 |
| 7 | Ministral-8B | LoRA | 8B | 0.753 | 4/60 |
| 8 | Qwen3-14B | QLoRA | 14B | 0.744 | 3/60 |
| 9 | Gemini FT | Google FT | – | 0.739 | 0/60 |
| 10 | Llama-3.1-8B | LoRA | 8B | 0.709 | 2/60 |
| 11 | gpt-4.1-nano epoch3 | OpenAI FT | – | 0.707 | 0/60 |
| 12 | Qwen3-8B | LoRA | 8B | 0.694 | 3/60 |
結果を見ると、明確な 4 つの性能階層 が浮かび上がります。
Tier 1 (0.82) : gpt-4.1-mini, gpt-4o-mini ← API mini 系
Tier 2 (0.76-0.78) : Ministral-14B, nano-ckpt, Ministral-8B ← OSS 14B / API nano
Tier 3 (0.71-0.74) : Qwen3-14B, Gemini FT, Llama-3.1-8B ← 一段落ちる
Tier 4 (0.69-0.71) : nano-epoch3, Qwen3-8B ← 下位
前回記事の ModernBERT (0.675) は Tier 4 にも入れない水準で、encoder → 生成モデルの切り替えによる改善幅の大きさが改めて確認できます。
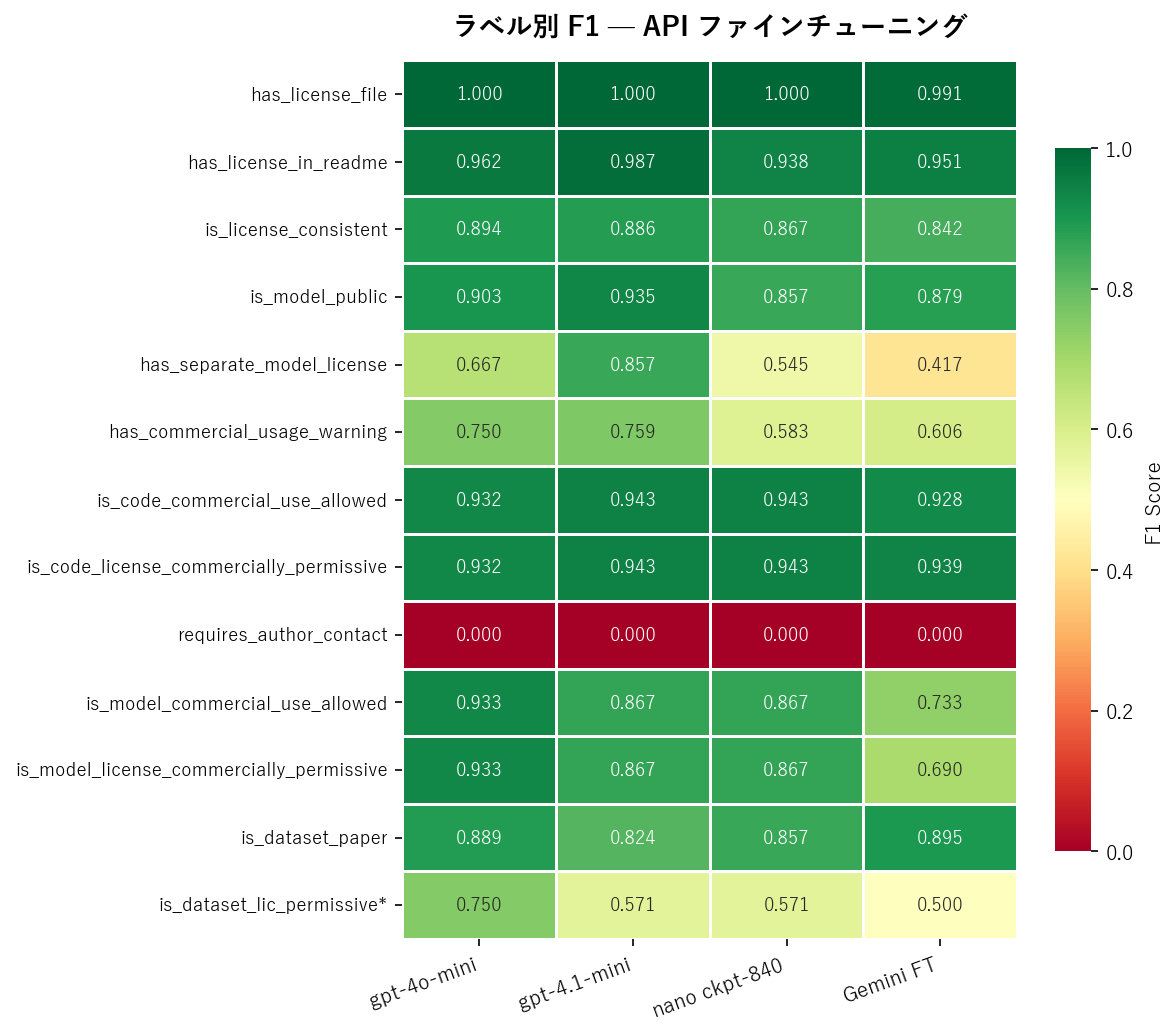
ラベル別 F1:API ファインチューニング
代表的な 4 モデルのラベル別 F1 です。requires_author_contact の行が真っ赤(全モデル F1=0)なのが目を引きます。
ラベル別 F1:OSS LoRA
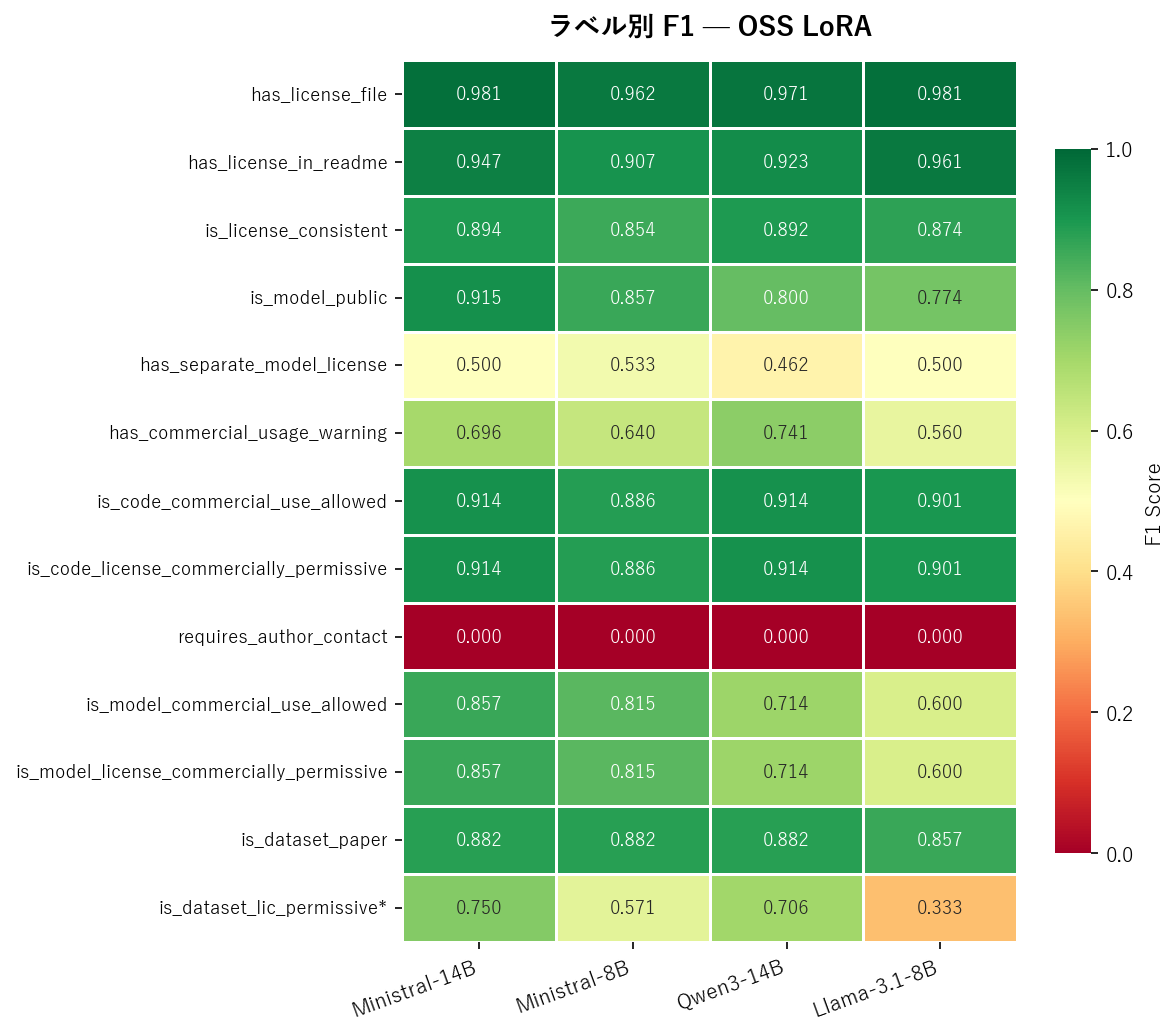
※ is_dataset_lic_permissive は is_dataset_paper=True のサンプルのみで評価(n=19)
分析:なぜこの順位になったのか
OpenAI >> Gemini:API FT
API ファインチューニング同士の比較で、最も意外だったのは Gemini の低さ です。
| OpenAI gpt-4.1-mini | Gemini FT | 差 | |
|---|---|---|---|
| macro F1 | 0.822 | 0.739 | +0.083 |
| parse 失敗 | 0/60 | 0/60 | 同等 |
GeminiはGemini 2.5 Flash Liteのファインチューニングです。
Gemini FT は OpenAI の最小モデル gpt-4.1-nano (0.760) にも届かず、OSS の Ministral-8B (0.764) にすら負けています。JSON パースの安定性は完璧 (0/60) なのですが、判定精度自体が低いという結果でした。
ただし、Gemini FT の訓練データは OpenAI / OSS と完全には同一でなく(ラベルセットに微差あり)、訓練設定の最適化余地も残されています。条件を揃えた再評価が必要です。
Ministral の圧勝:OSS LoRA の勝者
OSS モデル 8B 同士の比較で、Ministral の優位性は顕著でした。
| モデル | macro F1 | 特に強いラベル |
|---|---|---|
| Ministral-8B | 0.764 | モデル商用判定 (0.815) |
| Llama-3.1-8B | 0.709 | README 解析 (0.961) |
| Qwen3-8B | 0.694 | データセット判定 (0.882) |
Ministral は特に ライセンスの商用利用判定 (is_model_commercial_use_allowed, is_model_license_commercially_permissive) で他を大きく引き離しています。これは単純な文面一致ではなく、ライセンス条項の法的意味を理解した上での判断が必要なラベルです。Mistral の事前学習データにライセンス関連の法的テキストが豊富に含まれている可能性が示唆されます。
具体的に使用したモデルは、mistralai/Ministral-3-8B-Instruct-2512というものでしたが、Llama 3.1やQwen3などと比べて登場が新しいため、そのぶん性能が伸びやすかったというのはあるかと思います。
スケーリング効果:8B → 14B でどれだけ伸びるか
同じアーキテクチャで 8B と 14B を比較すると、興味深い差が見えます。
| ベースモデル | 8B | 14B | 改善幅 |
|---|---|---|---|
| Ministral | 0.764 | 0.780 | +0.016 |
| Qwen3 | 0.694 | 0.744 | +0.050 |
Qwen3 は 8B → 14B で大幅に改善 (+0.050) しましたが、Ministral は小幅な改善 (+0.016) にとどまっています。これは Ministral-8B が既に高い水準にあるため、スケーリングの恩恵が逓減しているためと考えられます。
いずれにせよ 14B でも gpt-4.1-mini (0.822) には届きませんでした。OSS LoRA で API mini 系に匹敵するには、Mistral Small 24B 以上のモデルサイズが必要かもしれません。
nano の学習量実験:多ければいいわけではない
gpt-4.1-nano については 3 つの学習設定を試しました。
| 設定 | macro F1 | 解釈 |
|---|---|---|
| epoch=3(学習量を抑制) | 0.707 | 学習不足。商用判定ラベルが大幅劣化 |
| デフォルト (final) | 0.760 | 一部ラベルで過学習気味 |
| 中間チェックポイント (step-840) | 0.772 | 最適な学習量 |
最良はデフォルト設定の 中間チェックポイント で、epoch 数の削減は逆効果でした。nano のような小規模モデルでは最適な学習量の幅が狭く、epoch 数のチューニングよりも中間チェックポイントの選択が有効です。
全モデル共通の闇:requires_author_contact が F1 = 0
12 モデル全てで F1 = 0.000 という異常な結果になったラベルがあります。requires_author_contact_for_commercial_use(商用利用に著者への連絡が必要か)です。
テストデータ中の正例は 25/60 件 (42%) と少なくないにもかかわらず、OpenAI の最強モデルも、OSS の全モデルも、Gemini も、一切正例を予測できませんでした。
これはモデルの能力の問題ではなく、ラベル自体の問題と考えるのが妥当です。
- 訓練データにおける正例の分布がテストデータと大きく異なる可能性
- 「著者への連絡が必要」という属性は、README/LICENSE の文面から読み取れる明確な手がかりが少ない
- ラベル定義自体が曖昧で、人間のアノテーションにもブレがある可能性
このラベルを除外すると、macro F1 の理論的上限は約 0.90 です。現時点の最高 0.822 は 天井の 91% に到達しており、残り 9% の改善にはラベル品質の改善が不可欠です。
JSON parse の安定性:API は完璧、OSS は工夫が必要
| 方式 | parse 失敗率 |
|---|---|
| OpenAI FT | 0/60 (0%) |
| Gemini FT | 0/60 (0%) |
| OSS LoRA | 2〜4/60 (3〜7%) |
API FT は JSON 出力が完全に安定しています。OpenAI は response_format でスキーマを指定でき、Gemini も response_schema で構造化出力を強制できるため、フォーマット崩れが一切起きません。
一方、OSS LoRA ではシステムプロンプトで JSON フォーマットを指示していますが、出力が完全には保証されません。ただし、parse 失敗時にリトライする戦略で軽減可能です。Ministral-8B では リトライにより失敗が 4 件 → 3 件に減少し、macro F1 も 0.753 → 0.764 に改善しました。
コストと持続性:本当の敵は「モデル廃止」
OpenAI の価格:F1 差 0.006 にコスト 2.67 倍
OpenAI のファインチューニング価格 (per 1M tokens) は以下の通りです。
| モデル | 訓練 | 推論 Input | 推論 Output |
|---|---|---|---|
| gpt-4.1-nano | $1.50 | $0.20 | $0.80 |
| gpt-4o-mini | $3.00 | $0.30 | $1.20 |
| gpt-4.1-mini | $5.00 | $0.80 | $3.20 |
| gpt-4.1 | $25.00 | $3.00 | $12.00 |
ここで注目すべきは、1 位の gpt-4.1-mini と 2 位の gpt-4o-mini の費用対効果です。
| gpt-4o-mini | gpt-4.1-mini | 倍率 | |
|---|---|---|---|
| macro F1 | 0.816 | 0.822 | 差 0.006 |
| 推論 Input | $0.30/1M tok | $0.80/1M tok | 2.67x |
| 推論 Output | $1.20/1M tok | $3.20/1M tok | 2.67x |
F1 差はわずか 0.006 で、テストデータ 60 件での統計的な揺れの範囲です。それに対して推論コストは 2.67 倍。純粋なコストパフォーマンスでは gpt-4o-mini が圧勝しています。
GPT-4o / 4.1 廃止の衝撃
しかし、「安くて精度もいい gpt-4o-mini を使い続ければいい」という結論には落とし穴があります。
2026 年 2 月、OpenAI は GPT-4o, GPT-4.1, GPT-4.1 mini を含む複数のモデルを ChatGPT からの提供を終了すると発表しました。API 経由の利用はしばらく継続されるものの、方向性は明確です。
- OpenAI は GPT-5.2 への一本化 を推進中
- 4o / 4.1 系は「旧世代」の扱い
- API も遠からず廃止されるのは時間の問題
GPT-5.2 FT の価格見通し
OpenAI の価格推移を見ると、世代が上がるほどファインチューニング費用も高くなる傾向が明確です。
gpt-4.1-nano: 訓練 $1.50 推論 $0.20/$0.80
gpt-4o-mini: 訓練 $3.00 推論 $0.30/$1.20
gpt-4.1-mini: 訓練 $5.00 推論 $0.80/$3.20
gpt-4.1: 訓練 $25.00 推論 $3.00/$12.00
GPT-5.2 の FT 価格が gpt-4.1 ($25) 相当かそれ以上になる可能性は十分にあります。仮に $25〜50 の訓練コストを払っても、0.822 → 0.85 程度の改善にとどまるかもしれません。
先述の通り、requires_author_contact が全モデル F1=0 な限り、macro F1 の理論的天井は約 0.90 です。現時点の最高 0.822 は天井の 91% に到達しており、残り 9% のためにコスト 5〜10 倍は費用対効果が低いと言わざるを得ません。
API FT vs OSS LoRA:長期で見るとどうか
| 観点 | API FT (OpenAI) | OSS LoRA |
|---|---|---|
| 現時点の精度 | 0.822 | 0.780 |
| 精度差 | – | -0.042 |
| モデル廃止リスク | 高い (1〜2 年周期) | なし |
| 再訓練コスト | 毎世代 $5〜25+ | 初回のみ |
| 推論コスト | 従量課金 | GPU 固定費のみ |
| データ主権 | 外部送信 | 完全ローカル |
| 持続性 | プロバイダ依存 | 永続 |
API FT は「安くて手軽に高精度」が魅力ですが、モデル廃止サイクルの加速と世代ごとの値上げにより、その優位性は中長期的に崩れつつあります。
一方、OSS LoRA は精度で 0.04 劣るものの、一度訓練すれば永続的に使えます。0.04 の精度差は「API 依存リスク回避」の対価と捉えることもできます。
結論:どのモデルを選ぶべきか
前回の ModernBERT (macro F1 = 0.675) から出発し、生成モデル(LLM)のファインチューニングで 最大 0.822 まで改善することができました。+0.15 の改善は、encoder → 生成モデルの切り替えによる恩恵です。
では、12 モデルの中からどれを選ぶべきでしょうか。用途に応じた推奨構成は以下の通りです。
短期運用で API 利用が許容される場合
gpt-4o-mini ファインチューニング (macro F1 = 0.816) がおすすめです。
gpt-4.1-mini (0.822) との差はわずか 0.006 で、推論コストは 1/2.67。訓練も数ドルで完了し、最も手軽に高精度を得られます。モデル廃止時は、同じ訓練データを新世代モデルにそのまま FT し直せばよいでしょう。
長期運用またはセルフホスト必須の場合
Ministral-14B LoRA (macro F1 = 0.780) が推奨されます。
OSS 最高精度で、OpenAI の gpt-4.1-nano (0.760) を上回ります。API 依存リスクがなく、モデルの重みとアダプタを保存しておけば永続的に再現可能です。シングルGPUでも動作します。
コスト最小化の場合
Ministral-8B LoRA + retry (macro F1 = 0.764) が選択肢に入ります。
VRAM 24GB程度で推論が完結し、retry 戦略で parse 失敗を軽減しつつ精度も改善します。14B との差は 0.016 で、GPU コストの差を考えると十分な水準です。
前回からのまとめ
| 記事 | アプローチ | 最高 macro F1 | 結論 |
|---|---|---|---|
| 前回 (ModernBERT) | encoder FT | 0.675 | 推論タスクには限界 |
| 今回 (生成モデル) | 生成モデル FT | 0.822 | API > OSS だが、差は縮まりつつある |
前回「コストが許容できるなら OpenAI fine-tuning 一択」と結論づけましたが、今回の実験を経て、その見解を少し修正する必要があります。
短期的には依然として OpenAI FT が最も効率的です。 しかし、モデル廃止サイクルの加速、世代ごとの値上げ、そして OSS モデルの急速な性能向上を考えると、OSS LoRA を「保険」として準備しておく価値は十分にありそうです。
特に Ministral-14B (0.780) は API の nano クラスを超える精度を出しており、API FT との差は 0.04 まで縮まっています。OSS モデルの進化が今のペースで続けば、次世代モデルで API mini 系に並ぶ日もそう遠くないかもしれません。
付録
A. 出力スキーマ全フィールド定義
OpenAI / OSS の訓練データで使用した出力スキーマの全体像です(Gemini はこれに加えてライセンス名の文字列フィールドを含みます)。
{
"has_license_file": true,
"has_license_in_readme": true,
"is_license_consistent": true,
"is_model_public": true,
"has_separate_model_license": false,
"has_commercial_usage_warning": false,
"is_dataset_paper": false,
"is_code_commercial_use_allowed": true,
"is_code_license_commercially_permissive": true,
"requires_author_contact_for_commercial_use": false,
"is_model_commercial_use_allowed": true,
"is_model_license_commercially_permissive": true,
"is_dataset_license_commercially_permissive": false
}
B. gpt-4o-mini vs gpt-4.1-mini:得意ラベルの違い
macro F1 では僅差の 2 モデルですが、得意ラベルが異なります。
| ラベル | 4o-mini | 4.1-mini | 差 |
|---|---|---|---|
| has_separate_model_license | 0.667 | 0.857 | +0.190 |
| is_model_public | 0.903 | 0.935 | +0.032 |
| is_model_commercial_use_allowed | 0.933 | 0.867 | -0.066 |
| is_dataset_paper | 0.889 | 0.824 | -0.065 |
4.1-mini は少数クラスの判定に強く、4o-mini はモデル/データセット関連の推論に強い傾向があります。アンサンブルやラベル別のモデル使い分けで更なる精度向上が期待できます。
C. Precision / Recall 詳細:API FT 上位 2 モデル
gpt-4o-mini (macro F1 = 0.816)
| ラベル | F1 | Prec | Rec |
|---|---|---|---|
| has_license_file | 1.000 | 1.000 | 1.000 |
| has_license_in_readme | 0.962 | 0.950 | 0.974 |
| is_license_consistent | 0.894 | 0.884 | 0.905 |
| is_model_public | 0.903 | 0.875 | 0.933 |
| has_separate_model_license | 0.667 | 0.714 | 0.625 |
| has_commercial_usage_warning | 0.750 | 0.900 | 0.643 |
| is_code_commercial_use_allowed | 0.932 | 0.895 | 0.971 |
| is_code_license_commercially_permissive | 0.932 | 0.895 | 0.971 |
| requires_author_contact | 0.000 | 0.000 | 0.000 |
| is_model_commercial_use_allowed | 0.933 | 0.933 | 0.933 |
| is_model_license_commercially_permissive | 0.933 | 0.933 | 0.933 |
| is_dataset_paper | 0.889 | 0.941 | 0.842 |
gpt-4.1-mini (macro F1 = 0.822)
| ラベル | F1 | Prec | Rec |
|---|---|---|---|
| has_license_file | 1.000 | 1.000 | 1.000 |
| has_license_in_readme | 0.987 | 0.975 | 1.000 |
| is_license_consistent | 0.886 | 0.848 | 0.929 |
| is_model_public | 0.935 | 0.906 | 0.967 |
| has_separate_model_license | 0.857 | 1.000 | 0.750 |
| has_commercial_usage_warning | 0.759 | 0.733 | 0.786 |
| is_code_commercial_use_allowed | 0.943 | 0.943 | 0.943 |
| is_code_license_commercially_permissive | 0.943 | 0.943 | 0.943 |
| requires_author_contact | 0.000 | 0.000 | 0.000 |
| is_model_commercial_use_allowed | 0.867 | 0.867 | 0.867 |
| is_model_license_commercially_permissive | 0.867 | 0.867 | 0.867 |
| is_dataset_paper | 0.824 | 0.933 | 0.737 |
D. OSS LoRA 訓練設定
全モデル共通のハイパーパラメータです。
| パラメータ | 値 |
|---|---|
| LoRA rank (r) | 16 |
| LoRA alpha | 32 |
| LoRA dropout | 0.05 |
| 学習率 | 2e-4 |
| 最大シーケンス長 | 8192 |
| バッチサイズ | 1 (gradient accumulation 4) |
| 重み精度 | bf16 |
| オプティマイザ | AdamW (8-bit) |
| 損失関数 | completion-only loss |
| 訓練環境 | EC2 g6e.2xlarge (NVIDIA L40S 48GB) |
Qwen3-14B のみ QLoRA (4-bit NF4 量子化) を使用し、エポック数を 6 に設定しています。これは 14B モデルの VRAM 使用量を抑えるための措置です。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー