
論文まとめ:StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners


- タイトル:StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
- 著者:Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang, Dilip Krishnan
- 論文URL:https://arxiv.org/abs/2306.00984
目次
ざっくりいうと
- Stable Diffusionの生成画像を使って、自己教師あり学習(SSL)をする研究
- Guidance Scaleをコントロールし、1対多の生成画像でSSLするためのStableRepというフレームワークを構築
- 実画像で訓練するより実画像のほうが、下流タスクの転移効率は高いが、ゼロショットでは課題
はじめに
- 画像データの集め方=理想は世界中にカメラを張り巡らさせる
- インターネットから収集されたノイジーなデータは、現実世界の問題とのドメインギャップがあり、社会的バイアスによる不均衡を反映
- もしデータ収集が自然言語のプロンプトで数秒でできたらどうだろう?→Stable Diffusion
- Classifier Free Guidanceが適切に設定された場合、同サンプル数の実画像の自己教師学習と同等かそれ以上のパフォーマンスを発揮
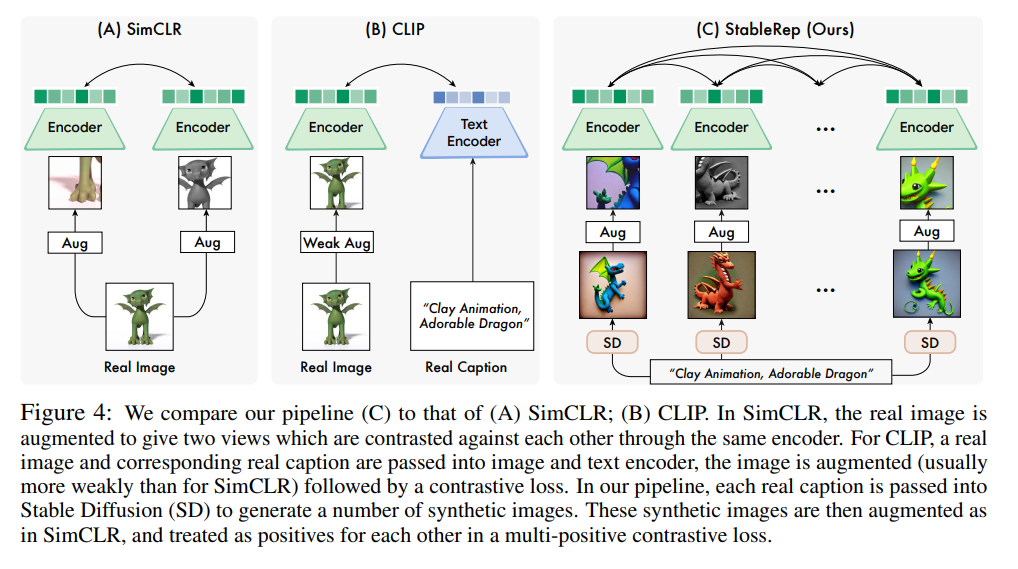
- CLIPの対照学習に触発され、同一キャプション(プロンプト)内の不変性を学習する表現学習のアプローチを開発
- 同一プロンプトから生成された複数の画像をPositiveとして扱い、対照学習の損失として利用=StableRep
- 合成画像のみなのに、同じサイズの実画像+テキストで学習するCLIPよりも良い性能だった
- なぜ実データよりうまくいくのか?
- Stable DiffusionのGuidance Scale、プロンプトや潜在変数によって、高度なサンプリング制御が可能
- 生成モデルは、学習データを超えて一般化する可能性があるため、対応する実データだけよりも豊かな(合成)学習セットを提供できる(←ほんと? Data Augmentationとして強いからではないの??)
- 結果
- StableRepで合成データのみで訓練したら、ViT-B/16でImageNetのLinear (Probe)精度が76.7%だった
- さらにこれに言語の教師を追加することで、実画像50M-キャプション50Mのデータセットで訓練したCLIPよりも、合成画像20M-キャプション10Mで訓練したCLIPのほうが性能が良かった

Classifier Free Guidanceとは
- Stable Diffusionなどの画像生成モデルで、プロンプトのテキストの意味を画像に反映するプロセス
- Classifer Guidanceというのが以前提唱されていたが、それを分類器不要でできるようにしたアプローチ
- U-Netのアップデート時に、「プロンプトなし」「プロンプトあり」の両方でアップデート後の計算し、その差分をとることで、プロンプトの反映方向を既定(Classifer Free Guidance)
- この強さを既定するパラメーターがGuidance Scaleで、理論的には条件付き確率のべき乗に相当

- 1枚目:Latent Diffusion
- 2,3枚目:Classifer-Free Guidance
-
Guidance Scaleが小さい=プロンプトの意味が反映されにくい
- Guidance Scaleが大きい=プロンプトの意味が反映されやすいが、強くしすぎると分布がピーキーになりすぎて画像が破綻する

自己教師あり学習のアプローチ
主に2つある。StableRepは両方の例で検証した
- 同一画像の異なるビューの不変性(Data Augmentationをかけた画像を同一とみなす)学習
- SimCLRを例として挙げる
- 画像をマスキングして復元する(MIM)
- MAEを例として挙げる
CC3Mで検証した例。単純な先行研究のフレームワークでも合成画像が優位(←合成画像の場合のプロンプトはどうしたのだろう?)
DINOでも優位だった。BYOLやMoCo v3ではわずかに下がることがあった。
合成画像によるMulti-Positive Contrastive Learning
ここからがStableRepのパイプラインの話。1つのプロンプトから複数の画像ができるため、Positiveが複数に対応するContrastive Learning(対照学習)をする

※論文の記述によると、将来画像生成が高速化してオンラインでバッチ処理できることを考えているらしい
実験詳細
キャプション(プロンプト)はどうしたのか?
CC3M (270万サンプル), CC12M (1000万サンプル) , RedCapsデータセット (1160万サンプル)のテキストから合成された合成画像に対してStableRepを学習
(所感:それはうまくいくはず。テキスト側が実データなので、画像生成モデルは単なる強いData Augmentationでしかない。GPTで合成した/言語モデルでMASK使って増やしたキャプションに対して検証していないのがちょっとずるいし、そこらへんを考えないと実世界の不均衡が反映されたままになるのではないか)
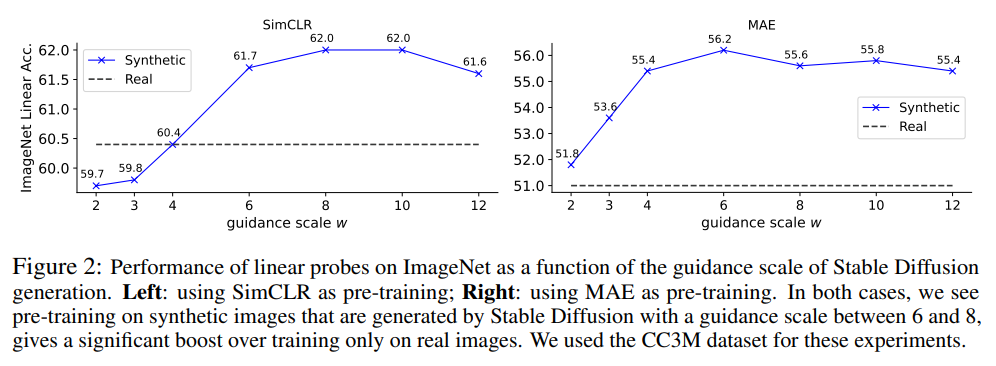
Guidance Scaleの選択について
- large scale = [8, 10]
- small scale = [2, 3]
- mixed scale = [2, 3, 4, 5, 6, 8, 10, 12]

- Guidace Scaleはsmall scaleのほうが下流タスクへの転移性が良かった
- (所感:それはそう。Guidance Scaleを小さくすると人間が見て良い画像ではない。プロンプトあたりの画像生成の分布が広がるので、クラス間の表現学習は進み下流タスクへの転移性はよくなるが、これを良いといっていいのか? 結局Data Augmentationとしての役割にとどまっているのではないか)
- CLIPで事前訓練すると(SimCLR/CLIP/StableRepの比較を参照)30エポックあたりでオーバーフィットしたが、StableRepで事前訓練するとエポック増やしてもスケールできた
- (所感:この事前訓練の工夫は素直にこの論文の貢献と言っていいのではないか)
- ViT-Lの事前学習は不安定で損失Nanになる。要因の1つはBatchNorm
下流タスクの転移性

Linear-Probeの精度。下流タスクの転移性という点では、合成画像で訓練したほうが良いケースが多かった。ゼロショット精度の話ではないのが要注意

Few-shotまで下げると、合成画像の優位性が少し下がる(AverageがRealよりも低い)。論文では特に記載がなかったが、合成データで訓練した場合、言語モデルにブーストされた、ゼロショットモデル特有の細かな表現力はないのではないか?
ゼロショット精度の場合は実画像よりも下がる
異なるGuidance Scaleについてキャプションごとに1枚の画像を生成し、CLIPを学習させた。ImageNetのゼロショット精度は実画像よりも5.4%も低かった
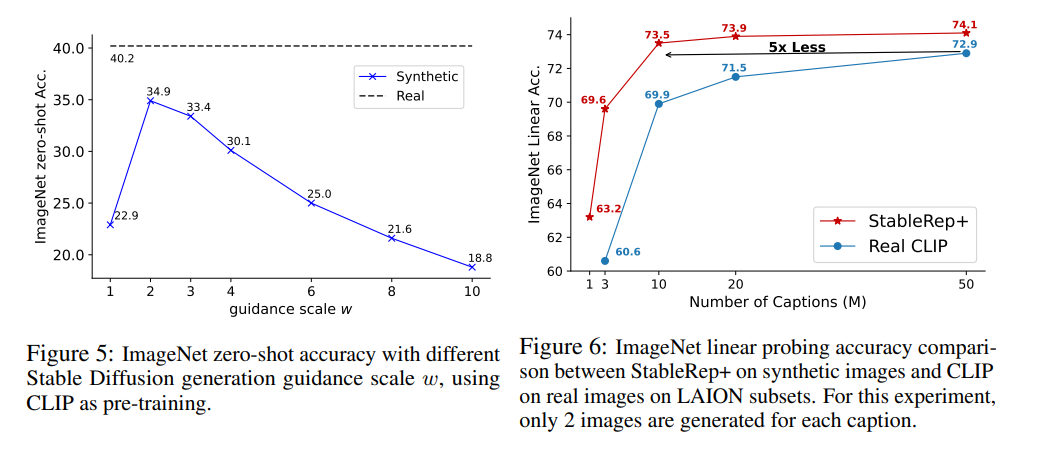
この理由は、生成画像とプロンプト間のミスアラインメントが原因。小さなクラスで顕著

StableRepの損失にImage2TextやText2Imageのロスを加えることで、Linear-Probeの精度が改善(←所感:これはあくまで下流タスクの話でゼロショットの話ではないでしょ?)
(所感:ミスアラインメントが原因ならキャプションをいじれば改善されそう。ただ、それだけが原因ではないと思う。同じ画像を見せたときに、人間は多様性があるのでレアな単語を入れることがある。そういった多様性を今の生成モデルを反映できていないため、そのデータで訓練するとレアな単語との関係を学習できない。その結果、特にゼロショットの精度が下がるのではないのか? GPTもStable Diffusionも1つの巨大なモデルからなり、人間の多様性は考慮していない。1つの巨大なモデルがいいというのは、ある意味一神教的な価値観のモデル)
結論
- 合成画像で訓練したら実画像で訓練するよりも、下流タスクで強い精度が出た
- StableRepと呼ばれる、画像合成結果を訓練データするケースに特化した事前訓練のスキームを作った
限界
論文に記載されていた内容
- 合成データの品質と有用性に影響を与える可能性のある、入力プロンプトと生成画像の間の意味的不一致の問題にも対処していません
- 合成データは、モード崩壊や「プロトタイプ」画像を出力する素因によるバイアスを悪化させる可能性がある
- 本手法は、未キュレーションの大規模なウェブデータで学習したテキストから画像への生成モデルに依存していることを認識することが重要
- テキストプロンプトは、完全にバイアスがないわけではなく、プロンプトの選択が合成される画像に影響を与えることを認識する必要がある
所感
- Stable DiffusionのText EncoderもCLIPで、この論文の定量評価にもCLIPを使っているため、StableRepという異なるフレームワークではあるものの、「結局訓練高速化したのってCLIPを蒸留したからでしょ」疑惑は否定できない。DeepFloyd IFのようなT5ベースの画像生成モデルでも確かめるべきだったかも(おそらく精度はStable Diffusionよりも上がる)
- 生成画像で訓練するのは思ったより課題が多い。論文ではバイアスを懸念しているが、多様性の消失が大きな課題。多様性はゼロショットと関係していそうというのが発見(合成データで訓練したらゼロショットが大きく下がったため)
- 合成データで訓練することの問題に対する、現実的な対策としては、実データを少しだけ混ぜる(これは多くの論文で主張されている内容)
- MIMとCLIPでどんどんゼロショット精度が上がっていったEVAの不思議さが気になる
- Guidance Scaleが低い画像は、人間的にはほとんど意味のない画像だが、下流タスクの精度を上げるために使うというのは理解できる(→でも人間にとって意味のない画像なら、数式駆動でいいじゃんみたいな話)
- FractalDBの価値がまた上がりそう(数式駆動だからバイアスを考える必要がない)。FractalDBの画像生成モデルや、言語版ができたら面白そう
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー