
論文まとめ:LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Posted On 2023-11-16


- タイトル:LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
- 論文URL:https://arxiv.org/abs/2311.05556
- 著者:Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu, Patrick von Platen, Apolinário Passos, Longbo Huang, Jian Li, Hang Zhao(精華大学、Hugging Face)
- プロジェクトページ:https://github.com/luosiallen/latent-consistency-model
- Diffusers版の公式記事:https://huggingface.co/blog/lcm_lora
目次
ざっくりいうと
- Consistency modelsの派生系である、Latent Consistency Models(LCM)を使い推論高速化する研究
- 従来のLoRAはカスタマイズしかできなかったが、ここに推論高速化の要素を加えることに成功
- 従来よりも少ないステップ数で拡散モデルの生成が可能。任意のモデルに適用可能
背景研究
- 従来のDiffusionモデルは推論に多数のステップがいて遅かった。これの改善版としてOpenAIの研究者が「Consistency Models」を発表
- 元論文:https://arxiv.org/abs/2303.01469
- なんかさんの超詳しい理論解説:https://zenn.dev/discus0434/articles/484be111f7862d
- 直感的な理解:拡散モデル(ODE)はノイズとデータの始点・終点の学習だった。Consistency modelsは途中の経路も含めて学習することで、収束を速くする。
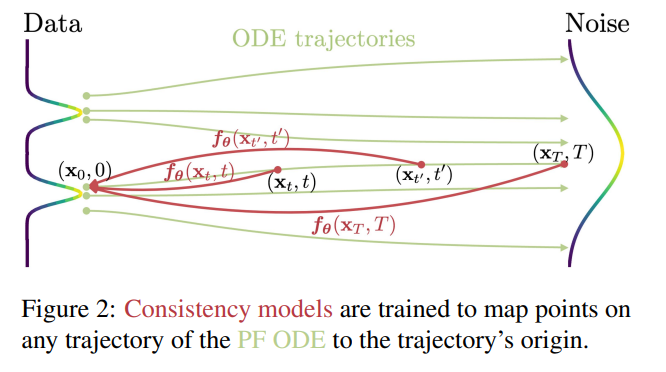
- Consistency modelsの発展形として、これを蒸留の方向で活用したLatent Consistency Models(LCM)が発表される
- 元論文:https://arxiv.org/abs/2310.04378
- 潜在空間の値が各ステップで同一になるような蒸留を提唱。これにより拡散モデルの推論速度が飛躍的に向上する
- Consistency Modelsは拡散モデルとは別のモデルだが、拡散モデルの速度向上(蒸留)においてもこの考え方が有効
- ただし、論文が確率微分方程式の展開で非常に読むのがつらい(本気で理解しようとすると相当の時間が必要そう)

repeat以下の数式(コードで理解するとそこまで難しくはない)
* 1行目:z:ノイズ、cはプロンプトといった条件
* 2行目:ノイズのサンプリング
* 3行目:Guidance Scaleの複数パスを考慮した版
* 4行目:普通の蒸留プロセス
* 5行目:Back Propergation
* 6行目:EMA
- LCMをLoRAにしたのがこのLCM-LoRA
概要
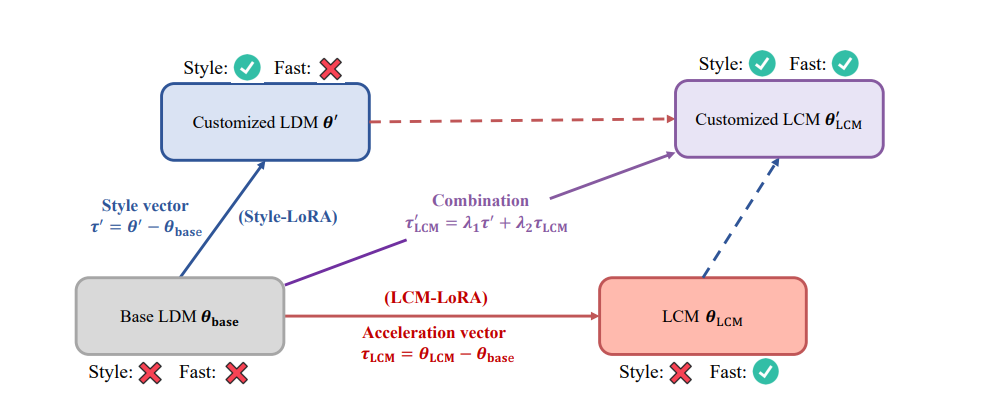
- LCMのような推論高速化を併せ持ちつつ、LoRAのようなカスタマイズが可能
- LCMは推論ステップ数を減らして高品質な画像ができるようにするための蒸留で、モデルサイズを軽量化するような蒸留ではない
- モデルの依存性はなく、SD1.5、SSD-1B、SDXLといった拡散モデルに適用可能
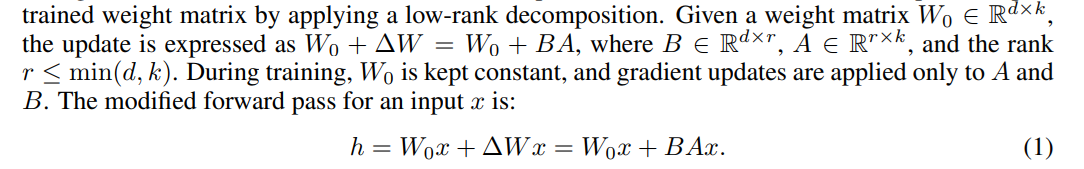
LoRAのアップデートプロセス。LCMの蒸留プロセスを訓練のフォワードパスに置き換えることが可能。LoRAを使うことで訓練パラメーター数を減らすことが可能。

LCM-LoRAを作ることで、汎用的に推論を加速することができる。
従来のLoRAはコンテンツ方向のカスタマイズだったが、これに推論の加速方向のマージを加えることができる。

ここでτ’がコンテンツ方向のカスタマイズ、τ_LCMが推論加速方向。それぞれλ1,2というマージのハイパーパラメータを持つ。
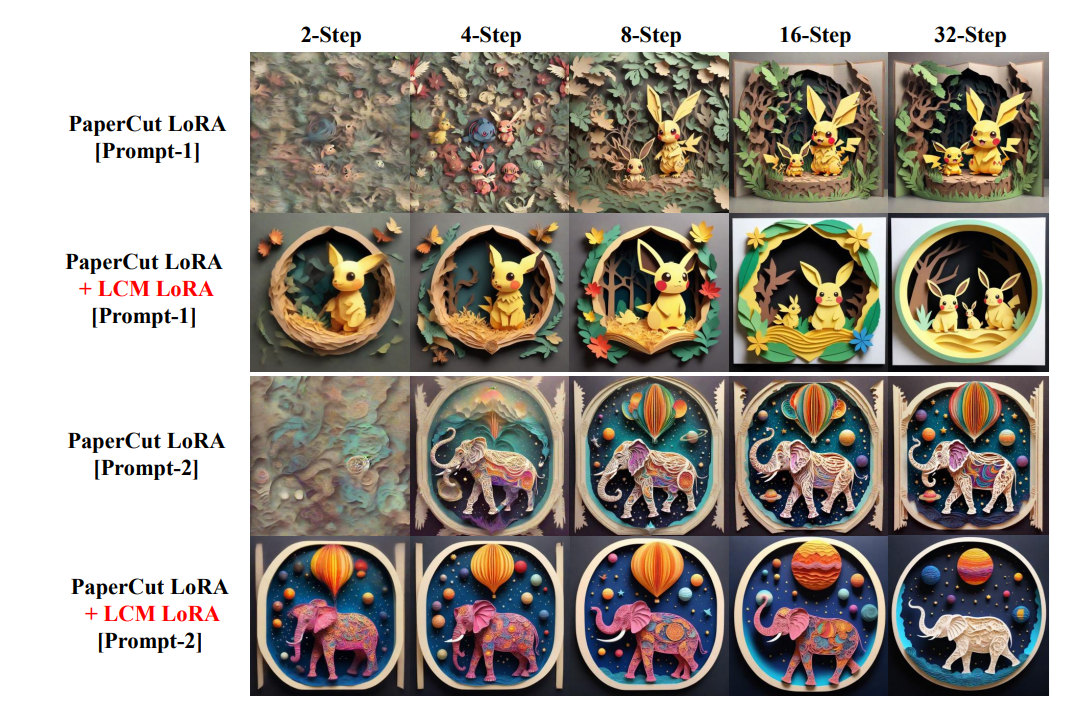
LCMの効果
LCMの論文より。理論部分は難しいのでスキップして、実験部分のみ着目。これはLoRAではなく、普通のT2Iの蒸留。
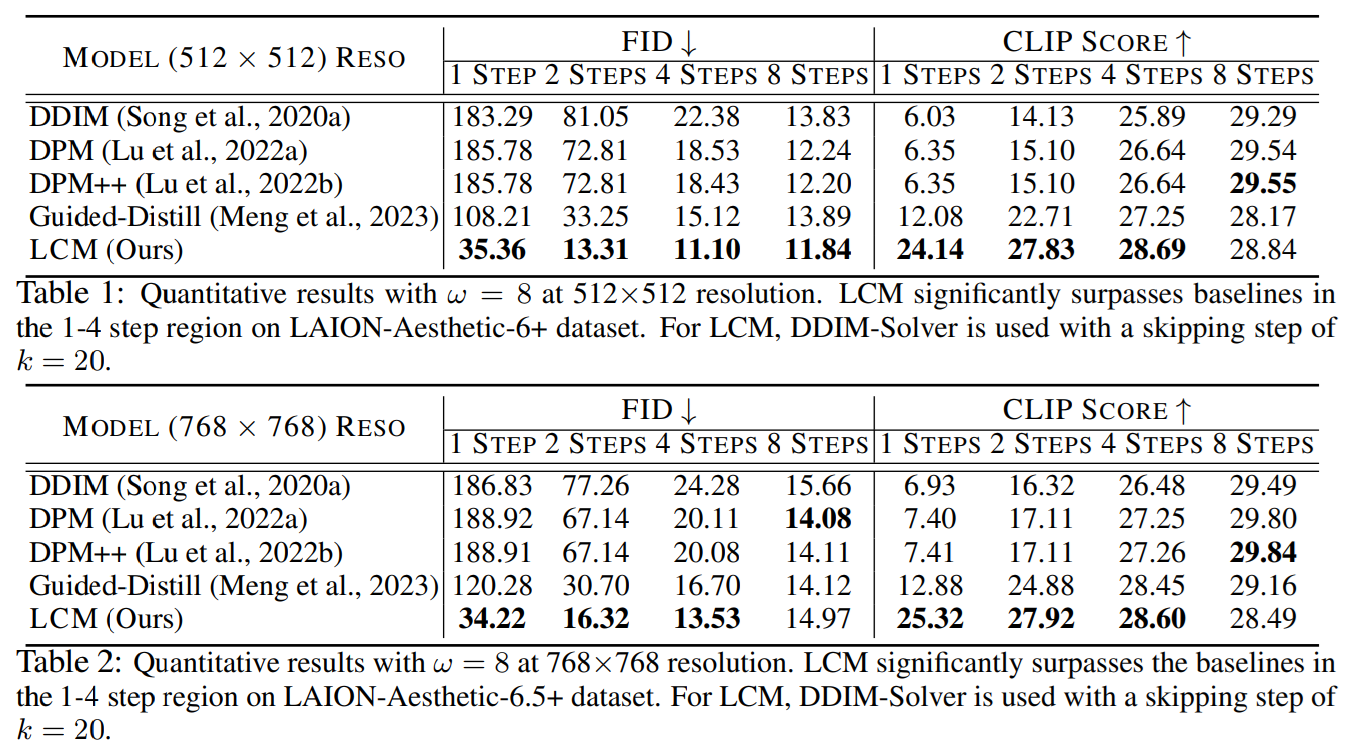
所感
- LoRAに推論加速の意味をもたせるのは時代を先取りしすぎていてすごい!
- これ拡散モデルのように何度も反復させるプロセスだからできる気がする。LLMのように一発推論のクソデカモデルに適用できたら強そう
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー
2 Comments