
PyTorchで複数のGPUで訓練するときのSync Batch Normalizationの必要性


PyTorchにはSync Batch Normalizationというレイヤーがありますが、これが通常のBatch Normzalitionと何が違うのか具体例を通じて見ていきます。また、通常のBatch Normは複数GPUでData Parallelするときにデメリットがあるのでそれも確認していきます。
目次
きっかけ
BigGANの論文を読んでいたら以下のような記述がありました。
Each model is trained on 128 to 512 cores of a Google TPUv3 Pod (Google, 2018), and computes BatchNorm statistics in G across all devices, rather than per-device as is typical.
TPUの話ですが、「デバイスごとにBatch Normlizationを計算するよりかは、すべてのデバイス間で統計量を統一したほうがいいよ」ということです。具体的な名前は出ていませんが、これはいわゆるSync Batch Normalizationといわれるものです。BigGANのPyTorchの(GPU)の実装を見ると、たしかにこれが検討されています。
BigGAN以外にも「Sync Batch Normがいい」と言われることがありますが、具体的になぜSyncのほうがいいか自分はよくわかりませんでした。この記事ではSyncかそうでないかで、具体的にどう計算結果が変わるかを見ていきたいと思います。
想定モデル
Batch Normするだけのモデルを作ります。
import torch
from torch import nn
class BNOnlyModel(nn.Module):
def __init__(self):
super().__init__()
self.bn = nn.BatchNorm1d(1)
def forward(self, inputs):
return self.bn(inputs)
モデルの入力は行列(2階テンソル)とします。shape=(batch, 1)で、やっていることはベクトルのNormalizationと同じです(Batch Normの定義上行列にしているだけ)。
CPU/GPU1枚の場合=特に関係ない
CPUで計算すると特に関係ありません。例えば入力を(0, 1, 4, 9)のように$k^2$で表される配列とします。
def cpu_ver():
model = BNOnlyModel()
x = torch.arange(4, dtype=torch.float32).view(4, 1)** 2 # [0, 1, 4, 9]
y = model(x)
print(y)
結果はただ0,1,4,9をNormalizationでならしただけになります。当たり前ですね。
# CPUの場合
tensor([[-0.5177],
[-0.3698],
[ 0.0740],
[ 0.8136]], grad_fn=<NativeBatchNormBackward>)
GPUは1枚の場合なら(DataParallelをやらなければ)関係ありません。同様に、
def single_gpu_ver():
model = BNOnlyModel().cuda()
x = torch.arange(4, dtype=torch.float32).cuda().view(4, 1)** 2
y = model(x)
print(y)
# GPU1枚の場合
tensor([[-0.6794],
[-0.4853],
[ 0.0971],
[ 1.0677]], device='cuda:0', grad_fn=<CudnnBatchNormBackward>)
CPUとGPUでスケールが若干違うのが気になるけど、Normalization自体は特におかしいところはありません。
GPU2枚以上(Data Parallel)でのBatch Normzalition
ここからが問題。ではData ParallelしたときのBatch Normってどんな挙動なんでしょうか? 先程のモデルを使えば同じようにできます。
def multi_gpu_ver():
model = BNOnlyModel().cuda()
model = nn.DataParallel(model)
x = torch.arange(4, dtype=torch.float32).cuda().view(4, 1)** 2
y = model(x)
print(y)
DataParallelを使うという複数GPUでの教科書的な書き方です。しかし、この結果はとても奇妙なことになります。
# GPU2枚でDataParallel + 通常のBatch Normの場合
tensor([[-0.9162],
[ 0.9162],
[-0.9162],
[ 0.9162]], device='cuda:0', grad_fn=<GatherBackward>)
なんと、「0, 1」と「4, 9」が別のGPUに配置されてしまったせいで、別々の平均・標準偏差でNormalizationされています。もともと2乗のデータだったのに、ジグザクな出力になってしまいデータの分布が変わってしまいました。これはおかしいです。
PyTorch公式のSync Batch Normが使えない
PyTorchには公式のSync Batch Normがあります。
詳細:https://pytorch.org/docs/stable/nn.html#syncbatchnorm
これを使えばSync Batch Normが使えるはずなのですが、ちょっと困ったことがあります。それは、DistributedDataParallel(torch.nn.parallel.DistributedDataParallel)でラップしないといけないということです。チュートリアルはこちら
DistributedDataParallelのチュートリアル:https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
ただ、これはUbuntuではおそらくうまくいくと思われるのですが、Windowsではうまくいきませんでした(PyTorch v1.1.0)。関連issue。DistributedDataParallelが使えるかどうかのテストとして、
torch.distributed.is_available()
という関数があります。これを実行したところ、自分の環境では「False」が返ってきました。そしてDistributedDataParallelを実行すると初期化に失敗してしまいます。
つまり、DistributedDataParallelが使えない環境だと、PyTorch組み込みのSync Batch Normが使えないという状況が起こります。これは困りました。
サードパーティのSync Batch Norm
BigGANのリポジトリを見ていたら、Sync Batch Normは公式のものではなく以下のリポジトリを使っていました。
https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
このサードパーティのSync Batch NormはDistributedDataParallelでのラップを必要としないため、何らかの理由でDistributedDataParallelが使えない環境でも使用することができます。今回はこれを使っていきます。
使い方は単純で、このリポジトリから「sync_batchnorm」のフォルダをコピーしてくるだけです。
Sync Batch Normの場合
さて話を戻しましょう。普通のBatch NormでData Parallelを使った場合、GPU別にBatch Normが計算されてしまい計算結果がおかしなことになるということを確認しました。先程のサードパーティの実装を使えば、モデル定義をそのままにしてBatch NormをSync Batch Normに変換することができます(公式のSync Batch Normでも同じことはできます)。
from sync_batchnorm import convert_model, DataParallelWithCallback
def sync_batchnorm():
model = BNOnlyModel()
model = convert_model(model).cuda() # Batch NormをSync Batch Normに変換
model = DataParallelWithCallback(model, device_ids=[0, 1]) # Data Parallel
x = torch.arange(4, dtype=torch.float32).cuda().view(-1, 1)** 2
y = model(x)
print(y)
device_idsは今GPUが2枚のものとしてやっています。この結果は以下のようになります。
# SyncBatchNorm + GPU2枚
tensor([[-0.1091],
[-0.0780],
[ 0.0156],
[ 0.1715]], device='cuda:0', grad_fn=<GatherBackward>)
(相変わらずスケールがまちまちすぎるのが気になりますが)、GPU2枚でも想定した通りの挙動になりました。Sync Batch Normが必要なのはこういうことです。つまり、Sync Batch Normを使うと、平均・標準偏差といったパラメーターがデバイス間で共通のものとして計算されているため、並列化による分布の変動がおきないということになります(これはかなり極端な例ですが)。
この例で、「DataParallelWithCallback」をコメントアウトすると次のようになります。
# DataParallelWithCallbackをコメントアウト
tensor([[-0.8537],
[-0.6098],
[ 0.1220],
[ 1.3415]], device='cuda:0', grad_fn=<CudnnBatchNormBackward>)
相変わらずスケールが謎すぎますが、GPUが1個と2個だと「grad_fn」の表記が変わるのでしょうね。
本当に並列化が効いているの?
DataParallelWithCallbackのケースでも本当に並列化が効いているのか不思議だったので、モデルを次のようにしてみました。
class BNOnlyModel(nn.Module):
def __init__(self):
super().__init__()
self.bn = nn.BatchNorm1d(1)
def forward(self, inputs):
# some heavy work
x = torch.randn(64, 1024, 64, 64).cuda()
kernel = torch.randn(1024, 1024, 25, 25).cuda()
y = F.conv2d(x, kernel)
####
return self.bn(inputs)
BatchNorm1個だけだとすぐ計算が終わってしまい、GPU使用率などの違いを確認できません。そこで、カーネルサイズ25、チャンネル数1024→1024などの意味のない巨大な畳み込み計算をモデルに入れます。さすがにこれは時間がかかるので、GPU使用率で並列化が効いているのかどうか容易に観測することができます。
計算中のELSA System Graphでのグラフはこちらです。2枚目のGPU使用率です。
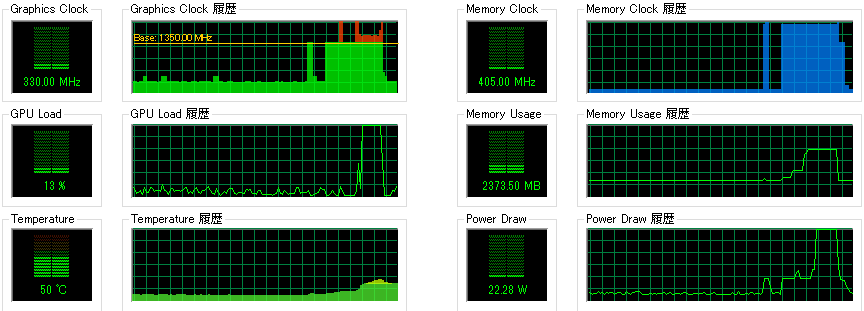
確かにこれは2枚目のGPUがちゃんと動いていますね(並列化が正しく動いている)。
まとめ
- 通常のBatch NormをData Parallelですると、平均や分散がデバイス単位で計算されてしまい、ミニバッチ内のデータの分布が変わってしまう可能性がある
- Sync Batch Normを使うと、デバイス間で平均や分散を共有するため、この問題を解決することができる
- ただし、公式のSync Batch Normは環境次第で動かないケースがあるので、サードパーティでケアする
複数GPUならSync Batch Normが必須というわけではないですが、GANでは頭の片隅に入れておいて損ではないかなと思います。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー