
論文まとめ:Shap-E: Generating Conditional 3D Implicit Functions


- タイトル:Shap-E: Generating Conditional 3D Implicit Functions
- 著者:Heewoo Jun, Alex Nichol(OpenAI)
- 論文URL:https://arxiv.org/abs/2305.02463
- デモ:https://huggingface.co/spaces/hysts/Shap-E
- コード:https://github.com/openai/shap-e
目次
ざっくりいうと
- Text-to-3DやImage-to-3Dを拡散モデルベースで行う研究
- 3Dアセットや点群データの暗黙的なニューラル表現(INR)を得るエンコーダーを訓練し、NeRFとSDFの潜在表現を生成
- INRをベースに、テキストや画像を条件とした3D生成ができ、品質は最適化ベースの手法に劣るが、レスポンスは速い
アバウトな理解
「Text-to-3Dや、Image-to-3Dを拡散モデルベースで、手軽にできるモデル」の理解でOK。Diffusersに統合された
https://github.com/huggingface/diffusers/releases/tag/v0.18.0
DALL-E 2とのアナロジー
Diffusion Priorという考え方は実はDALL-E2に近い(Diffusersの実装でもunCLIPと書いてある)
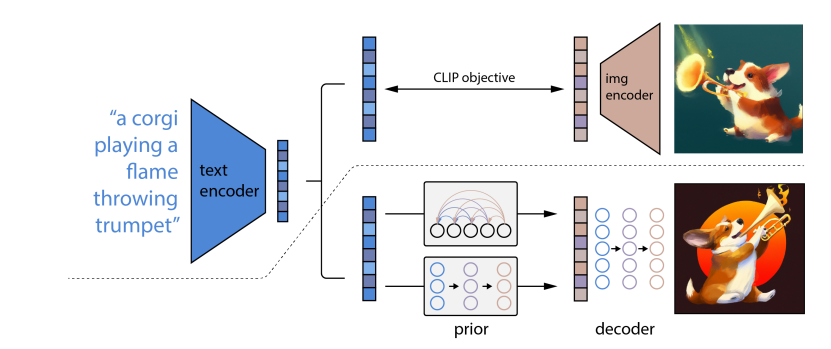
DALL-E 2は、Text-to-Imageのモデル。Inputがテキストで、CLIPのText Embeddingに変換し、Diffusion Priorは、それを逆拡散プロセスで繰り返しアップデートし、対応するCLIPのImage Embeddingに変換する。生成されたImage EmbeddingをDecoderが画像に変換する
ShapEの場合は、DALL-E2のImage EmbeddingをINR(暗黙的ニューラル表現)に置き換え、3Dモデルの生成に拡張したものとざっくり理解できる
導入
- Implicit Neural Representations (暗黙的ニューラル表現:INRs)
- 3Dアセットのエンコードのために近年普及。任意の入力点でクエリできるため解像度に依存しなく、微分可能
- この論文で焦点を当てているINRの例は2つ
- NeRF:座標+カメラの方向→密度(不透明度)とRGBカラーにマッピングするINR
- DMTet:座標→色、符号付き距離、頂点オフセットをマッピングする関数。テクスチャ付きの3Dメッシュを表現

- ShapEのやっていること:先行研究のスケールアップ
- 3DアセットのINRパラメーターを生成するために、Transformerベースのエンコーダーを訓練し、先行研究のアプローチのスケールアップ
- 先行研究と同様に、エンコーダーからの出力に対して拡散モデルを学習
- これまでの手法と異なるのは、NeRFとメッシュを同時に表現するINRを生成
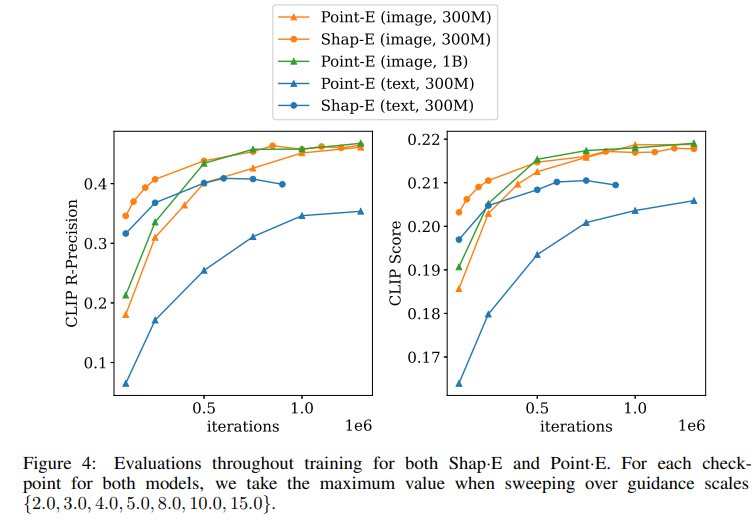
- 先行研究のPoint-Eと比較し、速く収束し、同等以上の結果が得られた
- 最適化ベースの3D生成よりかは、本手法はサンプリング品質で劣る。しかし、推論時間は桁違いに高速
STF( Signed Distance Functions and Texture Fields (STF))
- 目標:メッシュを構成したい
- 符号付き距離関数(SDF):3D形状をスカラー場で表現するための古典的手法
- 座標xをf(x)=dなるdにマッピング
- |d|はxから形状の表面に最も近い点までの距離。点が形状の外側にある場合はd<0
- f(x)=0が境界の定義、sign(d)が境界に沿った法線の向き
- 1つの関数で境界や法線を見れて便利で、メッシュ生成に利用される
- DMTet(先行研究)
- 空間上のグリッドに対し、SDFの値siとその変位Δviを生成する
- これらの値をベースにメッシュを生成
手法
訓練時の流れ
- 暗黙的表現を生成するエンコーダーを訓練
- 3Dアセットの潜在表現を生成するMLP
- エンコーダーによって生成された潜在表現を生成するための拡散モデル(Diffusion Prior)を訓練。Text-to-3Dの場合は、InputがTextで、Outputが3Dアセットの潜在表現
- 拡散モデルの条件は、画像かテキスト
- 対応するレンダリング画像、点群、テキストキャプションを持つ3Dデータセットですべてのモデルを訓練
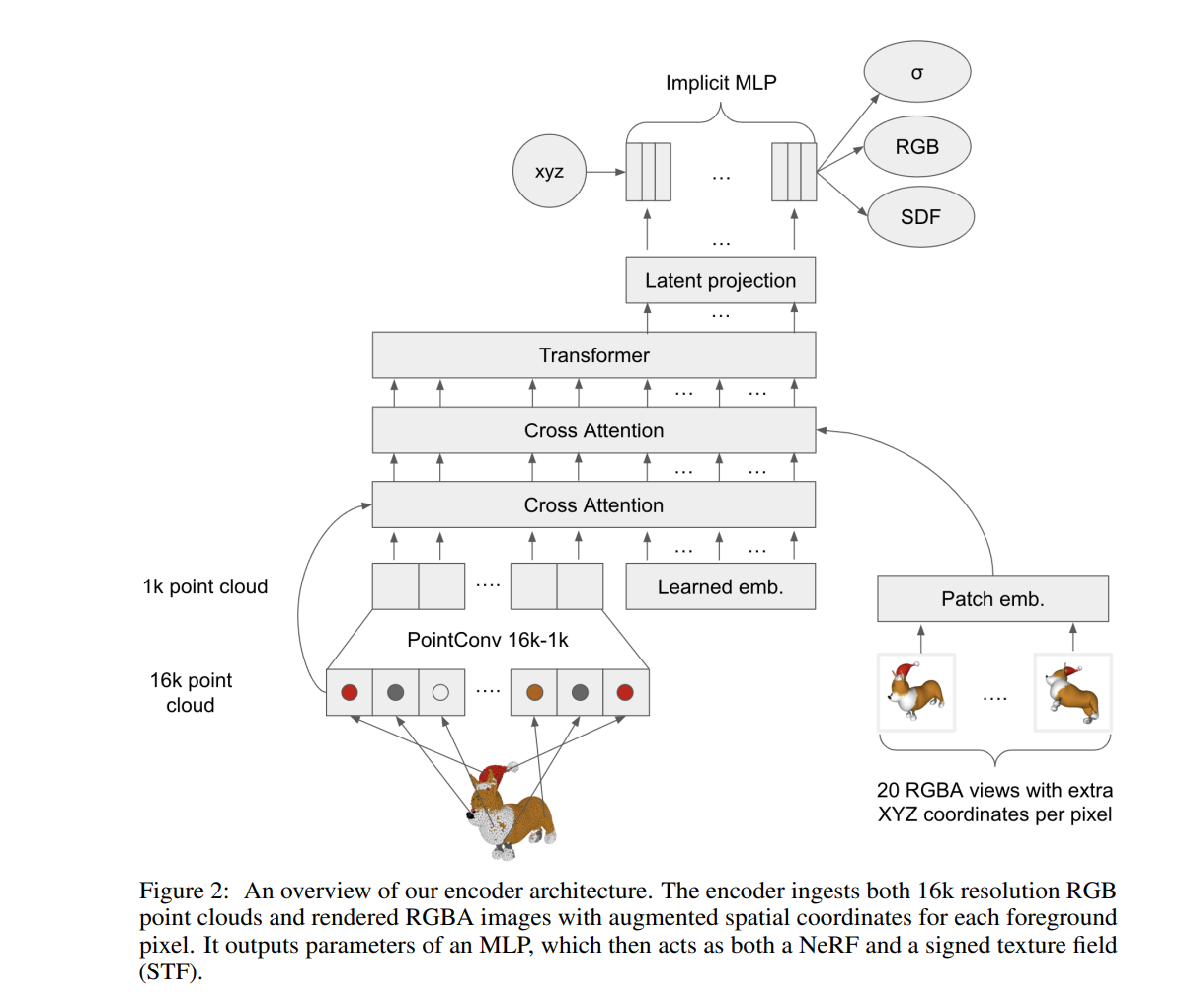
- Outputは「σ、RGB」だけならNeRFと同様(点群ではないが)、そこに「符号付き距離関数:SDF」が入っている
推論時の流れ
コード見ないとよくわからない。
- Diffusion Priorを使い、テキスト/画像から3Dアセットの潜在表現を得る
- テキストの場合も、画像の場合もCLIP Embeddingを使用
- それをNeRFやSTFのような手法で、3Dをレンダリング
結果
先行研究のPoint-Eより、少ないIterationで高性能な3Dモデルが得られる
Text-to-3Dの結果。単純なオブジェクトならある程度行ける
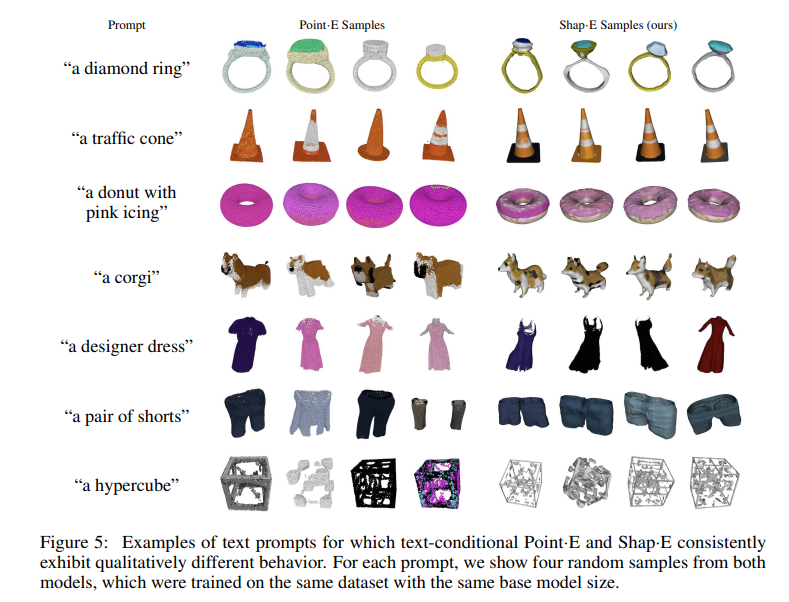
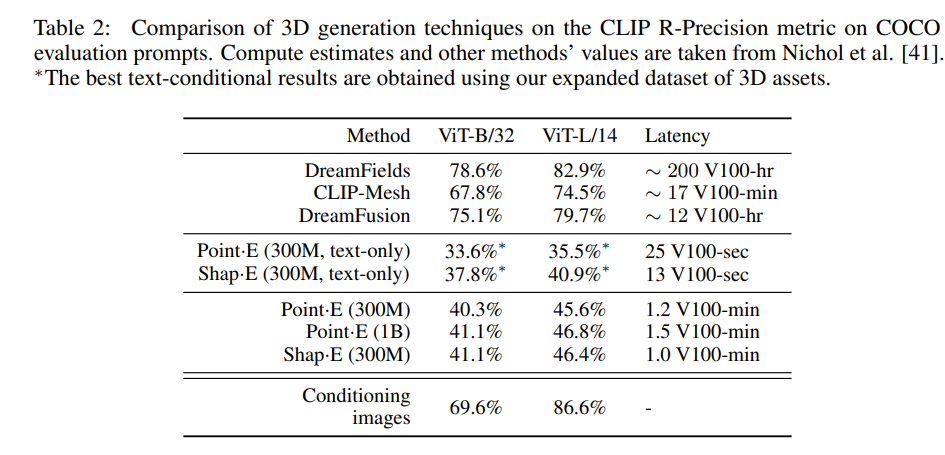
最適化ベースとの比較。3D生成時に最適化を入れる手法(DreamFieldsやDreamFusion)と比べると、生成される3Dのクォリティは大きく劣るが、レイテンシーが明らかに軽い。前者はV100で少なくとも12分なのに対し、提案手法はV100で1分程度。
やってみた
Text-to-3D
公式ドキュメントの例のコードをそのまま使う
プロンプト「a red car」

「a red car」のままGuidace Scaleを15→7.5に落とす

プロンプトを「a red sports car」に変える

GPT-4が吐き出した結果をText-to-3Dのプロンプトにする
- なんかいい感じの椅子の説明を英語で簡潔に書いて
- This chair boasts a sophisticated design with its sleek lines and plush upholstery. The comfortable padding and supportive backrest ensure maximum comfort, while the durable construction guarantees long-lasting use. Perfect for any home or office setting.

- なんかいい感じのシャンデリアの説明を英語で簡潔に書いて
- An elegant chandeliers cast a warm, inviting glow, showcasing intricate designs that beautifully reflect light. Its crystal pendants dazzle, making it a stunning centerpiece in any room.

→形状が複雑なものは難しそう
Image-to-3D
フリー素材の桜


なんかMinecraftみたいな出力になってるので、remove-bgで背景を消す

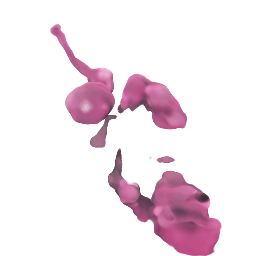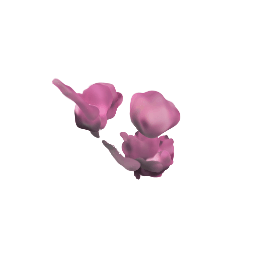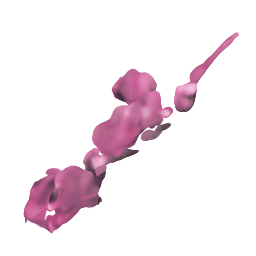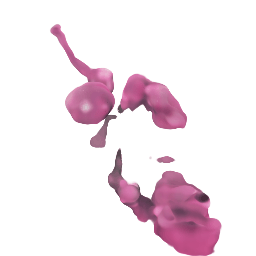
→形は似ているが、細部がやはりおかしいので、この程度が限度?
人間は向いてなさそう(岸田文雄の顔)

こういう単純な画像なら行けるのではないか?

なんだか立体視のようになっていて面白い

- Diffusers0.18.0の場合だと、Gifとして出力するだけでメッシュとして出力できないらしい
- 対応してほしいというissueが立ってる https://github.com/huggingface/diffusers/issues/3986
- 冒頭のHuggingfaceのデモはオリジナルのShapEの実装で、こちらは対応済み
- 割りと速くてお手軽GPUで動く
- 64ステップ+フレームサイズが256で、拡散プロセスが13秒程度、レンダリングがその2倍程度の時間
- Diffusersみたいなお手軽フレームワークで使えるのが良い
- 論文にも書いてあるとおり、精度と速度のトレードオフで、モデルがかなり単純なケース、粗い3Dケースでいいケースに絞れれば使えそう
- さらっと流されているが、INRのEncoderが割りと良さげな特徴抽出機として使えるのではないか
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー