
論文まとめ:LLM2CLIP: Powerful Language Model Unlock Richer Visual Representation


- 論文タイトル:LLM2CLIP: Powerful Language Model Unlock Richer Visual Representation
- 著者:Weiquan Huang, Aoqi Wu, Yifan Yang, Xufang Luo, Yuqing Yang, Liang Hu, Qi Dai, Xiyang Dai, Dongdong Chen, Chong Luo, Lili Qiu
- 論文URL:https://arxiv.org/abs/2411.04997
- コード:https://github.com/microsoft/LLM2CLIP/
- モデル:https://huggingface.co/collections/microsoft/llm2clip-672323a266173cfa40b32d4c
LLM2CLIP: Powerful Language Model Unlock Richer Visual Representation
目次
ざっくりいうと
- LLMを活用し、CLIPのテキストエンコーダーに従来は困難だった長く複雑なキャプションの処理能力を学習させる研究
- Caption Contrastive(CC)ファインチューニングを提案し、LLMが持っていない線形分離性を学習させる事前訓練を提案。より精度が出て効率的なCLIPのファインチューニングを提案。
- 画像テキスト検索タスクで従来のCLIPやEVAモデルを大幅に上回る性能を示し、LLMの知識を活用した視覚表現学習の有効性を実証。
論文要約 By Gemini 1.5 Pro
この論文において解決したい課題は何?
CLIPのような視覚言語モデルにおいて、LLMの優れたテキスト理解能力を活用して、より強力な視覚表現学習を実現すること。特に、従来のCLIPのテキストエンコーダでは困難だった、長く複雑なキャプションの処理能力を向上させることが目標。
先行研究だとどういう点が課題だった?
LLMはテキスト理解能力が高いものの、その出力特徴は単語予測に偏っており、CLIPのような対照学習に必要な線形分離性が低い。そのため、LLMを直接CLIPのテキストエンコーダとして利用すると、パフォーマンスが大幅に低下する。先行研究では、LLMのこの特性を克服できていなかった。
先行研究と比較したとき、提案手法の独自性や貢献は何?
LLMの出力特徴の識別能力を向上させるため、キャプション対照(CC)fine-tuningという手法を提案。これにより、LLMの潜在能力を引き出し、CLIPの学習を効果的に行うことを可能にした。また、LLMを固定し、アダプター層を導入することで、計算コストを抑えつつLLMの知識を活用できる効率的な学習プロセスを設計した。
提案手法の手法を初心者でもわかるように詳細に説明して
- キャプション対照(CC)fine-tuning: 同じ画像の異なるキャプションを正例、それ以外のキャプションを負例として、LLMの出力層をfine-tuning。これにより、LLMはキャプション間の意味的な類似度を捉える能力を獲得する。具体的には、ShareCaptionerで生成された詳細なキャプションと元のキャプションを正例ペアとして使用し、教師ありSimCSE損失を用いて学習を行う。
- LLM2CLIP: CC fine-tuning済みのLLMをテキストエンコーダとして使用し、CLIPの視覚エンコーダを学習。LLMは固定し、新たにアダプター層を導入することで、LLMの知識を保持しつつ、視覚エンコーダとの連携を最適化する。学習には、CLIP lossを使用する。また、計算コスト削減のため、LLMのテキスト特徴量は事前に抽出しメモリに保存する。
提案手法の有効性をどのように定量・定性評価した?
画像テキスト検索タスクを用いて定量評価を実施。Flickr、COCO、ShareGPT4V、Urban-1k、DOCCIなどのデータセットを用い、従来のCLIPやEVAモデルと比較して、検索精度が大幅に向上することを示した。また、中国語の検索タスクにおいても、英語データのみで学習したモデルが、中国語データで学習したモデルに匹敵する性能を達成することを示し、LLMの知識転移能力の有効性を示した。さらに、LLaVA 1.5の学習にも適用し、多くのベンチマークで性能向上を確認した。定性評価としては、キャプション検索の例を示し、fine-tuningによってLLMが関連性の高いキャプションを検索できるようになったことを示した。
この論文における限界は?
LLMの潜在能力を最大限に引き出すためには、fine-tuningデータの特性(分布、長さ、カテゴリなど)を考慮したデータ選択が必要となる可能性がある。また、本研究ではLLMの勾配を固定しているが、勾配を更新することで更なる性能向上が期待できる。Laion-2BやRecaption-1Bのような大規模データセットを用いた学習も今後の課題として挙げられている。
次に読むべき論文は?
- CLIP: Radford et al., Learning Transferable Visual Models From Natural Language Supervision.
- EVA-CLIP: Sun et al., EVA-CLIP: Improved Training Techniques for CLIP at Scale.
- LLaVA: Liu et al., Visual Instruction Tuning.
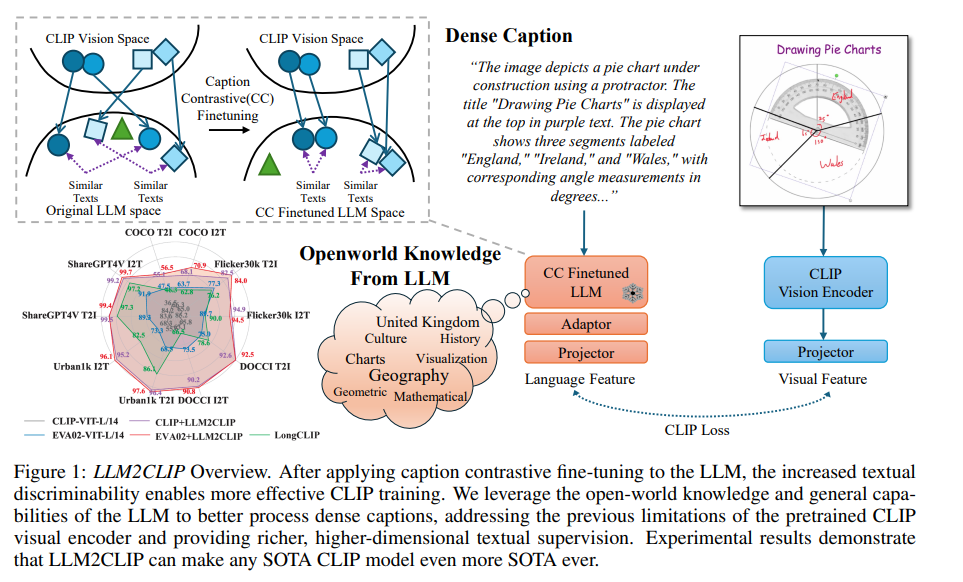
補足
なぜLLMはCLIPだと弱いのか
- テキスト埋め込みモデルとして直接使用することは困難
- 知識がモデル内にカプセル化され、彼らの出力特徴が個々の単語予測に大きく偏っているため
- 生成モデルであるため、出力特徴の線形分離性を保証するように訓練されておらず、CLIPのキャプションを解釈するために使用される場合、効果が低い。
- Chenら(2022)が強調しているように、CLIPにおけるクロスモーダル対照学習は、各モダリティが強い内部識別性を持つことを必要とする
- これのための定量評価:MS COCO Caption Retrieve Accracy (CRA)
- MS COCO Caption:異なる人間のアノテーターによって、1枚の画像につき複数のキャプションが割り当てられている
- 同一画像だがアノテーターが異なるキャプションを正例、それ以外を負例とする
- キャプション(テキスト)→キャプション(テキスト)の検索を行い、Top1の精度を比較
- 純粋なLLMを使用した場合は精度が低く、Llama-3 8Bを使ってCLIPを学習すると元のCLIPを大幅に下回る
CC Fine-tuning
- 同じ画像に対して多様な説明を得るために、ShareCaptionerが修正したCC-3Mデータセットを使用します。
- このデータセットには、各画像に対するオリジナルキャプションと拡張された詳細なキャプションの両方が含まれています。
- これらのキャプションは、正のペア(ポジティブペア)として扱うことができます。
- LLM2Vecの学習方法に従い、LLM(大規模言語モデル)の注意メカニズムを双方向注意に拡張します。
- 初期化には、Masked Next Token Prediction(MNTP)を採用して、より良い結果を得ます。

- LoRAの訓練
- 12BのLLMの訓練に、80GBのA100が8枚・バッチサイズが512でいい
LLM2CLIP
- LLMをフリーズしてクソデカバッチサイズでCLIPをファインチューニング
- Adapterをつける
- 8台のH100 GPUマシンで約3~9時間(バッチサイズ4096)
結果
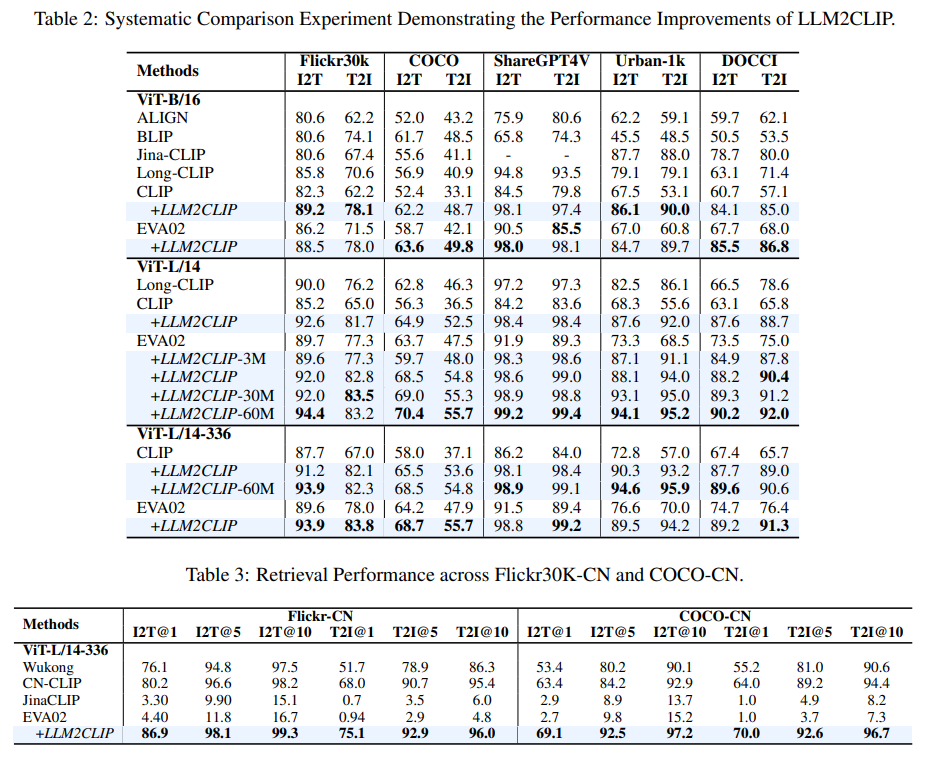
- くっそ強い結果になった
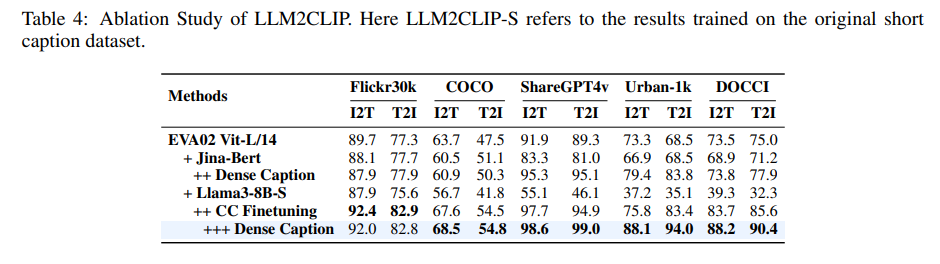
- 短いキャプション、長いキャプションの両方で訓練しないと得意・不得意なデータセットがある
- 例:長いキャプションをなくすと、COCOやFlickr30Kのようなデータセットでは良いが、ShareGPT4V、Urban-1K、DOCCIのような長文ベンチマークは悪い
- 訳注:Jina-Bertよりも、LLaMA3-8Bのほうがこの訓練方法のスケーラビリティがある
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー