
PyTorch lightningのCSVLoggerを攻略する


PyTorch lightningのロガーとしてTensorBoardがデフォルトですが、出てきた評価指標を解析するとCSVでロギングできたほうが便利なことがあります。lightningのCSVロガーとして「CSVLogger」がありますが、この使い方の資料があまりになかったので調べてみました。
目次
CSVLogger
これを使えばCSVでロギングができます
pytorch_lightning.loggers.CSVLogger
https://pytorch-lightning.readthedocs.io/en/stable/extensions/generated/pytorch_lightning.loggers.CSVLogger.html
使い方はTrainerのloggerに指定します。
logger_csv = pl.loggers.CSVLogger("outputs", name="lightning_logs_csv")
trainer = pl.Trainer(gpus=[1], max_epochs=100, logger=logger_csv)
TensorBoardと併用する+チェックポイント管理
ただこれだと2つ問題があり
- デフォルトのTensorBoardのロガーが使えない
- 最終エポックのチェックポイントが自動的に保存されるが、カレントディレクトリ直下の「lightning_logs_csv_lightning_logs_tb」に保存され、outputs直下に保存されない
この2つを解決していきます。1点目はTrainerのloggerが複数指定可能なことを使います。公式ドキュメントによると、
Logger (or iterable collection of loggers) for experiment tracking.
「collection of loggers」とあるので、リストを入れてしまえばいいです。
チェックポイントですが、これはマニュアルでModelCheckpointを設定します。
まとめると次のようになります。
def main():
model = TenLayersModel()
cifar = MyDataModule()
logger_csv = pl.loggers.CSVLogger("outputs", name="lightning_logs_csv")
logger_tb = pl.loggers.TensorBoardLogger("outputs", name="lightning_logs_tb")
checkpoint_cb = pl.callbacks.ModelCheckpoint(dirpath="outputs/checkpoints", save_top_k=1, monitor="val_acc",
mode="max", filename="{epoch:03}-{val_acc:.3f}")
trainer = pl.Trainer(gpus=[1], max_epochs=100, logger=[logger_csv, logger_tb], callbacks=[checkpoint_cb])
trainer.fit(model, cifar)
全体のコードはGistに示します。
ロギングされたCSVを解析する
outputs以下は次のようになります
- checkpoints
- lightning_logs_csv
- version_0
- hparams.yaml
- metrics.csv
- version_0
- lightning_logs_tb
csvのログ以外は省略します。versionは何回目の訓練かを示します。解析するファイルはmetrics.csvです。これをExcelで開くと次のようになります。
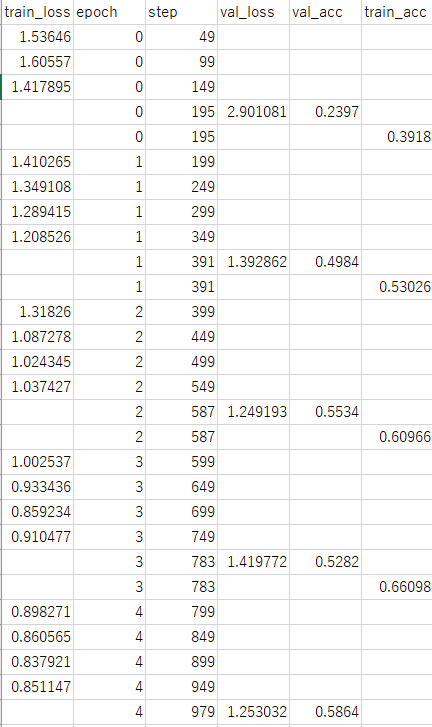
エポックの最後に記録しているtrain_accやval_accは。かなりNAが入った状態で記録されています。これは別途train_lossを定期的にとっているためです。
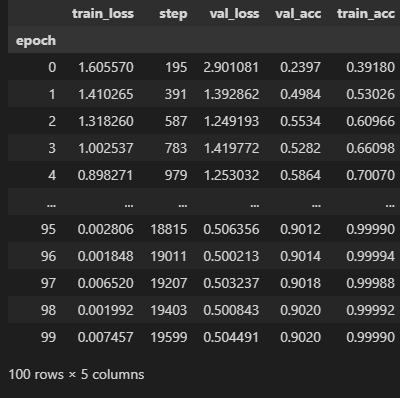
このNA弾きはpandasのgroupbyを使えばできそうです。集計のmax/minかは精度/ロスで異なるので注意してください。
df.groupby("epoch").max()
関数を続けて、train_loss, val_lossでプロットしてみましょう。
df.groupby("epoch").max()[["val_acc", "train_acc"]].plot(ylim=(0.7, 1.0))
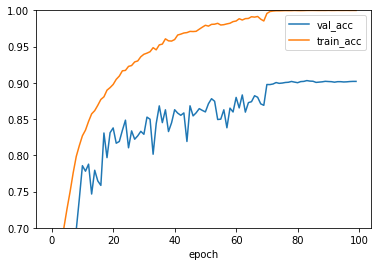
一瞬汚いCSVかと思いましたが、楽に扱えそうです。CSVLogger、便利ですね。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー