
論文まとめ:Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Posted On 2023-12-15


- タイトル:Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
- 著者:Stablity AIの方々
- 論文URL:https://static1.squarespace.com/static/6213c340453c3f502425776e/t/655ce779b9d47d342a93c890/1700587395994/stable_video_diffusion.pdf
- デモ:https://huggingface.co/spaces/multimodalart/stable-video-diffusion
- 記事:https://stability.ai/news/stable-video-diffusion-open-ai-video-model
目次
ざっくりいうと
- Stablity AIが公開した動画生成の研究「Stable Video Diffusion」
- 高解像度でなめらかな動画を生成するための、オプティカルフローやシーン変化の検出、キャプション生成やLLMを活用した、キュレーション戦略が大きな貢献
- キュレーションを良くすることで、動画生成の品質が良くなったほか、3次元生成への強い転移性を実証できた
はじめに
- 近年(おもに2023年)動画生成に大きな進展があった。動画生成の主なやり方は、
- ゼロから学習(Imagen Video)
- 事前学習済みの画像生成モデルに時間層を挿入(Align your Latents、Animatediffなど)
- 画像と動画のデータセットを混在させた学習が行われることが多い
- 空間層と時間層のアラインメントに焦点を当てた研究→データ選択の影響を調査していない。学習データ分布が生成モデルに与える影響を議論していない。
- さらに、画像生成は大規模な事前学習や、小さいが高品質なデータセットでのFine-tuningが性能を大幅に向上させることがわかっている(Emu、Stable Diffusion)
- 動画生成における、データや学習戦略、すなわち、低解像度でのビデオ事前学習と高品質の微調整の分離の効果はまだ研究されていない
-
良好なパフォーマンスを得るために重要と思われる3つの異なるビデオトレーニング段階を特定
- テキストから画像への事前学習
- ビデオ事前学習
- 高品質のビデオ微調整
- 「よくキュレーションされたデータセットでの事前学習は、高品質の微調整後に続く大幅な性能向上につながることを示唆」することが発見
- 6億サンプルからなる大規模なビデオデータセットを適用
- 動画生成のモデルだけでなく、強力なマルチビュー事前分布を提供し、Zero123XLやSyncDreamerなど特殊な新規ビュー合成手法を凌駕するマルチビュー拡散モデルをファインチューンするためのベースモデルとして機能することを発見
-
この論文の貢献
- 大規模でキュレーションされていない動画の集まりを、高品質な動画生成モデルを訓練するために置き換えるため*ワークフローを提示
- SoTAの性能
- 3次元理解の強い先行性を探る。具体的にはマルチビュージェネレーター
背景
- 画像→動画の拡張をどうする?
- 関連研究では、時間的にな混合層を事前訓練済みの画像生成モデルに追加
- 時間畳み込み層のみ学習する、学習しない研究などもあるが、この研究ではモデル全体をファインチューニングした
- データのキュレーション:CLIPでは重要だった。しかし、動画生成では議論されていない
- WebVid-10Mデータセットは、電子透かしがあり、解像度が最適とは言い難い
- WebVid-10Mは画像と組み合わせて使用されることが多く、画像とビデオのデータの効果を分離することが難しい
高画質な動画合成のためのデータキュレーション
高画質な動画合成のための、訓練レジュームは以下の3つのステップからなる。各レジュームの重要性を検討。
- Text2Iamgeでの事前学習
- 大量の動画で学習する動画の事前訓練
- 高解像度で高品質なサブセットモデルでファインチューニング
データ処理とアノテーション
大量の動画データには、動きの少ないシーンが多く含まれ、これが動画の学習を阻害している。例えばシーン検知して、オプティカルフロースコアを出すと、スコア0(動きがない)シーンが多い。
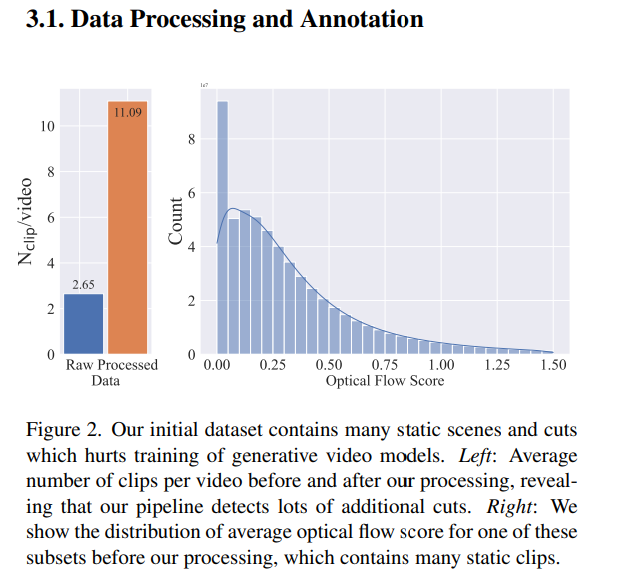
- 3種類のFPSレベルでカット検出(シーン分割)パイプラインを適用。シーン分割にはPySceneDetectを使用
- https://github.com/Breakthrough/PySceneDetect
- 注釈:このライブラリ初めて知ったが普通に便利そう
- 3種類の合成キャプションのアノテーション
- 動画の中間フレームに対し、画像キャプション生成モデルのCoCaを使ってキャプション
- V-BLIPを使ってビデオベースのキャプション
- 2つのキャプションに対しLLMベースの要約をし、第3の説明を生成
- ただ、これだけだと動きの少ないシーンまで抽出してしまうため、オプティカルフローによる閾値処理が別途追加した。2FPSでオプティカルフローを計算し、大きさが閾値以下のビデオを削除する処理を追加。
- オプティカルフロー計算はOpenCVのFarnebäckアルゴリズム。最短16pxのダウンスケールでOK
- OpenCVは概算でしかないため、フィルタリング後にモーションスコアを計算するために800×450のRAFTを使って正確なオプティカルフローを計算
- 大量の文字を含むウィードアウトクリップにOCRを適用
- 各動画クリップの最初、中間、最後のフレームにCLIPのEmbeddingを適用し、そこから美学スコアとテキスト画像の類似度を計算
キャプションの合成

OCRによるフィルタリング。Bounding Boxの面積を合計し、7%より多いものをフィルタリング。OCRはCRAFTを使用。
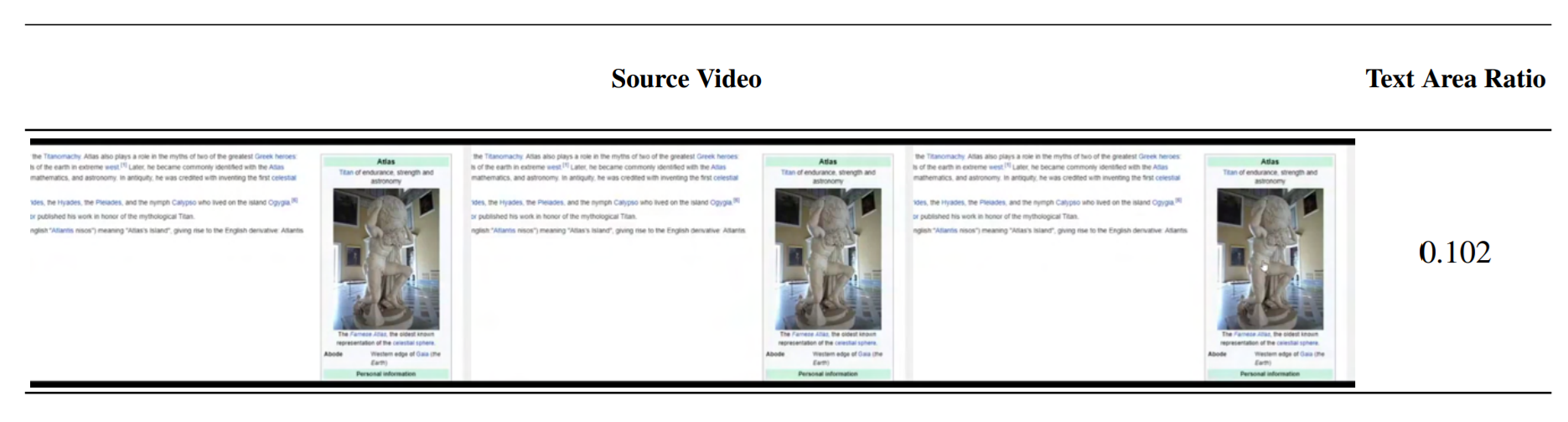
カスケード方式のカット検出

- カスケードなしだと下2つのような連続的なシーン変化を検出できない
- フレームレートや閾値が異なる3つのカット検出器のカスケードを適用
- 注釈:検出器モデルのアンサンブル的な文脈?
事前学習用のキュレーション
- 不要な例をフィルタリングするための強力な既製の表現がビデオ領域に存在しないため、適切な事前学習データセットを作成するために、人間の嗜好を信号として利用。
- 64のテストプロンプトから動画を生成し、人間のアノテーターに項目別評価
- この評価は評価閾値を選ぶ上でのハイパラ選びとして使う
- CLIPスコア、美的スコア、OCR検出率、合成キャプション、オプティカルフロースコアを評価指標とし、た9.8MサイズのLVD、LVD-10Mのサブセットから開始し、下位12.5、25、50%の例を系統的に削除
- 合成キャプションの場合はフィルタリングできないので、人間の嗜好投票に対するEloランキングを比較
- 注釈:Eloランキングはチェスで使われるレーティングの指標。LLMの比較でよく使われる
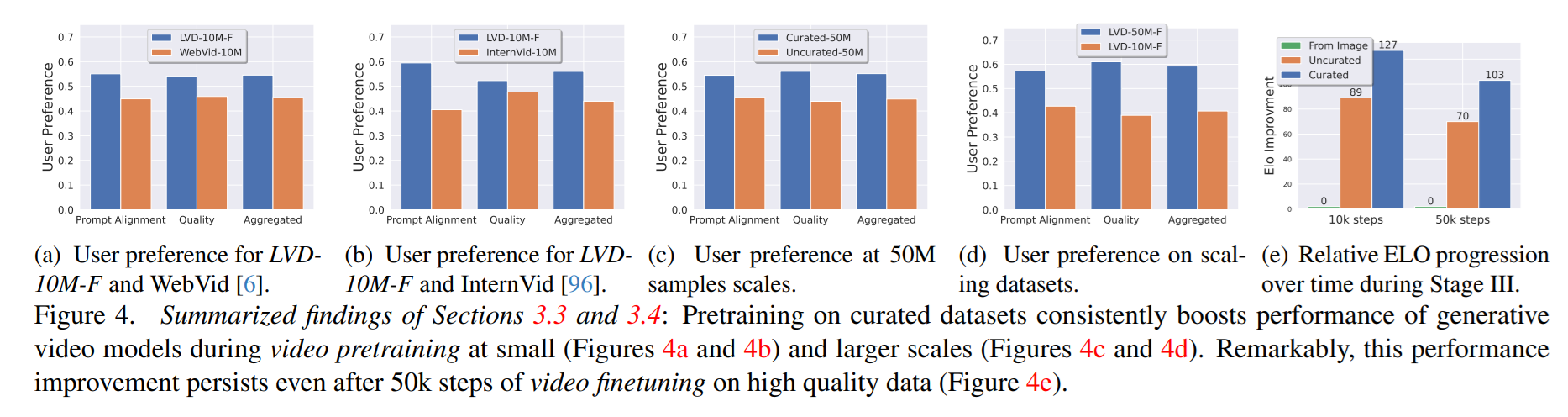
- キュレーションの有無で比較した結果、人間の嗜好やEloレーティングなどが大幅に向上することがわかった
- このキュレーション戦略はデータ数に対してスケールする(Fig 4d)
- この効果は高画質な動画データでファインチューニングしたあとも継続している(Fig 4e)
ビデオの学習
Text2Iamgeでの事前学習
Stable Diffusion 2.1を使用。学習段階では、ノイズスケジュールをより多くのノイズにシフトすることが重要で、先行研究の画像生成の結果を確認
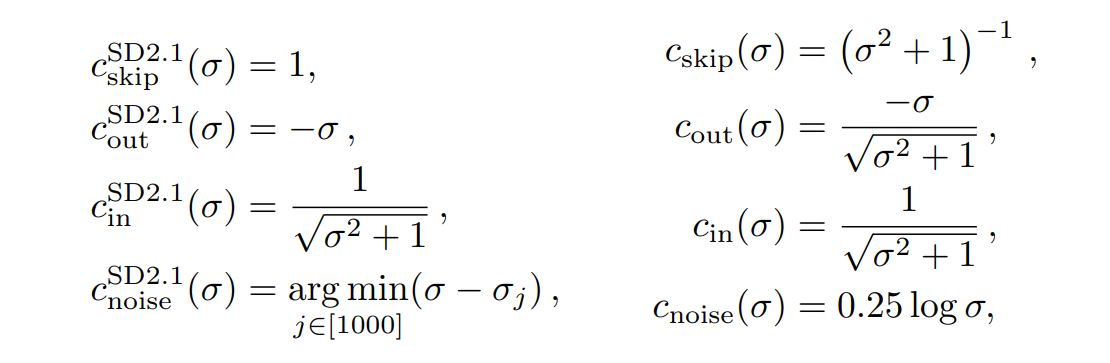
ノイズ生成時の関数を左から右に変更。左は最大ノイズが多くなると暗い画像を生成してしまう問題が先行研究で明らかになっていた。これを右に変更することで低減した。この式も先行研究から。
Classifier-free Guidance
プロンプトの意味を画像/動画に伝える際、Classifier-free Guidanceが使われるが(Cross Attentionによる潜在空間の誘導)。このスケールを、時系列方向に直線的に変化させて反映させるのが有効なことがわかった。これを提唱している。

Image2Video
- Text2Videoのほかに、Image2Videoも可能
- ImageのCLIP埋め込みをフレーム間でコピーするだけ」
カメラの動きのLoRA
- カメラの動きを学習するLoRAもできた(ズーム、水平シフト)
- 時間的なCross Attentionで学習。ランク16の低ランク行列を5kステップ。

フレーム補間
- フレーム方向の超解像
- 左右のフレームを連結し、マスキングして入力。2つのフレーム内の3つのフレームを予測することでFPSを4倍にアップサンプリング

マルチビュー生成
- 動画生成のモデルをファインチューニングして、複数の新規ビューを同時に得るためのファインチューニング
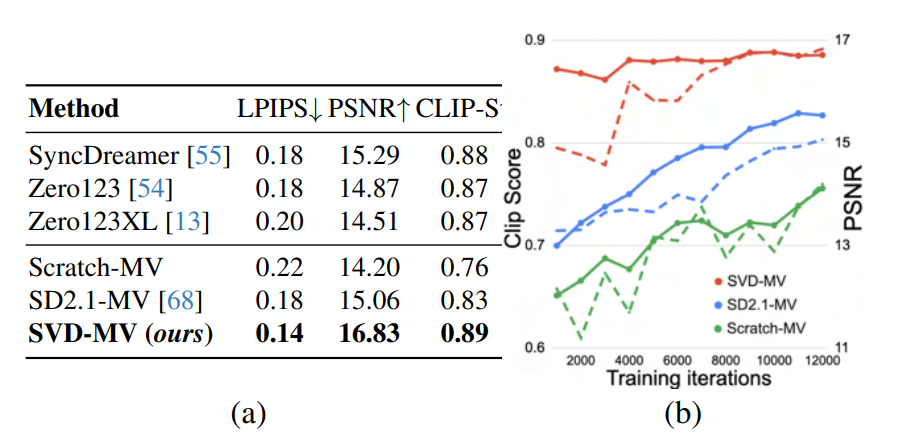
- SVDモデルは1枚の画像を撮影し、一連の多視点画像を出力する2つのデータセットで、SVDモデルをファインチューニング
- 80GB A100 GPU 8 枚を用い、バッチサイズ 16 で 12k ステップ(約 16 時間)
- より少ない訓練時間(16時間で12k反復)で最先端技術に対して競争力がある。例えば、SyncDreamerはObjaverseで4日間訓練された
所感
- 出てきた動画よりも、論文そのものがすごく価値のある内容でそこが面白い
- 前処理をここまでちゃんと書いてある論文はそこまで多くなく、この上位互換のモデルはすぐに出てくるだろうが、この部分の価値は褪せないと思う
- DALLE-3で生成したイラストで試したら普通に乱れたのでまだ難しい点は多そう。長時間の動画生成はまだ厳しそう
- モデルのライセンスが現状NC… https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー