
PyTorchでSliced Wasserstein Distance (SWD)を実装した


PyTorchでSliced Wasserstein Distance (SWD)を実装してみました。オリジナルの実装はNumpyですが、これはPyTorchで実装しているので、GPU上で計算することができます。本来はGANの生成画像を評価するためのものですが、画像の分布不一致を見るためにも使うことができます。
目次
コード
こちらのリポジトリにあります。
https://github.com/koshian2/swd-pytorch
SWDとは
PGGANの論文で使われている画像類似度の評価指標です。GANの評価指標の多く(Inception scoreやFID)が訓練済みInceptionモデルベースであるのに対し、SWDはInception依存ではありません。訓練済みInceptionモデルは大抵ImageNetベースなので、特徴量抽出がドメインによって得意だったり不得意だったりします。したがって、ImageNetによるInceptionが得意ではないドメイン(医用画像やアニメーション画像など)での類似度指標としては、Inception依存ではないほうが便利だったりします。
そして、大きな特徴として、SWDはラプラシアンピラミッドからパッチを切り出して距離を計算しているため、追加のラベルを参照しません。すべて教師なしでできます。
工夫した点
- オリジナルのNumpy実装をPyTorch実装に変えました。CUDA対応することで高速で計算することができます(CPUの計算だと結構時間かかる)。
- SWDの計算自体、非常にメモリを食うのでGPUのメモリに収まり切るように調整しました。ラプラシアンピラミッドの部分をミニバッチ処理にしたり、投射の次元数を変えてメモリを減らしたりしました。後で確認しますがこの次元数は変えてもほとんど影響ありません。
使い方
最も簡単なSWDの計算方法です。GPU上の計算となります。
import torch
from swd import swd
torch.manual_seed(123) # fix seed
x1 = torch.rand(1024, 3, 128, 128) # 1024 images, 3 chs, 128x128 resolution
x2 = torch.rand(1024, 3, 128, 128)
out = swd(x1, x2, device="cuda") # Fast estimation if device="cuda"
print(out) # tensor(53.6950)
パラメーター詳細
swd の引数の詳細情報です。
image1, image2: 必須 4ランクのPyTorchテンソル。各テンソルは[N, ch, H, W]のshapeであること。正方形の画像(H=W)推奨。n_pyramid: (任意) ラプラシアンピラミッドの層の数。もしNone(デフォルト : 論文と同じ)が指定されると、16×16の解像度に向かって再帰的にダウンサンプリングします。最小解像度のガウシアンピラミッドの層が、ラプラシアンピラミッドの配列に追加されるため、出力の層の数はn_pyramid + 1になります。slice_size: (任意) ラプラシアンピラミッドの各層から切り出すときのパッチサイズ。デフォルトは7(論文と同じ)。n_descriptors: (任意) 画像あたりのDescriptor(パッチ)の数。デフォルトは128(論文と同じ)。n_repeat_projection: (任意) ピクセル値を乱数で投射するときの反復回数。この値はGPUメモリに応じて指定してください デフォルトは128。「n_repeat_projection * proj_per_repeat = 512」となることが推奨されます。この積の値が512であることは論文と同じですが、公式実装ではn_repeat_projection=4、proj_per_repeat=128としています。(この方法だと非常に多くのメモリが必要です…)。proj_per_repeat: (任意) ピクセル値を乱数で投射するときの、ループ1回あたりの投射次元数。デフォルトは4。この値を大きくするとCUDA OOMを引き起こす恐れがあります。「n_repeat_projection * proj_per_repeat = 512」となることが推奨されます。device: (任意)"cpu"or"cuda". GPUで計算したいときはcudaを指定してください。デフォルトは"cpu"。return_by_resolution: (任意) Trueの場合、ラプラシアンピラミッドの各解像度ごとにSWDを返します。Falseの場合、解像度ごとに平均を取ったSWD値を返します。デフォルトはFalse。pyramid_batchsize: (任意) ラプラシアンピラミッドを計算する際のバッチサイズ。この値を大きくするとCUDA OOMを引き起こす恐れがあります。この値を変えることでSWDの計算結果が変わるということはありません。デフォルトは128。
実験
いくつかSWDの特徴を確認するために実験をします。2つの実験を行います。
n_repeat_projectionとproj_per_repeat値を変えてみる。ただし2つの値の積は512で固定。- SWDを計測する際のデータ数を変えてみる(10000 vs 10000, 5000 vs 5000など)
これをランダムノイズによるデータと、CIFAR-10で確かめます。結論から言うと、
- ほとんど変わらない
- すごい変わる
となります。したがって、SWDを使う際は事前に計測するデータ数を固定しておくのが重要となります。n_repeat_projectionとproj_per_repeatをメモリ使用量に応じて変えるのは差し支えありません。
n_repeat_projectionとproj_per_repeat値を変える実験
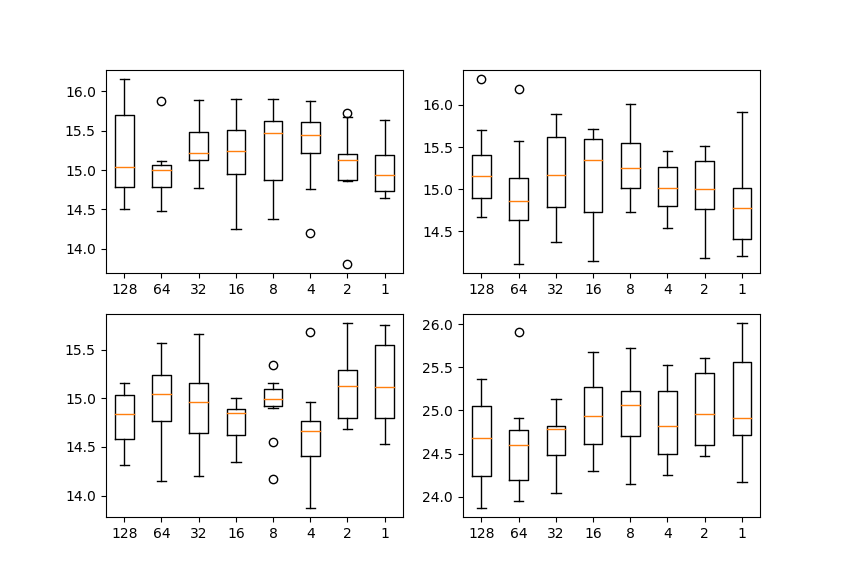
各プロットは、ラプラシアンピラミッドの解像度ごとのSWDを示し、横軸はproj_per_repeatの値、縦軸はSWDの値を示します。各ケース10回ずつ試行しました。
ランダムノイズの場合
ランダムノイズの場合は、16384個(論文と同じ)の乱数データを作りました。解像度は128×128です。
CIFAR-10の場合
訓練データ1万枚とテストデータ1万枚で比較しています。
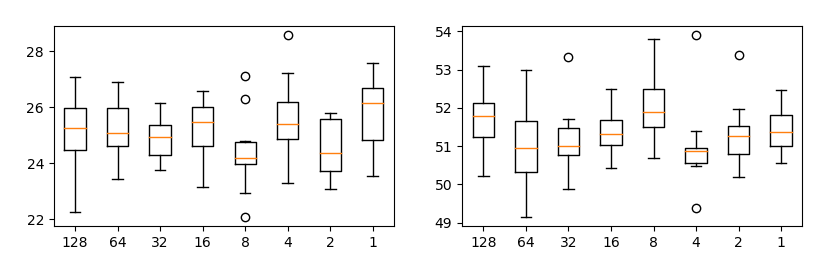
いずれの場合でも、proj_per_repeatを変えてもほとんど値が変わらないのがわかります(→メモリの応じて値を調整して良い)。
サンプル数を変える実験
今度はSWDを計測する際のサンプル数を変えて実験してみます。サンプル数が1万なら、訓練1万枚・テスト1万枚の間のSWDを計測し、サンプル数が5000だったら訓練5000枚・テスト5000枚間のSWDを計測する…という具合に変えてみます。
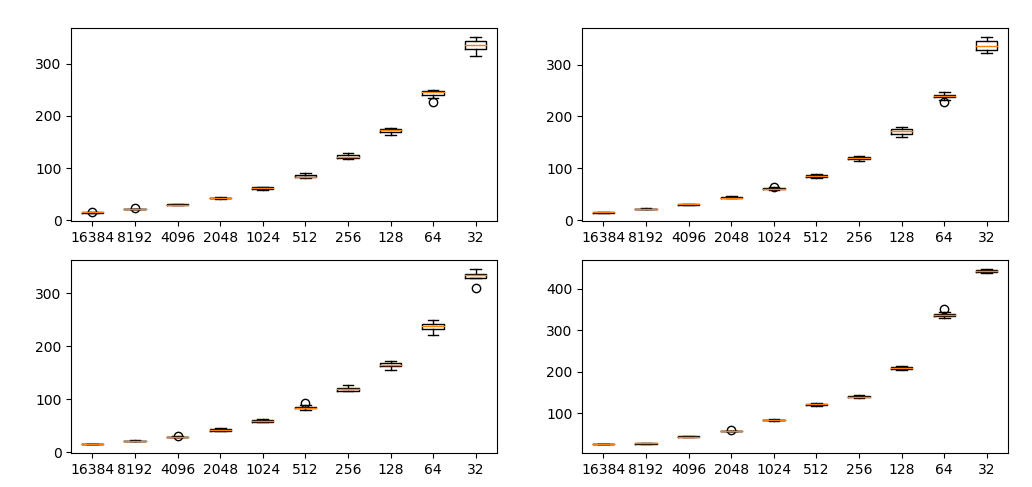
各プロットは、ラプラシアンピラミッドの解像度ごとのSWDを示し、横軸はサンプル数、縦軸はSWDの値を示します。各ケース10回ずつ試行しました。
ランダムノイズの場合
CIFAR-10の場合
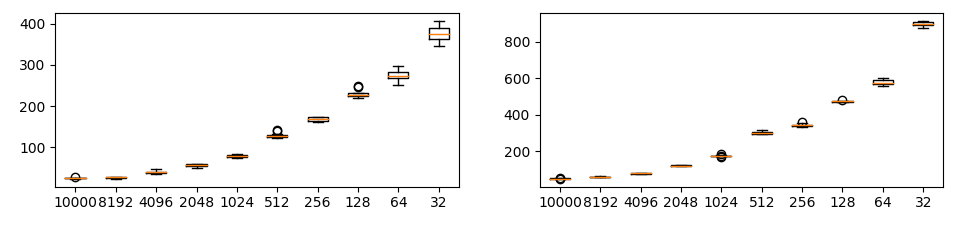
いずれの場合でも、サンプル数に応じてSWDが指数関数的に変わってしまうのが確認できます(重要)。これはSWDがWasserstein(Earth Mover)距離だからです。したがって、あるケースAではサンプル数1000で計測し、ケースBではサンプル数1万で計測するというのは適切ではありません。PGGANの論文ではサンプル数16384としていました。
データ数に応じて変えても良いかなとは思いますが、初めに値を決めたら統一して計測すべきかと思われます。
分布不一致の指標として
SWDは画像データ間の分布不一致を追加のラベルなしで計測できる指標、としても使うことができます。
2つの実験を行います。CIFAR-10の訓練・テストデータのSWDを以下の2条件で計測します。どちらのケースでもサンプル数は1万で統一します。
- クラスを削除 : テストデータは変更せず、訓練データは0~8のクラス数を順次削除する。
- 不均衡クラス : テストデータは変更せず、訓練データに人為的な不均衡を付与する。訓練データAは訓練全体からある1つのクラスを削除し、訓練データBは訓練データをそのまま使う。そしてAとBを連結し、A,Bから取り出して連結する個数を0~1万と変更させる。これにより、訓練データはある特定1クラスのみ不均衡となる。
実験1,2ともに訓練データは不均衡だが、実験1より実験2のほうがより弱い不均衡/ミスマッチとなります。このような弱いミスマッチをSWDは検出できるでしょうか?
クラスを削除する実験
各プロットは、ラプラシアンピラミッドの解像度ごとのSWDを示し、横軸は削除したクラス数、縦軸はSWDの値を示します。各ケース10回ずつ試行しました。
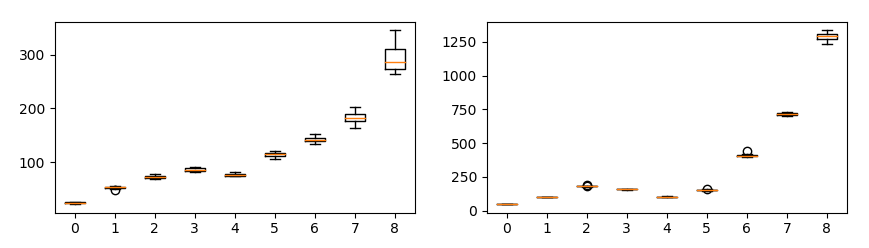
クラスの削除数が多くなるほど(ミスマッチが強くなるほど)、SWDが大きくなることがわかります。
不均衡クラスの実験
各プロットは、不均衡となっているクラスのインデックス別のSWDを示します。横軸は不均衡データ(訓練データA)の連結数、縦軸はSWDの値を示します。
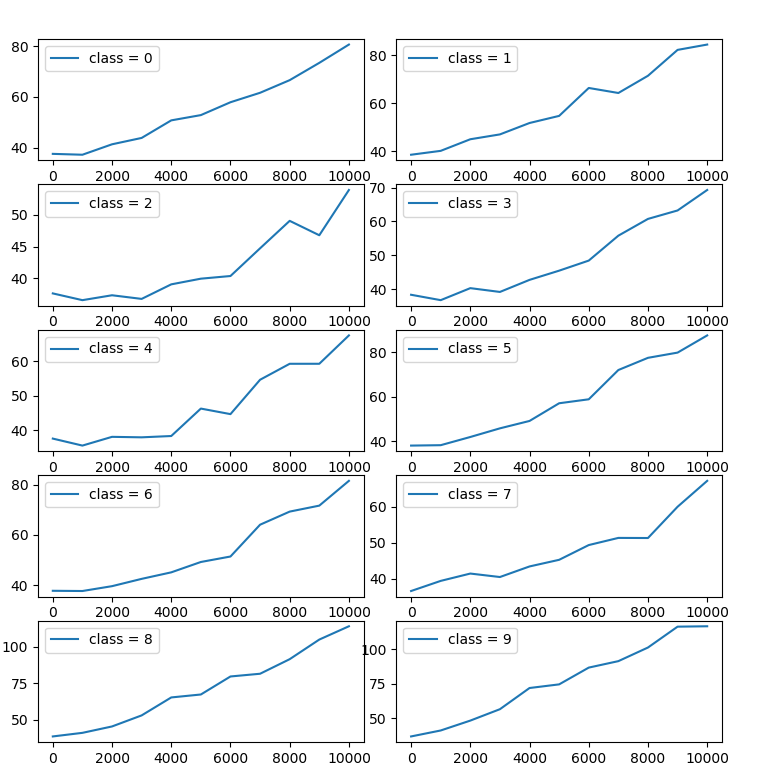
先程のクラスを削除する実験よりかは弱いミスマッチですが、このような弱いミスマッチにおいてもSWDは有効に機能することが確認できます。
おまけ:SSIMとの比較
一つ懸念されることは、同様のミスマッチ検出が他の評価指標(SSIMなど)でも検出できないかということです。先程のクラスを削除する実験をSSIMでも行ってみます。
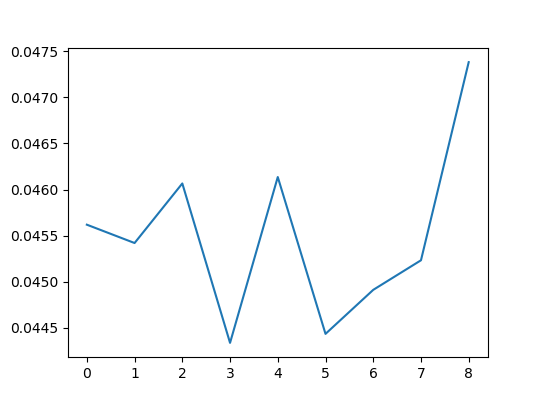
SSIMでは強いミスマッチに対してもうまく検出することができませんでした。
したがって、SWDはミスマッチを検出することに有効であるということが確認できたかと思います。
まとめ
- SWDはPGGANで使われている画像間の類似度の評価指標。ラプラシアンピラミッドベースなので、追加のラベルや訓練済みモデルは不要。
- PyTorch上で実装してみた。GPU上で計算可能。
- 本来はGANの生成画質を計測するものであるが、画像データ間の不均衡やミスマッチを計測する指標としても使用可能。SSIMではうまくいかないようなケースでも計測可能。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー