
Self-attention GAN(SAGAN)を実装して遊んでみた


前回の投稿では、Spectral Noramlizationを使ったGAN「SNGAN」を実装しましたが、それの応用系であるSelf-attention GAN「SAGAN」を実装して遊んでみました。CIFAR-10、STL-10、AnimeFace Dataset、Oxford Flowerを生成して確かめています。
(長いんで気楽に読んでね)
目次
Self-attention GANとは
論文:Self-Attention Generative Adversarial Networks https://arxiv.org/abs/1805.08318
主な特徴
- 基本的な発想はSpectral Noramlizationを使ったGAN(SNGAN)の発展。SNGANの論文、自分の記事
- GANに安定性に大きく貢献したSpectral Noramlizationを、SNGANはD(Discriminator)だけ使っていたが、このSAGANではG(Generator)にも使うのが大きな特徴
- D,Gともに中間層にSelf-attentionを入れることで、広域の特徴を確保し、生成画質の向上に寄与。Self-attentionがなにをやっているかのざっくりとしたイメージは、こちらの記事に書いた。
- SNGANではDとGのアップデート回数を5:1(Gを1回アップデートする間にDを5回アップデートする)のがメインだったが、SAGANではD:G=1:1にチャレンジすることを主眼においている。これは訓練の高速化を目的としたもの
- D:G=1:1は訓練が不安定になりがちだが、TTUR(Two Time-Scale Update Rule)を使用することで安定性を確保している。ちなみに論文はこちら。やっていることはDとGに異なる学習率を使うというだけだが、TTURの論文ではなぜこれが局所ナッシュ均衡に収束しやすいかを理論的に説明している(自分は「まぁ確かにそうだな」ぐらいで細かく読まなかったけど)。
以下実装に移ります。
リポジトリ
以下のリポジトリにまとめました。SNGANは割とうまくいきましたが、SAGANは割と微妙な感じになったのでリポジトリが適当です(あんまりうまく行かなかったんでやる気が起きない)。
https://github.com/koshian2/SAGAN
CIFAR-10 その1
SAGANの論文もSNGANのネットワークをベースにしているので、SNGANのCIFAR-10のネットワーク(ResNet)をベースにSAGANを訓練しました。Self-attentionは8×8の特徴マップに入れました(もう少し高解像度のレイヤーで入れたほうがよかったかも)。
TTUR, Self-attentionの効果
まず、3つの条件を用意しました。すべてConditionalな出力をします(GをConditiona BatchNorm、Dの出力層直前のProjectionを追加)。その上で、ケース0はTTUR、Self-attention不使用、ケース1はTTURだけ使用、ケース2はTTURとSelf-attentionの両方使用です。Inception Scoreを比較しましょう。
TTURを使用する場合の学習率はG=0.0001, D=0.0004、使用しない場合の学習率はG=D=0.0002とします。またAdamのパラメーターはbeta1=0, beta2=0.9とします。100エポック訓練させました。最後にこれハマったのですが、バッチサイズは64ではなく256のようです(公式リポジトリにそう書いてありました)。バッチサイズ64でGPU4枚だからバッチサイズ256とのことです。
結果は以下のようになりました。
| Case | 0 | 1 | 2 |
|---|---|---|---|
| Conditional | ○ | ○ | ○ |
| TTUR | × | ○ | ○ |
| Self-attention | × | × | ○ |
| Inception Score | 4.371 | 5.559 | 6.530 |
ちなみに自分が実装したSNGANでのCIFAR-10のResNetのInceptionが5.9~6ぐらいだったので、Self-attentionの導入によって純粋に良くなっているのが確認できます。CNNが局所的な特徴しか捉えないのに対して、Self-attentionはグラム行列の計算によって全体の特徴を捉えているのだから理解しやすいです。
確認のためにサンプリングと潜在空間の補間をプロットしてみましょう。
Case 0 (TTUR, Self-attentionなし) IS=4.371

序盤にベストのISが出ているせいか、ピンク色のカラーノイズが目立ちます
Case 1 (TTURあり, Self-attentionなし) IS=5.559

なんかそれっぽい形にはなっています
Case 2 (TTUR, Self-attentionあり) IS=6.530

形はいい感じになってきています。ただ、特に補間のテクスチャがなんかおかしいような感じはしなくはないです。Attentionを入れる位置がよくなかったのかもしれませんし、学習率が高すぎたのかもしれません。
崩壊の予兆とDのエラー
この訓練をしている間にみつけたのですが、SAGANはあるところまでは綺麗に画質が良くなりますが、それをすぎると急に訓練の巻き戻しがおこったような画質の劣化が起こります。図はSAGANの論文からです。
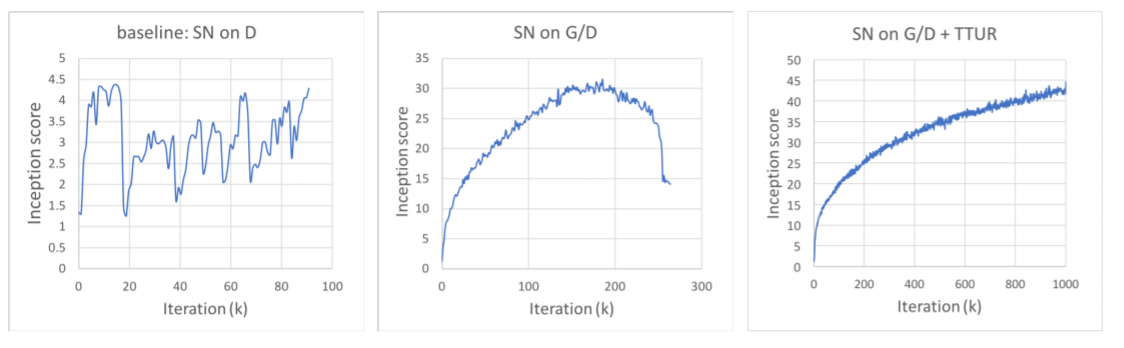
ちょうどこの真ん中のようなグラフですね。このようにISの急落が起こります(右はさすがにうまく行った例すぎて、ImageNetでもないと再現できなそう)。この画質の急落がおこっているときには、Dのロスが急に増加するという現象が起こります。ケース2のISとD、Gのロスのプロットです。
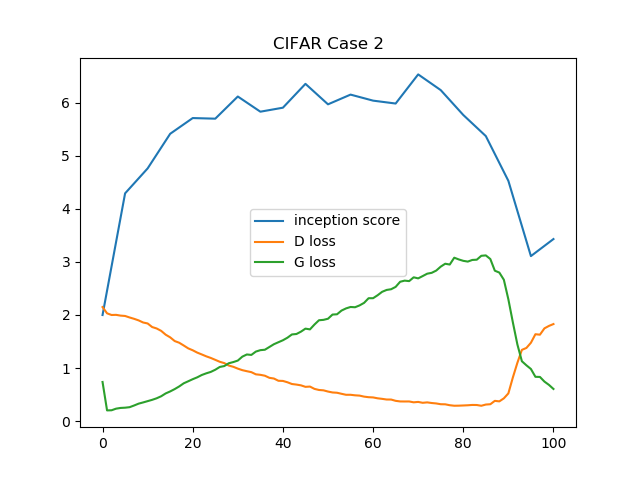
逆に言えば、基本的にはD:Gのアップデート回数を1:1にするが、Dのロスが急増しそうなときのみ集中的にDを訓練する――具体的には、Dのロスが一定値以上ならDのアップデート回数を5回にする、とやればより安定しそうな気はします(すごいアナログな方法ですが)。これは論文にない方法で、自分の思いつきです。
以下ケース3~5では、ケース0~2にそれぞれ、「Dのロスが0.5以上ならDのアップデート回数を5」にするという条件を加えています。それの結果を見ていきましょう。
Dのアップデート回数を可変にする
「D loss limit= 0.5」とは、Dのロスが0.5以上ならアップデート回数をD:G=5:1に、そうでなければD:G=1:1にするという意味です。またケース3~5では、Gのアップデート回数が足りなくなるのでエポック数を倍(200)にしています。
| Case | 3 | 4 | 5 |
|---|---|---|---|
| D loss limit | 0.5 | 0.5 | 0.5 |
| Conditional | ○ | ○ | ○ |
| TTUR | × | ○ | ○ |
| Self-attention | × | × | ○ |
| Inception Score | 6.372 | 6.525 | 6.241 |
この結果、ケース3~5すべてのケースで、D:G=1:1で固定しSelf attentionを入れたケース(ケース2)とほぼ同じようなISを出すことができました。ケース3~ケース5間のISはほぼ誤差のようなもので、Dのアップデート回数を可変にした場合は、Self attentionによる明確な画質向上を確認できませんでした。
各ケースのサンプリングと潜在空間の補間を見ていきましょう。
Case 3 (D_loss_limit=0.5 / TTUR, Self-attentionなし) IS=6.372
Dのアップデート回数を可変にしたら、急にそれっぽい形になりました。やっていることはGにSpectral Normを入れたSNGANですね。
Case 4 (D_loss_limit=0.5 / TTURあり, Self-attentionなし) IS=6.625

ちょっと画質が粗いような気がします。多分Dの学習率が高すぎたのでしょうね(ちなみにBigGANだとTTURは維持しつつも学習率をもっと小さくしている)。
Case 5 (D_loss_limit=0.5 / TTUR, Self-attentionあり) IS=6.241

ちょっとこれは潜在空間の補間がおかしいような気がします(補間が滑らかではない)。Self attentionによる画質向上は、あくまでD:Gを1:1でアップデートするとき限定なのかもしれません。少なくとも「Dのロスが○○以上ならアップデート回数を増やす」のようなアナログな手法だと効果がわかりませんでした。
Unconditionalな生成
論文だとConditionalな生成だけ議論していましたが、もともとSNGANはUnconditionalな生成ができるので、Conditiona BatchNormを普通のBatch Normに変えて条件なしの生成を行ってみました。
TTURとSelf-attentionはラベルなしでも使用できるので引き続き利用しています。
| Case | 6 | 7 |
|---|---|---|
| D loss limit | inf | 0.5 |
| Conditional | × | × |
| TTUR | ○ | ○ |
| Self-attention | ○ | ○ |
| Inception Score | 5.673 | 6.423 |
ケース6はすべてでD:G=1:1とするケース、ケース7はDのロスが0.5以上ならDを5回アップデートする方法です。SAGANはUnconditionalなケースだとなぜかうまくいって、特にケース7はラベルありのケースとほぼ同じようなISが出ています。
Case 6 (Uncodintional / D_loss_limit=inf / TTUR, Self-attentionあり) IS=5.673

ISは高めですが形がいびつなのが気にかかりますね
Case 7 (Uncodintional / D_loss_limit=0.5 / TTUR, Self-attentionあり) IS=6.423

やはりDの学習率がちょっと高すぎたような気がしなくもないです。(こんな出力でISが上がってしまうのだから、CNNの見ている範囲ってやっぱり適当なんじゃ)
学習曲線
ケース0~ケース7のISごとの学習曲線を示します。横軸がエポックで、縦軸がISです。
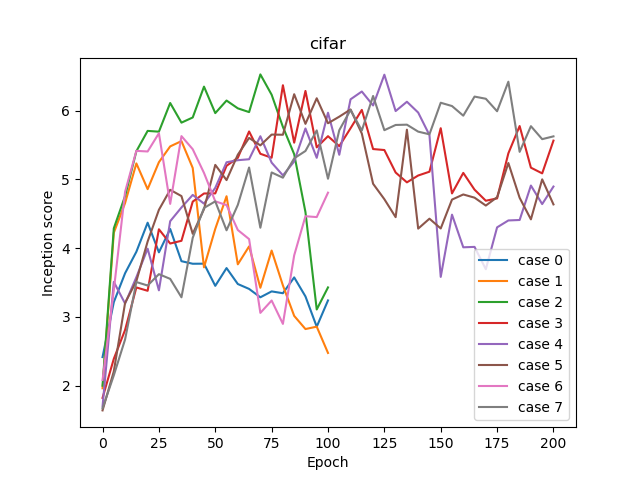
ケース0~2とケース6がD:Gが1:1、ケース3~5とケース7がD:Gが可変です。またケース0~5がConditionalで、ケース6~7がUnconditionalです。
これを見ると、D:Gが1:1のアップデートでは、直線的にISが上がったあとは直線的に失速するというケースが観測されます。D:Gが1:1ではそもそもの勾配の信頼性が低いせいか不安定なんでしょうね。これでも頑張ったほうだと思います。
結果まとめ
これまでの表をまとめます
| Case | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| D loss limit | inf | inf | inf | 0.5 | 0.5 | 0.5 | inf | 0.5 |
| Conditional | ○ | ○ | ○ | ○ | ○ | ○ | × | × |
| TTUR | × | ○ | ○ | × | ○ | ○ | ○ | ○ |
| Self-attention | × | × | ○ | × | × | ○ | ○ | ○ |
| Inception Score | 4.371 | 5.559 | 6.530 | 6.372 | 6.525 | 6.241 | 5.673 | 6.423 |
オリジナルのSelf-attention+TTURの設定がわずかにベストな結果となりました。
CIFAR-10 その2(学習率のスケーリング)
さて、このSAGANはバッチサイズ256でやっているので、モデルが大きくなるとGPUメモリに乗りきれないことが懸念されます。そのため何らかの学習率とバッチサイズの調整ができると便利かなと思いました。
そこで、画像分類(特にImageNetの高速化)で使われている、Linear Scalingという手法を使います。発想は単純で、バッチサイズを倍にしたら学習率も倍にする、バッチサイズを半分にしたら学習率も半分にするというものです。これも論文に乗ってたものではなく自分で勝手にやったものです。
すべてConditional. TTUR・Self-attentionありのCIFAR-10で考えます。ここでバッチサイズと学習率だけ変えます。今まではバッチサイズを256でやっていましたが、64, 128の2ケースを用意します。そしてそれぞれにLinear Scalingをするケースとしないケースを用意し、計4ケースからなります。Linear Scalingをしないケースでは学習率はバッチサイズ256のときと同じです。
また全てのケースで、D:Gのアップデートは1:1としました。
| ケース | 0 | 1 | 2 | 3 | (参考) |
|---|---|---|---|---|---|
| batch size | 64 | 128 | 64 | 128 | 256 |
| G lr | 0.000025 | 0.00005 | 0.0001 | 0.0001 | 0.0001 |
| D lr | 0.0001 | 0.0002 | 0.0004 | 0.0004 | 0.0004 |
| Incpetion Score | 6.908 | 6.835 | 6.883 | 6.602 | 6.530 |
(参考)のケースは、先程のCIFAR-10のケース2です。
学習率のスケーリングをしたほうが良さそうに見えますが、数字上はそこまで明確な差が出ているわけではありません。また、バッチサイズを下げたほうが良くなるという、BigGANの結論とは真逆のことが起きていますが、おそらくこれは誤差だと思います。
サンプリングと補間をプロットしてみました。
ケース0 : スケーリングあり、バッチサイズ64 IS=6.908

ISはいいです。テクスチャはしっかりしていますが、船と飛行機の形が似ていたり、どれも似たような形のような印象があります。
ケース1 : スケーリングあり、バッチサイズ128 IS=6.835

少し形がはっきりしてきたような印象がありますが、テクスチャがぼやけていますね。
ケース2 : スケーリングなし、バッチサイズ64 IS=6.883

スケーリングをやめたら鮮やかさが落ちたような気がします。あと補間が若干粗い?
ケース2 : スケーリングなし、バッチサイズ128 IS=6.602

やはりスケーリングしないとぼやっとした形だけで粗いような印象を覚えます。形なんかあまりCNN見ないんでしょうけど。
学習曲線
学習曲線を見るとかなりわかりやすい結果になりました。
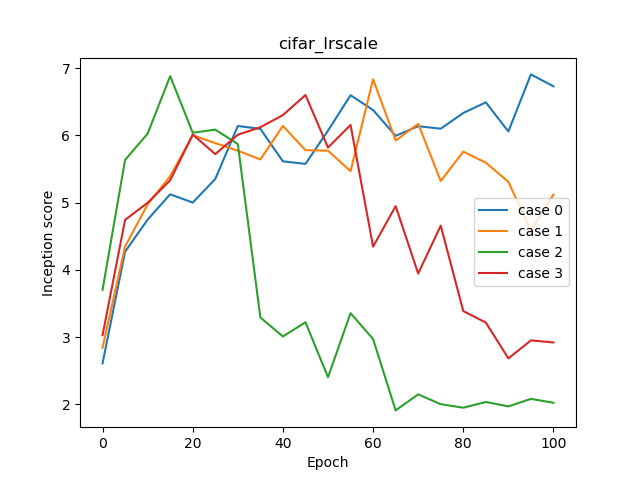
スケーリングしない場合、特にバッチサイズ64の場合(ケース2)は訓練が始まってすぐに急落しています。スケーリングなしのバッチサイズ128(ケース3)も早めに落ちていますね。学習率のスケーリングしたほうが長く高画質帯でとどまっているのが確認できます。
結論
Linear Scalingしてもよさそう。線形のスケーリングがいいのかどうかはわからないけど、勾配の大きさのコントロールでは効いているはず。
STL-10
SNGANと同様にSAGANでもSTL-10を調べてみました。SNGANの解像度48×48のResNetに12×12のSelf-attentionをつけたものです(もう少し高い解像度でAttentionすればよかったかも)。ちなみにSAGANの論文では、CIFAR-10もSTL-10も調べていません。
全てバッチサイズ256、D:G=1:1でTTUR, Self-attentionの有無の3パターンのみ調べています。400エポック訓練しました。
| Case | 0 | 1 | 2 |
|---|---|---|---|
| Conditional | ○ | ○ | ○ |
| TTUR | × | ○ | ○ |
| Self-attention | × | × | ○ |
| Inception Score | 6.073 | 6.122 | 5.640 |
Self-attentionが効いているのかどうか怪しい結果になりました。ちなみに、自分が調べたSNGANでのSTL-10はD:Gが5:1で7.136、D:Gが1:1で4未満だったので(STL-10をGANで生成するのがそもそも難しい)、確かにSNGANよりかは進歩しています。Self-attentionを24×24に入れればよかったのかもしれません。
サンプリング・補間
ケース0

クリーチャーみたいな出力に
ケース1

だめみたいですね
ケース2
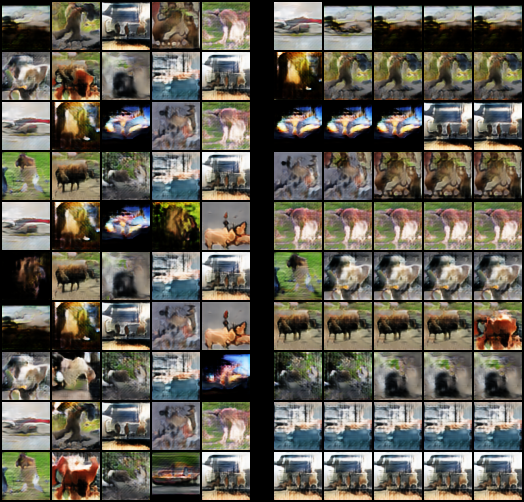
D:Gが1:1だと厳しいのかもしれません。
学習曲線
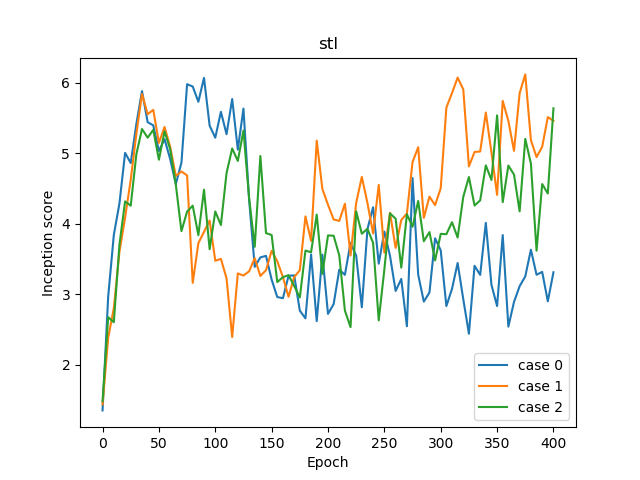
なんともいえない感がバリバリ……。
AnimeFace Character Dataset
SNGANと同じようにAnimeFace Character DatasetをGANで生成してみました。アニメ顔なのでInception Scoreはほぼ役に立たないので、サンプリングと補間のみお楽しみください。
ネットワークはSNGANの128×128のResNetを96×96化し(潜在空間のLinearの数を変えた)、24×24にSelf-attentionを入れました。250エポック訓練させてます。
30エポック

顔ができるのが早いです
50エポック

なんかモード崩壊してる!! 一見綺麗に見えますが、潜在空間の補間が同じ画像を返してしまいました。これはクラス単位のモード崩壊という現象で、AC-GANのときに広く見られた現象です。SNGANのときはこういうの起きなかったんですけどね…。
150エポック

綺麗にはなっているものの、モード崩壊は変わらず。
250エポック(ラスト)

ご愁傷さまでした。ちなみにSNGANのときはこんな感じ。

潜在空間の補間で画像がバラけているのが確認できます。こうなってほしかったのです。
アニメ顔まとめ
AnimeFacce Character DatasetはSAGANでやると、綺麗にはなったがクラス単位でモード崩壊してしまいました。そもそものクラスあたりのデータ数が少ないデータで、なおかつD:Gが1:1だと仕方ないのかもしれません(SNGANはD:G=5:1でやった)。
Oxford Flower Dataset
SNGANと同様にOxford Flower Datasetでやってみました。こちらはSNGANのときは、花のまとまりを出すのが難しいケースでした。おそらくSelf-attentionを入れると広域の情報を見るので、花のまとまり感は出ると思われます。
50エポック

まだギリギリモード崩壊していません
100エポック

残念、同様にクラス単位でモード崩壊してしまいました。
400エポック(ラスト)

確かに花としてのまとまり感は出ていますが、クラス単位でモード崩壊している以上、GANとして意味のあるものではないと思います。
ちなみにSNGANでの結果です。

SNGANの場合は花としてもまとまり感は薄いですが、モード崩壊していません。確かに花のまとまり感を出すのにSelf-attentionが効いているというのは言えそうです。
まとめ・感想
SAGANを実装したよということでした。以下のことがわかりました。
- 論文ではいろいろ頑張っているが、Spectral NormありでD:Gを1:1のアップデートで訓練するのは無理があるだろう。Anime FaceやOxford FlowerではSNGANにはなかったクラス単位でのモード崩壊が起こる。D:Gが1:1なので、Dの勾配が不正確になってしまったのが原因かと思われる。
- BigGANでD:Gが2:1でやっていることを考えると、D:Gを1:1にこだわる必要はないのでは
- ただし、バッチサイズと学習率のスケーリングは有効そう(特にBigGANで使えそう)
- Dのロスが一定以上ならDのアップデートを増やすといったアナログな手法を使うと、Self-attentionの効果が怪しい
- Oxford FlowerではSelf-attentionによる「花のまとまり感」を出すのにSelf-attentionが効いていたので、SAGANのような大域的な特徴を見るという発想は有効そう。Self-attentionではなく、Squeeze and ExcitationをResNetに組み込むのでもいいような気はする(確かめていない)
SAGAN、思ったより微妙でやる気が起きないので、このへんで終わりにします。

Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー