
PyTorchで双方向連結リストなデータ構造のモデルを作る


ディープラーニングのモデルには、訓練の途中でレイヤーを追加するなど特殊な訓練をするものがあります(Progressive-GANなど)。そのとき、モデルを「レイヤーやブロックの連結リスト」として定義しておくと見通しがよくなることがあります。その例を見ていきます。
目次
訓練中に継ぎ足していくモデル
例えば、Progressive-GAN(図は論文から)
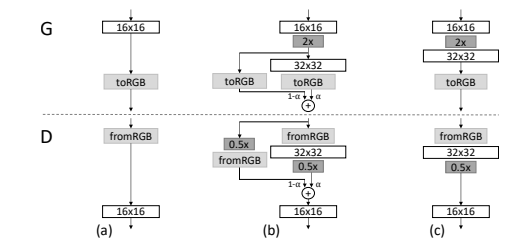
Progressive-GAN(PG-GAN)は低解像度から高解像度で積み重ねるように訓練していくのが特徴です。低解像度の訓練が終わったら、より高い解像度のレイヤーを継ぎ足す→そのレイヤーを訓練する→また継ぎ足すのように層状に訓練していきます。
双方向連結リストとして考える
このようなモデルの何が困るかというと、訓練する際にいちいちレイヤーを指定したりインデックスを指定しないといけないのです。PG-GANはモデル構造が決定的なので、全てのレイヤーをリストとかで格納するでも良いのですが、連結リストとして考えてみるとわかりやすいかもしれません。

連結リストとはデータ構造の一種で、このように前後のオブジェクト(ノードとか言います)の参照を記録しておくものです。後ろのオブジェクトだけ記録しておけば(前もあるかもしれないけど普通は後ろ)片方向、前後両方記録しておけば双方向の連結リストとなります。
今回は、PyTorchのレイヤーやモジュール(nn.Module)を連結リストのノードと見立てて、リスト全体で1個のモデルになるようにしてみます。
コード
ざっくりと実装してこんな感じ。Moduleクラスが追加するブロックの中身。Blockクラスが前後の参照を含んだブロック構成になります。
import torch
from torch import nn
class Module(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.layers = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_ch),
nn.ReLU(True)
)
def forward(self, inputs):
return self.layers(inputs)
class Block(nn.Module):
def __init__(self, new_in_ch, new_out_ch, prev_block):
super().__init__()
self.prev_block = prev_block
self.current_block = Module(new_in_ch, new_out_ch)
self.next_block = None
def forward(self, inputs):
x = self.current_block(inputs)
if self.next_block is not None:
return self.next_block.forward(x) # forwardを再帰にする
else:
return x
def add_block(self, new_block):
self.next_block = new_block
def count_params(model):
return sum([p.numel() for p in model.parameters()])
def main():
x = torch.randn(16, 3, 32, 32)
b1 = Block(3, 32, None) # 最初のブロック
print(count_params(b1), b1(x).size())
b2= Block(32, 64, b1) # 2番目ブロック
b1.add_block(b2) # 最初のブロックに2番目を追加
print(count_params(b1), b1(x).size()) # 呼び出すときは最初のブロック
b3 = Block(64, 128, b2)
b2.add_block(b3)
print(count_params(b1), b1(x).size())
if __name__ == "__main__":
main()
forwardを次のブロックの有無に応じて再帰にするのがポイントですね。呼び出すときは最初のブロックでやります。出力はこんな感じ。
928 torch.Size([16, 32, 32, 32])
19488 torch.Size([16, 64, 32, 32])
93472 torch.Size([16, 128, 32, 32])
パラメーターが二重カウントされるのではないかと危惧しましたがそういうことはないようです。backpropもちゃんと計算できました。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー